#007 PyTorch – Linear Classifiers in PyTorch – Experiments and Intuition

Highlights: In the field of machine learning, the goal of classification is to use characteristics of an object to identify a class to which that object belongs. To classify the object we can use various types of classifiers. In this post, we are going to talk about one particular type of classifiers called Linear Classifiers that can be used to solve easy image classification problems. To better understand them we will conduct several experiments and illustrations. So, let”s begin.
Tutorial Overview:
- Linear Classifier – Introduction
- Intuition 1 – Parametric viewpoint
- Intuition 2 – Algebraic viewpoint
- Intuition 3 – Visual viewpoint
- Intuition 4 – Geometric viewpoint
- Linear Classifiers challenges
- Linear-Classifiers – Experiments in Python using PyTorch
1. Linear Classifier – Introduction
Deep Neural Networks have recently become the standard tool for solving a variety of Computer vision problems. Indubitably, they represent one of the most important computer science technology of the future. In order to better understand the field of Deep Learning, we need to have a great overview of Linear Classifiers because they are one of the most important building blocks of Deep Neural Networks. We need to understand them very well in order to create a successful and efficient architecture for Deep Neural Networks.
One intuition of Linear Classifiers is that they are like Lego blocks. You can combine them in various architectures and obtain a large array and variety of models.
In this blog post [1], we will perform several experiments with Linear Classifiers. These experiments will be conducted mostly on the CIFAR10 Dataset. It is a standard dataset of 50 000 relatively small training color images of size of \(32\times32\times3 \) pixels, and 10 000 test images. All images are divided into 10 classes as you can see in the following image.
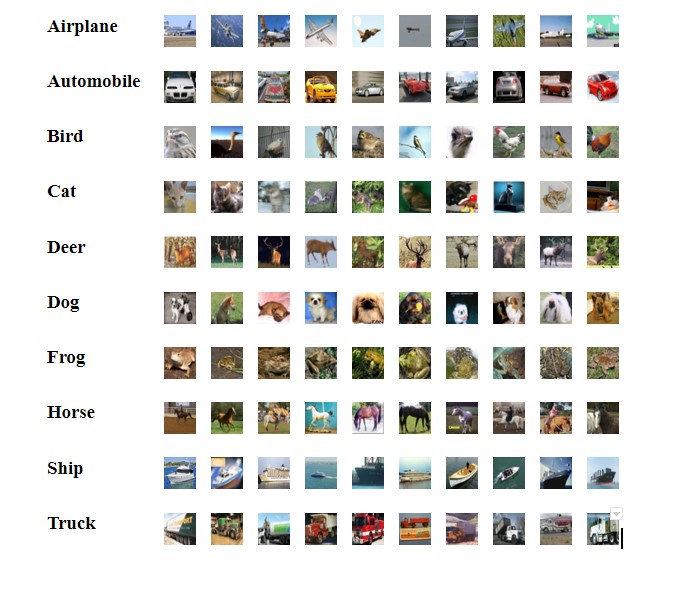
Another experiment will be conducted on the MNIST dataset. This dataset is a collection of grayscale handwritten digits ranging from 0 to 9. Each of these images has dimensions of \(28\times28 \) pixels. In our classification problem, we will use Linear classifiers want to identify what number is written in these images

2. Intuition 1 – Parametric viewpoint
In the first experiment, we will use the Parametric Approach. The idea of this approach is illustrated in the following example. We’re going to take our input image \(x \) with dimensions of \(32\times32\times3 \) pixels. Then, we can write our function that will input the image \(x \) multiplied with the parametric matrix \(W \).
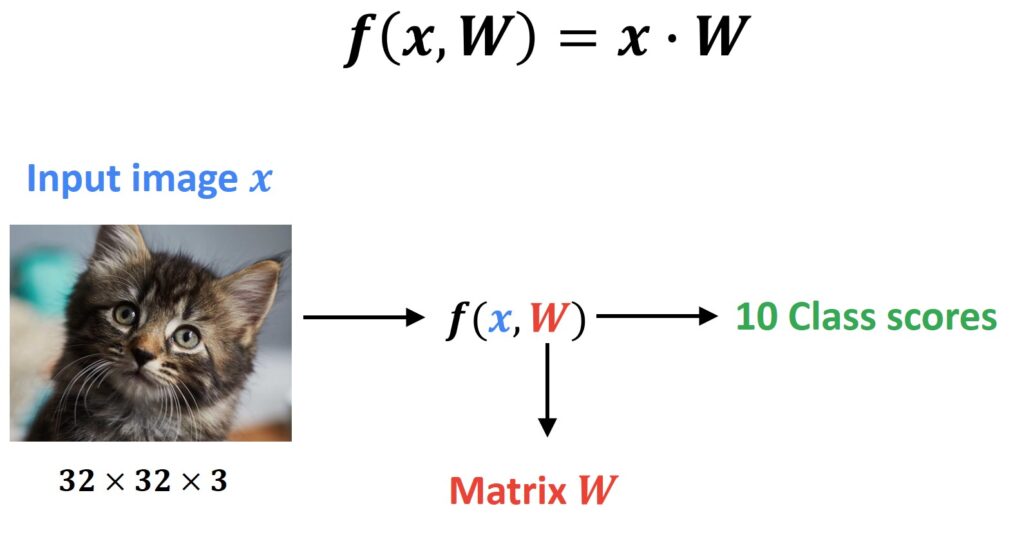
Here, \(x \) is a flattened or a vectorized image. The vector size is \(3072\times1 \). The parameter \(W \) is actually a matrix where all weights are stored. Also, in this case, there will be 10 classes. Therefore, we will construct the matrix \(W \) in such a way that it is \(3072\times10 \) in size.
This matrix will have a large number of parameters. The reason is that the size of this matrix is relatively large as compared to the size of the dataset that is available for us. So, the output of the multiplication of vectorized image and matrix \(W \) will be 10 numbers. These numbers are called Class scores. We can agree to a rule that once we have a higher score for a particular class, then the classifier will determine what class or category the image will belong to.
There are instances that we have to use a bias variable (vector) \(b \) as you can see in the following image.

In this case, since there are 10 classes, we are going to have a bias which will be a vector of 10 numbers. They will be used to adjust the hyperplanes that this multiplication produces. You can think of the \(b \) as an intercept term. For example, if \(x \) is of dimension 2, we will have a plane into space. We can then shift this plane, up and down to adjust it and have optimal classification. However, in this case, \(b \) will only act as a parameter that will assist these hyperplanes.
To better understand this, let us proceed with a simple example. Assume that we have a very tiny image of size \(2\times2 \) pixels. If we flatten this image, we will see that its spatial structure is destroyed. However, once this image is vectorized, the size of the vector will be equal to 4. To simplify this let’s assume further that we have only 3 classes. This means that the size of our \(W \) matrix will be \(3\times4 \). The matrix \(W \) will be multiplied with the vectorized image, and then we will add our bias term, which will now have a total of three elements. Here, each class will have one representation as you can see in the following image.
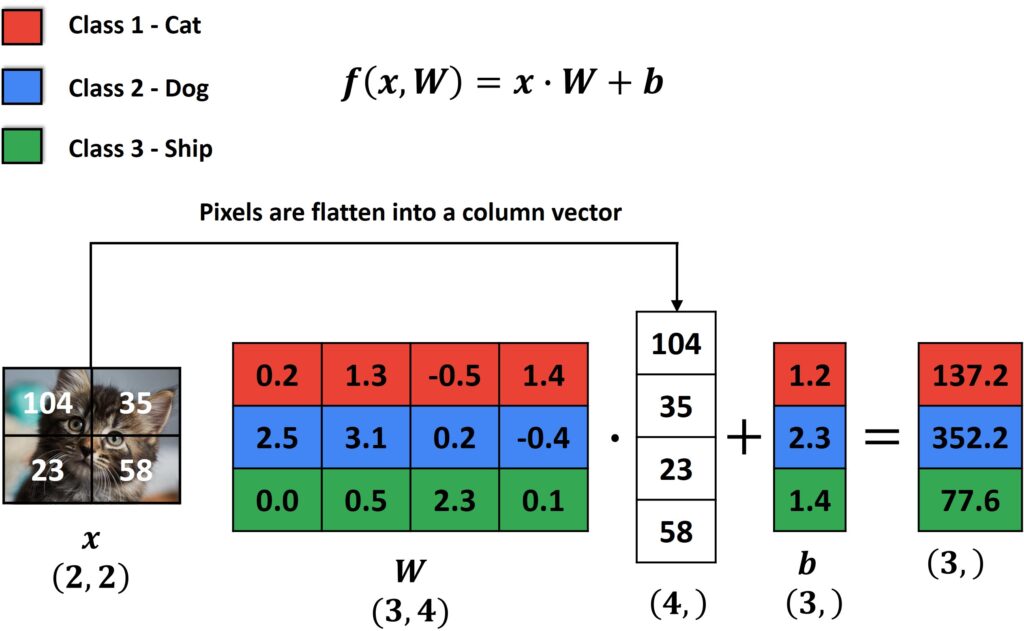
For the output of this example, we will get a vector with a size of 3. Each element of this vector is one score, and the maximal score corresponds to a category.
To simplify the notation, we can extend the \(W \) by adding a bias term to the end of this matrix so that it becomes of size \(3\times5 \). In this way, our image vector will be extended by a constant 1. Once we multiply this, we get the same expression as before.
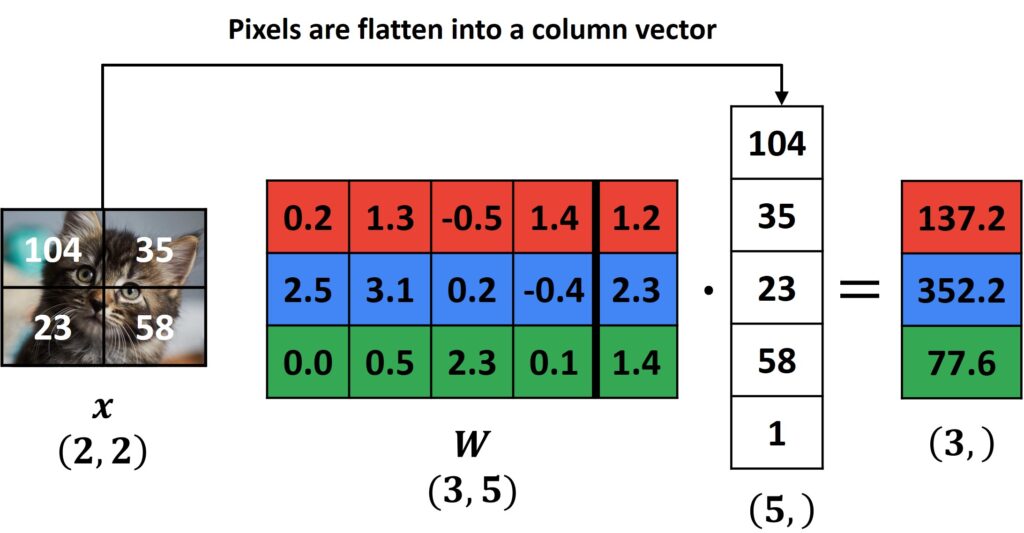
Application of the Parametric Approach without the constant
One important thing to note about Linear Classifiers is that they are indeed linear. So, we can ignore the bias term, and just multiply our image with the constant. In that way, we will get the same score output.
In the following example let us try to ignore the bias term.

Here, we can see that if we multiply our image with the constant \(c \), we will get the same score results that we got previously with the original image. In practice, this means that if you want to modify the image, the proper way is to use the default score values of the image and multiply them with some parameter (for instance 0.5). In this case, all pixel values will be cut in half, and our original image will be darkened.
Note that the output can be modified very easily and can be adjusted in this way. This can be good or bad, depending on the purpose. What is important is that we are aware of this trick because a darker or brighter image has different score values in the output. It is a good idea to be aware that we need to normalize our data especially when we are working with Linear Classifiers.
3. Intuition 2 – Algebraic viewpoint
So, from a parametric point of view, we learned that score is the result of the inner product between vectorized image \(x \) and one of the rows of a matrix \(W \).
We know that for inner products, there is a property: if there is a high correlation between two vectors (or vectorized images), the inner product will be large. On the other hand, if this correlation is low the inner product will be small. We can regard one of these vectors as a Template Vector. We can have one template vector for each class. Then, if the similarity between Template Vector and some other vector is high, that vector belongs to that class. On the other hand, if the similarity is low, we probably will not get the vector that belongs to that class.
Now, rather than stretching an image into a column vector, we can also reshape the rows of the matrix \(W \) into the same shape as the image. By doing that for each class, we will get the following tiny images of \(2\times2 \). pixels. However, these tiny images can now have a better intuition because these are very similar to Template vectors.

So, we multiply \(x \) and \(W \) element by element and add the bias \(b \). If the score is relatively high that would mean that this image shape is present in our image.
4. Intuition 3 – Visual viewpoint
For our first exercise, we will train some Linear Classifiers and plot learned weights from the matrix \(W \). It would be interesting to visualize what we can get as the output.
So, for each class, we will get a template image that should represent a certain property. For instance, if we work with the CIFAR10 dataset, \(W \) will be the template matrix for a certain class from this dataset like a car, airplane, or ship.
Here’s an illustration of interpreting all Linear Classifiers in visual viewpoint.

What is interesting here is that all of these classifiers are able to learn just one template per category. This is a limitation of Linear Classifiers in the sense that if we change the color of the background it will probably misinterpret different objects. For example, if we have a picture of a deer near the lake, the classifier can misinterpret the blue color of the water and blue color of the sky and recognize dear as an airplane.
Let’s take an image of the horse. In the CIFAR10 dataset, there is a large number of images with horses that are looking in different directions. Therefore, the visual appliance of the horses will be different. Unfortunately, the Linear Classifier has no way to separately learn templates for horses that are looking in different directions. So, if we take a look at the learned template of the horse in the image above, we can see that it has two heads.
5. Intuition 4 – Geometric viewpoint
Another interesting interpretation of a Linear Classifier is called a Geometric Viewpoint. Let’ say that we have one image and we want to calculate the score for three classes: car, horse, and bird. To illustrate this point of view, let us just pick one pixel from an image. That pixel will have coordinates of \((x=12, y=5, channel=0) \). Then we will draw a plot where the \(x \) axis is the value of the pixel and the \(y \) axis is the value of the classifier when the pixel changes while we keep all other pixels in the image fixed. We will change the values of this individual pixel from 0 to 255 (for color images in the CIFAR10 dataset we are changing the values of just one RGB channel) and multiply each value with three different weights template matrix \(W \). Once we do this, we will get certain lines that represent how these scores are changing in a linear manner.
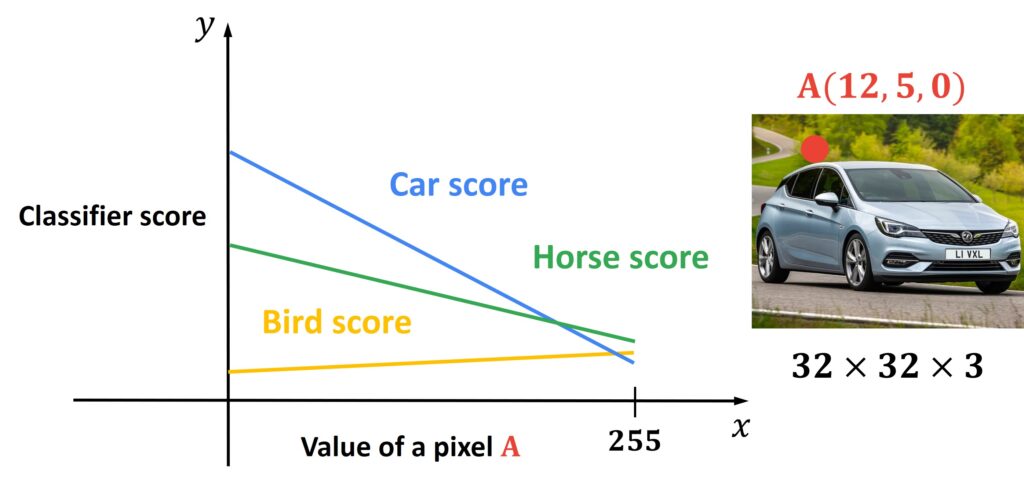
Linear Classifiers with Two Pixels
Another experiment that we can perform is to incorporate multiple pixels simultaneously. So, now instead of one pixel, we can pick two pixels. Then, we will again change the values of the first pixel and second from 0 to 255. Let us call them \(x_{1} \) and \(x_{2} \) pixels. We will plot \(x_{1} \) and \(x_{2} \) and we will calculate, the score for each of these three classes (car, horse, and bird).
Note that, as we changing the values of two pixels 256 times, we will get \(256\times 256 \) different score values. So, for each of these combinations, we will get a grid. We will go to a one-pixel increment and we will get an image of \(256\times 256 \) pixels. We can think of this image as some score image for each of these classes.
Now let’s illustrate this. In the following image, we can see a plot where along the \(x \) axis we have values of the first pixel, and along the \(y \) axis we have values of the second pixel. Along the third axis \(z \), we will have the values of the classifier. It is difficult to draw this third axis in 2D so try to imagine that you looking at this graph from a bird’s perspective. Now, to represent how scores are changing in 3D we will get planes instead of lines. These planes will intersect and form certain lines in this pixel space. These lines show all points in the space where a score will be equal to 0. Now, because this is a linear example, there is a direction in this pixel space along which the score will increase linearly. This direction is orthogonal to this line. Then, the learned car template will be somewhere along this line that is orthogonal to the score. In the example below, we can see three different lines for three different classes.
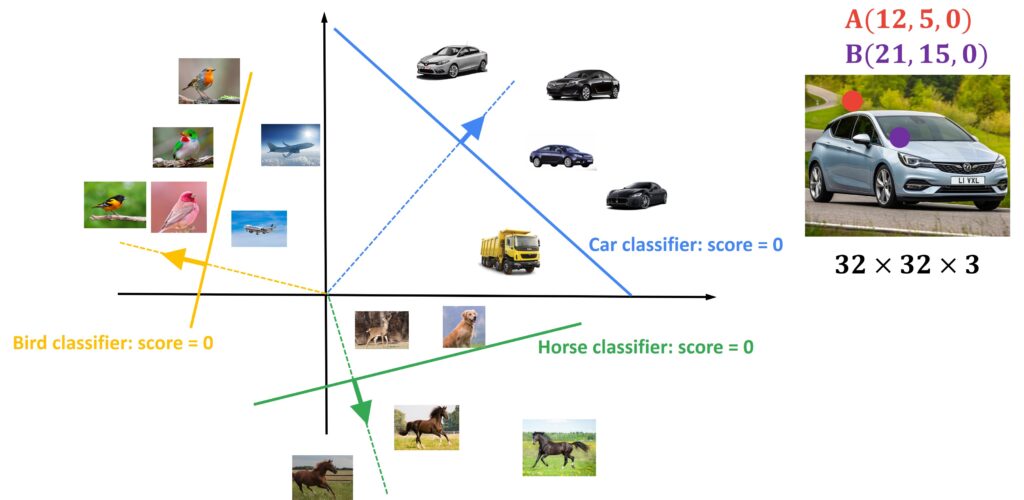
Here we can see these arrows that represent the direction of increase. So, if take a look at the car score we can see that all data points above the line in the direction of increase will have positive scores, and all points below the line will have negative scores.
Now, to visualize the correlation between these three planes let’s have a look at the 3D interpretation of the previous example.
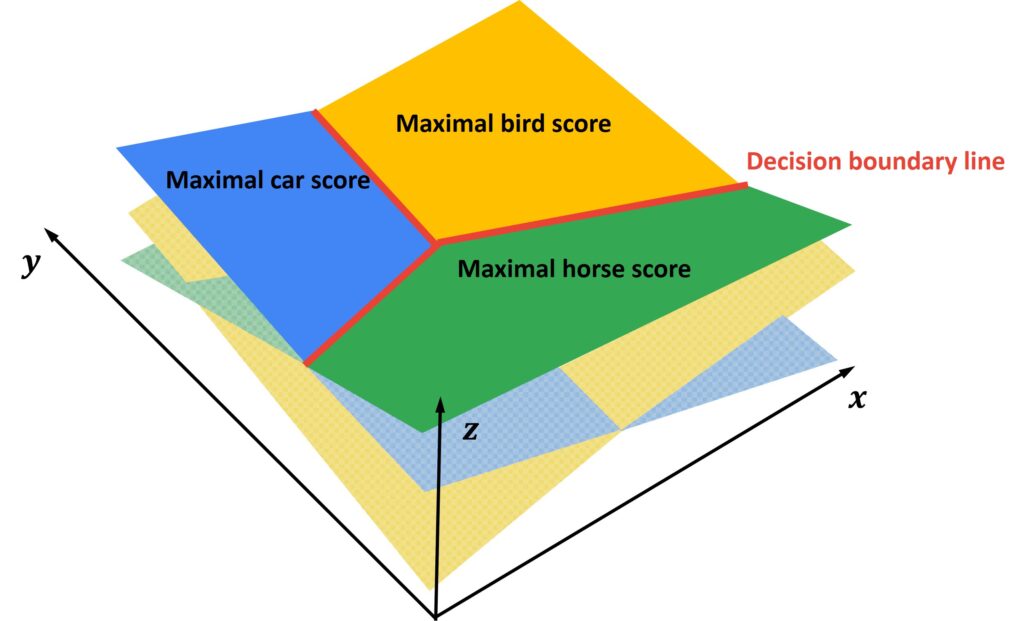
Here, we can see three planes for three different classes. The green plane represents the horse class, the blue plane represents the car class, and the yellow plane represents the bird class. Now, these three planes will intersect one horizontal plane at \(z=0 \) and form three lines. Along these lines, we will have all points in the space where a score is equal to 0. Then, we can see that everything below these lines will have a negative score value and everything above these lines will have a positive score value. The highest score values will be located in the highlighted areas of these planes. Also, notice three red lines where planes intersect with each other. These lines are called desition boundary lines and they separate our classes into three regions in space.
Now, remember that the images in Neural Networks are stretched into high-dimensional column vectors. So, we can interpret each image as a single point in this space. For example, in CIFAR10 dataset, each image is a point in 3072-dimensional space of \(32\times32\times3 \). pixels. Therefore, we need to extend this example with just two pixels to the higher dimensions. We can imagine a linear classifier that occupies the whole space of images in high dimensional euclidean space. In that space, we have one hyperplane per category that we want to recognize that cutting the euclidian space in two half.
6. Liner Classifiers challenges
Another interesting thing is that we see some hard cases for a Linear Classifier. Let’s have a look at the image below.
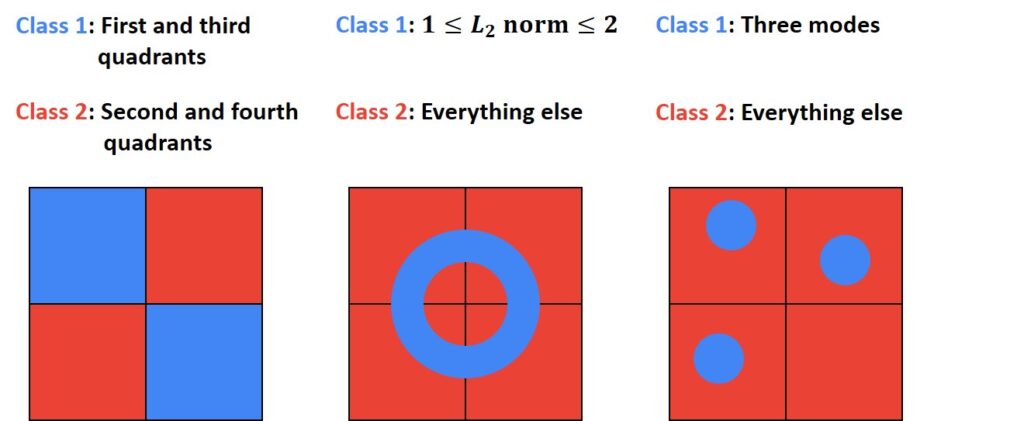
The idea is that two-dimensional pixel space is colored, with red and blue corresponding to different categories that we want the classifier to recognize. These are examples of three cases that are completely impossible for the linear classifier to recognize. On the left, we can see the case where the first and the third quadrants have one category, and the second and fourth quadrants have the other category. If you think about it, there’s no way that we can draw a single hyperplane that can divide the red and the blue categories. Another case that is very interesting is the case on the right where we can see three modes. Here, in the blue category, there are maybe three distinct regions in pixel space, that correspond to possibly different visual appearances of the category we wish we want to recognize. Again if we have these different regions in pixel space, corresponding to a single category, there’s no way for a single line to perfectly carve up the red and the blue regions.
In these three cases, we can see that a Linear Classifier cannot solve these challenging problems. This will be a motivation to introduce a solution for multilayers.
Another important example is Perceptron XOR. We already have developed the whole post for this. And you might want to check it out on this website.

Now, we will run one experiment with Linear classifiers in Python using PyTorch.
7. Linear Classifiers – Experiments in Python using PyTorch
A simple example
We will start by importing the necessary libraries.
import torch
import numpy as np
import matplotlib.pyplot as pltIn this experiment, we will perform the following classification: We will use a data set that has two features x1 and x2, and it will produce the output y of three classes. These three classes will have labels 0,1 and 2.
x1 = np.array([1, -1, -1], dtype=np.float32)
x2 = np.array([1, 1, -1], dtype=np.float32)
y = np.array([0, 1, 2])
x1 = np.repeat(x1, 100)
x2 = np.repeat(x2, 100)
y = np.repeat(y, 100)
x1+=np.random.randn(len(x1))*0.05
x2+=np.random.randn(len(x2))*0.05
index_shuffle = np.arange(len(x1))
np.random.shuffle(index_shuffle)
x1 = x1[index_shuffle ]
x2 = x2[index_shuffle]
y = y [index_shuffle]
So, here we have a multi-class problem. The points of the x1 and x2 arrays will represent centers of the blob that we want to create, and output y will represent our three classes. For instance, class 0 will have coordinates (1,1), class 1 will have coordinates (-1,1), and class 2 will have coordinates (-1,-1). Then, we will use the function np.repeat() to repeat every number in x1, x2, and y 100 times. In that way, we will create 3 blobs of 100 points. We will also add just a little bit of noise to scatter our points around the blob center. We can do that by using the np.random.rand()function and passing the length of x1 and x2 that is multiplied with some small number.
It’s important to shuffle these data. To do that we will create an index_shuffle variable and apply the np. arrange() function which will return 200 numbers from zero to 200. We will shuffle those elements, and then we will just use the same index to have the same ordering of our data.
Finally, we will scatter our data points in such a way that x1 and x2 are coordinates of the data, and where the class y is represented with three different colors. Let’s have a look at our result.
plt.scatter(x1, x2, c = y)
Before we proceed we need to convert our data to tensor. We just apply a simple conversion, and then we will apply the function torch. hstack() to stack x1 and x2 features. In this way, we obtain the data of 300 elements times 2. From that dataset, we take 250 elements for training and leave 50 elements for testing.
# converting to Torch
x1_torch = torch.from_numpy(x1).view(-1, 1)
x2_torch = torch.from_numpy(x2).view(-1, 1)
y = torch.from_numpy(y).view(-1, 1)
X = torch.hstack([x1_torch, x2_torch])
X_train = X[:250, :]
X_test = X[250:, :]
y_train = y[:250, :]
y_test = y[250:, :]X_train.shapetorch.Size([250, 2])Now, our goal is to create a Linear classifier. Here we will use a SoftMax classifier to create a LinearClassifier() class As you can see, it is similar to Logistic regression. However, here we only have one input dimension, and the output dimension will be of the size 3. So, instead of one line to separate the classes, with the SoftMax classifier, we will have three lines.
class LinearClassifier(torch.nn.Module):
def __init__(self, input_dim=2, output_dim=3):
super(LinearClassifier, self).__init__()
self.linear = torch.nn.Linear(input_dim, output_dim)
def forward(self, x):
x = self.linear(x)
return xNow that we have created the class LinearClassifier(), we need to create our Linear classifier model. So, we will create a variable model which will be equal to LinearClassifier() class. Then we will create a criterion where we will calculate the loss by using the function torch.nn.CrossEntropyLoss(). Also, we need to define an optimizer by calling the function torch.optim.SGD() which will calculate the gradients.
After that, we can start training our model. We will create a for loop that will iterate in the range from 0 to 10,000. It’s important to say that an output of our model actually has 3 numbers and that y_train is a scalar (0,1,2). So, each time we call this we will get certain three numbers, and the larger one will represent the higher probability afterward.
model = LinearClassifier()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
all_loss = []
for epoch in range(10000):
output = model(X_train)
loss = criterion(output, y_train.view(-1))
all_loss.append(loss.item())
loss.backward()
optimizer.step()
optimizer.zero_grad()
To better understand this let’s print our prediction for point (1,1) using the function model.forward().
model.forward(torch.tensor([1.,1.]))
tensor([ 3.8814, -0.8077, -3.6909], grad_fn=<AddBackward0>)As you can see we got the largest possibility for the zero class. And if we have a look at our graph, we can see that our prediction is correct. ( purple – class 0, yellow -1, green – 2.).
We can also plot the loss that we already saved in the variable all_loss.
plt.plot(all_loss)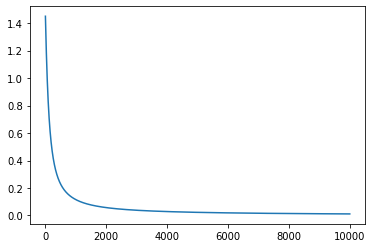
Now, we can define the parameters that we are going to access. We can print these parameters in order to interpret them.
aa = model.parameters()w, b = model.parameters()w = w.detach().numpy()
b = b.detach().numpy()warray([[ 2.7341104, 1.002038 ],
[-2.136448 , 2.2711906],
[-1.0507334, -2.5939922]], dtype=float32)As you can see we have a matrix with dimensions \(3\times3 \), where the values of \(w \) are stored. These values will be multiplied by a vector (\(x_{1} \), \(x_{2} \)). Then we will add the bias and we will obtain the following formulas:
$$ f_{0}=w_{00}\cdot x_{1} +w_{01}\cdot x_{2} +b_{0} $$
$$ f_{1}=w_{10}\cdot x_{1} +w_{11}\cdot x_{2} +b_{1} $$
$$ f_{2}=w_{20}\cdot x_{1} +w_{21}\cdot x_{2} +b_{2} $$
Now, we will draw this as vectors with the following code.
model.forward(torch.tensor([1.,0.], dtype = torch.float32))tensor([ 2.8794, -3.0789, -1.0969], grad_fn=<AddBackward0>)x1_fit = np.linspace(-1,1,100)
x2_fit = np.linspace(-1,1,100)
y1_fit = ( - x1_fit*w[0,0] - b[0] ) / w[0,1]
y2_fit = ( - x1_fit*w[1,0] - b[1] ) / w[1,1]
y3_fit = ( - x1_fit*w[2,0] - b[2] ) / w[2,1]
plt.scatter(x1, x2, c=y)
plt.plot(x1_fit, y1_fit)
plt.plot(x1_fit, y2_fit)
plt.plot(x1_fit, y3_fit)
plt.quiver(np.array([0,0,0]),np.array([0,0,0]), w[:,0], w[:,1])
plt.axis('equal')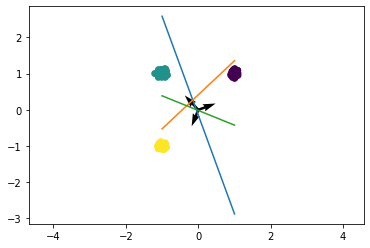
print(w[0,0])
print(w[0,1])
print(w[1,0])
print(w[1,1])
print(w[2,0])
print(w[2,1])
2.7341104
1.002038
-2.136448
2.2711906
-1.0507334
-2.5939922We can see that each of these three classes has vectors pointing in the direction of these lines. What can be challenging here is actually what’s happening in this part where the green line is positive and the blue line is positive. So, from this image, we can’t determine without knowing where these lines are intersecting.
So, additional computation is to use variables x1_fit and x2_fit to create the mash_grid object. For that, we will use the function np.meshgrid().
x1_fit = np.linspace(-3,3,20)
x2_fit = np.linspace(-3,3,20)
mesh_grid = np.meshgrid(x1_fit, x2_fit)
plt.scatter(mesh_grid[0], mesh_grid[1])
X = np.hstack([meshgrid[0].reshape(-1, 1), meshgrid[1].reshape(-1, 1)])
X = X.astype(np.float32)
X_torch = torch.from_numpy(X)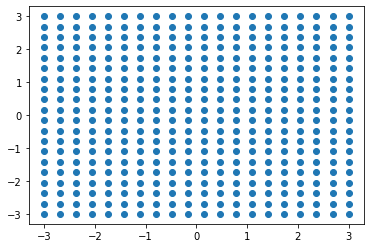
Now, that we obtained this mash_grid we will pass it into our classifier in order to see what it predicts. First, we need to convert the data.
X = np.hstack([meshgrid[0].reshape(-1, 1), meshgrid[1].reshape(-1, 1)])
X = X.astype(np.float32)
X_torch = torch.from_numpy(X)Now, if we check the shape of X_torch we can see that we will see that it consists of 400 elements that have 2 features. We can pass these points into our classifier by using the model.forward() function. Now, if we print the size of our prediction we will see that it consists of 400 vectors with 3 numbers in them. Each of these numbers represents the probability of data belonging to a certain class. So, we need to get the maximum value from these 3 numbers. We can do this by using the function torch.argmax(). Now, if we print the shape again we will see that it just has 400 numbers.
y_pred = model.forward(X_torch)
y_pred = torch.argmax(y_pred, axis = 1)If we print our prediction we can see that it belongs either to the class 0, class 1 or class 2.
print(y_pred)
plt.scatter(X_torch[:,0], X_torch[:,1], c = y_pred.detach().numpy())tensor([2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 0, 0, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 0, 0, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 0, 0, 0, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 0,
0, 0, 0, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 0, 0, 0, 0, 0, 0,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0,
0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0])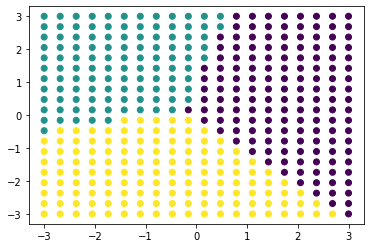
After we scattered our data points we can see that the model classified violet points as class 0, green points to class 1, and yellow points to class 2.
After this simple example where we learned how the classifier classifies the data, we can move on to some more complex examples. Here we will show you how to use linear classifiers for the MNIST dataset.
Linear classifiers on MNIST dataset
To automatically download the MNIST dataset we can use the torchvision module. First, we will create a list of transforms that we want to compose called transform and apply a class torchvision.Compose. Inside of the list, we will call the function transforms.ToTensor() which will convert the entire data into torch.tensor. We will also call the function transforms.Normalize() and pass as arguments pre-calculated values of the global mean and standard deviation of the MNIST dataset.
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.1307], [0.3081])
])Next, we will create a variable trainset where we will download the MNIST dataset using the function torchvision.datasets.MNIST(). As arguments, we will provide rooth where we specify the folder where the dataset will be downloaded, train which is set to True because this part of the data set will be used for training purposes. The third argument is download which is also set to True. Finally, in order to convert the data to tensors, we will set the parameter transform=transform. Then we will create a variable testset using a similar code. Ty only difference is that we will set the train parameter to False.
trainset = torchvision.datasets.MNIST(root='./data', download=True, train=True , transform=transform)
testset = torchvision.datasets.MNIST(root='./data', download=True, train=False, transform=transform)Since we are working with a large number of parameters it is always useful to load train and test data in batches using the DataLoader class. So, we will create a variable trainLoader and call torch.utils.data.DataLoader() function. As a first argument, we will pass trainset to specify that we want to load the training data. Then we will set the second argument batch_size to be equal to 4. The third parameter is shuffle which will shuffle our data after we pass the boolean value of True. To speed up the training process, we can use the argument num_workers. It is an optional attribute of the DataLoader class which specifies how many sub-processes we want to use for data loading. In our case, we will set this argument to be equal to 2. After we created a trainLoader variable, we will create to create another variable called testLoader using the same code.
trainLoader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True, num_workers=2)
testLoader = torch.utils.data.DataLoader(testset, batch_size=4, shuffle=True, num_workers=2)The next step is to define the number of classes. For that, we will use the function np.arange(). Since the MNIST dataset has 10 classes we will arrange them in the range from 0 to 10 with the step of 1.
In order to iterate through our data, we call the function iter(), and pass trainLoader variable as an argument. After that, we will initialize the first batch using the command .next().
classes = np.arange(0, 10, 1)
dataiter = iter(trainLoader)
images, labels = dataiter.next()To display the images we will define the function imshow. This function will normalize the images, transform them into NumPy array, and transpose them. Then, we will call imshow() function and as an argument, we will pass torchvision.utils.make_grid(images). In that way, we will make a grid of four images from MNIST dataset.
def imshow(img):
img = img / 2 + 0.5
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
imshow(torchvision.utils.make_grid(images))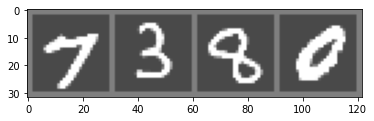
We can also check the labels of these four images.
print(labels)tensor([7, 3, 8, 0])
Building the model
Now, it is time to build our model. First, we will define the model class using the LinearCllasifier() method within torch.nn.Module. After that, we will set up the initialization method _init_. As parameters, we will pass self, input_size which will be equal to the image size in MNIST dataset and output_size which will be equal to 10 classes. Next, we will call a super() method on our LinearClassifier() function. Then we will define one linear layer with the size of an input dimension. Then we will create the forward method and return the results.
class LinearClassifier(torch.nn.Module):
def __init__(self, input_dim=28*28, output_dim=10):
super(LinearClassifier, self).__init__()
self.linear = torch.nn.Linear(input_dim, output_dim)
def forward(self, x):
x = self.linear(x)
return xThen, we will create a variable model which will be used for calling our LinearCllasifier() function. After that, we need to calculate the loss. To do that we will create the object criterion and specify the function torch.nn.CrossEntrophyLoss(). To calculate the gradients will create a variable optimizer, and call the function torch.optim.SGD(). As parameters to this function, we will pass the model.parameters(), and the learning rate lr which will be equal to 0.001
model = LinearClassifier()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr = 0.001)Training the model
The next step is to train our model. We will start by creating an empty list all_loss in which will store the loss after training is finished. Then, we will create a for loop that will iterate in the range from 0 to 1000. After that, we will create an empty list temp_loss so that we can keep track of loss during the training. Also, we need to iterate over images and labels in trainLoader variable where our training data is stored. Then, we need to create a output variable where we will pass the images that will be flattened using the function.view().
After the forward pass, we will start backpropagation. First, we will calculate the loss by calling criterion the output and labels. Then we need to update the list temp_loss by appending loss.item. To calculate the gradients we will use the optimizer.step() function. Also, we need to make sure that calculated gradients are equal to 0 after each epoch. To do that, we’ll just call optimizer.zero_grad() function.
After all, images are trained, we need to update all_loss list with the mean of the values stored in the temp_loss list. Finally, we’ll go ahead and print the loss after each epoch.
all_loss = []
for epoch in range(10):
temp_loss = []
for images, labels in trainLoader:
output = model(images.view(images.shape[0], -1))
loss = criterion(output, labels)
loss.backward()
temp_loss.append(loss.item())
optimizer.step()
optimizer.zero_grad()
all_loss.append(np.mean(temp_loss))
print(f"Epoch: {epoch}, loss: {np.mean(temp_loss)}")Epoch: 0, loss: 0.422779010532548
Epoch: 1, loss: 0.3165135584906442
Epoch: 2, loss: 0.29943322980460557
Epoch: 3, loss: 0.2901047709106196
Epoch: 4, loss: 0.28431303392786844
Epoch: 5, loss: 0.27965582165470115
Epoch: 6, loss: 0.2763478965909783
Epoch: 7, loss: 0.2733405952781633
Epoch: 8, loss: 0.27101428845680103
Epoch: 9, loss: 0.2688760106117203For better visualization we can also plot the loss.
plt.plot(all_loss)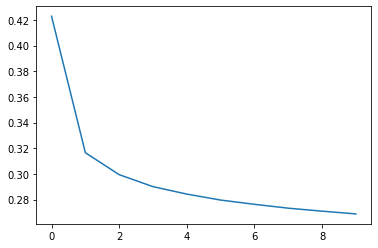
Here we can see that loss is drooping after each epoch. If we increase the number of epoch these results will drop even more.
Testing the model
Now, let’s run our test data. we will start with creating the variable correct where correctly predicted data will be stored, and variable total where all predicted data will be stored. Initially, both variables are initially set to zero. Next, we will turn them off the gradient calculation with torch.no_grad() function. The next step is to create the variable outputs where we will pass the images that will be flattened using the function.view(). Also, it is important to extract the maximal predicted values from the outputs. We can do that by using the function torch.max(). Then we will add the number of images that we tested to the variable total and to the variable correct we will add the number of correct predictions.
correct, total = 0, 0
with torch.no_grad():
for images, labels in testLoader:
output = model(images.view(images.shape[0], -1))
_, predicted = torch.max(output.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()Now, we can evaluate the accuracy of our model. To get the percentage of correctly predicted data we can simply divide all data with correctly predicted data and multiply that number by 100.
100 * correct / total92.24
As you can see accuracy of our model is 92.24.
A very useful thing is to check the accuracy for each class. We will start by creating variables class_correct and class_total.
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))Then again, we will turn off the gradients, flatten the images using the function.view(), extract the maximal predicted values and extract correctly predicted labels. After that, we will create a for loop and iterate in the range of 4 which is the number of batches in our model. Then, we will add the correctly predicted labels to the variable class_correct and we will add number 1 to the variable class_total.
with torch.no_grad():
for images, labels in testLoader:
output = model(images.view(images.shape[0], -1))
_, predicted = torch.max(output.data, 1)
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1Now we can iterate over 10 classes in our model and print accuracy for each class.
for i in range(10):
print(f"Accuracy of {classes[i]}: {100 * class_correct[i] / class_total[i]}")Accuracy of 0: 97.75510204081633
Accuracy of 1: 97.79735682819383
Accuracy of 2: 89.34108527131782
Accuracy of 3: 91.18811881188118
Accuracy of 4: 93.58452138492872
Accuracy of 5: 85.65022421524664
Accuracy of 6: 95.61586638830897
Accuracy of 7: 92.21789883268482
Accuracy of 8: 88.91170431211499
Accuracy of 9: 89.197224975223As you can see for all 10 classes we obtained an accuracy greater than 85%. Our model predicts the number 1 with the highest accuracy of 97%, while number 5 is predicted with the lowest accuracy of 85%.
Now, one thing that will be interesting to see is how our model interprets the images from the dataset. As we already explained the classifiers learn a certain template per category. Here, we will extract one template matrix \(W \) for each of the 10 classes in our dataset. To do that we will define weight and bias using the function model.parameters()and plot the templates with the following code.
w, b = model.parameters()plt.figure(figsize=(20, 17))
for i, data in enumerate(w):
plt.subplot(5, 5, i+1)
plt.imshow(data.detach().reshape(28, 28))
plt.axis('off')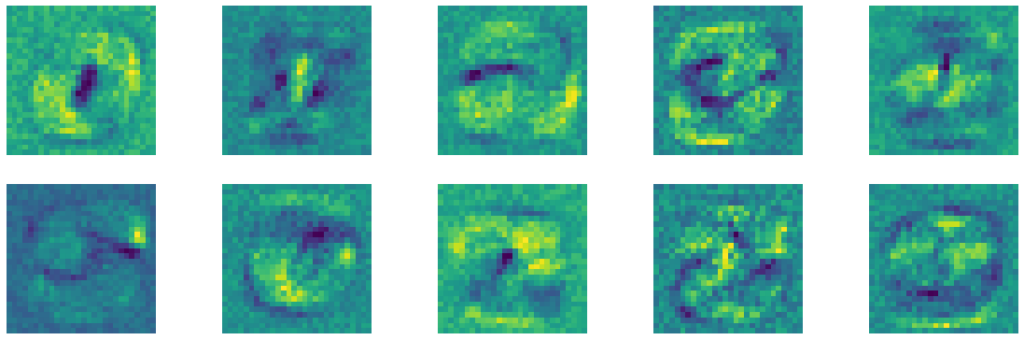
Here, we can see our templates. If we take a close look we can recognize templates for numbers 0,1,2,3,4 in the first row, and templates for numbers 5,6,7,8,9 in the second row.
Now, let’s conduct a similar experiment that we did earlier in the post. We will take three images of different classes. let’s say 0, 1, and 8. Then we will pick a single pixel with particular coordinates and change the values of this pixel from 0 to 255 while keeping the other pixel values fixed. Then after we multiply each value with a template matrix \(W \), we will get lines that represent how scores for these three classes are changing. We can do this with the following code.
First we will choose a 0,1 and 8 class and we will take on sample from each class and plot these three images.
idx_0 = testset.train_labels==0
idx_1 = testset.train_labels==1
idx_8 = testset.train_labels==8
zero = testset.train_data[idx_0]
one = testset.train_data[idx_1]
eight = testset.train_data[idx_8]
zero = zero[15].clone()
one = one[20].clone()
eight = eight[24].clone()
zero = transform(transforms.ToPILImage()(zero))
one = transform(transforms.ToPILImage()(one))
eight = transform(transforms.ToPILImage()(eight))
three_class_data = torch.stack([zero, one, eight])plt.figure(figsize=(20, 17))
for i, data in enumerate(three_class_data):
plt.subplot(5, 5, i+1)
plt.imshow(data.cpu().detach().reshape(28, 28))
plt.axis('off')
plt.show()
Next, we will find the minimal and maximal pixel value from these images and create a variable changeup which is a Numpy array of 256 numbers ranging from the minimum to the maximum value. Then, we will extract the weight and the bias for each of these classes and plot three template images.
imgs = torch.stack([img_t for img_t, _ in trainset], dim=3)
min_ = imgs.view(1, -1).min(dim=1).values[0]
max_ = imgs.view(1, -1).max(dim=1).values[0]changeup = np.linspace(min_, max_, 256)w_class = torch.vstack([w[0], w[1], w[8]])
b_class = torch.vstack([b[0], b[1], b[8]])plt.figure(figsize=(20, 17))
for i, data in enumerate(w_class):
plt.subplot(5, 5, i+1)
plt.imshow(data.cpu().detach().reshape(28, 28))
plt.axis('off')
plt.show()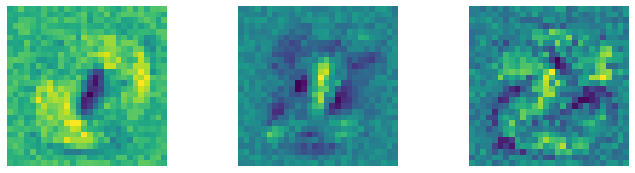
Now, we picked one pixel with coordinates (12,24) and created a for loop in order to iterate over that pixel in the range of variable changeup. Finally, we calculate the scores for these three classes by multiplying all pixels with weights and adding biases. Now will be interesting to plot changeup for each of three classes on the \(x \) axis and calculated scores on the \(y \) axis. Let’s see what will happen.
data_0 = np.zeros((256))
data_1 = np.zeros((256))
data_8 = np.zeros((256))
for i in range(len(changeup)):
reshaped = eight.reshape(28, 28, 1)
reshaped[12, 15] = changeup[i]
data_0[i] = ((torch.sum(w_class[0] * reshaped.reshape(-1)) + b_class[0]).cpu().detach().numpy())
data_1[i] = ((torch.sum(w_class[1] * reshaped.reshape(-1)) + b_class[1]).cpu().detach().numpy())
data_8[i] = ((torch.sum(w_class[2] * reshaped.reshape(-1)) + b_class[2]).cpu().detach().numpy())plt.plot(changeup, data_0)
plt.plot(changeup, data_1)
plt.plot(changeup, data_8)
plt.legend(['0', '1', '8'])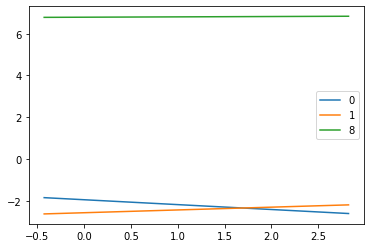
So, we can see that changing pixel intensity from a darker to a brighter value can affect our prediction. For number zero we can see that when pixel intensity increases score will decrease. For number 1 we got the opposite result, and for number 8 we can see that changes in pixel intensity of one pixel did not affect the score value at all.
In a similar manner, we can change the values of multiple pixels. In the next example, we will change the values of two pixels with coordinates (15, 13) and (17,14). To do that we will run the same code as in the previous example.
data_0 = np.zeros((256, 256))
data_1 = np.zeros((256, 256))
data_8 = np.zeros((256, 256))
for i in range(len(changeup)):
reshaped = eight.reshape(28, 28, 1).float()
reshaped[12, 15] = changeup[i]
for j in range(len(changeup)):
reshaped[17, 14] = changeup[j]
data_0[i, j] = ((torch.sum(w_class[0] * reshaped.reshape(-1)) + b_class[0]).cpu().detach().numpy())
data_1[i, j] = ((torch.sum(w_class[1] * reshaped.reshape(-1)) + b_class[1]).cpu().detach().numpy())
data_8[i, j] = ((torch.sum(w_class[2] * reshaped.reshape(-1)) + b_class[2]).cpu().detach().numpy())combined = np.array([data_0, data_1, data_8])
class_names = ['0', '1', '8']
plt.figure(figsize=(20, 17))
for i, data in enumerate(combined):
plt.subplot(5, 5, i+1)
plt.imshow(data)
plt.title(class_names[i])
plt.axis('off')
plt.show()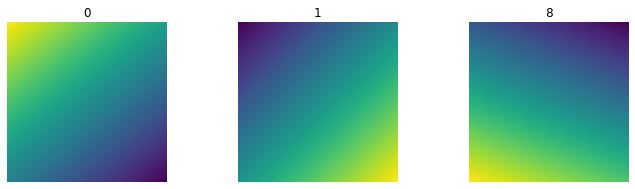
Here, we can see the score results for numbers 0, 1, and 8 when we change the values of two pixels. It’s pretty hard to comprehend what is going on in these images. To better understand this try to visualize these three images as representations of the three planes intersecting with each other in space seen from a bird’s perspective.
Summary
In this post, we covered three viewpoints of the Linear classifiers. Algebraic viewpoint where we studied how the inner products behave and how we can scale the image and get different vectors. In the visual viewpoint, we can have a template for each class, but there will be just one template for a single image. For the geometric viewpoint, we illustrated how class scores can be interpreted in 2D and in 3D. Finally, we conducted several intuitive experiments with Linear classifiers in Python using PyTorch.
This brings us to the end of this tutorial post. We hope you have learned a great deal about the importance of Linear classifiers in the structure and architecture of Neural Networks. We hope to illustrate as many examples and experiments as we go deeper into this study.
References:
[1] Lecture 3: Linear Classifiers – YouTube by Justin Johnson