#011 Deep L-layer Neural Network

Deep L-layer Neural Network
In this post we will make a Neural Network overview. We will see what is the simplest representation of a Neural Network and how deep representation of a Neural Network looks like.
You may have heard that the perceptron is the simplest version of a Neural Network. The perceptron is a one layer Neural Network with the \(step\) activation function . In the previous posts we have defined a Logistic Regression as a single unit that uses \(sigmoid\) activation function. Both of these simple Neural Networks we also call shallow neural networks and they are only reasonable to be applied when classifying linearly separable classes. 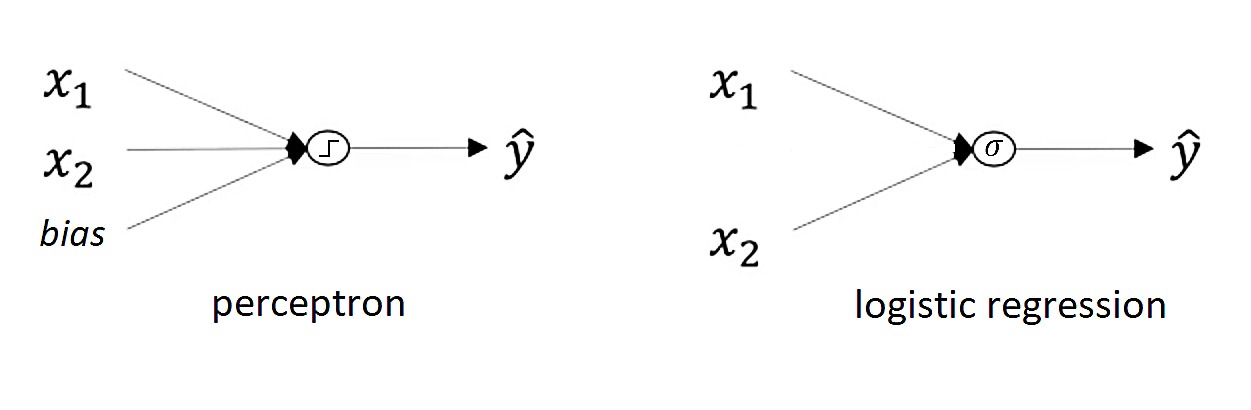
A single unit of a Neural Network
Slightly more complex neural network is a two layer neural network (it is a neural network with one hidden layer). This shallow neural network can classify two datasets that are not linaearly separable, but it is not good at classifying more compelex datasets.
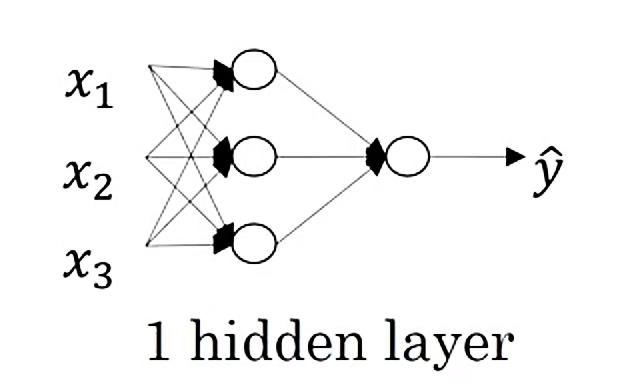
One hidden layer Neural Network
A little bit more complex model than previous one is a tree layer neural network (it is a neural network with two nidden layers):
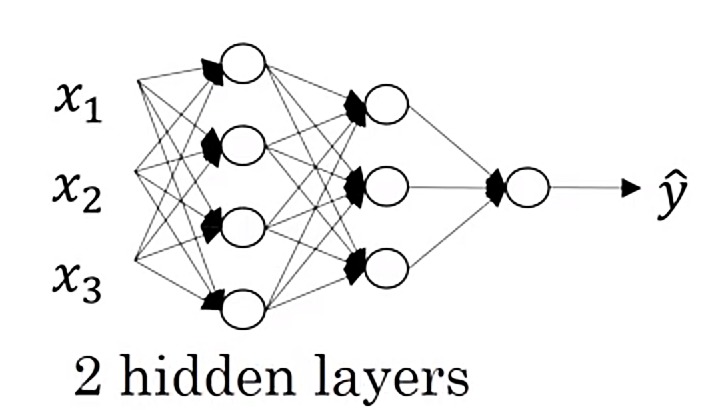
Two hidden layers Neural Network
Even more complex neural network, which we can call deep neural network, is for example, a six layer neural network (or neural network with five hidden layers):
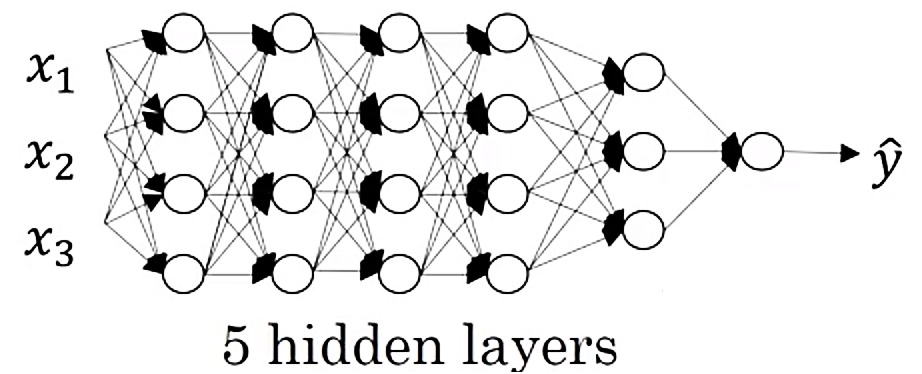
A Deep Neural Network
How do we count layes in a neural network?
When counting layers in a neural network we count hidden layers as well as the output layer, but we don’t count an input layer.
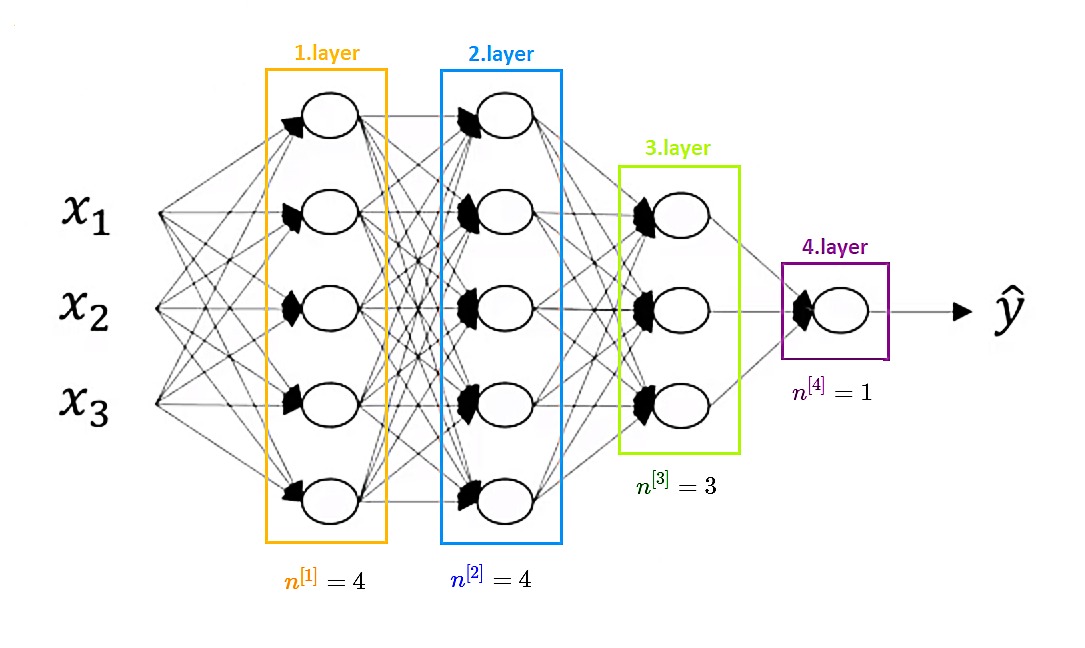
Four hidden layer Neural Network with a number of hidden units in each layer
Here is the notation overview that we will use to describe deep neural networks:
Here is a four layer neural network, so it is a neural network with three hidden layers. Notation we will use for this neural network is :
- \(L \) to denote the number of layers in a neural network
- in this neural network \(L = 4\)
- \(n^{[l]} \) to denote a number of layers in the \(l^{th}\) layer
- \(\color{Orange} {n^{[1]}} = 4 \), there are four units in the first layer
- \( \color{Blue} {n^{[2]}}= 4 \), there are four units in the second layer
- \(\color{Green} {n^{[3] }}= 3 \), there are three units in the thirs layer
- \(\color{Purple} {n^{[4]} }= 1 \), this neural network outputs a scalar value
- \(n^{[0]} = n_x = 3 \) because input vector, feature vector, has three features
- \(a^{[l]} = g(z^{[l]}) \) to denote activation functions in the \(l^{th}\) layer
- \(x = a^{[0]} \)
- \( \textbf{W}^{[l]} \) to denote weights for computing \(z^{[l]} \)
Forward propagation in a deep network
Once again we will see how the forward propagation equations look like. We will show equation for the neural network ilustrated above. In addition, below every two equations we will show the dimensions of vectors or matrices used in the calculations.
A vectorized version of these equations, equations considering all input examples, and correspodnding dimensions of these matrices (which are printed in gray as above) are:
| Equations for the neural network shown above, and below every two equations we will show the dimensions of vectors or matrices used in calculations (which are printed in gray as above) | Vectorized version of these equations, equations considering all input examples, and correspodnding dimensions of these matrices (which are printed in gray as above) |
| Equations for the first layer:
\(z^{[1]}= W^{[1]}x + b^{[1]} \) \(a^{[1]} = g^{[1]}(z^{[1]}) \) \(\color{LightGray} { (n^{[1]},1) = (n^{[1]},n^{[0]} ) ( n^{[0]}, 1) + (n^{[1]},1), n^{[0]} = n_x} \) \(\color{LightGray} { (n^{[1]},1) = (n^{[1]},1) } \) Equations for the second layer: \(z^{[2]} = W^{[2]}a^{[1]} + b^{[2]} \) \(a^{[2]} = g^{[2]}(z^{[2]}) \) \(\color{LightGray} { (n^{[2]},1) = (n^{[2]},n^{[1]} ) ( n^{[1]}, 1) + (n^{[2]},1)} \) \(\color{LightGray} { (n^{[2]},1) = (n^{[2]},1) } \) Equations for the third layer: \(z^{[3]} = W^{[3]}a^{[2]} + b^{[3]} \) \(a^{[3]} = g^{[3]}(z^{[3]}) \) \(\color{LightGray} { (n^{[2]},1) = (n^{[2]},n^{[1]} ) ( n^{[1]}, 1) + (n^{[2]},1)} \) \(\color{LightGray} { (n^{[3]},1) = (n^{[3]},1) } \) Equations for the fourth layer: \(z^{[4]} = W^{[3]}a^{[3]} + b^{[3]} \) \(a^{[4]} = g^{[4]}(z^{[4]}) \) \(\color{LightGray} { (n^{[4]},1) = (n^{[4]},n^{[3]} ) ( n^{[3]}, 1) + (n^{[4]},1)} \) \(\color{LightGray} { (n^{[4]},1)} \color{LightGray} {= (n^{[4]},1) } \) |
Equations for the first layer: \(\textbf{Z}^{[1]}= \textbf{W}^{[1]}\textbf{X} + b^{[1]} \) \(\textbf{A}^{[1]} = g^{[1]}(\textbf{Z}^{[1]}) \) \(\color{LightGray} { (n^{[1]},m) = (n^{[1]},n^{[0]} ) ( n^{[0]}, m) + (n^{[1]},1), n^{[0]} = n_x} \) \(\color{LightGray} { (n^{[1]},m) = (n^{[1]},m) } \) Equations for the second layer: \(\textbf{Z}^{[2]} = \textbf{W}^{[2]}\textbf{A}^{[1]} + b^{[2]} \) \(A^{[2]} = g^{[2]}(\textbf{Z}^{[2]}) \) \(\color{LightGray} { (n^{[2]},m) = (n^{[2]},n^{[1]} ) ( n^{[1]}, m) + (n^{[2]},1)} \) \(\color{LightGray} { (n^{[2]},m) = (n^{[2]},m) } \) Equations for the third layer: \(\textbf{Z}^{[3]} = \textbf{W}^{[3]}\textbf{A}^{[2]} + b^{[3]} \) \(A^{[3]} = g^{[3]}(\textbf{Z}^{[3]}) \) \(\color{LightGray} { (n^{[2]},m) = (n^{[2]},n^{[1]} ) ( n^{[1]}, m) + (n^{[2]},1)} \) \(\color{LightGray} { (n^{[3]},m) = (n^{[3]},m) } \) Equations for the fourth layer: \(\textbf{Z}^{[4]} = \textbf{W}^{[3]}\textbf{A}^{[3]} + b^{[3]} \) \(\hat{Y}=\textbf{A}^{[4]} = g^{[4]}(\textbf{Z}^{[4]}) \) \(\color{LightGray} { (n^{[4]},m) = (n^{[4]},n^{[3]} ) ( n^{[3]}, m) + (n^{[4]},1)} \) \(\color{LightGray} { (n^{[4]},m)} \color{LightGray} {= (n^{[4]},1) } \) |
From equations we have written, we can see that generalized equations for layer \(l \):
|
Non – Vectorized \(z^{[l]} = \textbf{W}^{[l]}a^{[l-1]} + b^{[l]} \) \(a^{[l]} = g^{[l]}(z^{[l]}) \) Dimensions are: \((n^{[1]},1) = (n^{[l]},n^{[l-1]} ) ( n^{[l-1]}, 1) + (n^{[l]},1)\) \( (n^{[l]},1) = (n^{[l]},1) \) |
Vectorized \(\textbf{Z}^{[l]} = \textbf{W}^{[l]} \textbf{A}^{[l-1]} + b^{[l]} \) \(\textbf{A}^{[l]}= g^{[l]}(\textbf{Z}^{[l]}) \) Dimensions of these matrices are: \( (n^{[l]},m) = (n^{[l]},n^{[l-1]} ) ( n^{[l-1]}, m) + (n^{[l]},1) \) \( (n^{[l]},m) = (n^{[l]},m) \) |
In case that you are thinking how can we add \(b^{[l]}\), read about broadcasting here.
Notice that, when making a calculation for the first layer, we can also write \(z^{[1]}= \textbf{W}^{[1]}a^{[0]} + b^{[1]} \). So, instead of using \(x \) we use \(a^{[0]} \) as an activations in the input layer. \( g^{[1]} \) is activation function in the first layer. Remember that we can choose different activation functions in a Neural Network, but in a single layer we must use the same activation function, so in the output layer we have \( g^{[2]} \) as the activation function and so on.
Matrix \( \hat{Y} \) is a matrix of predictions for all input examples, so it is the output of a neural network when the input is matrix \(X \), matrix of all input examples (or a feature matrix).
We can see that there must be a \(for \) loop, going through all layers in a neural network and calculating all \(Z^{[l]} \) and \(A^{[l]}\) values (where \(l \) is a number of the layer ). Here, it is prefectly fine to use an explicit for loop.
Why deep representation?
We’ve heard that neural networks work really well for a lot of problems. However, neural networks doesn’t need only to be big. Neural Networks also need to be deep or to have a lot hidden layers.
If we are, for example, building a system for an image classification, here is what a deep neural network could be computing. The input of a neural network is a picture of a face. The first layer of the neural network could be a feature detector, or an edge detector. So, the first layer can look at the pictures and find out where are the edges in the picture. Then, in next layer those detected edges could be grouped together to form parts of faces. By putting a lot of edges it can start to detect different parts of faces. For example, we might have a low neurons trying to see if it’s finding an eye or a different neuron trying to find part of a nose. Finally, putting together eyes, nose etc. it can recognise different faces.

Example of feature detection. SImpler features are detected in the first layers and more complex features are detected in the later layers
To conclude, earlier layers of a neural network detects simpler functions (like edges), and composing them together, in the later layers of a neural network, deep neural network can compute more complex functions.
In case of trying to build a speech recognition system, the first layer could detect if a tone is going up or down or is it a white noise or a slithering sound or some other low level wave of features. In the following layer by composing low level wave forms, nural network might be abe to learn to detect basic units of sound – phonems. In the word cat phonemes are c, a and t. Composing all this together a deep neural network might be able to recognize words and maybe sentences.
So the general intuition behind everything we have said is that earlier layers learn lower level simple features and then later deep layers put together the simpler things it has detected in order to detect more complex things, so that a deep neural network can do some really complex things.
In the next post we will learn about the building blocks of a Deep Neural Network.