#008 PyTorch – DataLoaders with PyTorch

Highlights: Hello and welcome to our new blog post. So far, we have mainly worked with very simple datasets. To train our models we used linear regression and logistic regression models and for that purpose, we artificially created very easy toy data sets such as blobs. However, in order to fully utilize the power of Deep Learning and neural networks, we will have to work with the larger dataset. Now it is a great time to see how we can load some interesting more complex data sets. So, let’s begin with our post.
Tutorial overview:
- CIFAR10 – a dataset of small images
- How to download the CIFAR10 dataset with PyTorch?
- The class of the dataset
- Dataset transforms
- Normalizing dataset
- Organizing data in mini-batches with DataLoader
1. CIFAR10 – a dataset of small images
One of the most known datasets used in computer vision for benchmarking is MNIST data set. However, there is another data set that can be a little bit more interesting for our purpose called CIFAR10 dataset. It consists of \(60000 \) color (RGB) images of dimensions \(32\times32 \) divided in 10 classes (6000 images per class). The dataset is divided into five training batches and one test batch, each with 10000 images. The test batch contains exactly 1000 randomly-selected images from each class. The training batches contain the remaining images in random order. However, some training batches may contain more images from one class than another. Between them, the training batches contain exactly 5000 images from each class.
In the following image, we can see 10 classes of the dataset, as well as 10 random images from each class.
As you can see, the resolution of images is relatively low, but still, these images can be easily recognized.
2. How to download the CIFAR10 dataset with PyTorch?
First, let’s import the necessary libraries.
from torchvision import datasets, transforms
import torch
import matplotlib.pyplot as pltTo automatically download this dataset and load it as a collection of PyTorch tensors, we can use the torchvision module. So, from the torchvision library, we can import data sets. Then we can create a variable data_path and use a simple string (these two dots mean that we are going one level up from our directory) to specify the path. Next, we create an object cifar10 and from datasets, we call the already existing function CIFAR10(). As arguments, we provide data_path, train which is set to True because this part of the data set will be used for training purposes. The third argument is download which is also set to True. This means that if the dataset does not exist, we will download it. Finally, we will create an object cifar10_val. For that ve will use exactly the same function as the above. The only difference is that we set the argument train to False. This means that this data set will not be used for training purposes but mainly for validation.
data_path = '../data_cifar/'
cifar10_train = datasets.CIFAR10(data_path, train=True, download=True)
cifar10_val = datasets.CIFAR10(data_path, train=False, download=True)Note, that this data set is not the only one that you can use. The datasets submodule gives us access to the most popular computer vision datasets, such as MNIST, Fashion-MNIST, CIFAR-100, SVHN, Coco, and Omniglot. So, we can use the _mro_attribute to get a list of types the class is derived from. In each case, the dataset is returned as a subclass of torch.utils.data.Dataset. We can see that the method resolution order of our cifar10 instance includes it as a base class.
type(cifar10).__mro__Output:
(torchvision.datasets.cifar.CIFAR10,
torchvision.datasets.vision.VisionDataset,
torch.utils.data.dataset.Dataset,
typing.Generic,
object)3. The class of the dataset
Let’s see what this means in practice. Well, that means that all datasets are subclasses of torch.utils.data. and they have two methods implemented:
len(size of dataset) – returns the number of items in the datasetgetitem– return the item consisting of a sample and its corresponding label
To better understand this have a look at the following image.
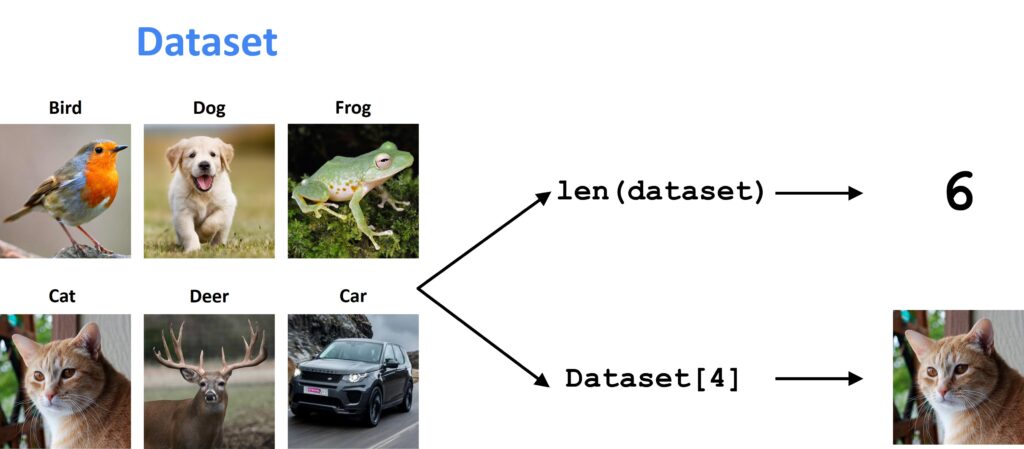
In this illustration, we can see a dataset that consists of six images. With function len(), we can see the size of the dataset. With function getitem() if we pass a number 4 as an argument, we will get the fourth image from a dataset. So, this will create the tuple of an image and the label.
Now let’s apply this in Python and extract one image from the dataset.
len(cifar10)Output:
50000image, label = cifar10[0]We can check the type of the image with the function type() and we will see that it is a PIL image.
type(image)Output:
PIL.Image.ImageAlso, if we print the label we can see that the value is 6. If we take a look at the class names we will see that it is a frog.
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
print(label)
print(classes[label])Output:
6
frogNow, we can plot the image using Matplotlib.
plt.imshow(image)Output:

4. Dataset transforms
So far, this is very interesting. However, before we can use the image for training neural nets, we will have to find a way to convert the image into a PyTorch tensor. For this purpose, we have a module torchvision.transforms. This module defines a set of composable function-like objects that can be passed as an argument to a torch vision dataset. This means that we can pass a method in the function datasets.CIFAR10() which will allow us to perform certain image processing. After that, we will store these images as tensors. In order to do this, we will use the command dir and we will pass transforms as an argument.
dir(transforms)'CenterCrop',
'ColorJitter',
'Compose',
'ConvertImageDtype',
'FiveCrop',
'GaussianBlur',
'Grayscale',
'Lambda',
'LinearTransformation',
'Normalize',
'PILToTensor',
'Pad',
'RandomAffine',
'RandomApply',
'RandomChoice',
'RandomCrop',
'RandomErasing',
'RandomGrayscale',
'RandomHorizontalFlip',
'RandomOrder',
'RandomPerspective',
'RandomResizedCrop',
'RandomRotation',
'RandomSizedCrop',
'RandomVerticalFlip',
'Resize',
'Scale',
'TenCrop',
'ToPILImage',
'ToTensor',
'__builtins__',
'__cached__',
'__doc__',
'__file__',
'__loader__',
'__name__',
'__package__',
'__path__',
'__spec__',
'functional',
'functional_pil',
'functional_tensor',
'transforms']As you can see this will give us a list of all functions that we can use, once we work with the transforms.
So, after we imported transforms, we can use the function transform.ToTensor(), which turns NumPy arrays and PIL images into tensors. We will pass the PIL image as an argument to this function which will return a tensor as an output.
to_tensor = transforms.ToTensor()
img_t = to_tensor(image)
type(image)Output:
PIL.Image.Imageimg_t.shapeOutput:
torch.Size([3, 32, 32])We can see that the image is converted into a tensor of size \(3\times32\times32 \), where number 3 represents 3 channels of red, green, and blue, and the size of the image is \(32\times32 \) pixels.
Now, we can pass the transform directly as an argument to the CIFAR 10 dataset and access any image that we want. If we pass the function transforms.ToTensor() as the parameter we can immediately transform our whole dataset to tensors.
tensor_cifar10 = datasets.CIFAR10(data_path, train=True, download=False, transform=transforms.ToTensor())Also, using indexing we can play around and access labels or classes.
tensor_cifar10[0][1]Output:
6tensor_cifar10.classes[6]Output:
frogIt is useful to to check the data type of the tensor. We can do this in the following way:
tensor_cifar10[0][0].dtypeOutput:
torch.float32This means that the original PIL image was in the range from 0 to 255 with 8 bits per channel, and transform.ToTensor() turned the data into a 32 -bit floating-point per channel. Moreover, it scaled the pixel values of the image from 0.0 to 1.0. We can check the minimum and maximum value with the following code:
img_t.min()Output:
tensor(0.)img_t.max()Output:
tensor(1.)Another thing that we can do is to permute the axes using the function permute(). In that way, the order of axes will change from (channel, height, width) to (height, width, channel).
plt.imshow(tensor_cifar10[100][0].permute(1, 2, 0))Output:

5. Normalizing dataset
One good thing with the transforms is that we can actually chain them and specify whatever we need in order to pre-process our dataset. This is very important once we start to work with the data augmentation where very good practice is to normalize our dataset. In this way, each channel will have zero mean and unitary standard deviation. In order to calculate zero mean and unitary standard deviation we can use the following formula: v_n [c]=(v[c] - mean[c]) / stdev [c].
This equation states that a normalized vector of all pixels in one channel is equal to the mean value of these pixels divided by the standard deviation. In order to proceed with the normalization of the dataset, we will have to calculate values of mean and standard deviation.
So, to work out the normalization, we will perform the following. Because we are going to work with the whole dataset, we are going to stack all the images. We can achieve this by using the torch.stack() function. Then, with the for loop, we will iterate over the dataset and extract the images. Also, we will disregard the labels which mean that images will be stacked along the third dimension.
imgs = torch.stack([img_t for img_t, _ in tensor_cifar10], dim=3)Here, we can check the shape of our dataset.
imgs.shapeOutput:
torch.Size([3, 32, 32, 50000])As you can see this is our loaded CIFAR 10 as a tensor. It has 50,000 items, that are stored as a tuple.
Next, we can also transform the entire dataset with command view (3,-1) which keeps three channels and merges all the remaining dimensions into one dimension with appropriate size. Here our \(3 \times 32 \times 32 \) image is transformed into a \(3 \times 51200000 \) vector.
temp = imgs.view(3, -1)
temp.shapeOutput:
torch.Size([3, 51200000])Then we will calculate the mean over the 51200000 elements of each channel. The command mean() will return three numbers that are mean values for each terminal in a complete dataset.
mean_ = temp.mean(dim=1)Output:
tensor([0.4914, 0.4822, 0.4465])In the same way we can calculate the standard deviation.
std_ = temp.std(dim=1)Output:
tensor([0.2470, 0.2435, 0.2616])Now, when we got our three numbers we can initialize the transforms.Normalize() function.
transforms.Normalize((0.4915, 0.4823, 0.4468), (0.2470, 0.2435, 0.2616))Output:
Normalize(mean=(0.4915, 0.4823, 0.4468), std=(0.247, 0.2435, 0.2616))We can also transform the images as we load them using the datasets module. To do that we just need to pass the transforms.Compose() function inside the transform parameter. Inside this function, we specify what types of transformation we want to apply. For example, we want to transform our images into tensors, we will pass a list transforms.ToTensor(). On the other hand, if we want to normalize the images we will pass in the transforms.Normalize() function, and as parameters, we pass in the mean and std that we calculated.
transformed_cifar10 = datasets.CIFAR10(
data_path, train=True, download=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean_.numpy(), std_.numpy())
]))Now, we have a normalized dataset. We should keep in mind that normalization has shifted the RGB levels outside the 0.0 to 1.0 range. In this way, the overall magnitudes of the channels are changed. Remember, all of the data is still there. However, Matplotlib renders it as black.
img_t, _ = transformed_cifar10[99]
plt.imshow(img_t.permute(1, 2, 0))Output:

6. Organizing data in mini-batches with DataLoader
One additional thing that is very important is that usually, we need to split our dataset into several subclasses. We will use these subclasses to faster optimize our parameters. For example, we can create a dataset subclass that only includes images with birds and airplanes. A common way to do that is to use mini-batches.
For that purpose in torch.utils.data module there is a class that can help with shuffling and organizing the data in mini-batches. It is called DataLoader and its job is to sample mini-batches from a dataset. This will provide us the flexibility to choose from different sampling strategies.
Now, let’s see how we can load our images inside a DataLoader class. We will first create a dictionary label_map which will be used to change the class label. We will select only two classes out of 10. Class 0 will be an airplane and class 2 will be a bird.
label_map = {0: 0, 2: 1}
cifar2 = [(img, label_map[label]) for img, label in transformed_cifar10 if label in [0, 2]]After selecting all images that belong to those two classes, we can now call the functiontorch.utils.data.DataLoader(). Inside the brackets, we pass the parameter dataset. Also, we will set other parameters like the batch_size that will automatically group images into batches. The other parameter is shuffle which will shuffle our data if we pass the boolean value of True.
train_loader = torch.utils.data.DataLoader(cifar2, batch_size=64, shuffle=True)To access the images and labels we can simply make a for loop and iterate through the DataLoader and train_loader objects that we created.
for imgs, labels in train_loader:
print(labels)Output:
tensor([1, 0, 1, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 1,
0, 1, 0, 1, 1, 0, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0,
1, 1, 0, 1, 0, 0, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1])
tensor([1, 1, 0, 1, 1, 1, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0,
0, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1,
0, 1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 1, 1, 1, 0, 0])
tensor([1, 1, 1, 0, 0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1,
1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0,
1, 1, 1, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 1, 1, 1])
tensor([0, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 0,
0, 0, 1, 0, 1, 1, 0, 0, 1, 0, 1, 0, 0, 0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1,
1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1])......We can check out the number of batches that are created.
print(labels.shape)
print(imgs.shape)Output:
torch.Size([16])
torch.Size([16, 3, 32, 32])As you can see, we selected 1024 images and created 16 batches where each batch contains 64 images with labels.
Summary
In this post, we learned how to work with large and complex data sets. For that purpose we examined CIFAR 10 dataset that consists of \(60000 \) color images of dimensions \(32\times32 \) divided into 10 classes. We learned how to automatically download the dataset, how to transform images into tensors, and how to normalize the dataset. Moreover, we learned how to organize the data in mini-batches using the DataLoader class. In the next post, we will explain how to apply backpropagation with vectors and tensors.