#009 Activation functions and their derivatives
Activation functions
When we build a neural network, one of the choices we have to make is what activation functions to use in the hidden layers as well as at the output unit of the Neural Network. So far, we’ve just been using the sigmoid activation function but sometimes other choices can work much better. Let’s take a look at some of the options.
\(sigmoid \) activation function
In the forward propagation steps for Neural Network there are two steps where we use sigmoid function as the activation function.
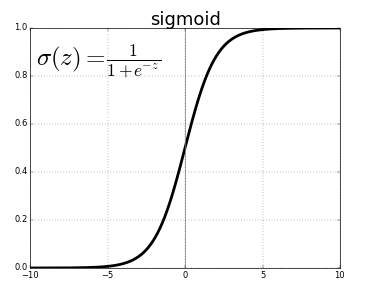
\(sigmoid \) function
So, it goes smoothly from zero to one and if we use sigmoid ( \(\color{Green} {\sigma} (z) \)) function as the activation function in all units in the Neural Network that looks like this:
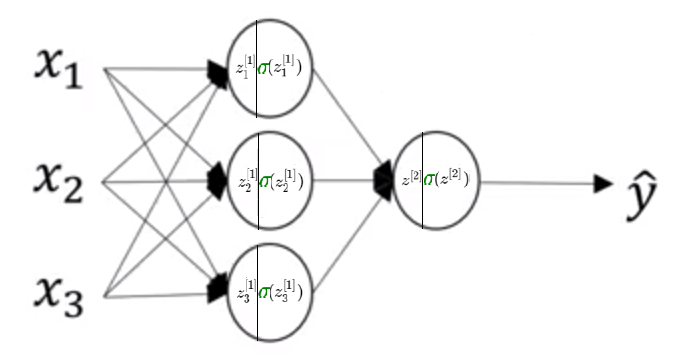
A 2-layer Neural Network with \(sigmoid \) activation function in both layers
We have following equations:
\(z^{[1]} = W^{[1]} x + b ^{[1]} \)
\(a^{[1]} = \color {Green}{\sigma} (z^{[1]} ) \)
\(z^{[2]} = W^{[2]} a^{[1]} + b ^{[1]} \)
\(a^{[2]} = \color{Green}{\sigma} ( z^{[2]} )\)
In more general case we can have a different function which we will denote with \( \color{Blue}{g}(z) \).
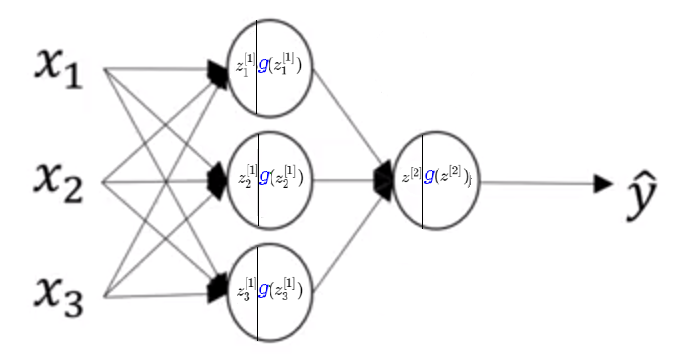
A 2-layer Neural Network with activation function \(g({z})\)
So, if we use \(g(z) \) then those equations above will be transformed to these:
\(z^{[1]}=W^{[1]} x + b ^{[1]} \)
\(a^{[1]} = \color {Blue}{g}( z^{[1]} )\)
\(z^{[2]} = W^{[2]} a^{[1]} + b ^{[1]}\)
\(a^{[2]} = \color {Blue}{g}( z^{[2]}) \)
\(tanh\) activation function
An activation function that almost always goes better than sigmoid function is \(tanh \) function. The graphic of this function is the following one:
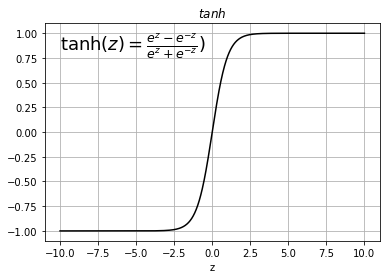
\(tanh \) activation function
This function is a shifted version of a \(sigmoid \) function but scaled between \(-1 \) and \(1\) . If we use a \(tanh\) as the activation function it almost always works better then sigmoid function because the mean of all possible values of this function is zero. Actually, it has an effect of centering the data so that the mean of the data is close to zero rather than to \(0.5 \) and it also makes learning easier for the next layers.
When solving a binary classification problem it is better to use sigmoid function because it is a more natural choice because if output labels \(y \in \{ 0,1 \} \) then it makes sense that \(\hat{y} \in [1,1] \) .
An activation function may be different for different layers through Neural Network, but in one layer there must be one – the same activation function. We use superscripts as square parentheses \([] \) to denote to which layer of a Neural Network belongs each activation function. For example, activation function \(g^{[1]} \) is the activation function of the first layer of the Neural Network and \(g^{[2]} \) is the activation function of the second layer, as presented in the following picture.
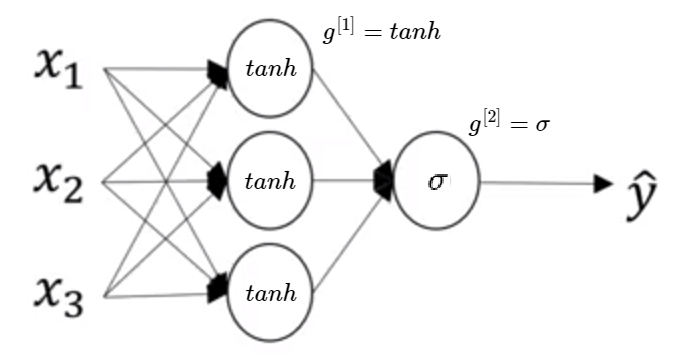
A 2-layer Neural Network with \(tanh\) activation function in the first layer and \(sigmoid\) activation function in the second layer
When talking about \(\sigma(z) \) and \(tanh(z) \) activation functions, one of their downsides is that derivatives of these functions are very small for higher values of \(z \) and this can slow down gradient descent.
In the following computations we will denote the derivative of function with \(g'(z) \) and that is equal to \(\frac{d}{dz}g(z) \).
Derivative of \(sigmoid \) function.
\(g (z)=\frac{1}{1+e^{-z}} \)
\(\frac{d}{dz}g(z)=slope\ of \ g(z) \ at \ z \)
\(\frac{d}{dz}g(z) = \frac{-1}{(1+e^{-z})^2} e^{-z} (-1) = \frac {e^{-z}} {(1+e^{-z})^2} = \frac{e^{-z} +1 -1 }{(1+e^{-z})^2} \)
\(\frac{d}{dz}g(z)= \frac{1}{1+e^{-z}} (\frac{1+e^{-z}}{1+e^{-z}} + \frac{-1}{1+e^{-z}} ) = \frac{1}{1+e^{-z} } \left (1-\frac{1}{1+e^{-z}}\right ) = g(z)( 1-g(z)) \)
\( g'(z) =g(z)(1-g(z)) \)
\(z=10 \ \ \ g(z) \approx 1 \Rightarrow g'(z) \approx 1(1-1)\approx 0 \)
\(z=-10\ \ \ g(z) \approx 0 \Rightarrow g'(z) \approx0(1-0)\approx 0 \)
\(z=0 \ \ \ g(z)=\frac{1}{2} \Rightarrow g'(z)= \frac{1}{2}=\left (1-\frac{1}{2}\right )=\frac{1}{4} \)
We denote an activation function with \(a \), so we have:
\(a = g (z)=\frac{1}{1+e^{-z}} \)
\(\frac{d}{dz}g(z)=a(1-a) \)
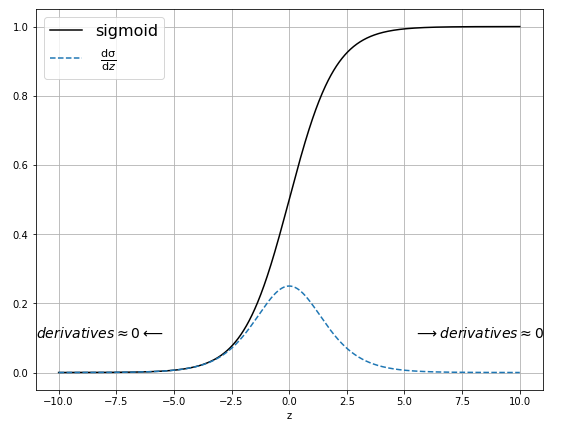
\(sigmoid\) function and it’s derivative
Derivative of a \(tanh \) function.
\(g (z)=tanh(z) =\frac{e^{z}-e^{-z}}{e^{z}+e^{-z}}\)
\(\frac{d}{dz} g(z) =slope\ of \ g(z) \ at \ z\)
\(\frac{d}{dz}g(z) = \frac{(e^{z}+e^{-z})(e^{z}+e^{-z}) – (e^{z}-e^{-z})(e^{z}-e^{-z}) }{(e^{z}+e^{-z})^2} = \frac{(e^{z}+e^{-z})^2 – (e^{z}-e^{-z})^2 }{(e^{z}+e^{-z})^2} \)
\(\frac{d}{dz}g(z) = \frac{\frac{(e^{z}+e^{-z})^2 – (e^{z}-e^{-z})^2 }{(e^{z}+e^{-z})^2}}{\frac{(e^{z}+e^{-z})^2}{(e^{z}+e^{-z})^2}} = \frac{\frac{1-{tanh(z)}^2}{1}}{1} = 1- {tanh(z)}^2 \)
\(z=10 \ \ \ tanh(z) \approx 1 \Rightarrow \frac{d}{dz}g(z) \approx 1 – 1^2 \approx 0 \)
\(z=-10\ \ \ tanh(z) \approx -1 \Rightarrow \frac{d}{dz}g(z) \approx 1 – (-1)^2 \approx 0 \)
\(z=0 \ \ \ tanh(z)=0 \Rightarrow \frac{d}{dz}g(z)(z)=1- 0^2 = 1 \)
$$ $$
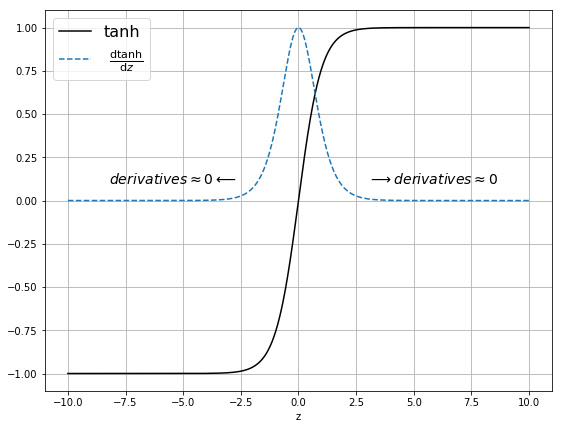
\(tanh\) activation function and it’s derivative
\(ReLU \) and \(LeakyReLU \) activation function
One other choice that is well known in Machine Learning is ReLU function. This function is a commonly used activation function nowadays.
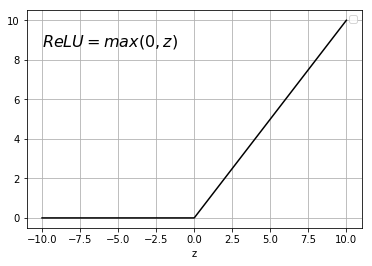
\(ReLU\) function
There is one more function, and it is modification of \(ReLU\) function. It is a \(Leaky ReLU\) function. \(Leaky ReLU\) usually works better then \(ReLU\) function. Here is a graphical representation of this function:
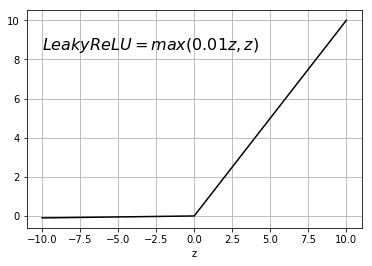
\(Leaky ReLU \) function
Derivatives of \(ReLU \) and \(LeakyReLU \) activation functions
A derivative of a \(ReLU \) function is:
\( g(z)=max(0,z) \)
\(g'(z)= \Bigg\{ \begin{matrix} 1 \enspace if \enspace z > 0 \\ 0 \enspace if \enspace z<0 \\ undefined \enspace if \enspace z = 0 \end{matrix}\)
The derivative of a \(ReLU\) function is undefined at \(0\), but we can say that derivative of this function at zero is either \(0 \) or \(1\). Both solution would work when they are implemented in software. The same solution works for \(Leaky ReLU\) function.
\(g'(z)= \begin{cases} 0 & if \enspace z<0 \\ 1 & if \enspace z\geq0\\\end{cases}\)

Derivative of a \(ReLU\) function
Derivative of \(Leaky ReLU \) function is :
$$ g(z)=max(0.01z,z) $$
$$ g'(z) = \begin{cases}0.01 & if \ \ z< 0 \\1 & if \ \ z\geq0\\\end{cases} $$
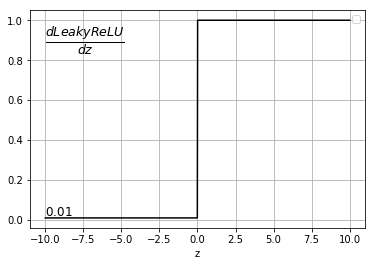
Derivative of a \(Leaky ReLU\) function
Why the non-linear activation function?
For this shallow Neural Network:
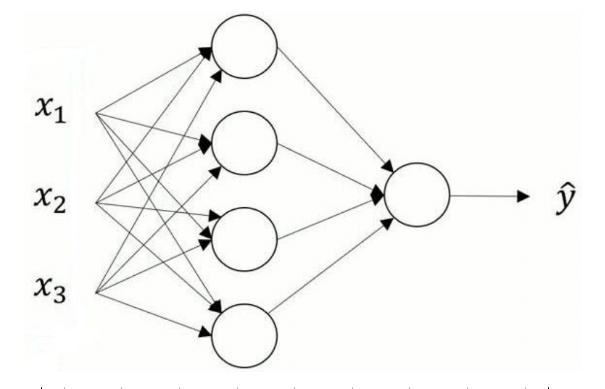
A shallow Neural Network
we have following propagation steps:
\(z^{[1]}=W^{[1]}x+b^{[1]}\)
\(a^{[1]}=g^{[1]}(z^{[1]})\)
\(z^{[2]}=W^{[2]}x+b^{[2]}\)
\(a^{[2]}=g^{[2]}(z^{[2]})\)
If we want our activation functions to be linear functions, so that we have \( g^{[1]} = z^{[1]} \) and \( g^{[1]} = z^{[1]}\) , then these equations above become:
\( z^{[1]}=W^{[1]}x+b^{[1]} \)
\(a^{[1]}=g^{[1]}(z^{[1]}) \)
\(a^{[1]}=z^{[1]}=W^{[1]}x+b^{[1]} \)
\(a^{[2]}=z^{[2]}=W^{[2]}a^{[1]}+b^{[2]} \)
\(a^{[2]}=W^{[2]}(W^{[1]}x+b^{[1]})+b^{[2]}\)
\(a^{[2]}=(W^{[2]}W^{[1]})x+(W^{[2]}b^{[1]}+b^{[2]})=W’x+b’ \)
Now, it’s clear that if we use a linear activation function (identity activation function), then the Neural Network will output linear output of the input. This loses much of the representational power of the neural network as often times the output that we are trying to predict has a non-linear relationship with the inputs. It can be shown that if we use a linear activation function for a hidden layer and sigmoid function for an output layer, our model becomes a logistic regression model. Due to the fact that a composition of two linear functions is a linear function, our area of implementing such a Neural Network reduces rapidly. Rare implementation example can be solving a regression problem in machine learning (where we use a linear activation function in a hidden layer). Recommended usage of linear activation function is to be implemented in the output layer in case of regression.
The complete code for this post you can find here.
In the next post we will see how to implement gradient descent for one hidden layer Neural Network.