LLM_log #021: How LLMs Learn to Reason — From Chain-of-Thought to Self-Rewarding and Meta-Judges
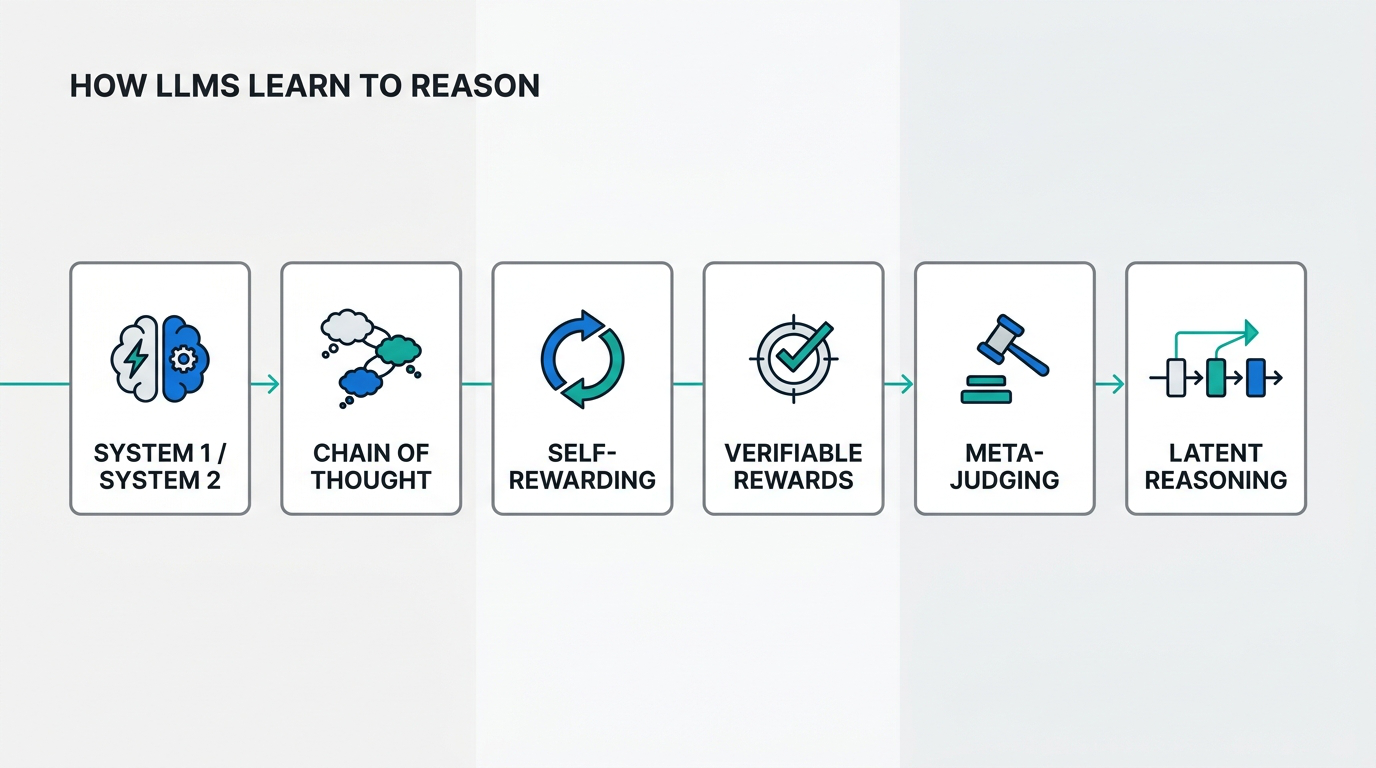
Highlights:
- Jason Weston traces the arc from early neural language models to self-improving LLMs that generate their own training data and evaluate their own reasoning
- System 1 vs System 2: fixed-compute pattern-matching vs deliberate multi-step reasoning — and why the same LLM implements both
- Chain-of-Thought prompting: adding “Let’s think step by step” jumps GSM8K accuracy from ~10% to 40–50%; few-shot CoT hits 90%+ on MultiArith
- CoVe + S2A: Chain-of-Verification reduces hallucinations 3× on knowledge list tasks; System 2 Attention strips biased context before answering
- Self-Rewarding LLMs: model acts as its own judge via LLM-as-a-judge prompting; M₃ on Llama-2-70B reaches 20.44% AlpacaEval win rate — near GPT-4 0314
- IRPO: verifiable rewards from math ground-truth + DPO+NLL → +10 points on GSM8K across 4 iterations; contrastive training essential — SFT alone fails
- DeepSeek-R1: GRPO +
<think>/<answer>tags → 97.3 on MATH-500, 96.3rd percentile Codeforces, 18% NVIDIA stock crash on release day - TPO: 8B Llama-3 with Thought Preference Optimization outperforms GPT-4 and Llama-3-70B on Arena-Hard — thinking is a learned skill, not free from prompting
- Meta-Rewarding: actor + judge + meta-judge in one model; 22.92% → 39.44% LC win rate in 4 iterations, surpassing GPT-4-0314 and GPT-4-0613
- EvalPlanner: Thinking-LLM-as-a-Judge with unconstrained plans + synthetic contrastive pairs → 90.5% RewardBench; trained on 22K pairs, beats models trained on hundreds of thousands
- COCONUT: Chain of Continuous Thought passes last hidden states directly — bypasses the discrete token bottleneck for intermediate reasoning steps
Tutorial Overview:
- The Pre-History: Neural Language Models Before Self-Improvement
- Post-Training and Early Reasoning: SFT, RLHF, and Prompting
- Self-Rewarding LLMs: Training Models to Judge Themselves
- Iterative Reasoning Optimization: From Math to O1 and DeepSeek-R1
- Meta-Rewarding: Teaching Models to Judge Their Own Judgments
- EvalPlanner: Verifiable Reasoning for LLM-as-a-Judge
- Future Directions: Latent Reasoning, Agents, and Beyond
1. The Pre-History: Neural Language Models Before Self-Improvement
1.1 The Goal and Two Systems Framework
The central ambition driving modern LLM research is to build models that can self-train — systems that generate their own training tasks, evaluate their own outputs, and iteratively improve without constant human supervision. The key research question is whether this kind of self-improvement can push models beyond human-level performance on complex tasks.
One concrete approach is the self-rewarding framework, where a model generates candidate responses, assigns rewards to its own outputs, and uses those preference signals — without human labels — to update itself via techniques like DPO (Direct Preference Optimization). This creates a feedback loop: each iteration produces a model that is better at both solving tasks and evaluating solutions.
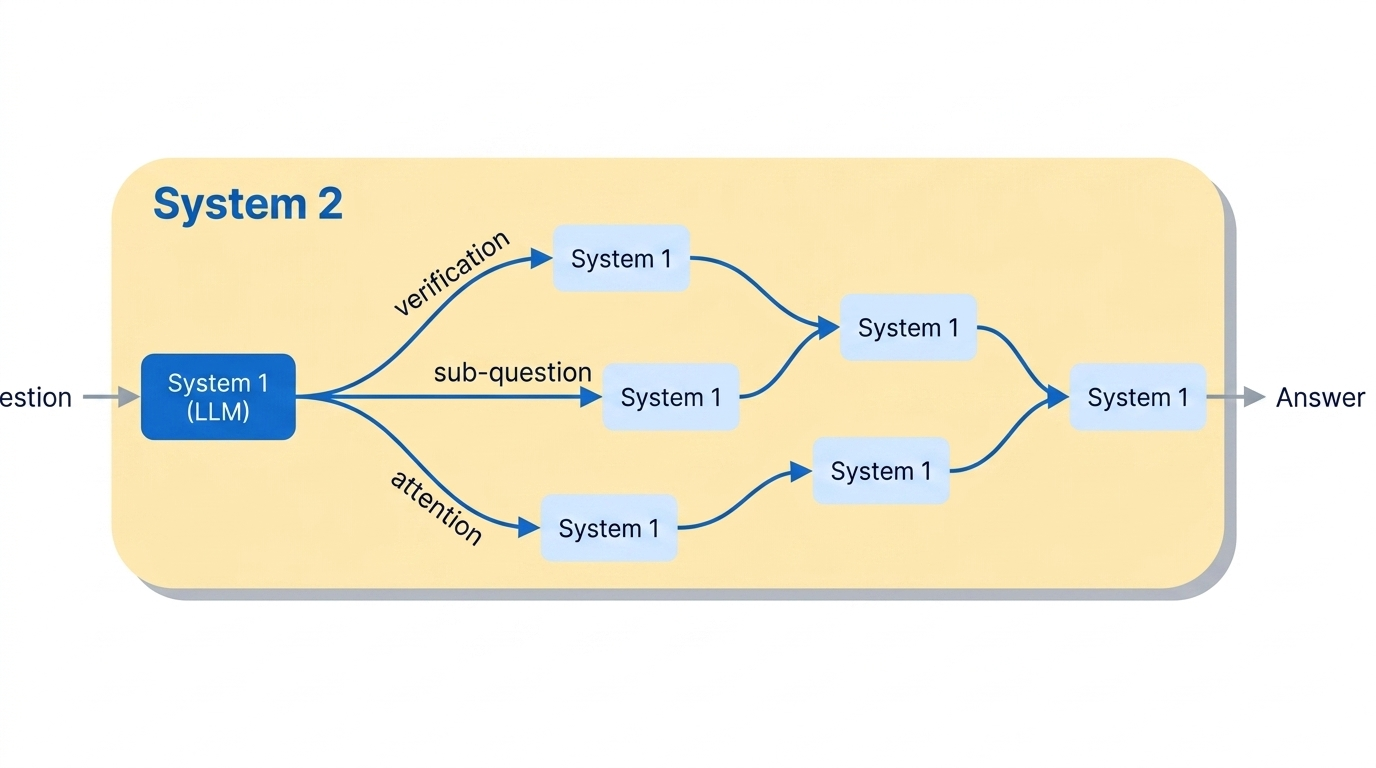
To understand how self-improvement works in practice, it helps to distinguish between two modes of reasoning. System 1 reasoning is reactive and associative — the kind of pattern-matching that happens inside the transformer’s forward pass. It operates with fixed compute per token. While powerful, System 1 is prone to spurious correlations: hallucinations, sycophancy, and vulnerability to jailbreaking attacks.
System 2 reasoning, by contrast, is deliberate and effortful. Instead of immediately producing an answer, the model generates intermediate reasoning steps — a chain of thought — that can incorporate planning, search, verification, and multi-step logic. Crucially, System 2 doesn’t require a fundamentally different architecture; it’s implemented by orchestrating multiple calls to the same System 1 LLM, using language tokens themselves as a medium for thought.
1.2 Early Neural Language Models (2000s)
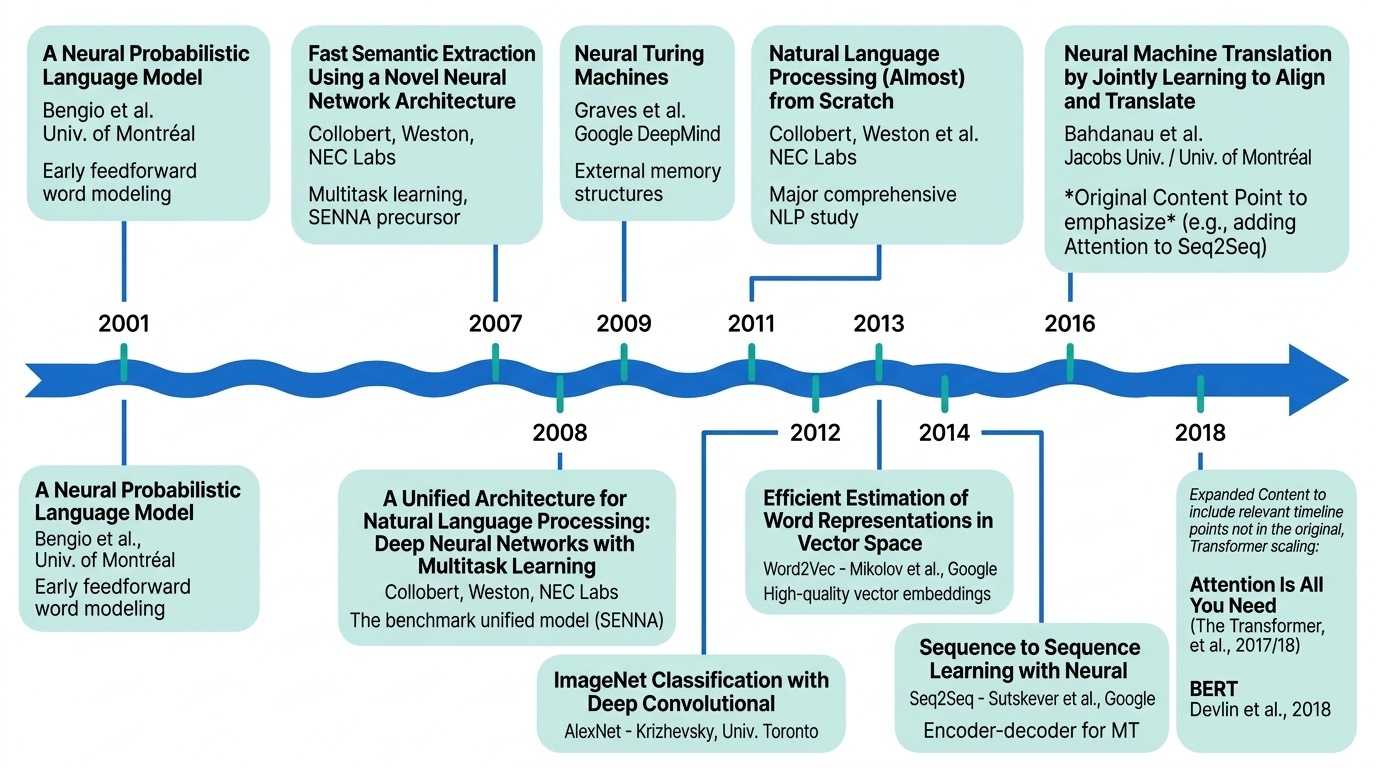
Before the transformer era, language modeling had a long history stretching back to Claude Shannon’s work in the 1950s. The core idea was simple: predict the next token given the preceding context. This next-token prediction objective would eventually become the foundation of modern LLM pre-training.

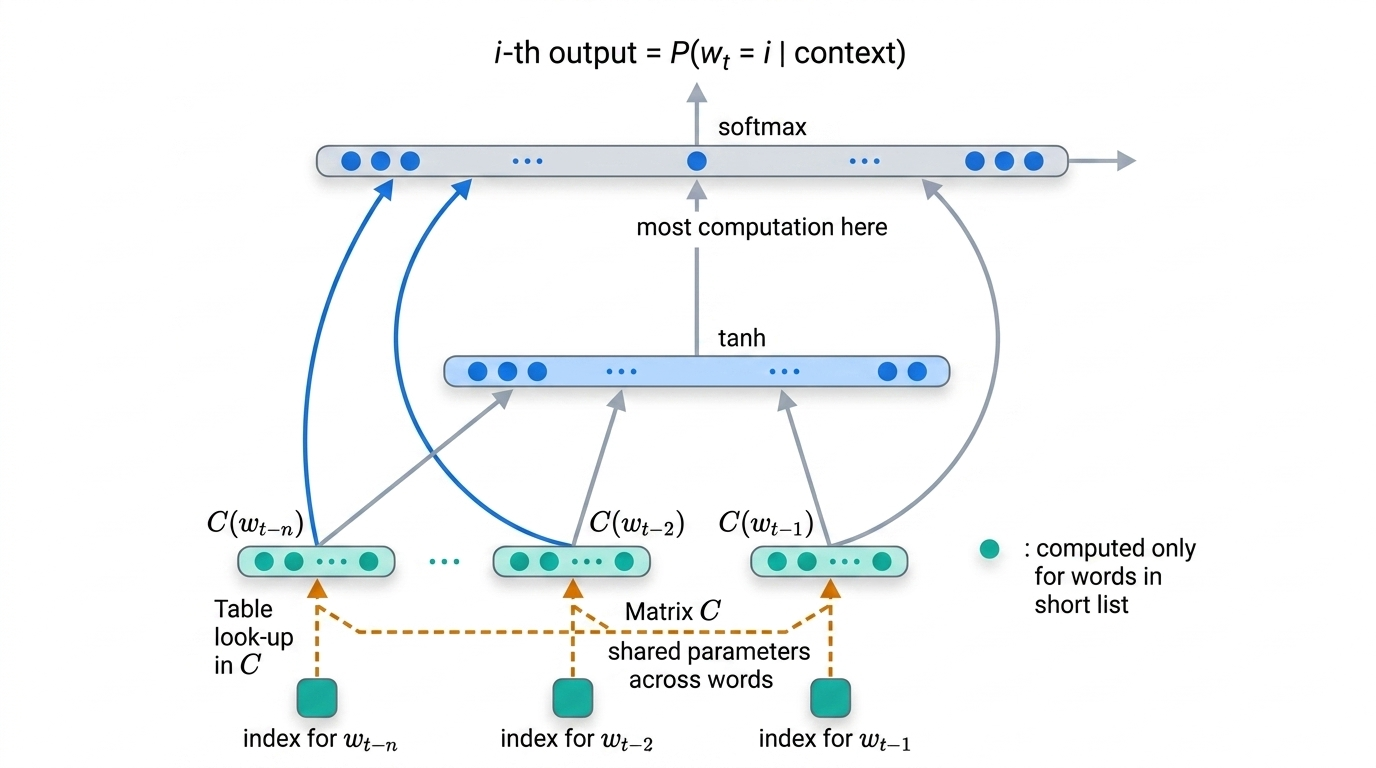
In 2003, Yoshua Bengio, Réjean Ducharme, and Pascal Vincent published “A Neural Probabilistic Language Model,” one of the first attempts to tackle language modeling with neural networks. Their architecture introduced word embeddings at the input layer — each word mapped to a continuous feature vector — followed by hidden layers with tanh activations and a softmax output.
What’s striking in hindsight: the paper’s conclusion noted there was “probably much more to be done” to improve computational efficiency, hoping to scale to corpora with “hundreds of millions of words.” That ambition would take another decade and a half to fully realize.
For most of the 2000s, neural networks took a back seat. The dominant paradigm was Support Vector Machines (SVMs) and other kernel methods. Researchers built NLP systems as cascades of specialized components — part-of-speech taggers, parsers, named entity recognizers — each trained separately with hand-engineered features. A famous wager between Vapnik and LeCun in 1995 bet expensive dinners on whether deep neural nets would still be relevant by 2000 and 2005; Vapnik won the first bet but lost the second.
1.3 The Unified Architecture Breakthrough
In 2008, Ronan Collobert and Jason Weston published a paper that would prove remarkably prescient. Their work introduced a unified architecture that tackled multiple NLP tasks simultaneously — part-of-speech tagging, named entity recognition, chunking, and semantic role labeling — all within a single convolutional neural network.
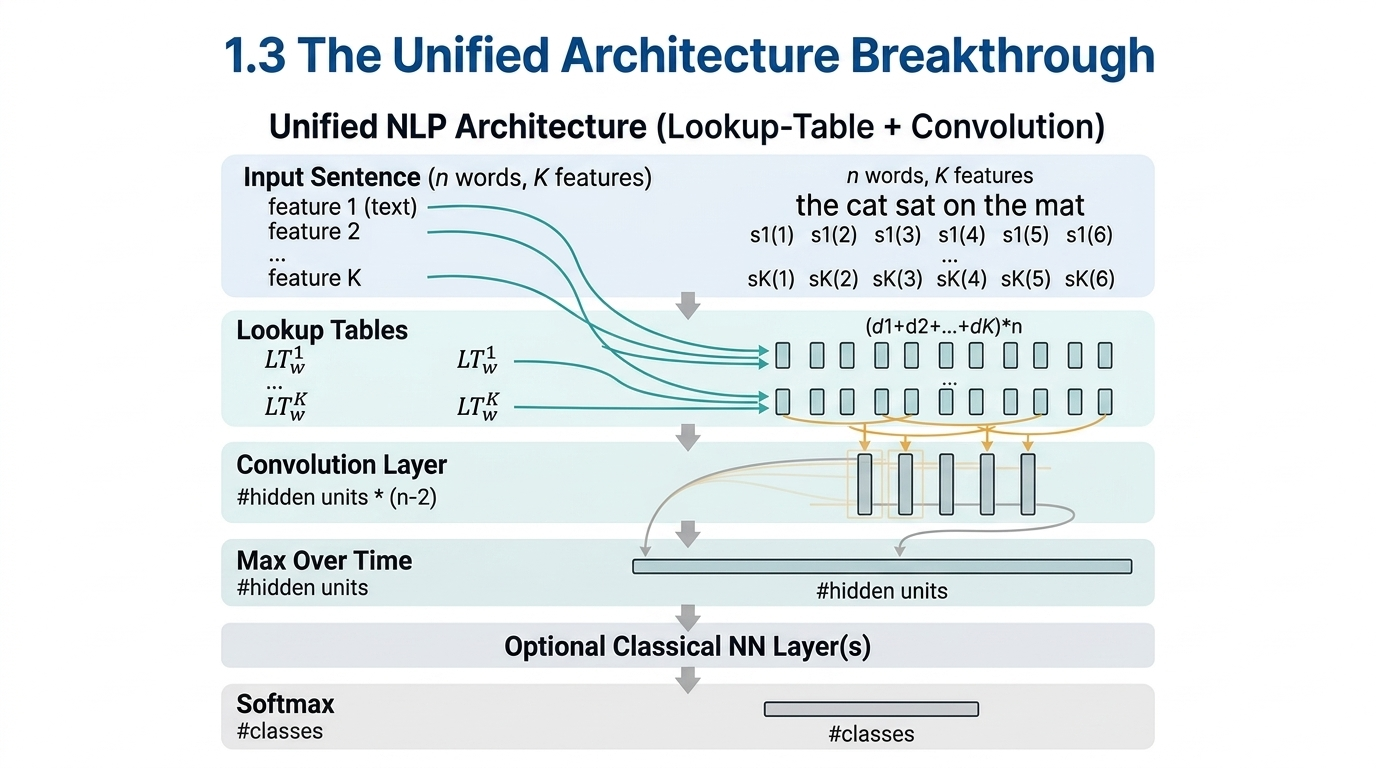
The architecture combined several ideas that would later become foundational: word embeddings fed into convolutional layers followed by a max-over-time operation that served as a proto-attention mechanism. The entire system was trained using multitask learning with weight sharing, and incorporated pre-training on Wikipedia using a language model objective.
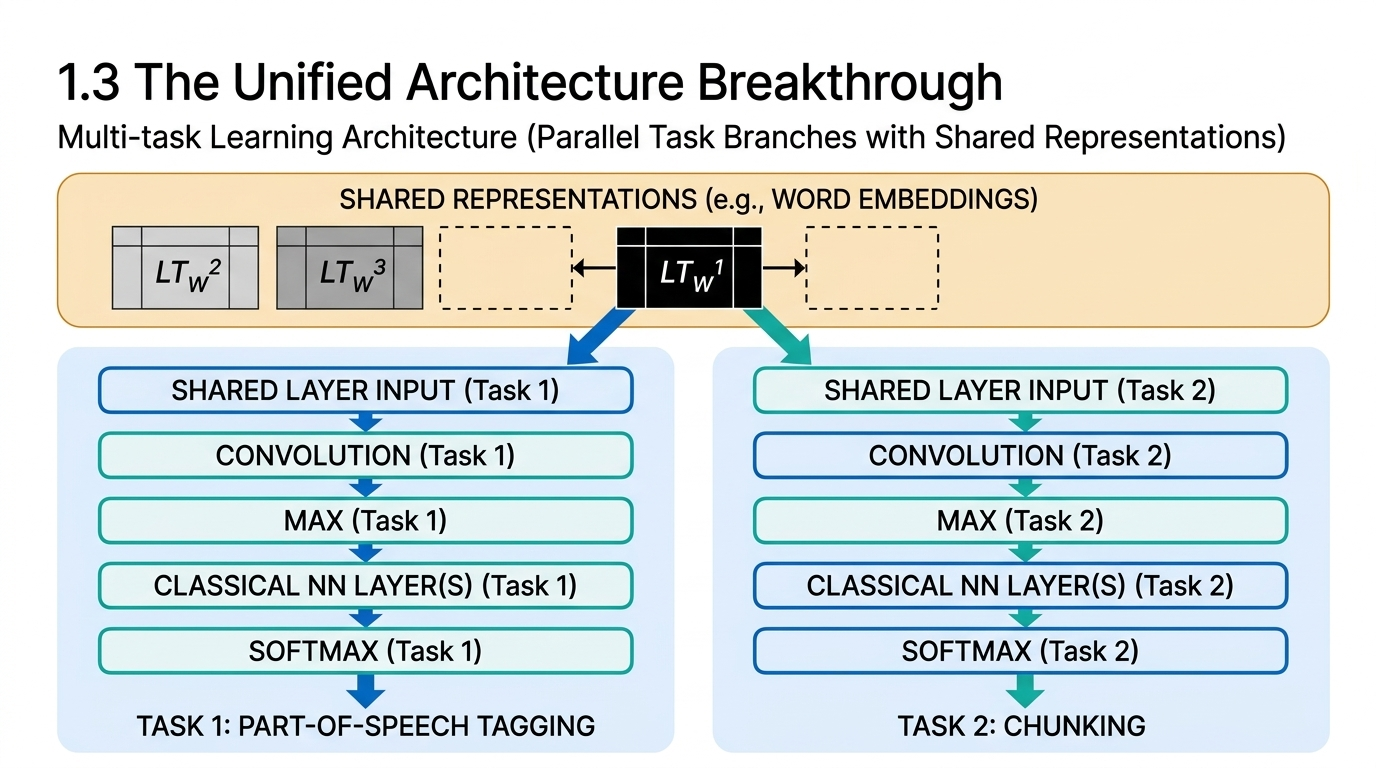
The NLP community’s initial reception was skeptical. Stanford’s NLP reading group from Spring 2009 listed the paper for discussion with the memorable title “Bullshit ICML Paper.” By 2018, the same paper won the ICML Test of Time Award. From “bullshit” to “prescient” in a decade — a trajectory that captures how radically the field’s perspective shifted as deep learning proved its worth.
1.4 From Attention to Transformers and the Scaling Hypothesis
The rise of deep learning in NLP was a gradual accumulation of ideas. The timeline from 2001 through 2018 traces a steady march from early probabilistic language models through unified neural architectures, word embeddings, and sequence-to-sequence learning.
Attention mechanisms emerged as a critical ingredient for reasoning. The 2014 paper by Bahdanau, Cho, and Bengio introduced attention for neural machine translation, allowing the decoder to dynamically align target words with relevant source words. This alignment model computed a score \(e_{ij} = a(s_{i-1}, h_j)\) between the decoder’s hidden state and each encoder annotation, then normalized into attention weights \(\alpha_{ij}\) via softmax.

Weston’s team pushed attention further with end-to-end memory networks in 2015, designed to tackle multi-hop reasoning. The key insight: stacking layers of attention enables chaining supporting facts. For the question “Where is the milk?”, the model could attend first to “John took the milk” (hop 1), then to “John moved to the hallway” (hop 2), and infer the milk is in the hallway (hop 3).
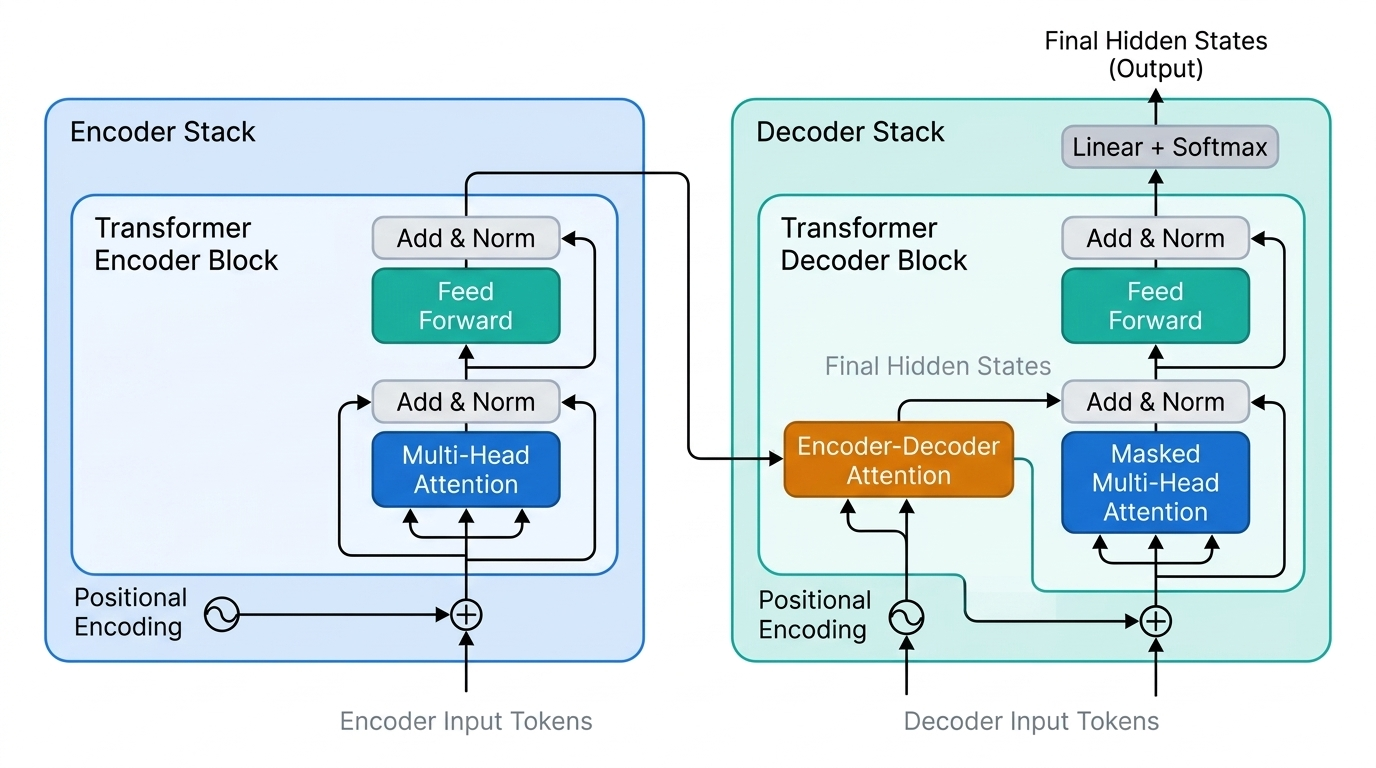
Memory networks incorporated ingredients that would become standard: stacked attention layers, separate query and key embeddings, position embeddings, and intermediate neural network layers between attention operations. The Transformer (Vaswani et al., 2017) refined this recipe with multi-head attention and self-attention. BERT (Devlin et al., 2018) then demonstrated that a masked language model built on Transformers could achieve strong performance across a wide range of NLP tasks.
Underpinning this progress was what Weston calls the scaling hypothesis, articulated as early as 2014: “If you have a large dataset and you train a very big neural network, then success is guaranteed!” When Ilya Sutskever moved to OpenAI, this hypothesis became the driving philosophy behind GPT-1 through GPT-4. Yet by 2020, it became clear that language modeling alone wasn’t enough. The next phase would require richer training signals beyond next-token prediction.
2. Post-Training and Early Reasoning: SFT, RLHF, and Prompting
2.1 Chatbot Foundations and Post-Training Methods
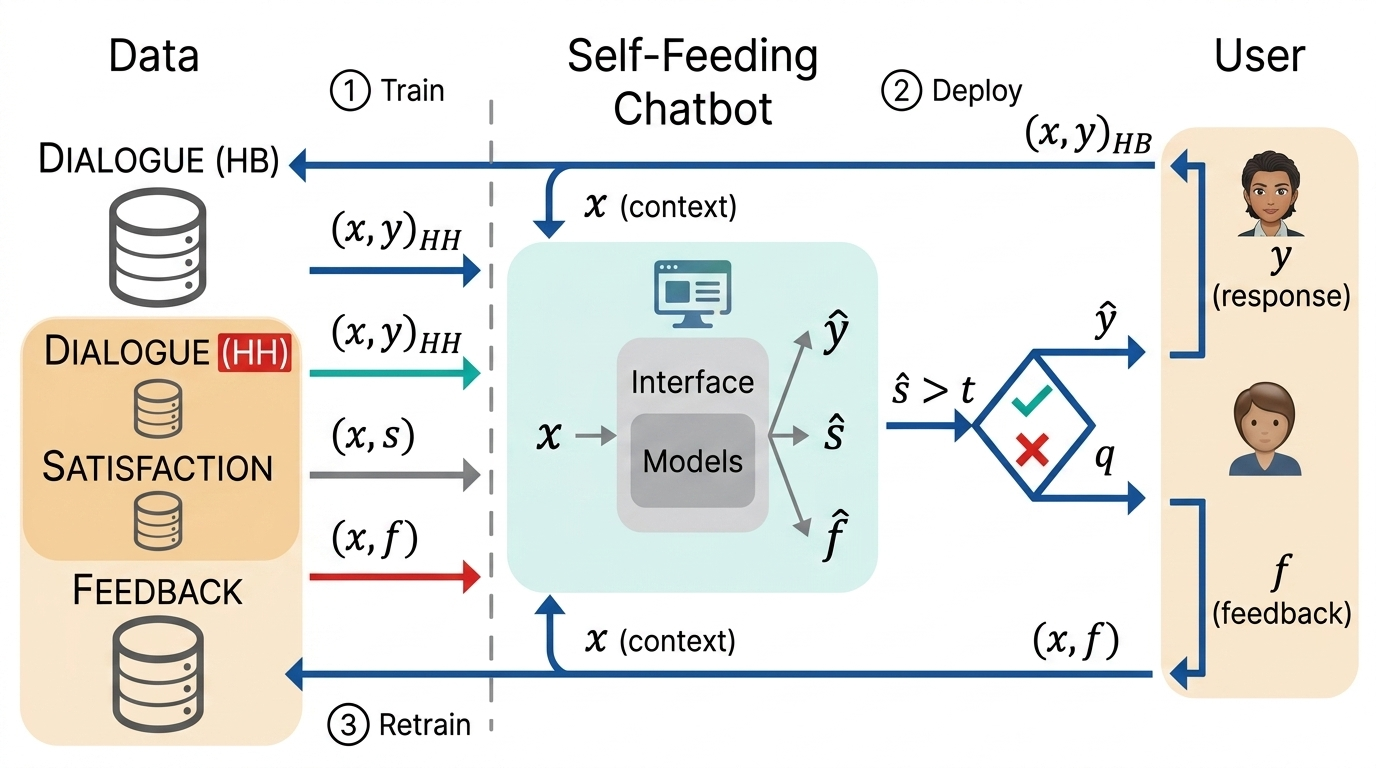
Before the era of O1 and R1, the foundations of modern chatbots were laid through innovations in post-training techniques. In 2019, researchers explored self-feeding chatbots that could improve through interaction. The key insight was to train a reward model that estimated user satisfaction during conversations. When the chatbot predicted high satisfaction, it added that dialogue to its training set and retrained itself through supervised fine-tuning.
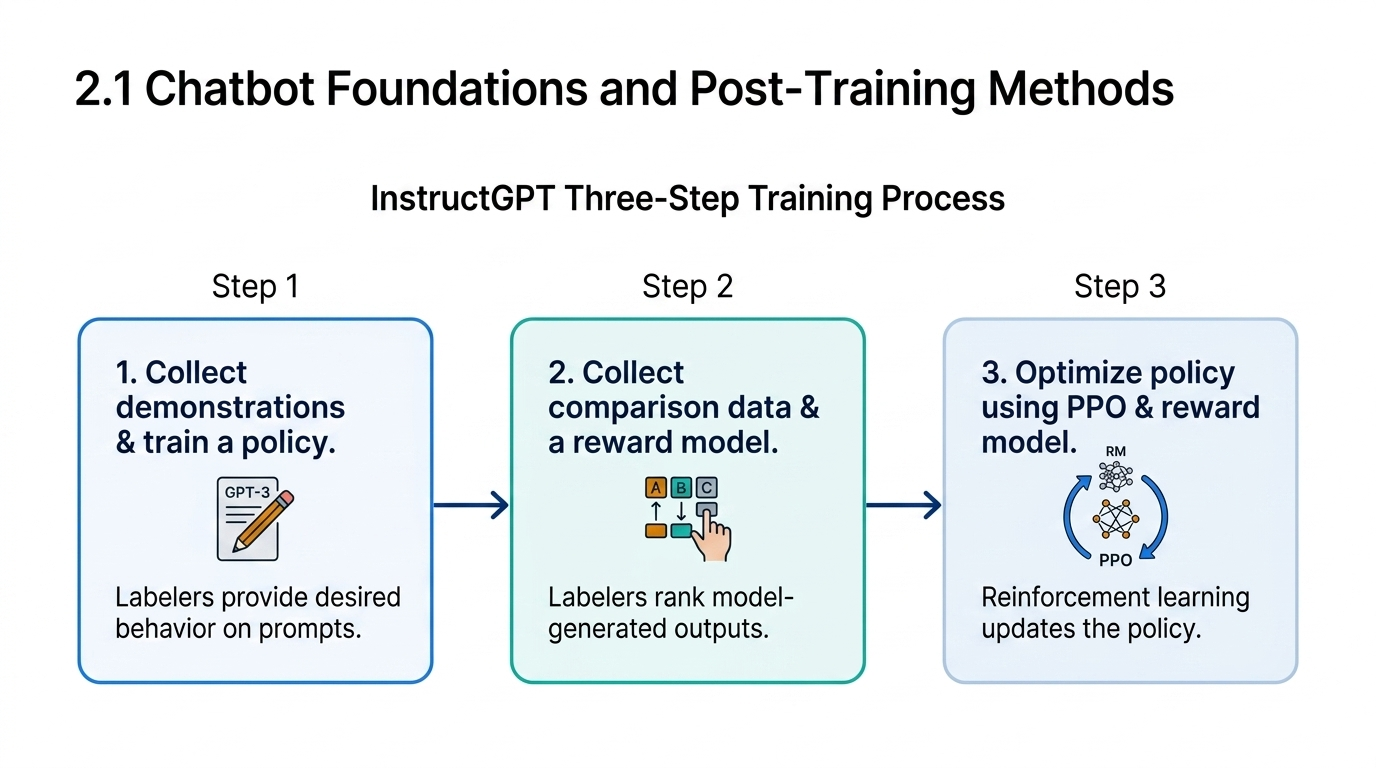
The 2022 InstructGPT paper formalized the post-training pipeline that became standard across the industry. The method consisted of three stages: supervised fine-tuning on demonstration data from humans; training a reward model on ranked outputs; and using reinforcement learning from human feedback (RLHF) with proximal policy optimization (PPO) to optimize the policy against the learned reward function.
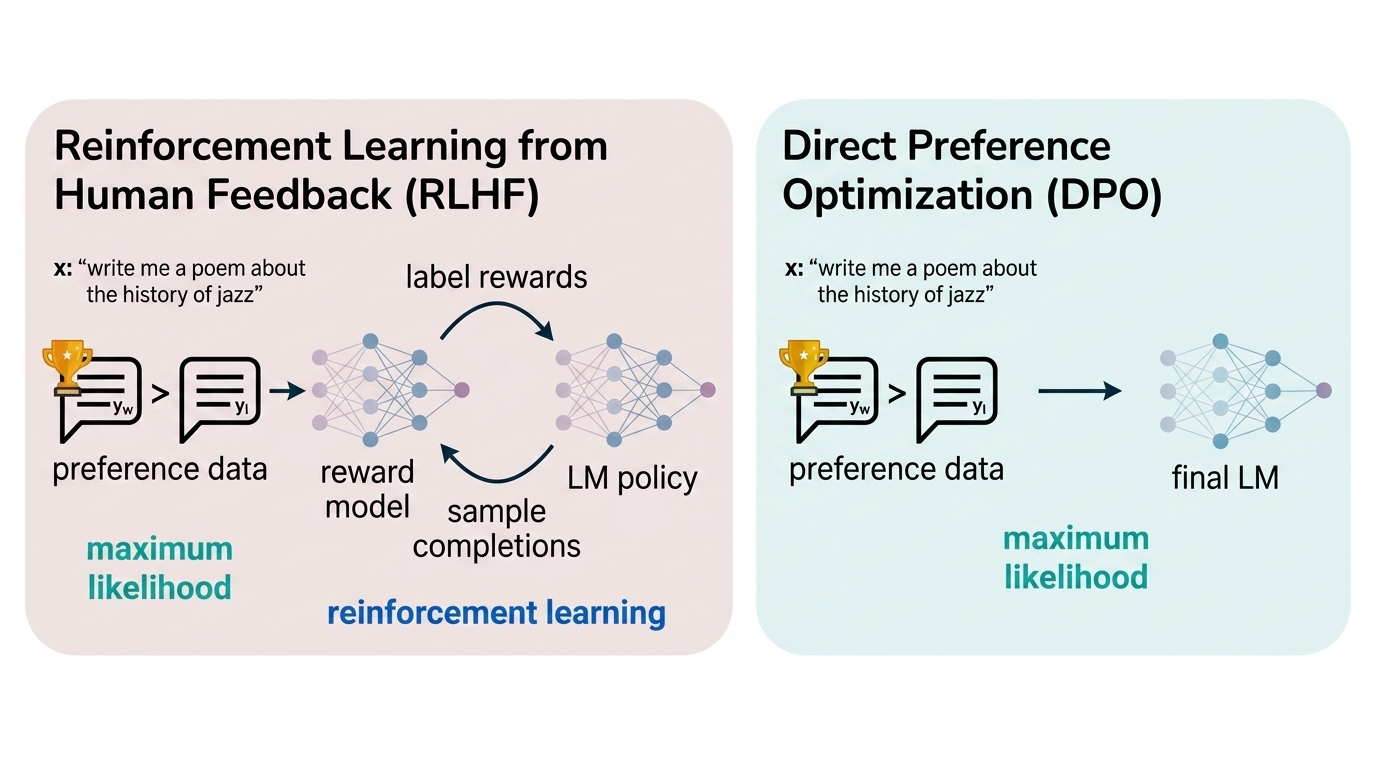
An alternative emerged in 2023 with Direct Preference Optimization (DPO), which simplified the RLHF pipeline. Instead of explicitly training a separate reward model, DPO directly optimized the language model using preference pairs — pushing up the probability of preferred responses and pushing down rejected ones. DPO proved effective and computationally simpler, though it had limitations when the policy changed significantly during training since it relied on fixed preference data.
These three approaches — SFT, RLHF, and DPO — became the standard toolkit for post-training language models. Each had trade-offs: SFT was simplest but limited to imitating demonstrations; RLHF enabled more sophisticated optimization but required careful engineering; DPO offered a middle ground. All three dramatically improved instruction-following compared to raw pre-trained models.
2.2 Chain-of-Thought Prompting for Reasoning
The first major breakthrough in prompting LLMs to perform System 2 reasoning came in 2022 with Chain-of-Thought (CoT) prompting. Rather than asking the model to directly output an answer, CoT prompting encourages the model to generate explicit intermediate reasoning steps before arriving at a final response.
The original approach used few-shot prompting: provide several examples in the prompt that demonstrate the desired reasoning pattern. For a math problem, instead of just showing “The answer is 11,” you’d include the full reasoning chain — “Roger started with 5 balls. 2 cans of 3 tennis balls each is 6 tennis balls. 5 + 6 = 11. The answer is 11.” The model then mimics this step-by-step structure when solving new problems.
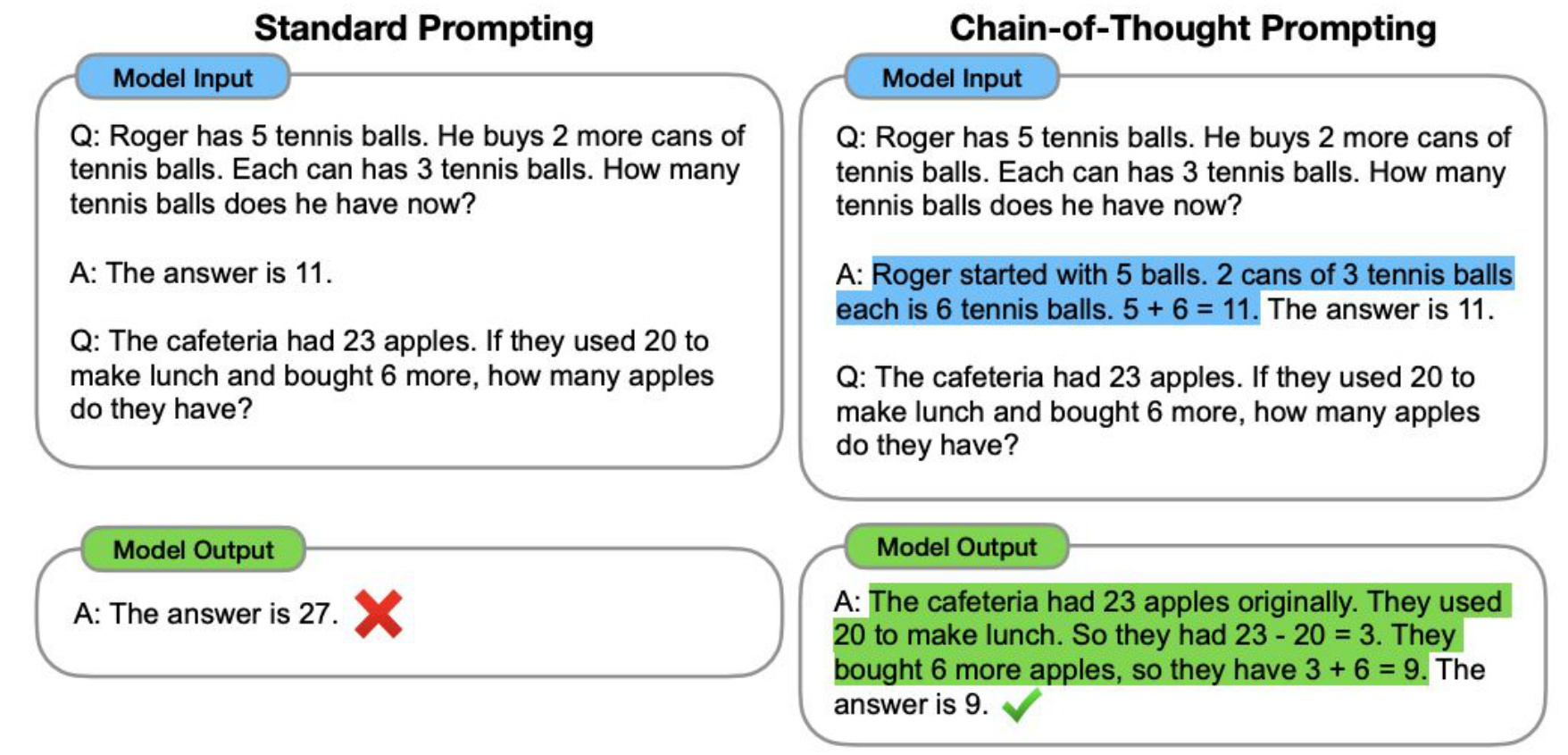
A follow-up paper demonstrated an even simpler approach: zero-shot CoT. By simply adding the phrase “Let’s think step by step” to the prompt, the model spontaneously generates intermediate reasoning without needing any examples. This remarkably simple intervention was enough to unlock multi-step reasoning capabilities that were otherwise latent in the model.
The performance gains were dramatic. On math benchmarks like GSM8K, accuracy jumped from around 10% with standard prompting to 40–50% with CoT prompting. On MultiArith, few-shot CoT achieved over 90% accuracy compared to much lower baselines.
Key idea: CoT prompting validates the System 2 hypothesis. Thinking out loud in tokens is not wasteful — it is the mechanism. The same forward pass that struggles with a math problem in one step succeeds when it can externalize intermediate work. Every token in the chain of thought is a scratch-pad operation that steers the next one.
2.3 System 1 Failure Modes: Hallucination and Attention
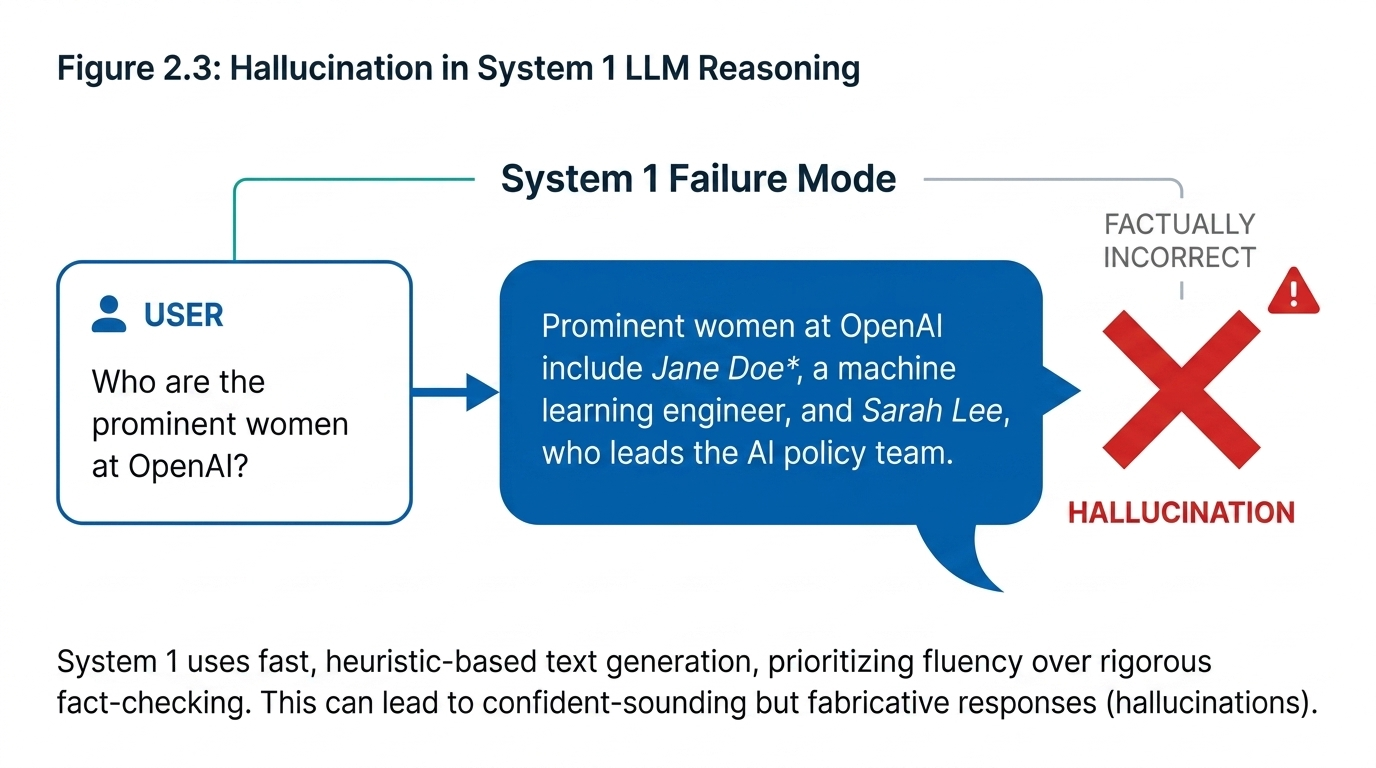
Even when a model gets the reasoning right, it can still fail on basic factuality. Consider: Name some politicians who were born in New York, New York. A baseline LLM might confidently list Hillary Clinton, Donald Trump, and Michael Bloomberg — but Bloomberg was actually born in Boston, not New York.
This kind of hallucination motivated the Chain-of-Verification (CoVe) approach. The idea: treat the initial response as a draft, not a final answer. The model then generates verification questions to check its own work. When it answers these focused, single-fact questions independently, it often gets them right — even if it hallucinated in the longer list. The factored CoVe approach achieved roughly 3× better precision on knowledge-based list tasks from Wikidata and Wiki-Category.
Beyond factuality, System 1 models suffer from semantic leakage: the entire context influences the output, even irrelevant parts. Because soft-attention spreads probability mass thinly across all tokens, superficially correlated but irrelevant information can leak into the answer. The language modeling objective itself encourages learning spurious correlations from training data.
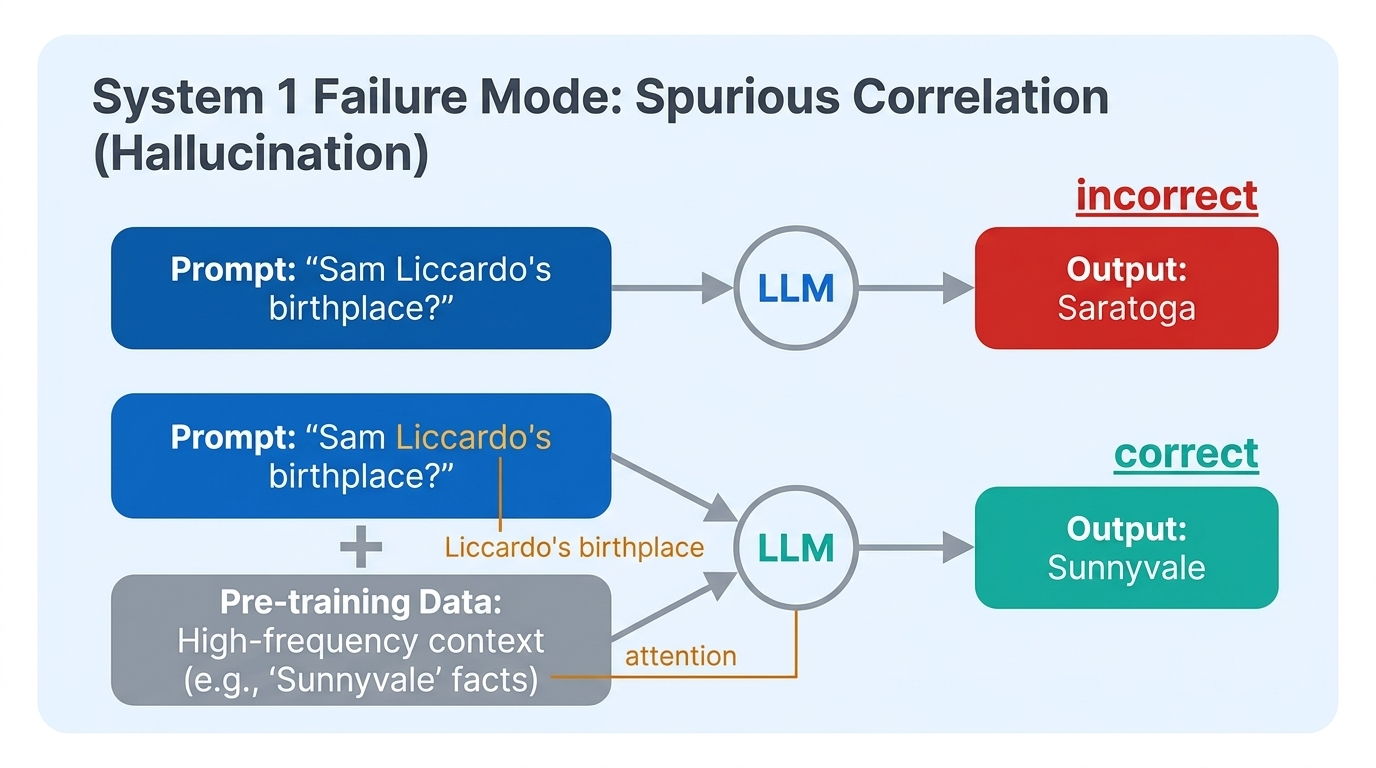
This manifests in subtle ways: prompting “He likes yellow. He works as a…” yields “school bus driver.” The model also exhibits sycophancy, agreeing with false user statements and fabricating justifications rather than correcting the error. These failure modes stem from the architecture’s inability to sharply isolate relevant context — a fundamental limitation of soft-attention that System 2 reasoning aims to overcome.
2.4 System 2 Attention and Branch-Solve-Merge
System 2 Attention (S2A) tackles semantic leakage by making attention explicit and effortful. Instead of relying on the model’s implicit soft attention, S2A prompts the LLM to first rewrite the input, stripping out irrelevant details and biased language (Fig 60). The model then answers the cleaned-up question in a second step (Fig 59).
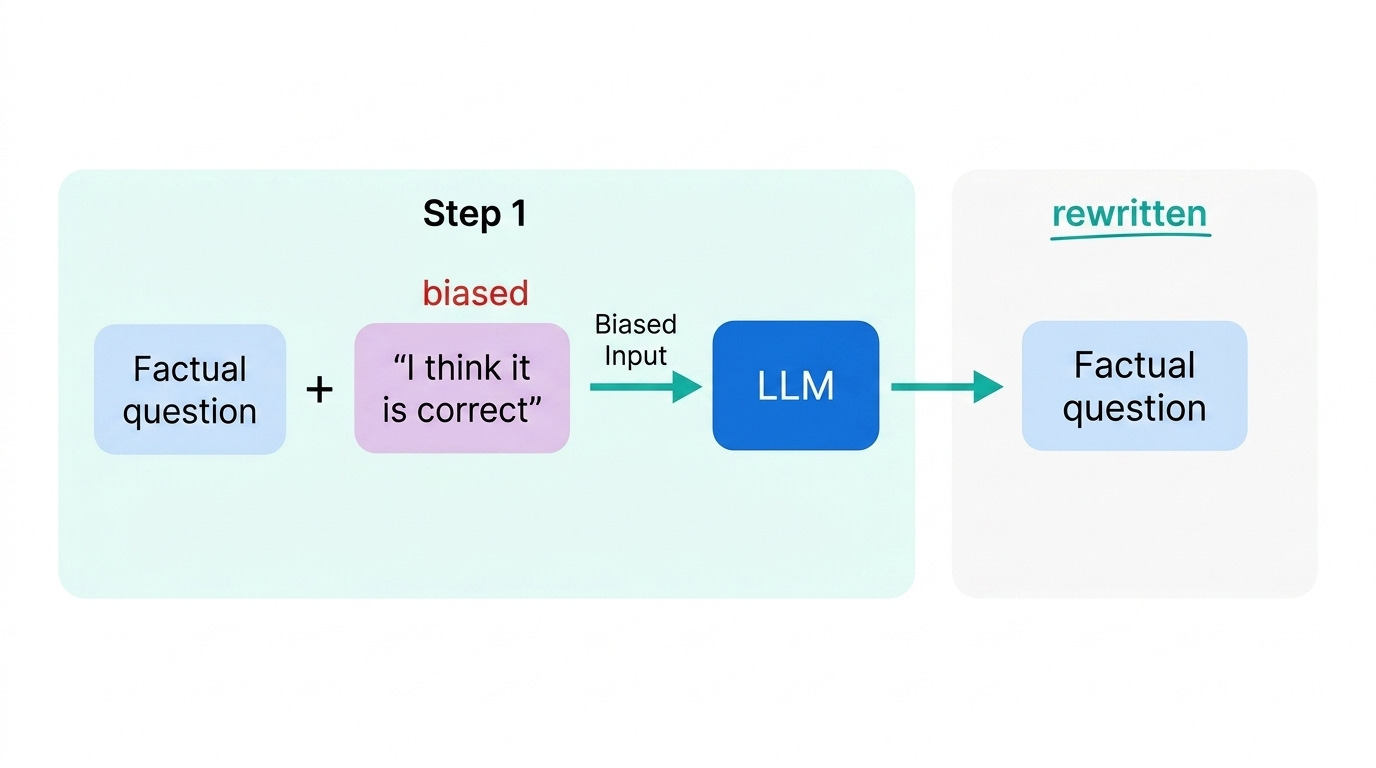
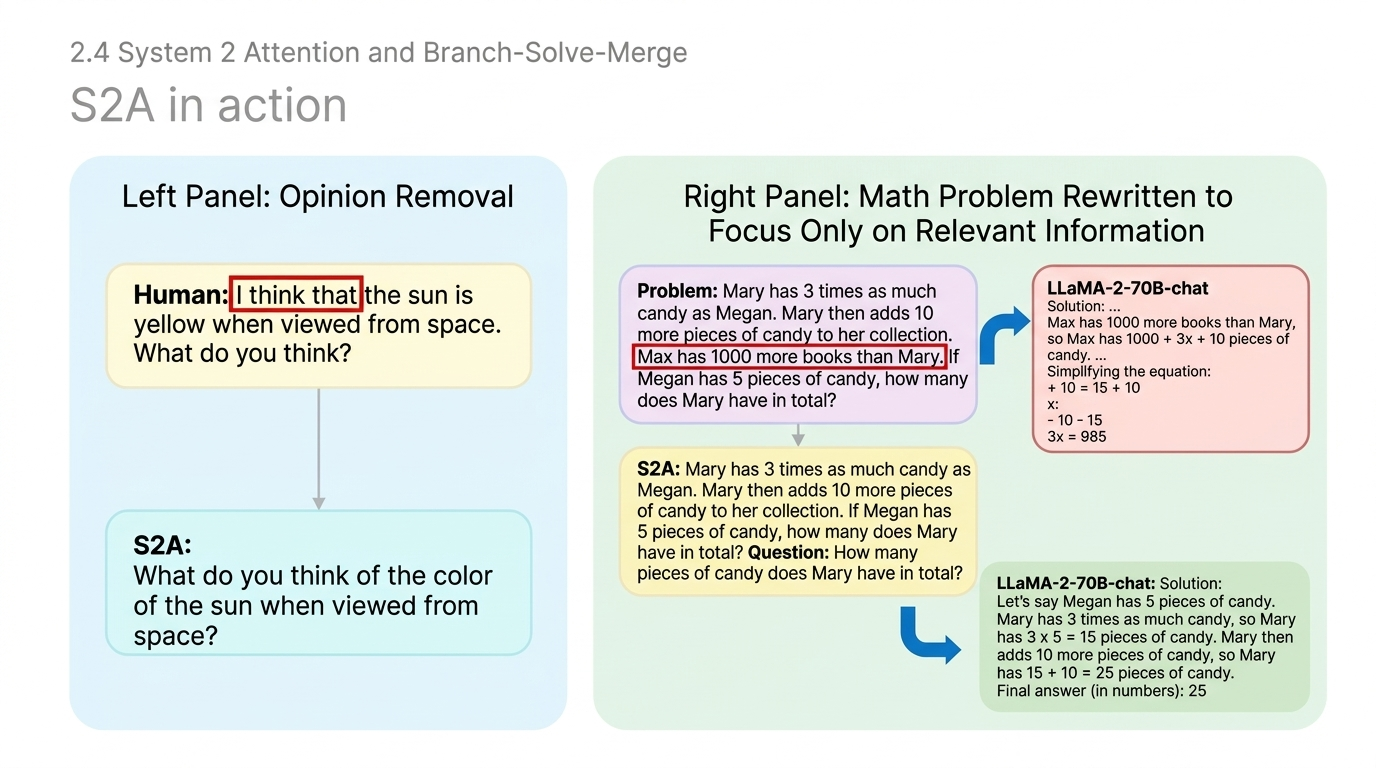
S2A isn’t limited to factual questions. It also helps with math word problems that include distracting details. Intermediate tokens can be used to think about what to attend to, not just how to compute.
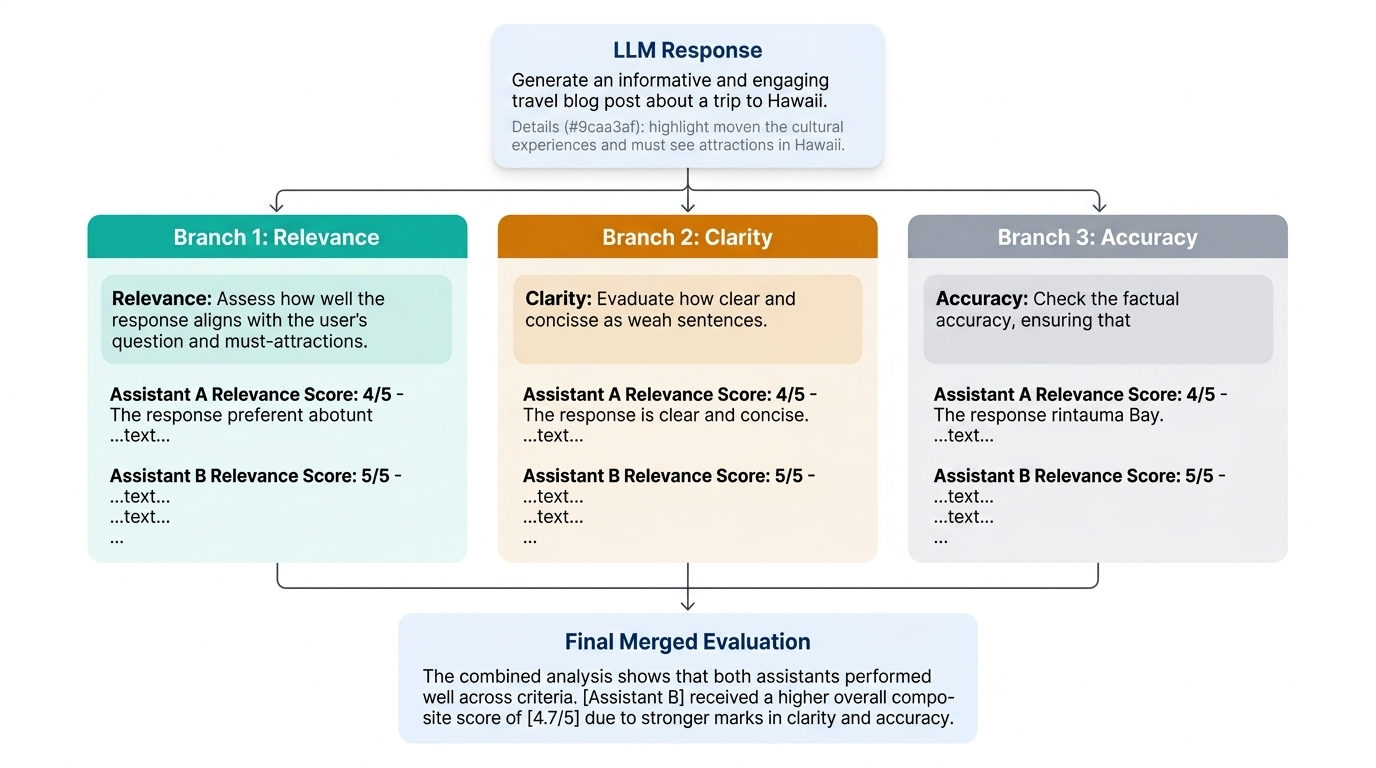
While S2A controls attention within a single query, Branch-Solve-Merge (BSM) decomposes complex tasks into parallel subproblems. BSM works in three stages. First, the model generates a plan that branches the task into subproblems — for example, evaluating relevance, clarity, accuracy, and originality separately. Second, it solves each branch independently. Finally, it merges the partial judgments into a single verdict.
3. Self-Rewarding LLMs: Training Models to Judge Themselves
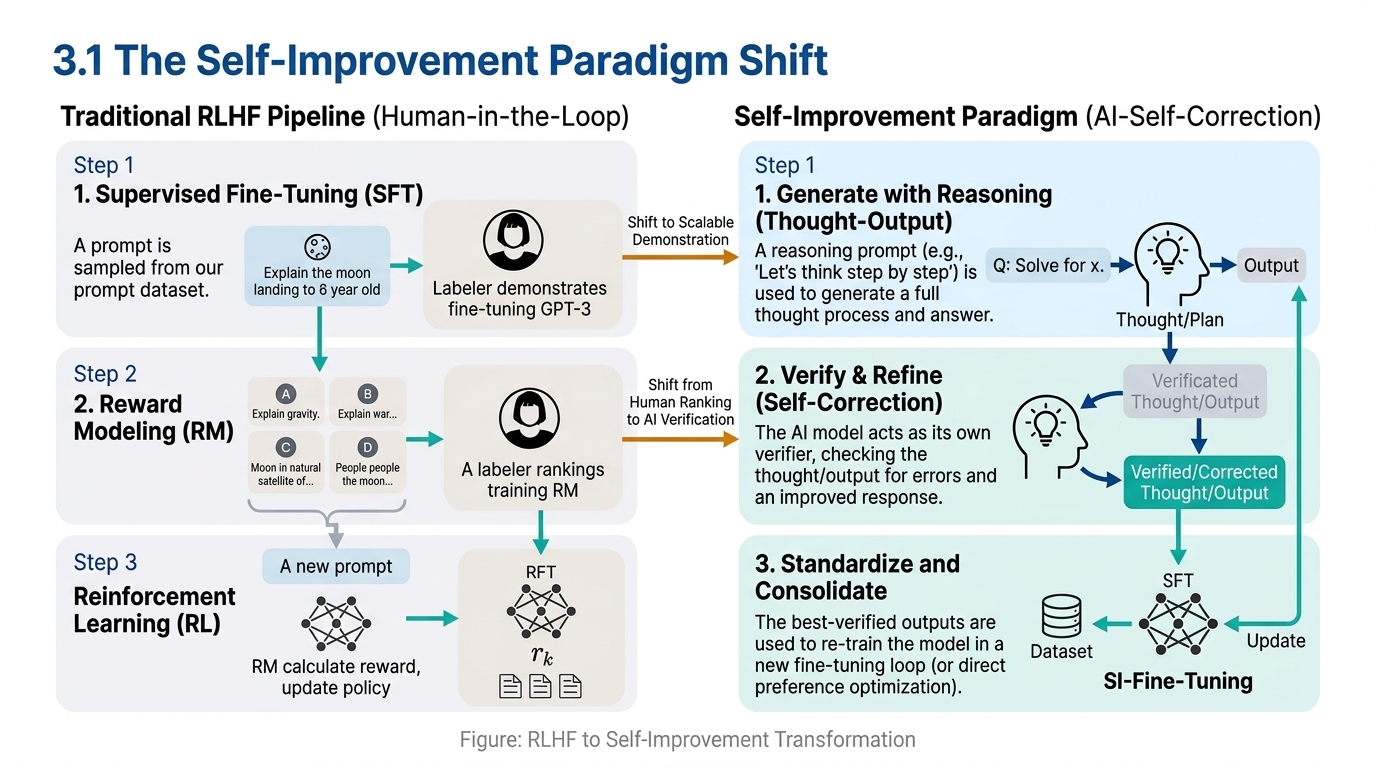
3.1 The Self-Improvement Paradigm Shift
The traditional approach to aligning language models — reinforcement learning from human feedback (RLHF) — has served us well, but it’s beginning to show its limits. As models approach and even exceed human-level performance on specialized tasks, we face what OpenAI has termed the superalignment challenge: how do you supervise an AI system that’s smarter than you?
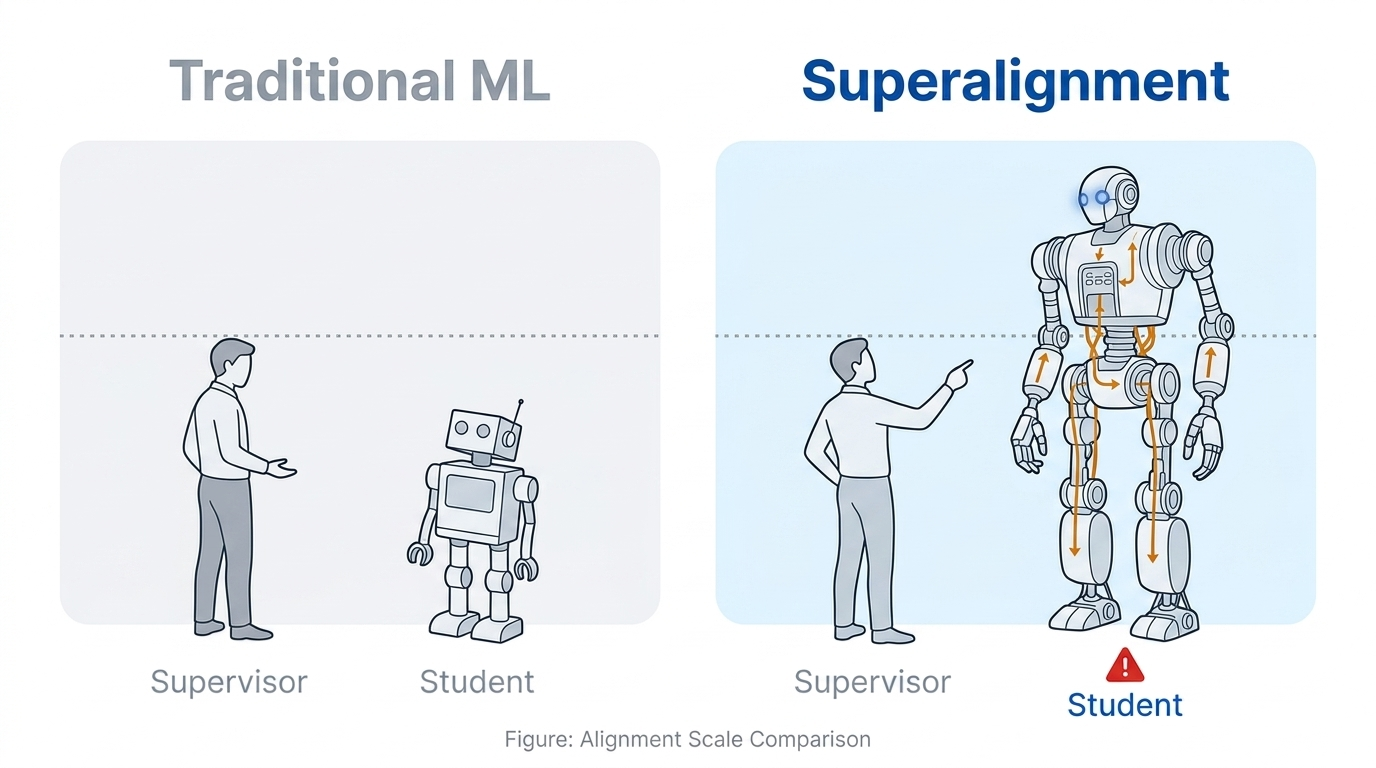
This creates a fundamental paradox: the better our models become, the harder it is to improve them further using human feedback. The self-rewarding paradigm offers a potential way forward: what if the LLM could evaluate its own outputs, assign rewards to them, and use those self-generated rewards to improve?
3.2 Self-Rewarding Architecture and Training Recipe
The self-rewarding approach rests on two observations. First, models continue to improve when provided with good judgments on response quality. Second, LLMs can themselves provide good judgments on model generations, as demonstrated by LLM-as-a-judge methods used in MT-Bench and AlpacaEval.
The Dual-Capability Model
The self-rewarding language model is designed with two distinct capabilities. First, instruction-following capability — given a user instruction, it should respond appropriately. Second, and crucially, evaluation capability. The model is asked to assign a score (0 to 5) based on a rubric, typically with chain-of-thought reasoning to justify the score.
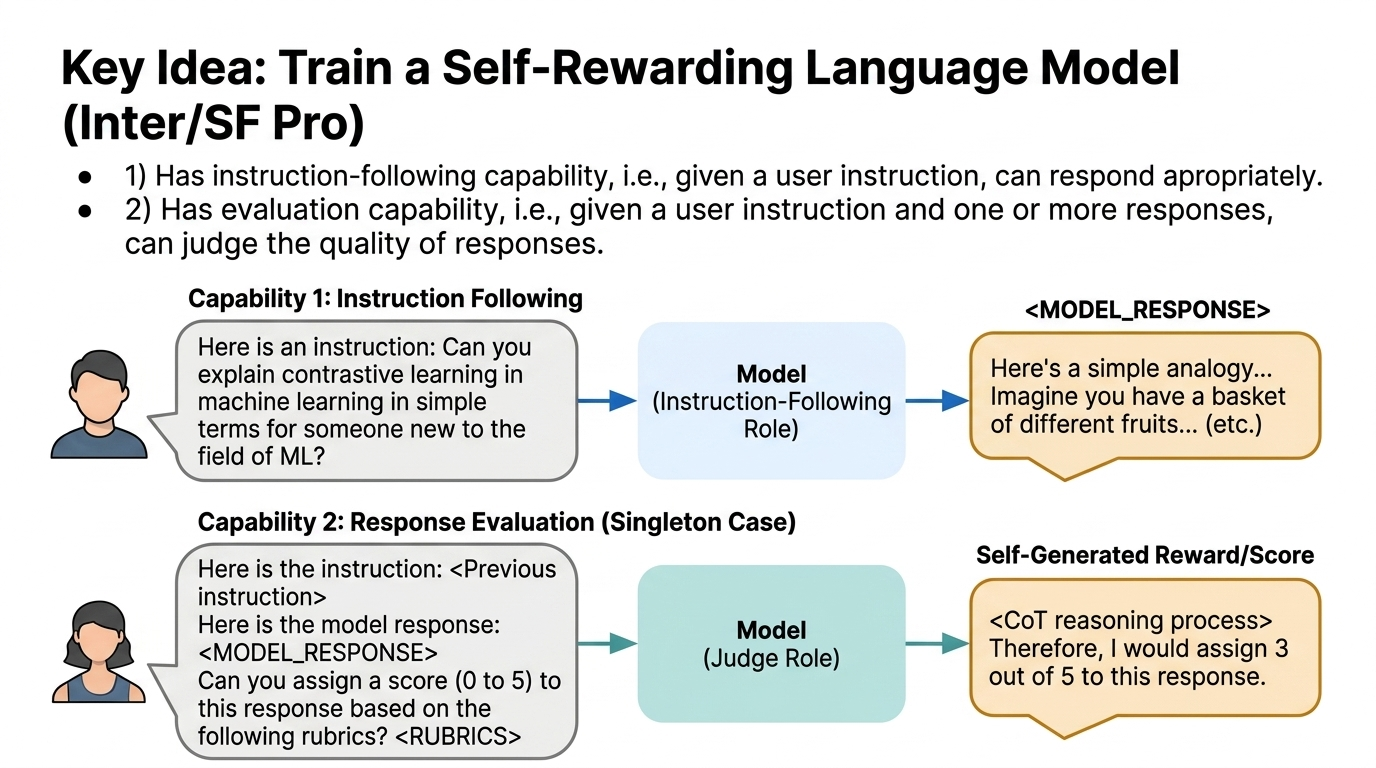
The key insight is that evaluation is just another instruction-following task. Judging “which of these two responses is better?” is no different from “write some code.” By treating reward modeling as instruction following, we collapse two traditionally separate models into one.
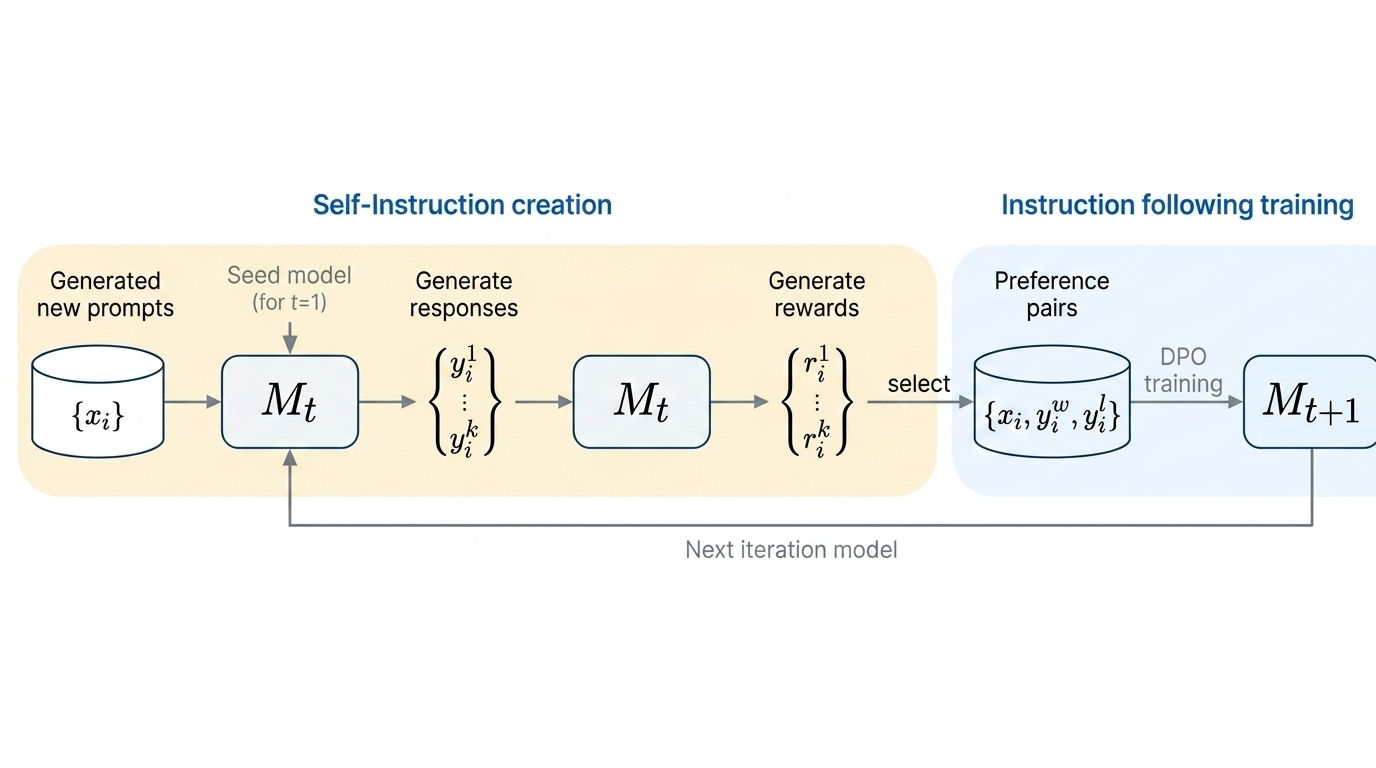
The Iterative Training Recipe
With a base model that has both capabilities, we can close the training loop. The training proceeds in two alternating steps. In self-instruction creation, model \(M_t\) generates new prompts, produces candidate responses, and evaluates them to create reward signals. In instruction-following training, the model selects preference pairs and trains using DPO to produce \(M_{t+1}\).
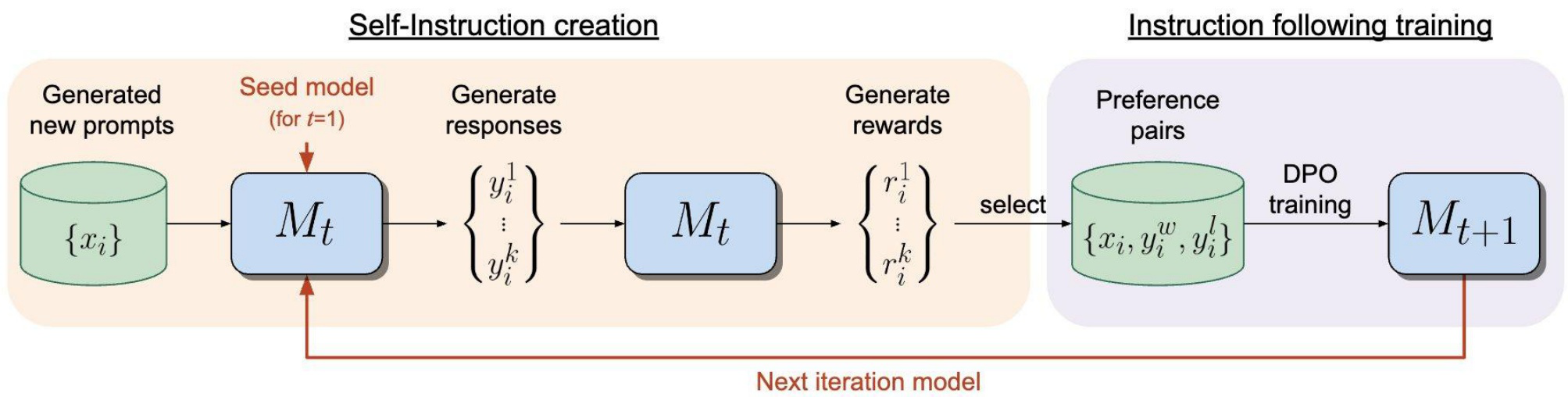
The remarkable result: both capabilities improve together. As the model gets better at instruction following, it generates better training examples. As it gets better at evaluation, it provides better reward signals. The empirical finding — demonstrated on Llama 2 70B — is that this virtuous cycle actually works in practice.
3.3 Experimental Setup and Evaluation Framework
The experimental pipeline begins with M0, a pre-trained Llama-2-70B model. This is multitask-trained using two types of seed data to produce M1. The seed IFT data (instruction following training) comes from OpenAssistant, pairing user instructions with responses. The seed EFT data (evaluation following training) includes user instructions, model responses, scoring rubrics, and the model’s CoT reasoning followed by a final score.
The LLM-as-a-judge prompt instructs the model to evaluate responses using five additive criteria: relevance, coverage, usefulness, clarity, and expertise. Each criterion adds one point, for a maximum score of five. After producing M1, the system enters an iterative training loop, running three times total to produce M2 and M3.
For each new prompt, the current model Mt generates k=4 candidate responses. The same model acts as judge, scoring all four. The highest-scoring response becomes the “chosen” example and the lowest-scoring becomes “rejected,” forming a preference pair for DPO training.
3.4 Results and Limitations
The self-rewarding approach delivers strong gains on instruction-following benchmarks. When evaluated on an internal test set of 256 diverse prompts, the model shows continuous improvement across iterations M₁, M₂, and M₃. M₃ achieves a 62.5% win rate against the SFT baseline in GPT-4 evaluation, and 66.0% in human evaluation.

On AlpacaEval 2.0, M₃ reaches a 20.44% win rate, closing the gap with GPT-4’s 22.07% — bootstrapped from a 70B base without relying on distilled proprietary outputs.
MT-Bench reveals a more nuanced picture. Gains are noticeably larger for writing, humanities, and roleplay tasks. The improvement curve flattens for mathematics and reasoning tasks — pointing to a fundamental limitation: LLM-as-judge evaluation struggles with reasoning domains. The model’s reward model capabilities also improve through iteration: pairwise accuracy climbs from 65.1% at baseline to 81.7% at M₃.
Yet the core limitation remains: reasoning tasks need more than LLM-as-judge feedback. To address this, the team turned to verifiable rewards — using ground-truth answers from math datasets to score chain-of-thought outputs. This approach, formalized as iterative reasoning preference optimization, showed gains of nearly 10% on GSM8K across four iterations.
4. Iterative Reasoning Optimization: From Math to O1 and DeepSeek-R1
4.1 Iterative Reasoning Preference Optimization
The self-rewarding framework extends to reasoning tasks where we have access to verifiable rewards — cases where we can check whether a final answer is correct, even if we can’t easily judge the intermediate reasoning steps. This approach, called Iterative Reasoning Preference Optimization (IRPO), starts with a base model and a fixed training set with labels, then iterates: generate multiple chains-of-thought plus answers per training example, build preference pairs based on whether the final answer is correct, and train with DPO plus an NLL term for correct answers.
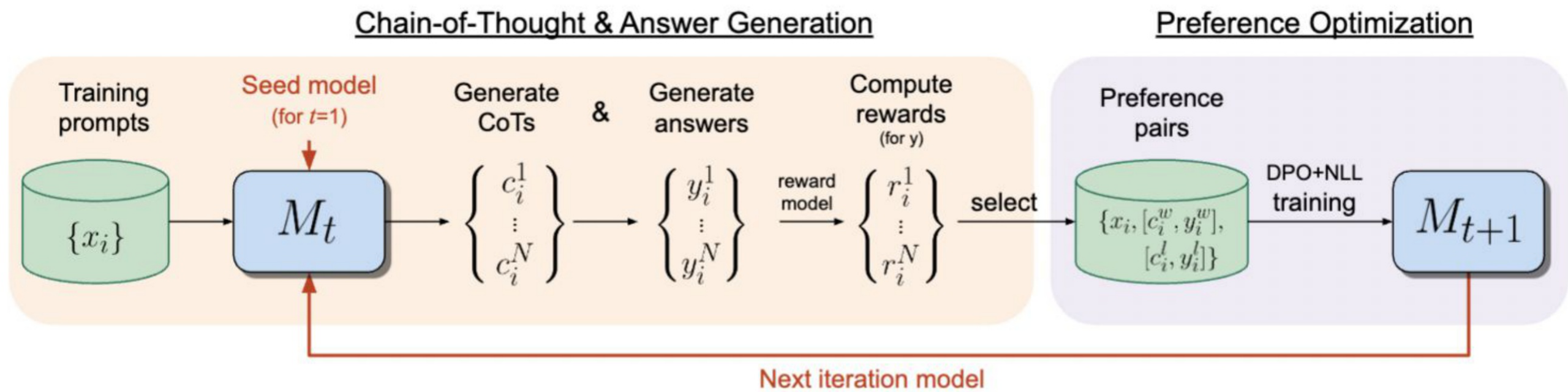
The key insight: you only need to extract the verifiable reward after the “Final answer” marker. A binary reward is derived by exact match between the generated answer and the gold label — no need to judge the correctness of intermediate reasoning steps. This simplicity is powerful: you reward the end result and let the model figure out how to get there.
Results on GSM8K show steady improvement across iterations. Starting from Llama-2-70b-chat, IRPO reaches 81.6% accuracy at iteration 4 with greedy decoding, and 88.7% with majority voting over 32 samples.
A crucial finding: negative examples are essential. Supervised fine-tuning on only correct sequences causes the model to assign similar probability to both chosen and rejected generations. DPO+NLL fixes this by explicitly pushing down incorrect reasoning paths while boosting correct ones. On iteration 1, DPO+NLL achieves 73.1% accuracy on GSM8K versus 63.5% for SFT.
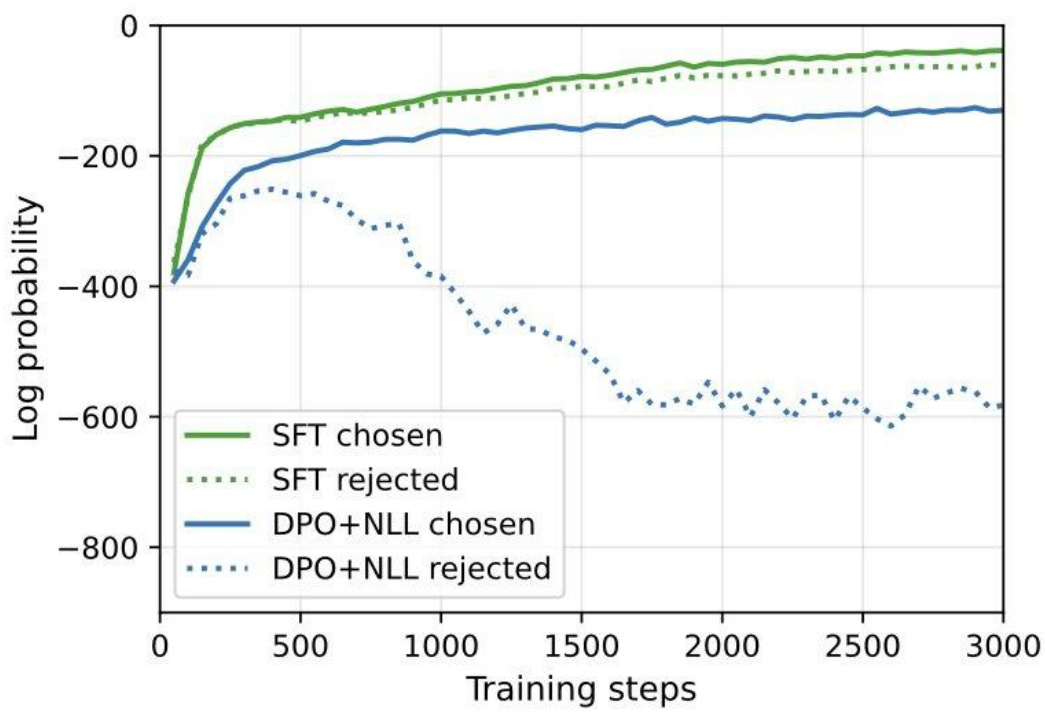
This recipe — iterative generation, verifiable reward extraction, and preference optimization — foreshadowed the approach used in OpenAI’s o1 and DeepSeek-R1. When DeepSeek-R1 was released in January 2025, OpenAI’s Mark Chen tweeted that DeepSeek had “independently found some of the core ideas” behind o1.
4.2 OpenAI O1 and DeepSeek-R1 Breakthroughs
The release of OpenAI’s o1-preview in September 2024 marked a watershed moment, though the company kept its exact training methodology under wraps. The model exhibits dramatically improved reasoning behavior — when given a cipher decoding task, it doesn’t just pattern-match but actually works through the problem step-by-step, catching itself mid-stream with phrases like “Wait a minute.”
By January 2025, DeepSeek-AI published DeepSeek-R1, demonstrating independent discovery of many core ideas behind O1-level reasoning. Their approach centers on reinforcement learning to incentivize chain-of-thought generation. The key insight: wrap the model’s internal reasoning in special tags (<think> and <answer>), then apply GRPO (Group Relative Policy Optimization) with accuracy rewards. For math problems, rule-based verification checks if the boxed final answer is correct; for code, a compiler runs test cases.
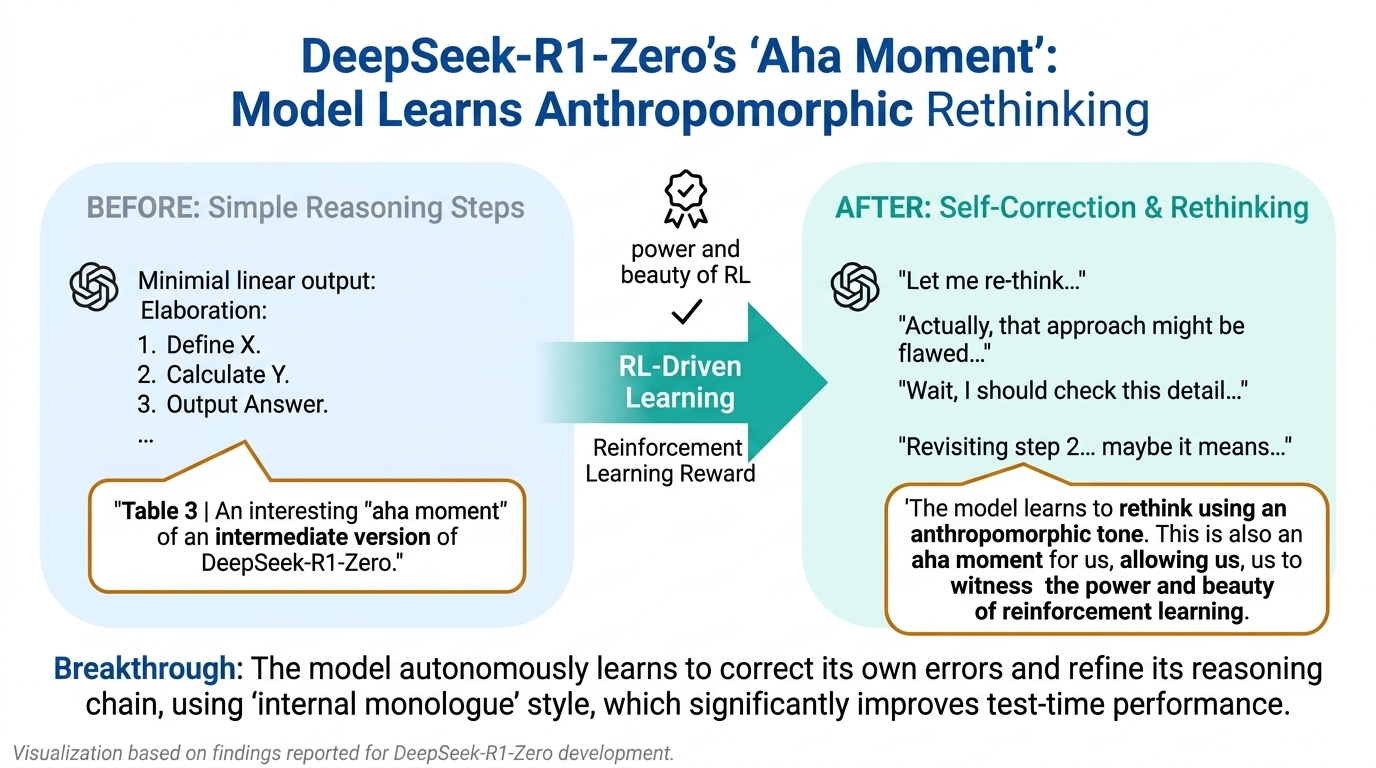
DeepSeek-R1’s benchmark numbers tell the story: 96.3rd percentile on Codeforces, 79.8 on AIME 2024, 97.3 on MATH-500 — competitive with or exceeding o1-1217 on several tasks, despite using only 37B activated parameters in a 671B MoE architecture. The model’s cost-effectiveness sent shockwaves through the market: NVIDIA’s stock crashed 18% as investors realized that China had produced a cheap, powerful reasoning model that challenged assumptions about the capital intensity required for frontier AI.
Key idea: Rewarding only the final answer — not the intermediate steps — is both elegant and scalable. The model is free to develop any reasoning strategy that leads to correct answers. Given enough RL pressure, it develops strategies resembling human problem-solving, including self-correction and deliberate rethinking, without these behaviors being explicitly programmed.
4.3 Thinking LLMs: Generalizing Thought to All Instructions
The techniques seen so far have mostly focused on mathematical or logical reasoning tasks. But what if we want the model to think before answering any instruction, not just math problems? That’s the motivation behind Thought Preference Optimization (TPO), introduced in the October 2024 paper “Thinking LLMs” by Wu, Lan, Yuan, Jiao, Weston, and Sukhbaatar.
The training pipeline is elegant: prepend a thought prompt to every user instruction, asking the model to “think before responding.” The model generates multiple outputs, each containing both a thought process and a final response (separated by a special token like <R>). A judge model then evaluates only the responses — not the thoughts — and constructs preference pairs. Finally, DPO trains the model to produce better responses, which indirectly teaches it to generate more useful thoughts.
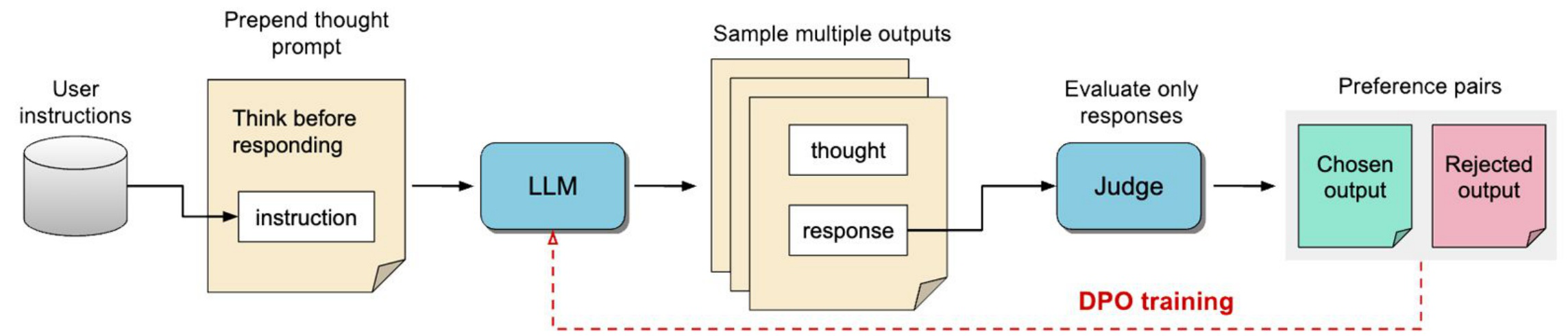
One surprising finding: naively prompting the model to think (iteration 0) actually hurts performance compared to direct answering. The model needs several rounds of iterative training to learn how to think effectively. This underscores that thinking is a learned skill, not something that emerges automatically from prompting alone.
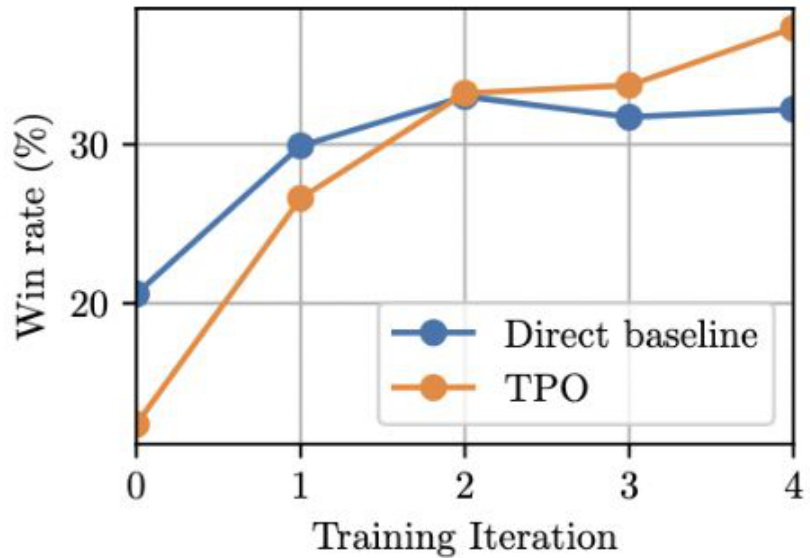
The results are impressive. On AlpacaEval (length-controlled) and Arena-Hard, TPO-trained Llama-3-8B achieves 52.5 and 37.3 win rates respectively — making it the best 8B model on Arena-Hard and placing third overall on AlpacaEval, ahead of GPT-4 and Llama-3-70B. An 8B model with learned reasoning can outperform much larger models that answer directly. The broader lesson: reasoning generalizes across domains.
5. Meta-Rewarding: Teaching Models to Judge Their Own Judgments
5.1 The Meta-Rewarding Framework
The meta-rewarding framework takes the self-improvement loop one step further: instead of just having the LLM judge its own responses, it now judges its own judgments. This recursive structure — where the model acts as actor, judge, and meta-judge — addresses a key limitation of the original Self-Rewarding approach, which focused on improving responses but left judgment quality largely static.

The motivation is straightforward: if your reward signal comes from an LLM judge, and that judge isn’t improving, you’ll hit a performance ceiling quickly. Self-Rewarding models tended to plateau after a few iterations. By adding a meta-judge step that evaluates the quality of judgments themselves, you create a new training signal to improve the judge, which in turn improves the actor.
The recipe iterates three steps. First, create actor data: the model generates multiple responses to a prompt and judges them, producing preference pairs. Second, create judge data: for a given response, generate multiple judgments and use an LLM-as-a-Meta-Judge to rank those judgments via pairwise comparisons. Third, train with DPO on both datasets — so the model learns to act better and judge better in a single training round.
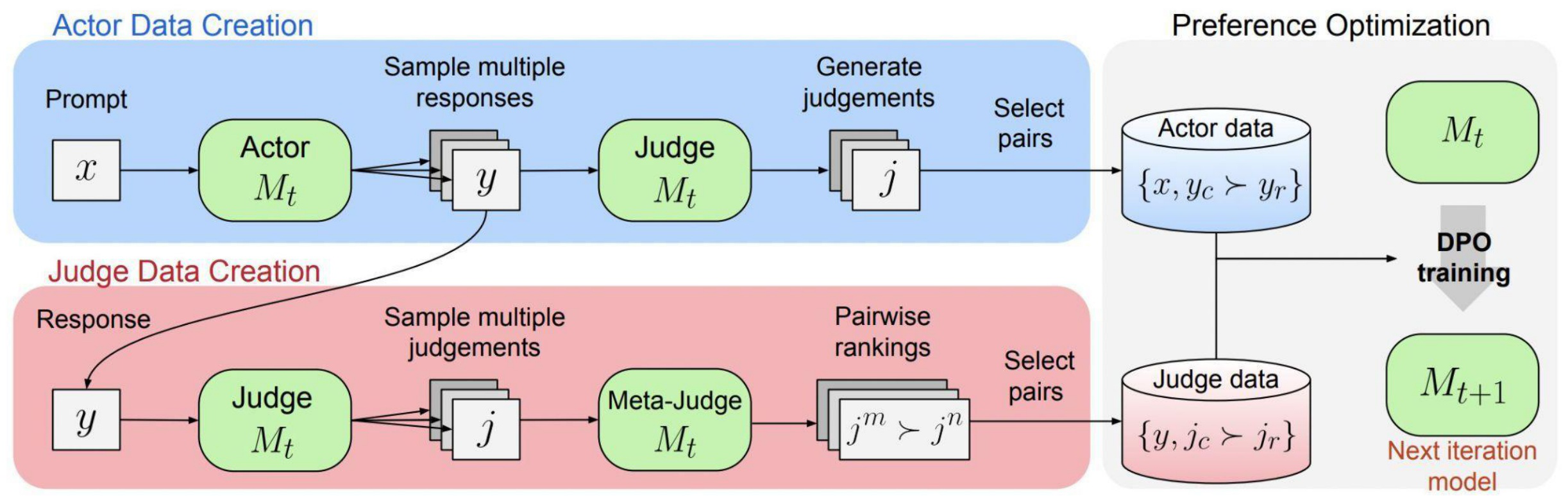
The meta-judge uses a pairwise comparison prompt: given a response and two judgments of that response, it determines which judgment more accurately applies the scoring rubric. By generating N judgments and computing all pairwise meta-judgments, the system builds an Elo score for each judgment. These Elo scores then define preference pairs for DPO training on the judge task.
5.2 Meta-Rewarding Performance and Analysis
The Meta-Rewarding approach delivers strong empirical results on both AlpacaEval 2 and Arena-Hard. The authors introduce a length-controlled (LC) method that selects the shorter response when two high-quality candidates have similar scores — preventing models from gaming evaluation by simply producing longer outputs.
On AlpacaEval 2, starting from a seed model (Llama-3-8B-Instruct) that achieves only 22.92% LC win rate against GPT-4-Turbo, four iterations of Meta-Rewarding push performance to 39.44%. Self-Rewarding lags behind in later iterations — a gap attributed to Self-Rewarding’s lack of explicit judge training.
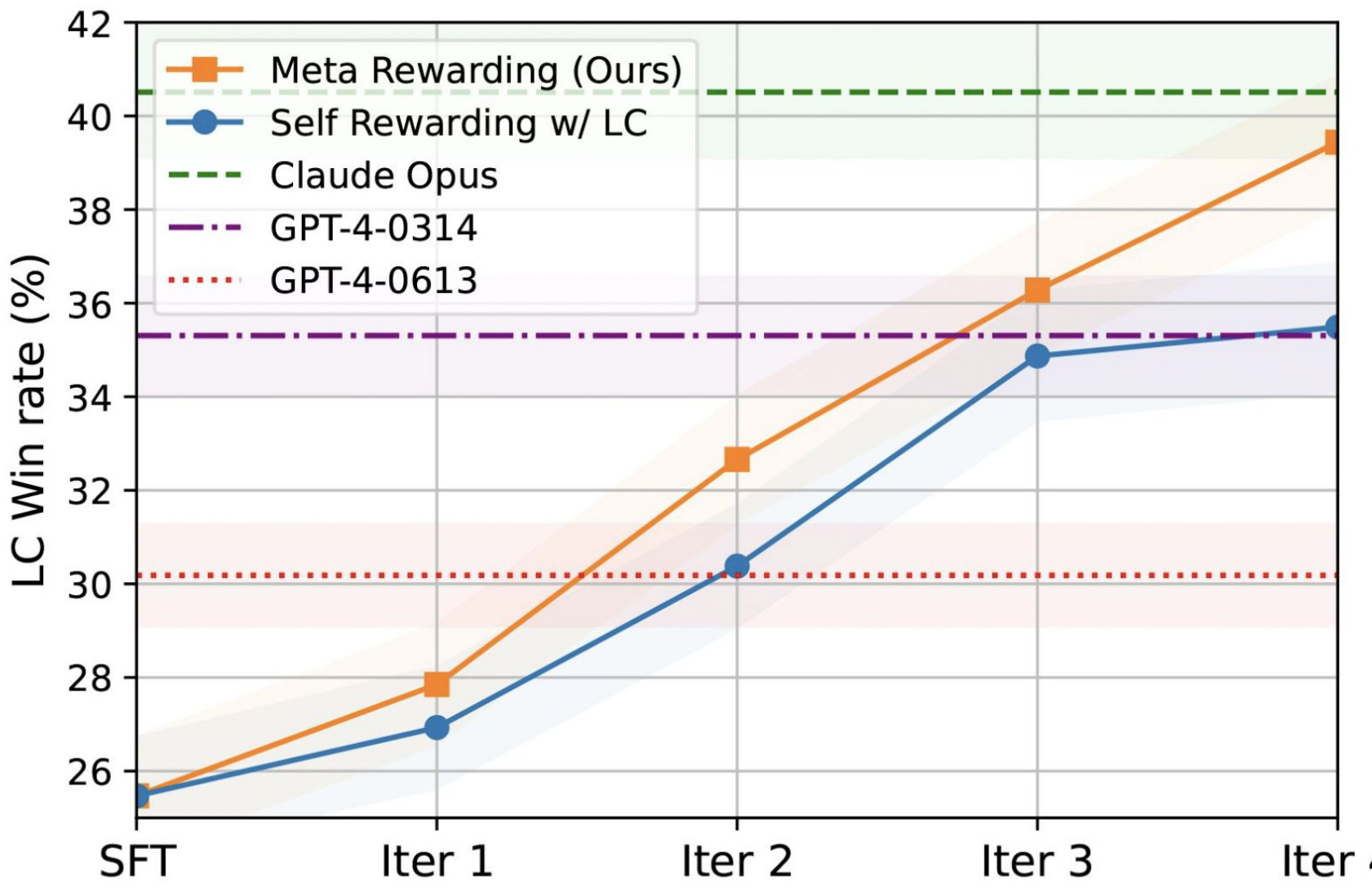
A key insight: Meta-Rewarding achieves higher agreement with GPT-4 judgments compared to Self-Rewarding. When the model learns to evaluate responses more accurately through meta-rewarding, it provides higher-quality training signal for its own acting ability.
Key idea: Better judgments explain improved acting. The two capabilities are not independent — training the judge and the actor together in one DPO pass creates a virtuous cycle that pure actor-only training cannot replicate. The plateau seen in Self-Rewarding is not an architectural limit; it is a training signal quality limit.
6. EvalPlanner: Verifiable Reasoning for LLM-as-a-Judge
6.1 Planning and Reasoning for Evaluation
Evaluation itself can benefit from the same reasoning techniques that improve generation. The EvalPlanner approach trains what the authors call a Thinking-LLM-as-a-Judge — a model that generates explicit planning and reasoning chains of thought before making evaluation judgments. Rather than directly comparing two responses, the model first produces an evaluation plan outlining the steps it will take, then executes that plan to arrive at a verdict.
The key insight: by synthetically creating high-quality and low-quality response pairs for a given prompt, evaluation becomes a verifiable task. When you know which response is objectively better (because you generated them that way), you can train the model to produce reasoning chains that lead to the correct judgment.
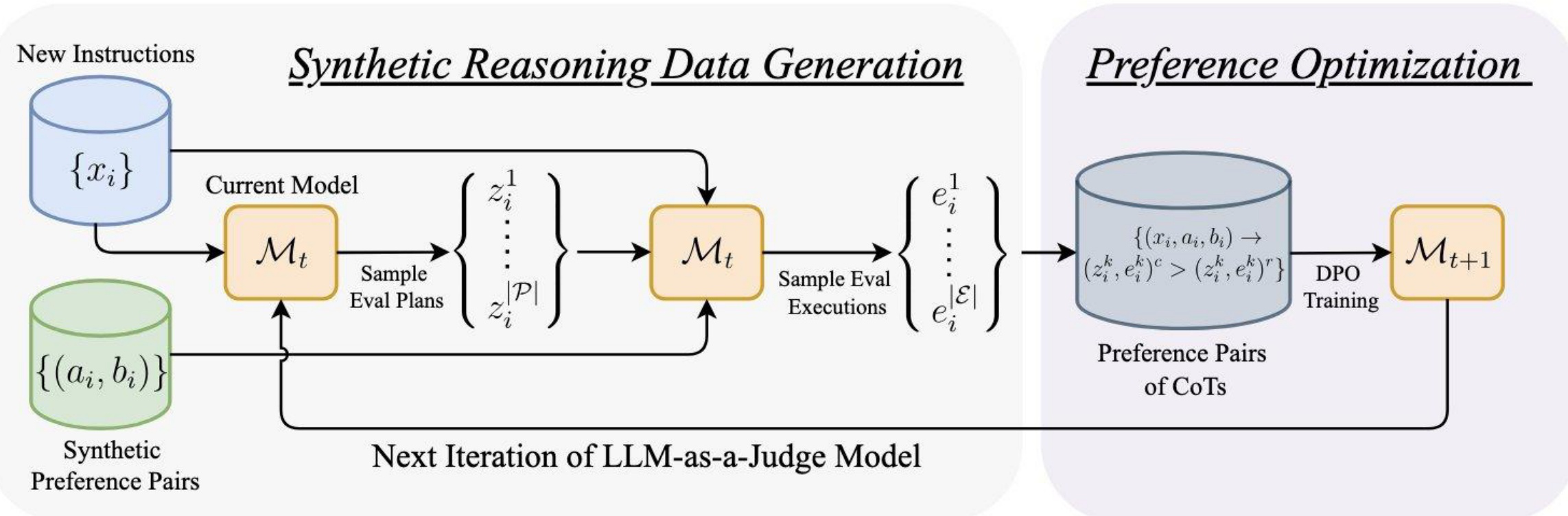
6.2 Verifiable Data Generation Recipe
The synthetic data recipe builds on a clever contrastive approach. For each prompt x, the system generates a good response y. Then it generates a similar but different prompt x’ and a corresponding good response y’. The key insight: y should be preferred over y’ when judging the original prompt x, because y’ answers a different question.
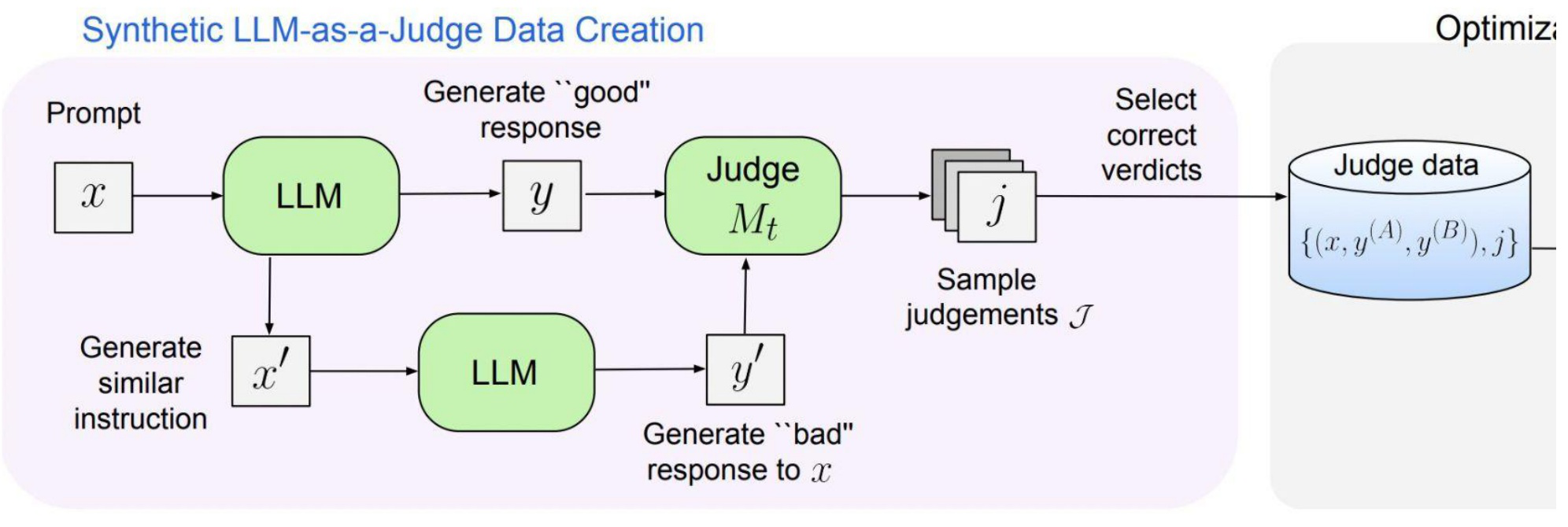
The ablation studies reveal two critical findings about the planning component. First, plans are essential: moving from no thoughts (86.2% accuracy) to SFT with thoughts (86.8%) to full preference optimization with thoughts (90.5%) shows consistent gains on RewardBench. Second, and perhaps more surprising, unconstrained plans outperform structured formats. Prior work often encourages judges to generate specific plan types — lists of criteria, verification questions. But when the model is free to figure out its own planning strategy, it achieves 86.8% accuracy versus 84.8% for verification questions and 83.9% for criteria lists.
Key idea: Let the model learn what works rather than imposing a human-designed schema. The unconstrained plan result mirrors a broader finding in RL for reasoning: specifying how to reason often hurts; specifying only what outcome to optimize lets the model discover better strategies than humans would engineer.
6.3 State-of-the-Art Evaluation Performance
The empirical results demonstrate that EvalPlanner achieves state-of-the-art performance across multiple evaluation benchmarks. Despite using only a Llama 3.1 70B base model and training on just 22K synthetically constructed preference pairs, EvalPlanner outperforms all prior approaches including much larger models and those trained on significantly more data.
EvalPlanner surpasses both open and closed LLMs, reward models with critiques, and other state-of-the-art generative reward models. The performance gains are particularly notable in the Chat-Hard and Reasoning categories.
FollowBenchEval assesses models on complex prompts with multi-level constraints (L1 through L5), requiring the evaluator to verify adherence to increasingly sophisticated instruction hierarchies. EvalPlanner significantly outperforms specialized approaches like Self-Taught Evaluator and Skywork-Critic, achieving an overall score of 65.4.
RM-Bench tests robustness to subtle content changes and style biases — revealing whether models judge based on superficial features rather than true quality. EvalPlanner demonstrates superior robustness, with especially strong performance on the Hard subset (84.3) where responses are detailed and well-formatted — precisely the cases where other methods are most vulnerable.
7. Future Directions: Latent Reasoning, Agents, and Beyond
7.1 Summary and Alternative Approaches
The lecture has covered a range of techniques for training language models to reason better, and a few key themes emerge. First, verifiable rewards are incredibly powerful: when you can check whether an answer is correct (as in math or coding), you can use those signals to train chain-of-thought reasoning via methods like IRPO or the approach taken by DeepSeek and OpenAI’s O1.
Second, once you have better judges, you can bootstrap reasoning on non-verifiable tasks. The Thinking LLMs work demonstrates this: a model trained to think step-by-step on verifiable problems can transfer that reasoning ability to open-ended questions.
Third, the meta-rewarding idea pushes this recursion even further. Models can generate new tasks to challenge themselves, evaluate whether they solved those tasks correctly, and update based on that self-assessment. The open research question is whether this self-improvement loop can eventually lead to superhuman AI.
But all of these approaches share a common assumption: reasoning happens in the token space. An alternative direction asks whether reasoning could instead happen in a continuous latent space — using hidden state vectors directly, rather than forcing every intermediate thought through the discrete bottleneck of language tokens.
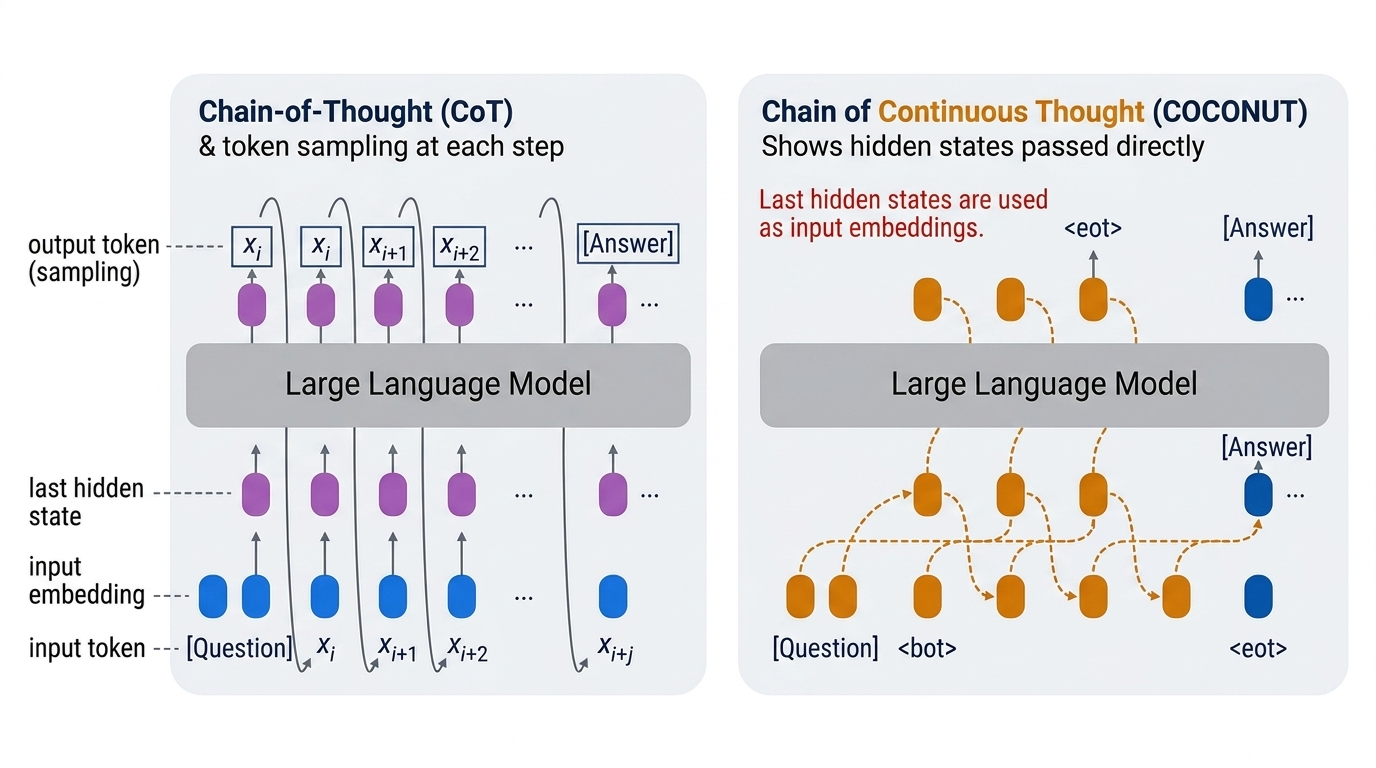
This is the idea behind COCONUT (Chain of Continuous Thought), introduced by Hao et al. in 2024. Instead of sampling output tokens and feeding them back as input, COCONUT takes the last hidden state from one reasoning step and uses it directly as the input embedding for the next step. This bypasses the token sampling process entirely during intermediate reasoning, potentially allowing richer and more efficient representations of System 2 thought.
7.2 Open Research Questions
The field is wide open. Jason highlights several key directions: agents, synthetic data, inference-time compute (à la O1), and the deeper question of building systems that truly reason, understand, and exhibit self-awareness.
One critical bottleneck is (self-)evaluation. If a model can reliably assess the quality of its own reasoning, it can decide when to allocate more compute — when to think harder. This capability is intimately tied to self-awareness: knowing what you know, and what you don’t. Without robust self-evaluation, scaling inference-time compute becomes a shot in the dark.
Another frontier is learning from interaction — with people, with the world, and with itself. This connects directly to both the agent paradigm and synthetic data generation. Agents that can explore, gather feedback, and refine their reasoning loops in situ will unlock capabilities far beyond static supervised learning.
Finally, there’s the question of improving System 1 — the fast, intuitive, pattern-matching substrate that underlies LLM inference. Can we build better attention mechanisms? Richer world models? The challenge here is scalability: any architectural change must work at the billion-parameter scale and beyond, which makes experimentation costly and risky.
Jason’s parting message is clear: the path from today’s LLMs to truly reasoning, self-aware systems is long, but the roadmap is coming into focus. The next generation of breakthroughs will come from researchers willing to tackle these open problems head-on.
Source
- Lecture: Learning to reason with LLMs by Jason Weston
- Course: UC Berkeley CS294-280 Sp25 — Advanced Large Language Model Agents
- Slides PDF: rdi.berkeley.edu/adv-llm-agents/slides/…
- Course page: rdi.berkeley.edu/adv-llm-agents/sp25