Visual Complexity Without an LLM Judge — Head-to-Head Against Gemini Highlights: LLM/VLM pairwise judges have a structural position bias — the first-shown candidate wins more often than it should, worst-case exactly on close calls. We replace the LLM judge with a transparent, CPU-only alternative: handcrafted complexity features + logistic regression on the signed difference \( \mathbf{d} = f(A) – f(B) \). The same fit gives you a per-image score \( \text{score}(x) = \mathbf{w} \cdot f(x)…
Read more

LLM_log #024 Visual Complexity Without an LLM Judge — Head-to-Head Against Gemini

LLM_log #023: Visual Complexity Scoring — CLIP vs Gemini on SAVOIAS Advertisements
Highlights: In this post we try to answer one practical question: can we score the visual complexity of an image without humans in the loop? We grab the SAVOIAS dataset (1,420 images with human-rated complexity), focus on the 200 advertisements, and try five different recipes — zero-shot CLIP prompts, Ridge regression on CLIP embeddings, pairwise ranking on embedding differences, kNN retrieval on cosine similarity, and finally Gemini 2.5 Pro as a chain-of-thought judge. The headline:…
Read more
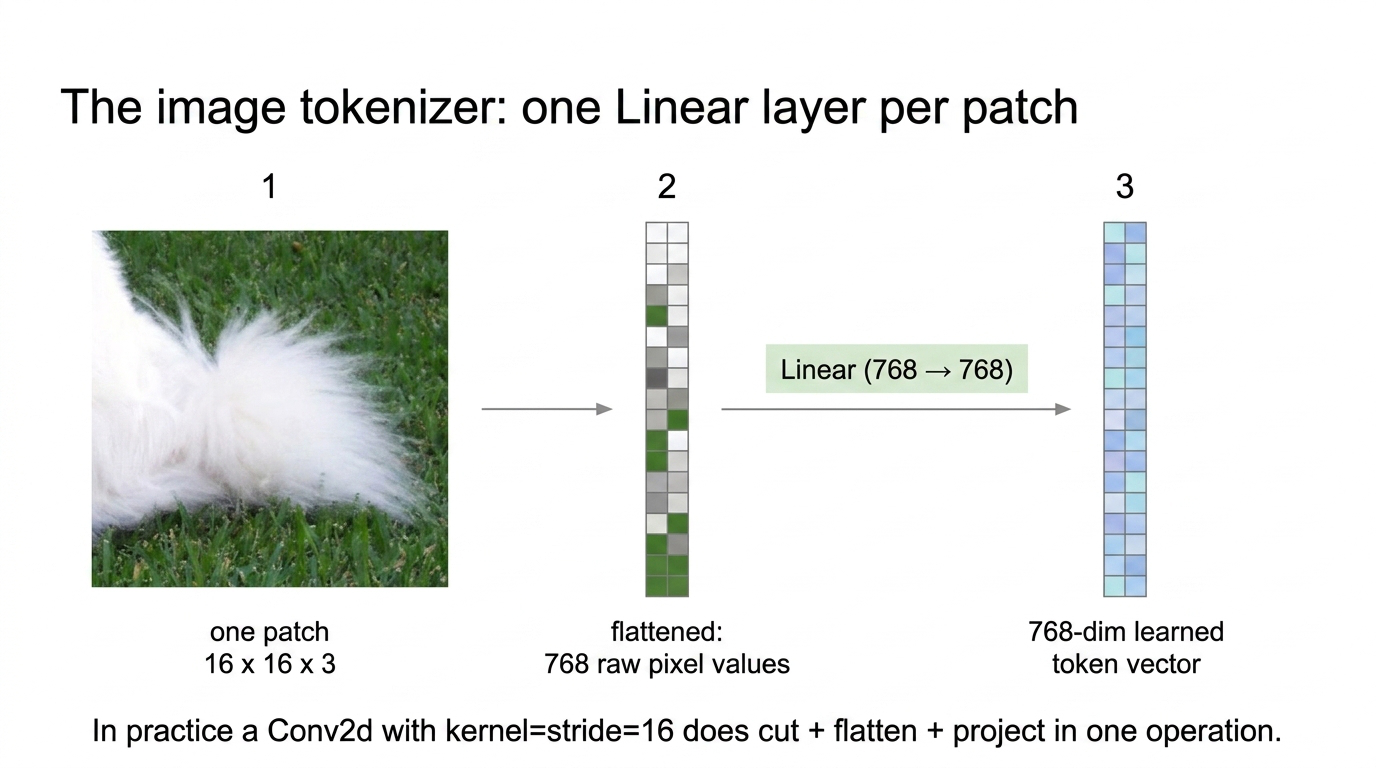
LLM_log #022: Vision Transformer From Scratch — From Pixels to Tokens (Part 1)
Highlights: An image is just a matrix — but the Transformer eats sequences of vectors. The whole “vision” trick of ViT lives in how that matrix is turned into a sequence. We cut a 224×224 image into a fixed 14×14 grid of 16×16 patches, flatten each, and project it through ONE learned Linear layer. Patches are not sampled — every cell of the grid becomes a token, in fixed order. We prepend a learnable [CLS]…
Read more
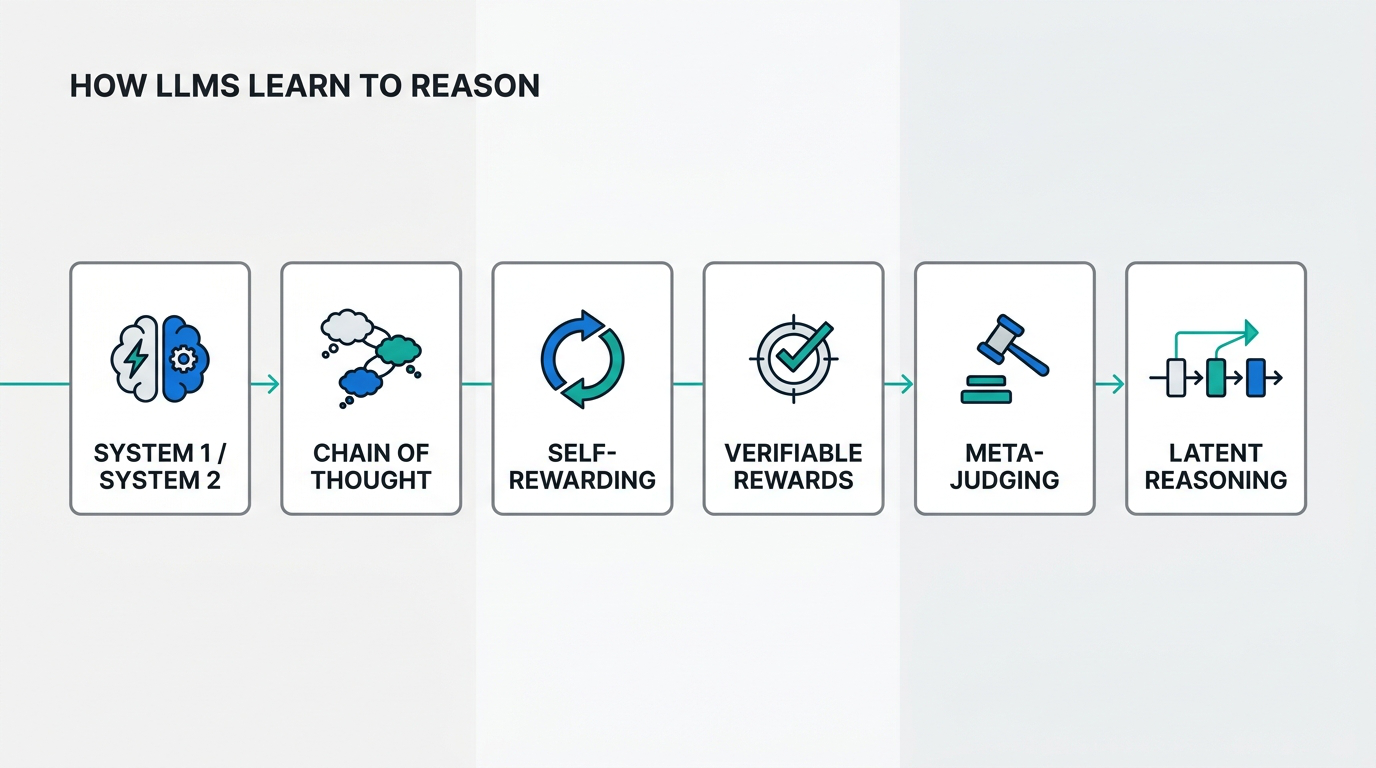
LLM_log #021: How LLMs Learn to Reason — From Chain-of-Thought to Self-Rewarding and Meta-Judges
Highlights: Jason Weston traces the arc from early neural language models to self-improving LLMs that generate their own training data and evaluate their own reasoning System 1 vs System 2: fixed-compute pattern-matching vs deliberate multi-step reasoning — and why the same LLM implements both Chain-of-Thought prompting: adding “Let’s think step by step” jumps GSM8K accuracy from ~10% to 40–50%; few-shot CoT hits 90%+ on MultiArith CoVe + S2A: Chain-of-Verification reduces hallucinations 3× on knowledge list…
Read more
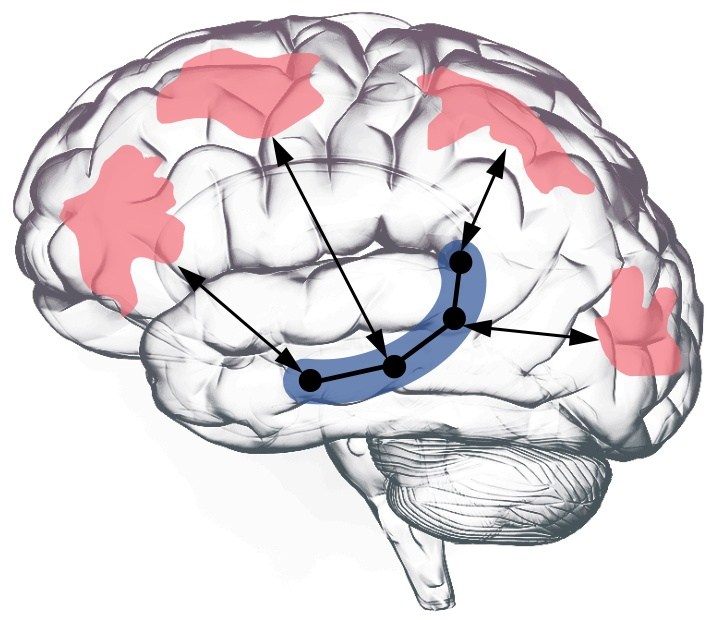
LLM_log #020: Language Agents — Memory, Reasoning, and Planning
Highlights: Yu Su’s guest lecture in the UC Berkeley CS294-280 course argues language agents are not “LLM + tools” but a new evolutionary stage of machine intelligence. We walk through the agent-first framing and three concrete research pillars — long-term memory (HippoRAG), implicit reasoning (Grokked Transformers), and model-based planning (WebDreamer) — that map directly to classical AI problems re-examined through the lens of LLMs. Agent-first framing: token generation is itself an action; the inner monologue…
Read more
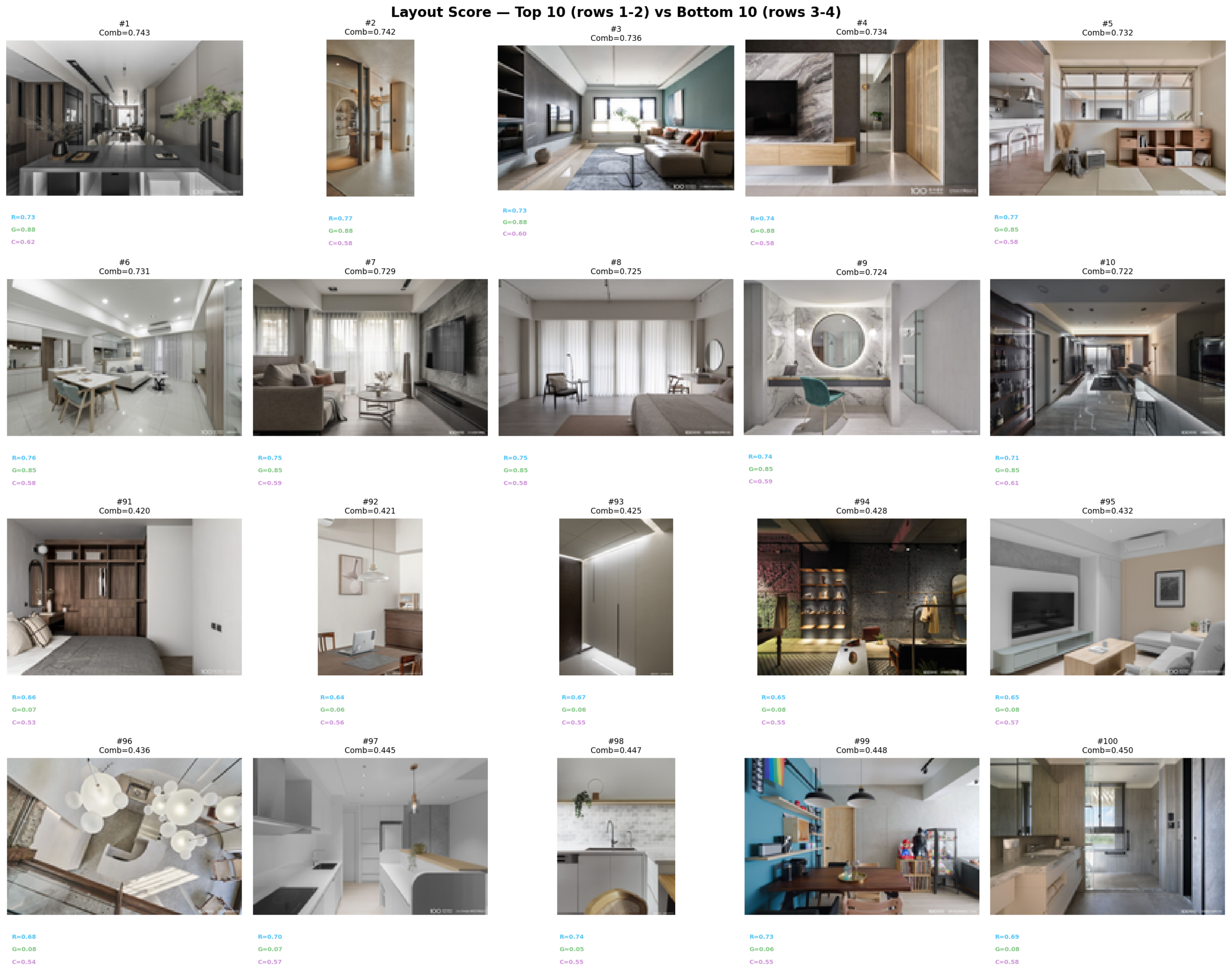
LLM_log #019: Layout Scoring — Does Furniture Placement Follow the Rule of Thirds?
Highlights: Can we measure spatial composition in living room photographs? We score 100 interior images using saliency-based rule-of-thirds alignment, Gemini Vision layout ratings, and CLIP composition prompts — then cross-correlate with color scores from #018 to find rooms that nail both color and layout. Method 1 — Rule of Thirds + Balance: gradient saliency → Gaussian-weighted power point alignment + visual balance index Method 2 — Gemini Vision Layout: send each image to Gemini 2.5…
Read more

LLM_log #018: Color Harmony Ranking — Three Methods, 500 Living Rooms
Highlights: Can three completely independent methods agree on which living room has the best colors? We rank 500 interior images using Cohen-Or harmonic templates, Hasler-Süsstrunk colorfulness, and CLIP IQA with 44 color-focused prompts — then measure whether they correlate at all. Method 1 — Cohen-Or: K-means palette → saturation-weighted hue histogram → sweep 7 harmonic templates × 36 rotations → H/T/S composite Method 2 — Hasler-Süsstrunk: opponent channels (rg, yb) → colorfulness + 4×4 spatial…
Read more
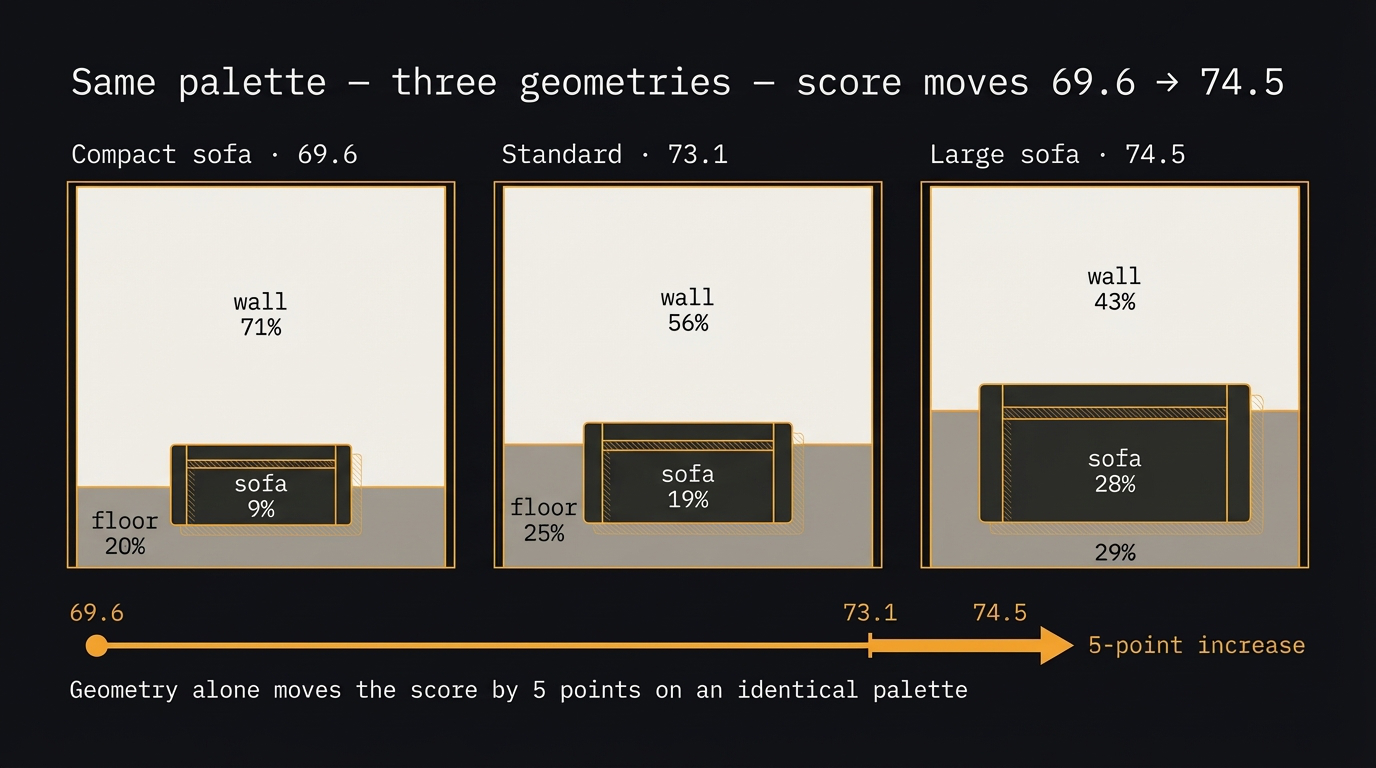
LLM_log #017: Scoring Color Harmony — From Two Squares to a Room
Highlights: Can you score color quality algorithmically? Not as taste — as math. This post builds a scoring system from first principles: two adjacent color squares, then triplets, then a real room with three spatial regions. We walk through every formula with brand and flag examples you already know, then prove that geometry alone can move the score by five points on an identical palette. Four pair scoring dimensions: contrast (WCAG luminance), harmony (hue peaks),…
Read more
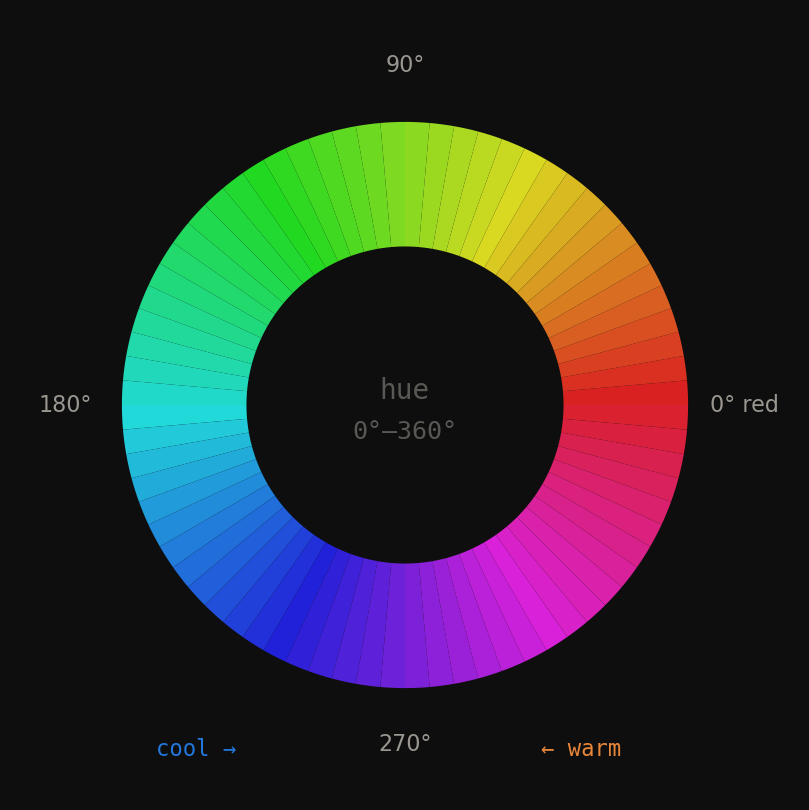
LLM_log #016: RGB is for Screens. Lab is for Humans — Color Scoring for Living Room Images
Highlights: Every computer vision pipeline that touches color starts with the same mistake: using RGB. RGB is built for screens, not for human perception. In this post we build a complete color scoring system for living room images — from the right color space (Lab), through palette extraction (K-means), to a two-color harmony scorer tested on 10 global brand palettes. We discover why luxury brands deliberately score low, and what that means for your model.…
Read more

LLM_log #015: Fine-Tuning LLMs — Teach a 3B Model to Call Functions with QLoRA + Unsloth on Free Colab T4
Highlights: Every modern LLM agent — from ChatGPT plugins to Claude tools — relies on a single learned skill: outputting a structured JSON function call instead of free text. In this post we teach that skill to a 3-billion parameter model using QLoRA on a free Google Colab T4. We start from the fundamentals — why fine-tuning, when LoRA, how quantization works — then build the full training pipeline from scratch. By the end, your…
Read more
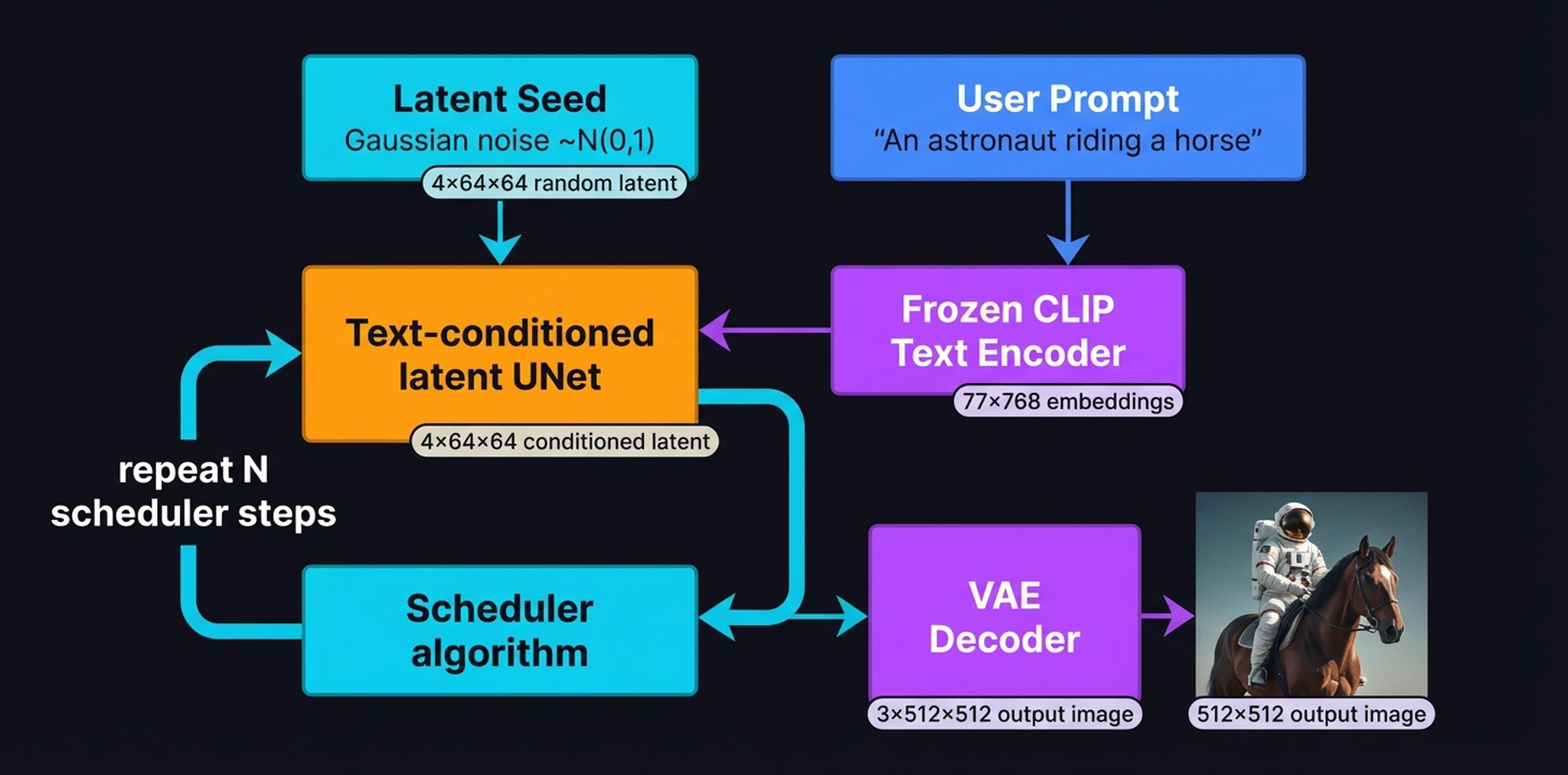
LLM_log #014: Stable Diffusion & Conditional Latent Diffusion — From VAE Compression to Cross-Attention Conditioning
Highlights: Stable Diffusion doesn’t paint an image in one shot — it sculpts one from static, guided by your words. In this post we disassemble the entire machine. We start with the VAE that compresses pixels into a tractable latent space, walk through the forward and reverse diffusion processes, open up the UNet to see how cross-attention physically connects text tokens to spatial regions, and finish with the complete Latent Diffusion architecture diagram that ties…
Read more

LLM_log #013: Latent Space — From AutoEncoders to the Engine Inside Stable Diffusion
Highlights: Every time you use Stable Diffusion, DALL-E, or Sora, the model never touches a single pixel during its main computation. It works entirely inside a compressed, structured space of floating-point numbers — a latent space learned by a VAE. In this post we build that space from scratch. We start from the simplest possible compression — an AutoEncoder on MNIST digits — understand why it fails at generation, fix it with the VAE’s probabilistic…
Read more

#004 How to smooth and sharpen an image in OpenCV?
Highlight: In our previous posts we mastered some basic image processing techniques and now we are ready to move on to more advanced concepts. In this post, we are going to explain how to blur and sharpen images. When we want to blur or sharpen our image, we need to apply a linear filter. You will learn several types of filters that we often use in the image processing In addition, we will also show…
Read more

#000 How to access and edit pixel values in OpenCV with Python?
Highlight: Welcome to another datahacker.rs post series! We are going to talk about digital image processing using OpenCV in Python. In this series, you will be introduced to the basic concepts of OpenCV and you will be able to start writing your first scripts in Python. Our first post will provide you with an introduction to the OpenCV library and some basic concepts that are necessary for building your computer vision applications. You will learn…
Read more

#006 Linear Algebra – Inner or Dot Product of two Vectors
Highlight: In this post we will review one of the fundamental operators in Linear Algebra. It is known as a Dot product or an Inner product of two vectors. Most of you are already familiar with this operator, and actually it’s quite easy to explain. And yet, we will give some additional insights as well as some basic info how to use it in Python. Tutorial Overview: Dot product :: Definition and properties Linear functions…
Read more

#008 Linear Algebra – Eigenvectors and Eigenvalues
Highlight: In this post we will talk about eigenvalues and eigenvectors. This concept proved to be quite puzzling to comprehend for many machine learning and linear algebra practitioners. However, with a very good and solid introduction that we provided in our previous posts we will be able to explain eigenvalues and eigenvectors and enable very good visual interpretation and intuition of these topics. We give some Python recipes as well. Tutorial Overview: Intuition about eigenvectors…
Read more

#011 TF How to improve the model performance with Data Augmentation?
Highlights: In this post we will show the benefits of data augmentation techniques as a way to improve performance of a model. This method will be very beneficial when we do not have enough data at our disposal. Tutorial Overview: Training without data augmentation What is data augmentation? Training with data augmentation Visualization 1. Training without data augmentation A familiar question is “why should we use data augmentation?”. So, let’s see the answer. In order…
Read more