#009 PyTorch – How to apply Backpropagation With Vectors And Tensors

Highlights: In Machine Learning, a backpropagation algorithm is used to compute the loss for a particular model. The most common starting point is to use the techniques of single-variable calculus and understand how backpropagation works. However, the real challenge is when the inputs are not scalars but of matrices or tensors.
In this post [1], we will learn how to deal with inputs like vectors, matrices, and tensors of higher ranks. We will understand how backpropagation with vectors and tensors is performed in computational graphs using single-variable as well as multi-variable derivatives. So, let’s begin.
Tutorial Overview:
- Introduction
- Vector Derivatives
- Backpropagation With Vectors
- Backpropagation With Tensors
- Backpropagation with vectors and tensors in Python using PyTorch
1. Introduction
Single-variable Calculus has made it easy and quite intuitive to perform backpropagation and computational graphs using scalars. If you are interested to learn how to perform these calculations check our post Computational graph and Autograd with Pytorch.
However, in practical applications, we do not often work with scalars. Instead, we work with vector-valued functions where vectors, matrices, and tensors of higher ranks come into the picture.
So, how do we perform the same backpropagation and visualize computational graphs for such vector-valued functions?
The answer lies in multi-variable derivatives. Before beginning to understand backpropagation and computational graphs using multi-variable derivatives, we need to understand the basic concept of single-variable derivatives. Then, we will study how backpropagation and computational graphs are made using single-variable derivatives. After that, we will study the basics of multi-variable derivatives and finally learn how to perform backpropagation using multi-variable derivatives.
Let us start with the concept of single-variable derivatives.
2. Vector Derivatives
We can categorize derivatives using the type of input data that our function receives, and the type of output data our function produces. Have a look.
- Regular Derivatives – Scalar Input, Scalar Output
Given an ordinary scalar input \(x\), the derivative of the scalar output \(y\) with respect to the input \(x\) can be written as:$$ x\in \mathbb{R} $$
$$ y\in \mathbb{R} $$
Regular derivative:
$$ \frac{\partial y}{\partial x} \in \mathbb{R} $$
The above scalar derivative signifies the local linear aproximation. In other words, it informs us about the change in output \(y\) when the input \(x\) is changed by a small amount. - Gradient Derivatives – Vector Input, Scalar Output
Given a vector input \(x\), the derivative of the scalar output \(y\) with respect to the input \(x\) can be written as:
$$ x \in \mathbb{R}^{N}, y \in \mathbb{R} $$
Derivative is Gradient:
$$ \frac{\partial y}{\partial x} \in \mathbb{R}^{N} \quad\left(\frac{\partial y}{\partial x}\right)_{n}=\frac{\partial y}{\partial x_{n}} $$
The above vector derivative is of the same dimension as the input \(x\) and tells us about the change in output \(y\) for a small amount of change in each element \(x_{n} \) of input vector \(x\). - Jacobian Derivatives – Vector Input, Vector Output
Given a vector input \(x\) of dimension \(N\), the derivative of the vector output \(y\) of dimension \(M\) with respect to the input \(x\) can be written as:$$ x \in \mathbb{R}^{N}, y \in \mathbb{R}^{M} $$
Derivative is Jacobian:
$$ \frac{\partial y}{\partial x} \in \mathbb{R}^{N \times M}\left(\frac{\partial y}{\partial x}\right)_{n, m}=\frac{\partial y_{m}}{\partial x_{n}} $$
The above matrix derivative is of a dimension \(N \times M\) which is different than the input, as well as the output. This tells us about the change in each element of the output \(y\) for a small change in each corresponding element of input vector \(x\).
3. Backpropagation With Vectors
Now that we have a basic idea of how scalar and vector derivatives work, let us understand what exactly backpropagation is and how we can perform backpropagation using vector derivatives.
Concept: Backpropagation Using Vector Derivatives
Have a look at the visualization of the backpropagation process for a particular node \(f\).
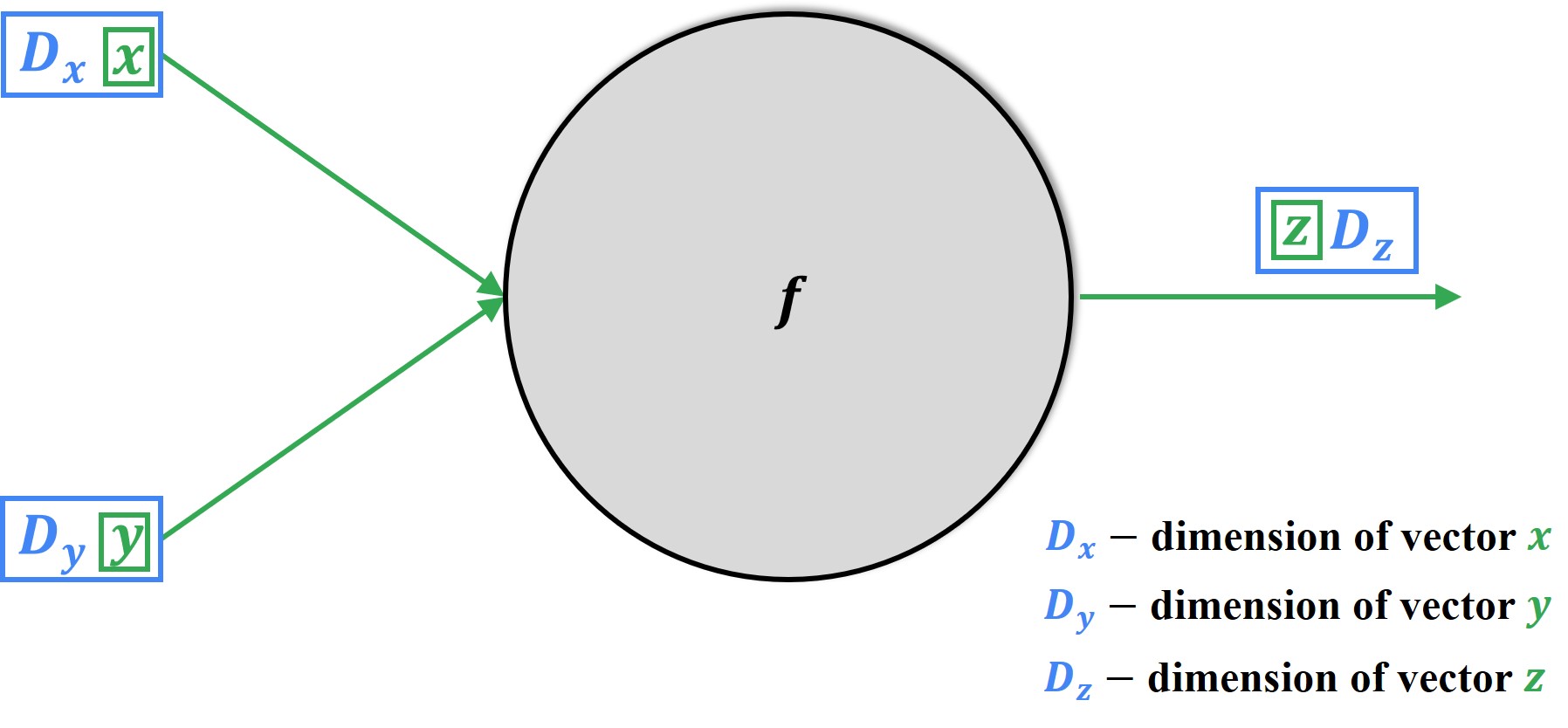
For the node represented above, we have two vector inputs \(x\) and \(y\), of dimensions \(D_x\) and \(D_y\) respectively. These input vectors are producing an output vector \(x\) of dimension \(D_z\). This is how forward propagation works.
When we get into backpropagation, we make use of an upstream gradient as shown below.
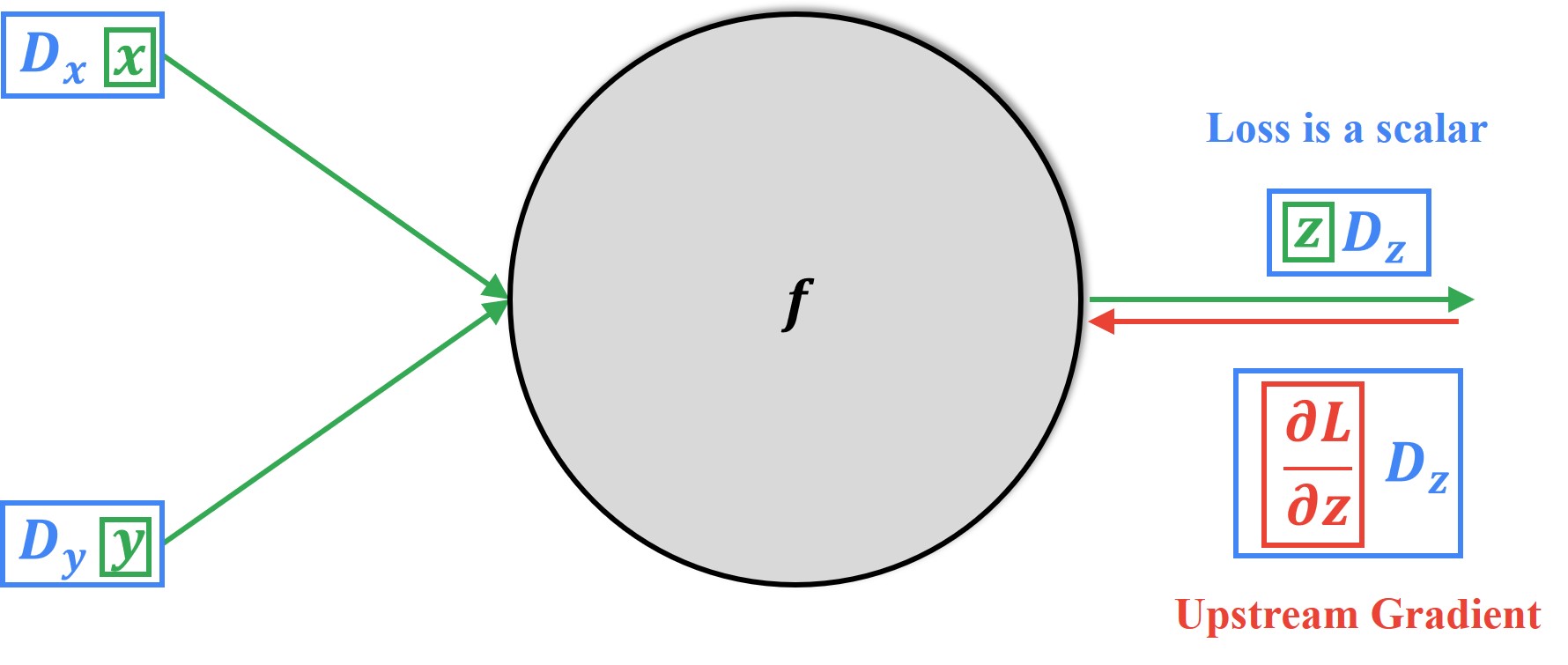
In the case of this upstream gradient, the loss computed is always a scalar value, no matter if the input or output is scalar, vector, tensor, or anything else. This upstream gradient tells us how a small amount of change in each element of \(z\) affects the value of loss \(L\).
Now, within the node \(f\) itself, we have local gradients or the so-called Jacobian matrices. Again, these local gradients or the Jacobian matrices inform us how much the output \(z\) changes with respect to each of the elements of each of the input vectors \(x\) and \(y\) respectively. Here, \(\left [ D_{x}\times D_{z} \right ] \) and \(\left [ D_{y}\times D_{z} \right ] \) are dimensions of a Jacobian matrix. Have a look at the updated visualization below.

Finally, the downstream gradients will always be computing the change in the value of Loss \(L\) with respect to the input vectors \(x\) and \(y\) respectively. These downstream gradients will have the same respective size as the inputs.

Notice how the downstream gradient vectors are nothing but a matrix-vector product of the local Jacobian matrix and the upstream gradient vector. Let us understand the above theory using an example.
Example: Backpropagation With ReLu
Let us reinforce the concept of backpropagation with vectors using an example of a Rectified Linear Activation (ReLU) function.
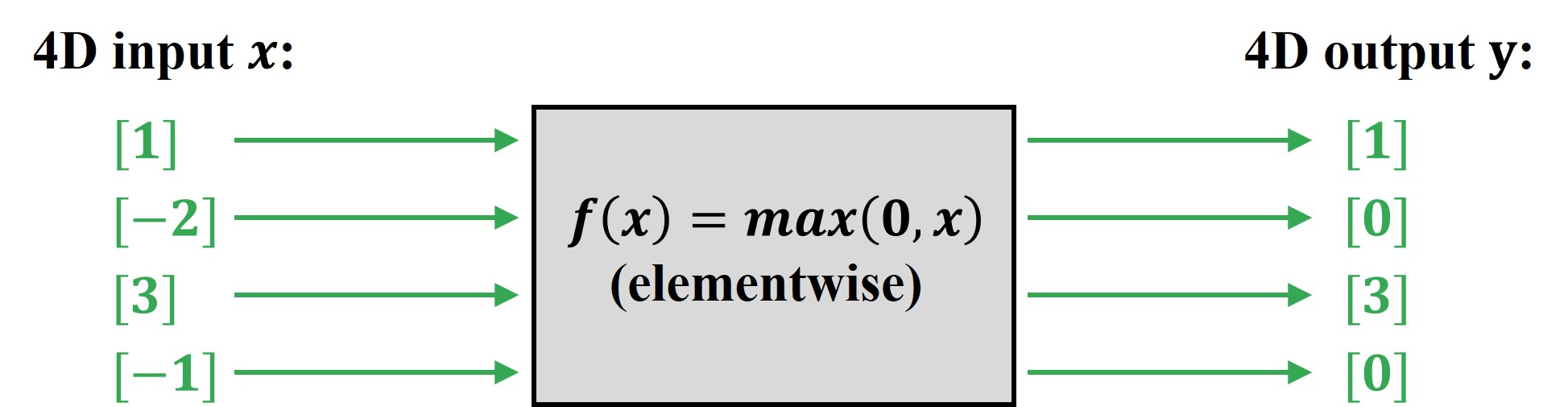
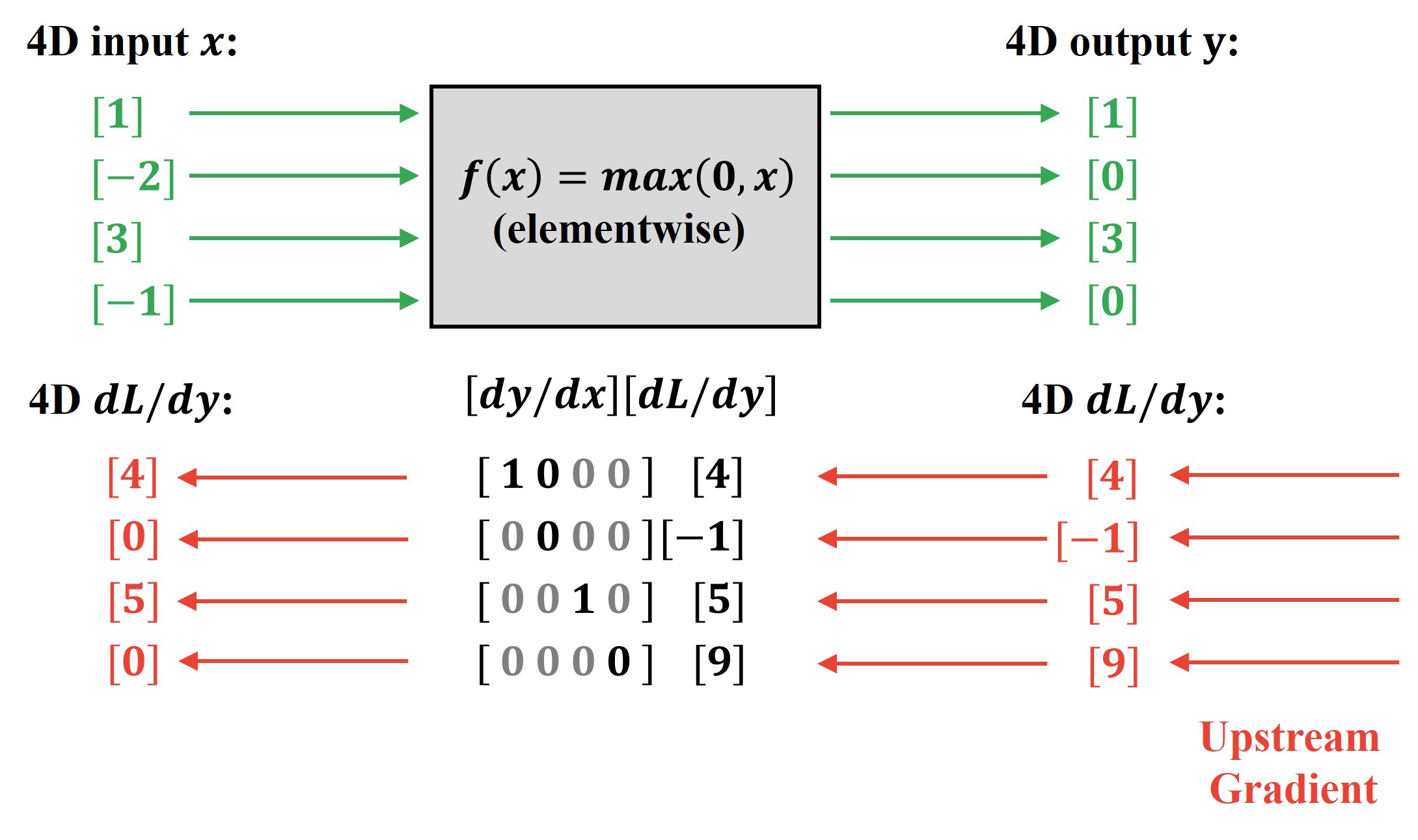
As we can see above, a ReLU function is an elementwise linear function that outputs the value of input as it is, if it is greater than 0 (i.e., positive) and outputs 0 when the input value is below 0 (i.e., negative).
Now, this entire ReLu function acts as a coherent computational node and is embedded in an appropriate position in our computational graph. This means that this ReLU computational node will eventually receive an upstream gradient vector that looks something like this.
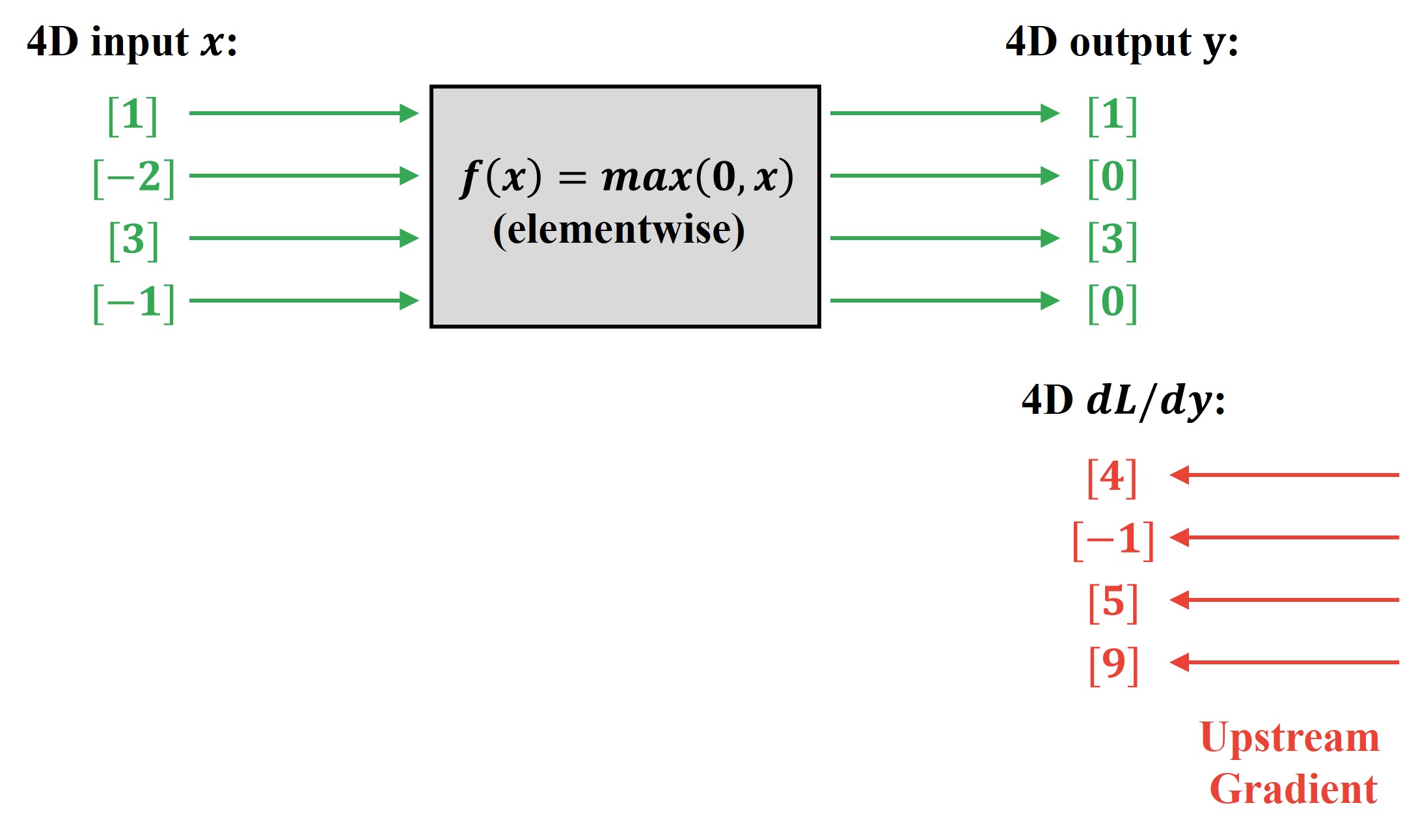 As we discussed earlier, this upstream gradient will tell us how much our Loss \(L\) will change with a small change in each element of the output vector of our ReLu function. These upstream gradient vector element values can be arbitrarily positive or negative and do not affect our backpropagation.
As we discussed earlier, this upstream gradient will tell us how much our Loss \(L\) will change with a small change in each element of the output vector of our ReLu function. These upstream gradient vector element values can be arbitrarily positive or negative and do not affect our backpropagation.
Next, our local Jacobian matrix tells us how our ReLu output vector elements change with respect to changes in each element of the input vector.

There is something interesting that we can observe from the local Jacobian matrix of our elementwise ReLU function we see above. It is evident that the change in each element of the output is affected only by the corresponding input element. In simpler words, the first element of the input vector \(x\) has influence only on the first element of the output vector \(y\) and no other output element. Similarly, the second input element influences only and only the second output element. And, so on.
As a result, the local Jacobian matrix of the elementwise ReLU function is diagonal.
Now, we multiply this local Jacobian matrix with the upstream gradient vector to compute the downstream gradient vector as shown below.
This downstream gradient vector will now serve as an input to another ReLU computational node and the process will continue.
Implicit Multiplication of the Jacobian Matrix
As we noticed above, the local Jacobian matrix of the ReLU function turned out to be sparse, which means it had a lot of zeros. This is a very common case with most of the functions that we use in Deep Learning.
Therefore, in such scenarios, we will almost never form these Jacobian matrices explicitly. Simply put, we never perform the multiplication between the local Jacobian matrix and the upstream gradient vector explicitly and always use implicit multiplication.
While it may not look too much in the case of the example of ReLU function above where only 4 elements were taken in the input vector \(x\), it becomes a tedious task to handle the sparse Jacobian matrix when there are hundreds of elements in the input vector and in turn, thousands of zeros within the local Jacobian matrix.
Performing a multiplication with such a massively sparse Jacobian matrix is super-wasteful and extremely inefficient. This is why, we formulate a way to express these local Jacobian matrices such that the multiplication with the upstream gradient vector becomes implicit and thus, more efficient.
In the case of the ReLU example above, this implicit multiplication process can be seen below.

Note that in the example of the ReLU function, the diagonal values of the local Jacobian matrix are either 1 or 0. Therefore, the implicit multiplication will work by either passing on the value of the upstream gradient when it is positive and passing on zero value when the upstream gradient value is negative.
Now that we have understood how backpropagation works with vectors, let us learn how we can perform backpropagation in the case of tensors.
4. Backpropagation With Tensors
We have a fair knowledge of the backpropagation process when it comes to dealing with vectors. However, we often work with tensors with rank greater than 1, matrices, 3D tensors, 4D tensors, and tensors of other arbitrary dimensions, as well. Have a look at the visualization of a forward propagation in the case of a tensor node.
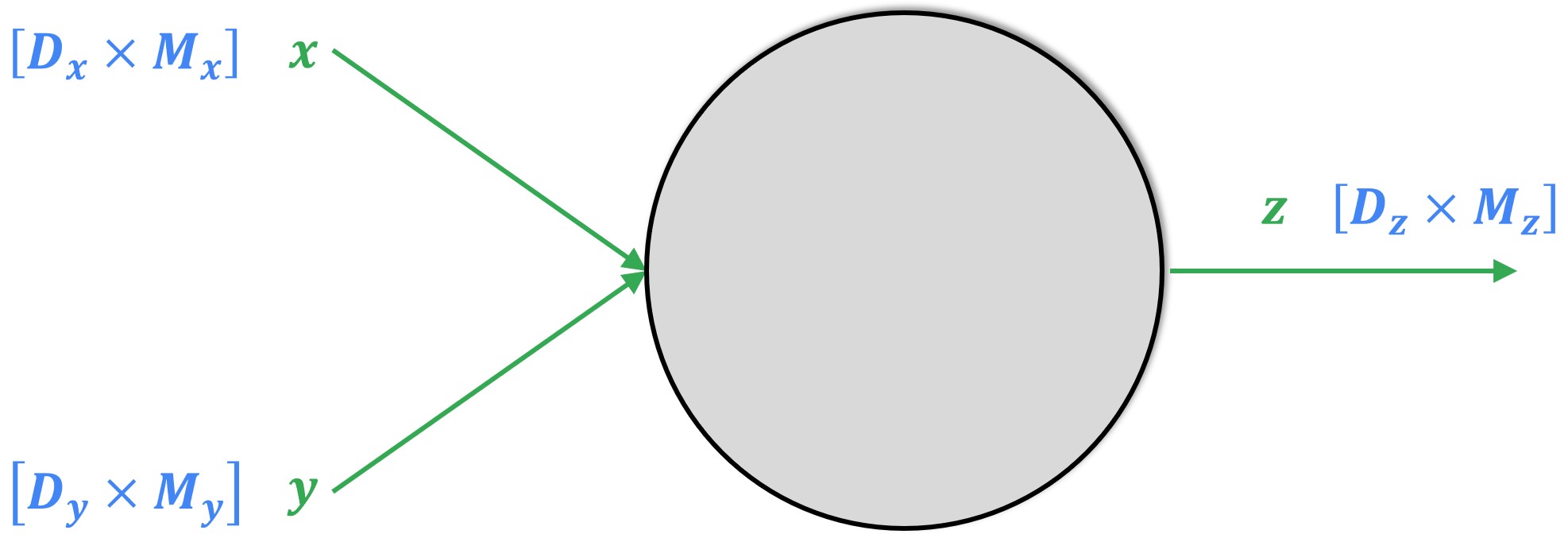
Here, the local function \(f\) takes two matrices as input, \(x\) of dimension \(D_x \times M_x\) and \(y\) of dimension \(D_y \times M_y\) respectively. The output for this local function will also be a matrix \(z\) of dimension \(D_z \times M_z\).
As we learned above, the loss \(L\) will still be a scalar and the gradient tensor of this loss with respect to \(x\) will be of the same shape as \(x\).
Following the same backpropagation method, we will input our upstream gradient to the local function as follows.
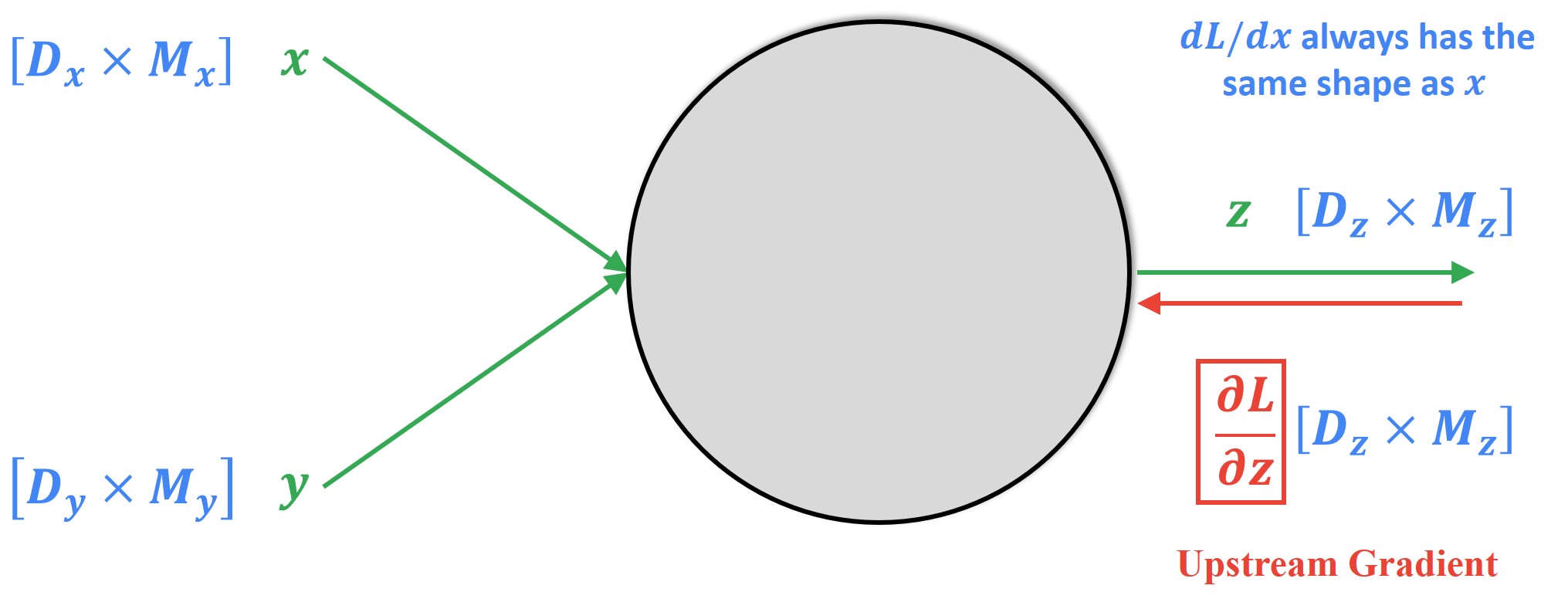
Now, the local Jacobian matrices here will tell us how much each scalar element of inputs \(x\) and \(y\) will influence each scalar element of the output \(x\).

And, finally, the downstream gradient tensors will be computed using the matrix-vector multiplication of the local Jacobian matrices with the upstream gradient tensors. Being a general formula, this multiplication process involves flattening of the high-level tensors of the output as well as the input into a giant vector to finally achieve the upstream gradients.
Notice how we have landed at the same Jacobian matrix problem again where the matrix is extremely sparse. Looking at the multiplication, it looks quite complicated to be able to express it into an implicit multiplication.
So how do we simplify this multiplication process? Let us understand using an example.
Implicit Matrix Multiplication
Let us see how we can obtain a general process for deriving backpropagation operations and simplifying the otherwise complicated high-order multiplications pertaining to arbitrary tensors. Have a look at the example given below.
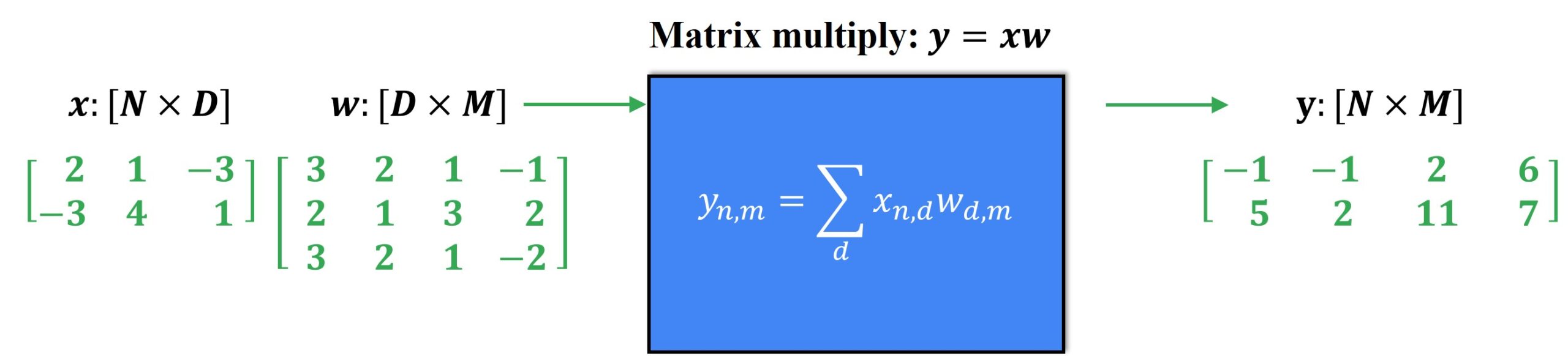
Observe the forward propagation above wherein the \(2\times3 \) input matrix \(x\) and the \(3\times4 \) input matrix \(w\) produce a \(2\times4 \) output matrix \(y\). Let us see the visualization for the backpropagation process.
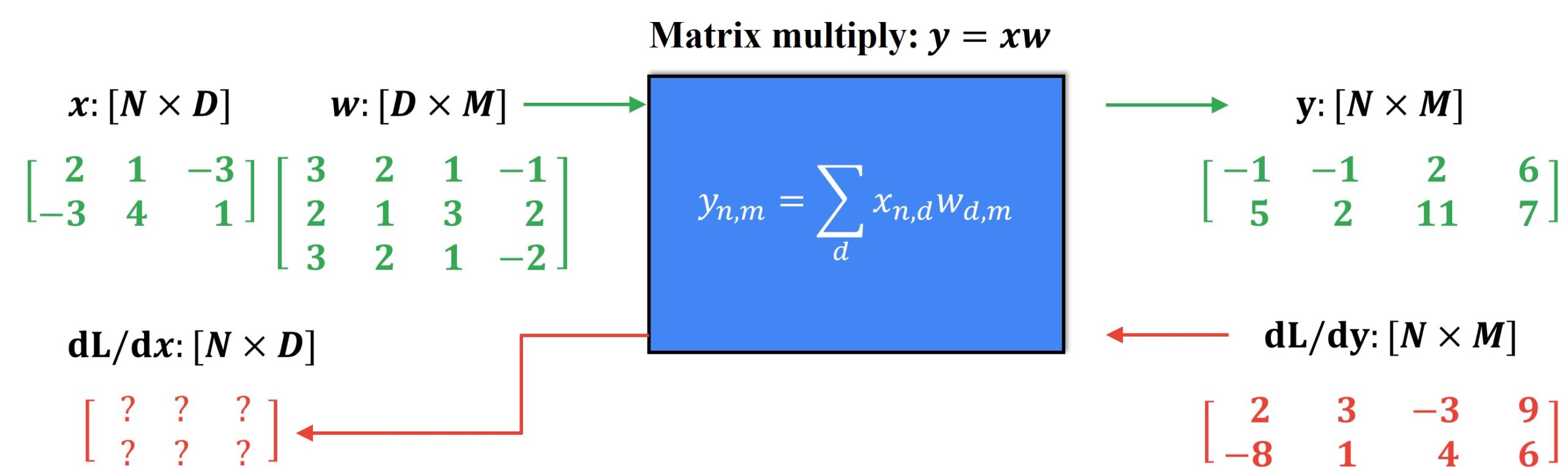
We have received an upstream gradient \(2\times4 \) matrix from somewhere within the computational graph and it is inputted into the node. To calculate the \(2\times3 \) downstream gradient matrix, we need to figure out the local Jacobian matrices and then multiply them with the upstream gradient.
Usually, the calculation for local Jacobian matrices would look something like this.
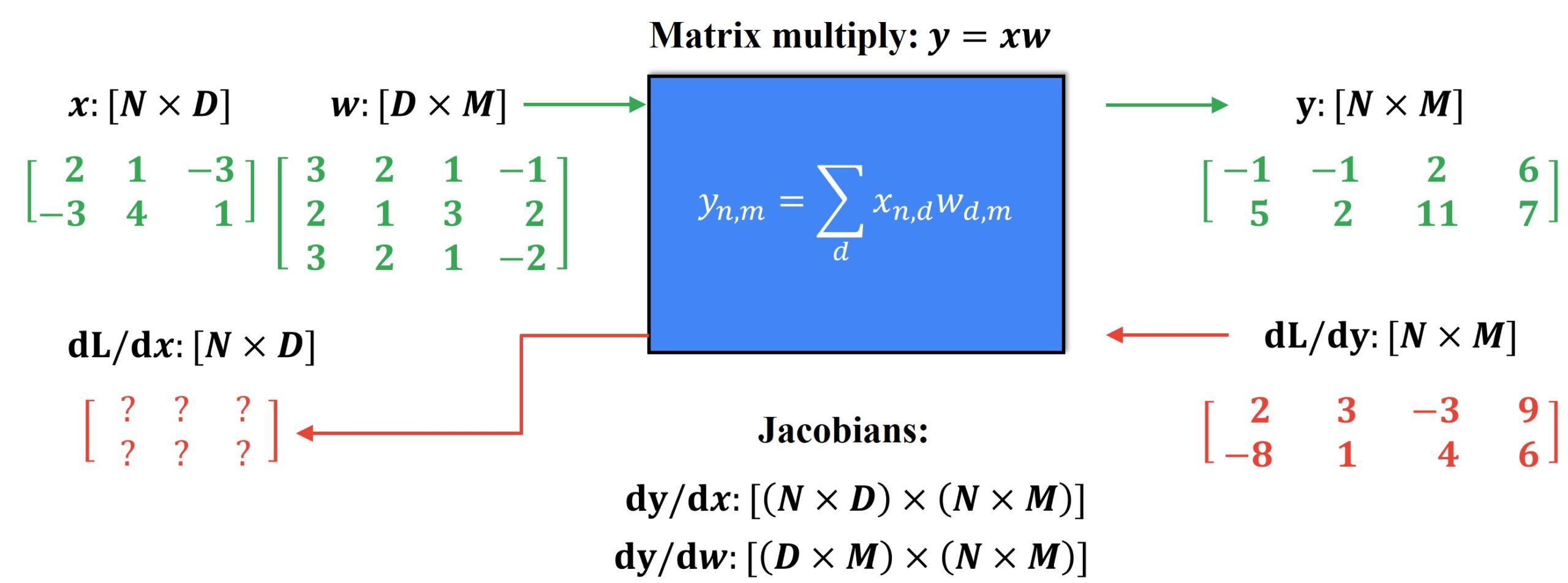
Now, for a more common neural network, the dimensions will be quite big such as \(N = 64\) and \(D=M=4096\), and each Jacobian matrix will take up 256 GB of memory. Therefore, we need to perform multiplication implicitly and more efficiently to save up memory.
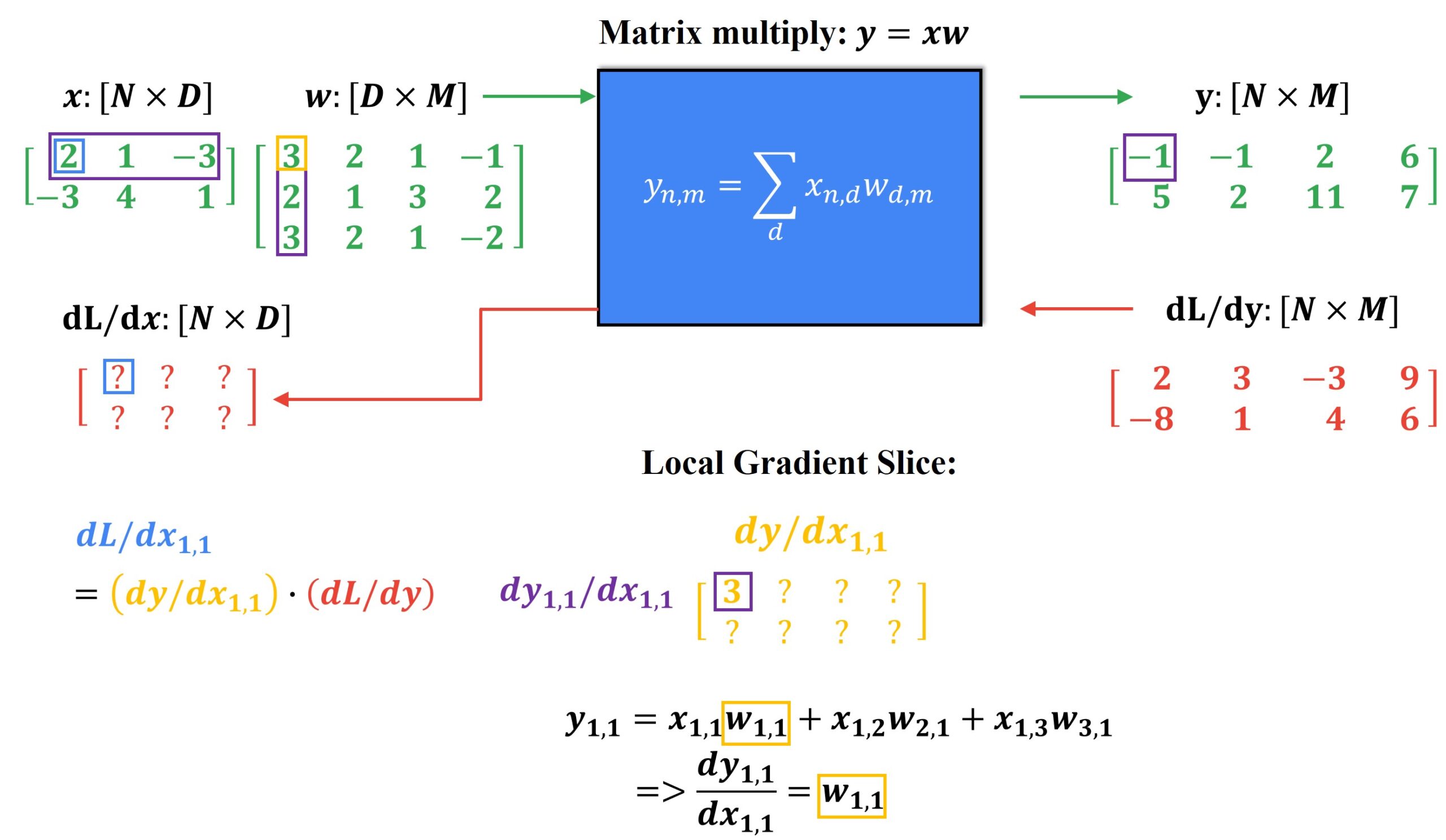
Here, instead of multiplying the entire shape of the Jacobian matrix to the entire shape of the upstream gradient, we only compute a slice of the local gradient where the derivative is calculated with respect to a scalar value.
We start by computing each element \(y_{1,1}\) and finding the change in this element with respect to \(x_{1,1}\) as follows.
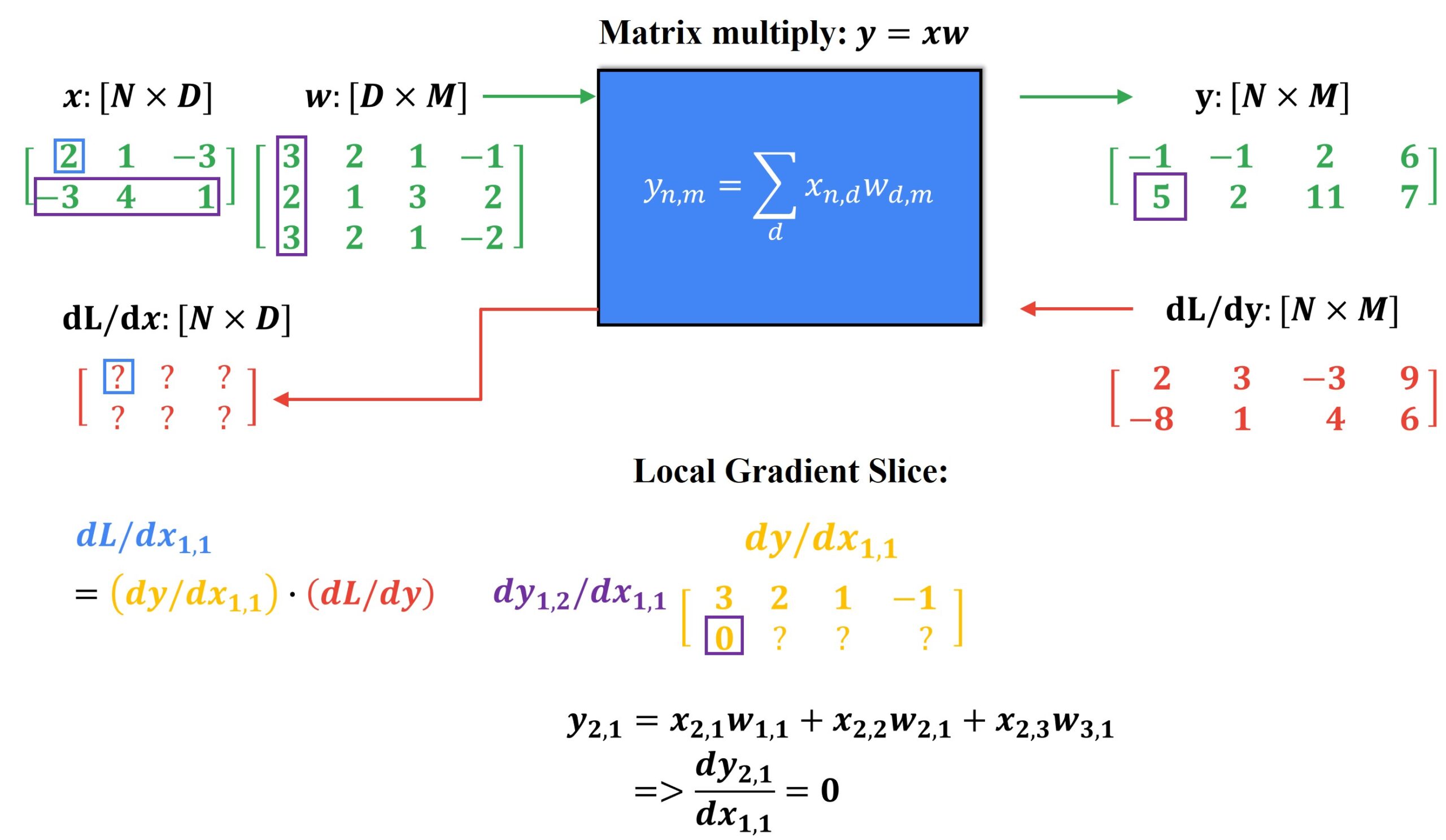
We can repeat the same process for each element in the first row of our local gradient slice and receive the entire local gradient slice. Here, we can see a pattern where the first pow of the local gradient slice is just copying over the first row of the weight matrix \(w \).

Now, we can compute the first element of the second row of the local gradient slice. What is interesting here is that equation for calculating the output doesn’t involve \(x_{1,1} \) term at all. Therefore the local gradient is equal to 0. This pattern will repeat for all elements in the second row of the local gradient slice.
Using this local gradient slice, we can compute one element or a slice of the downstream gradient as shown below.
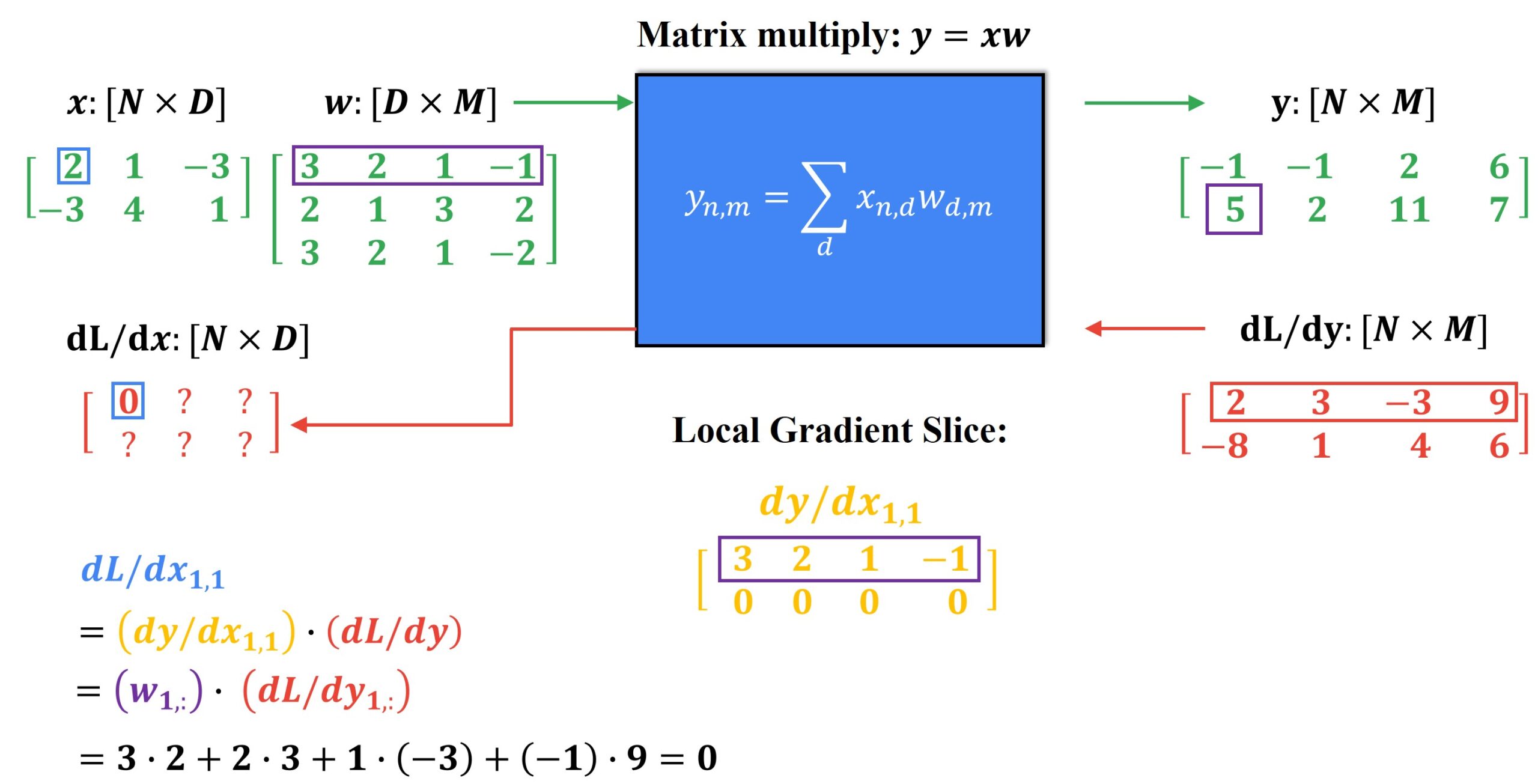
If you notice the above process carefully, you can notice that ultimately the value of one element of the downstream gradient depends only upon one of the rows of the weight matrix \(w\) and one of the rows of the upstream gradient matrix. To generalize this entire process, we can write the expression for computing the downstream gradient using elementwise multiplication, as follows.
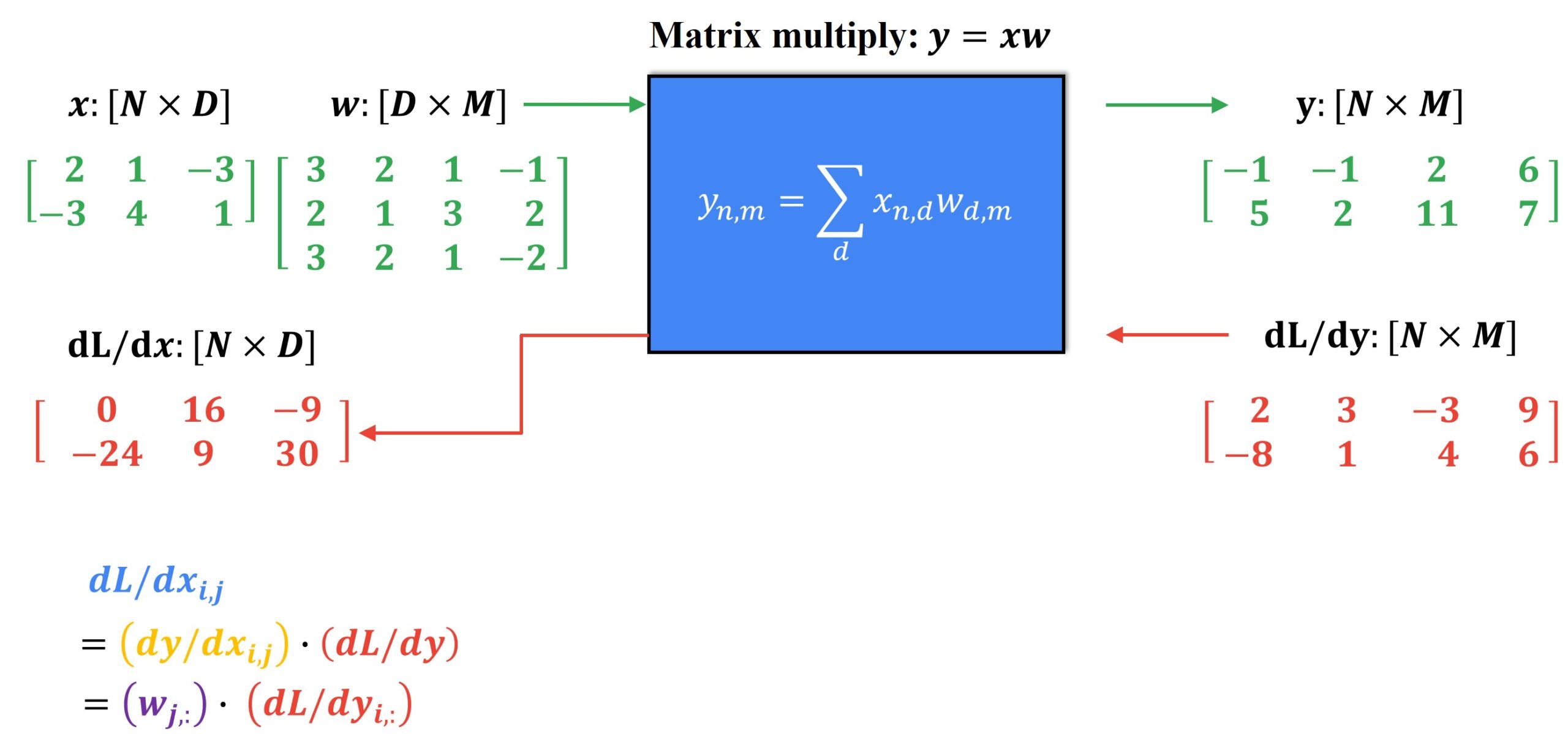
We can simplify this even further in the form of a matrix product, as given below.
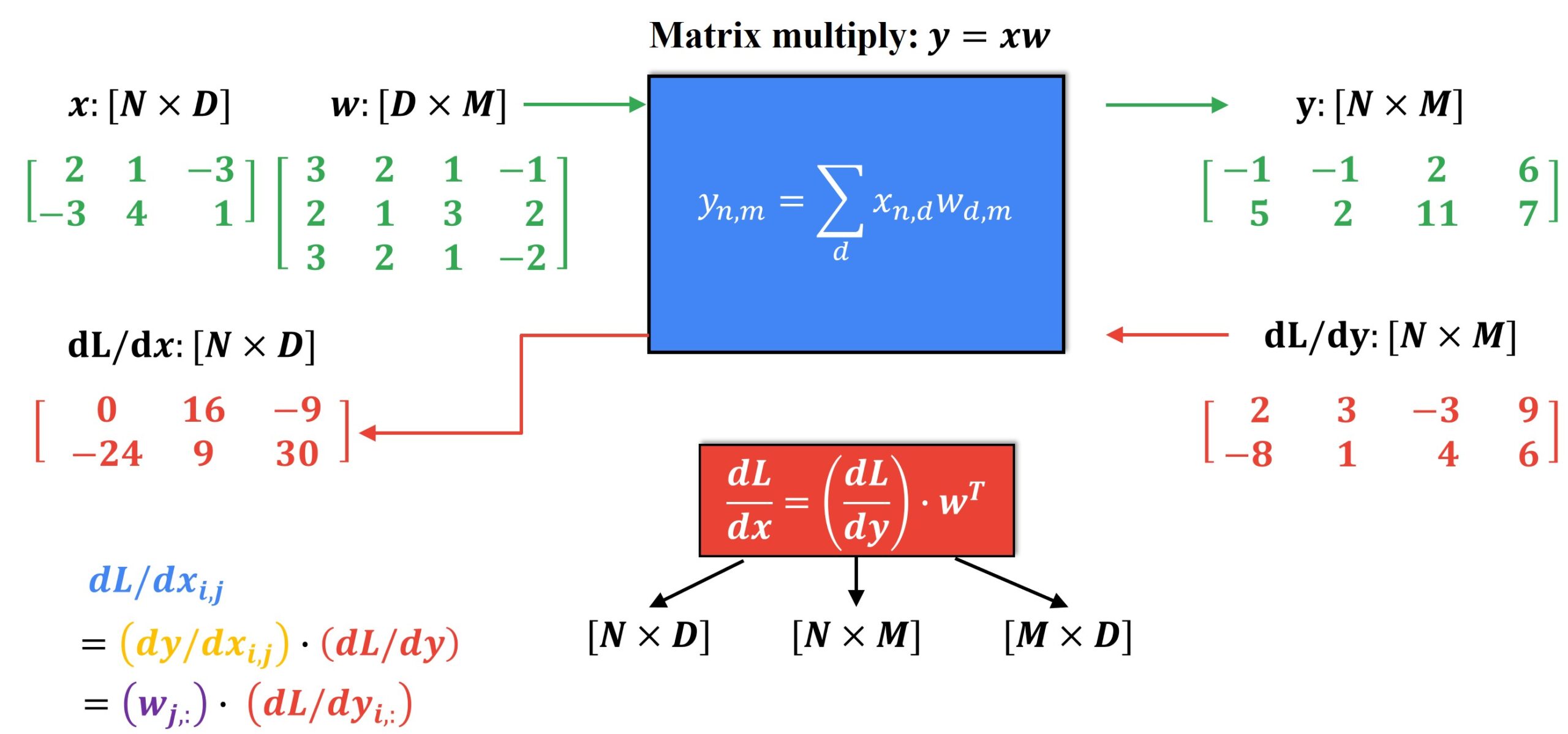
So, this is how we perform an efficient implicit multiplication without forming the Jacobian explicitly. Now, let’s see how we can apply backpropagation with vectors and tensors in Python with PyTorch.
5. Backpropagation with vectors and tensors in Python using PyTorch
Backpropagation with vectors in Python using PyTorch
First we will import the necessary libraries.
import torch
import numpy as np
import matplotlib.pyplot as pltIn the first example, we will see how to apply backpropagation with vectors. We will define the input vector X and convert it to a tensor with the function torch.tensor(). Here, we will set the requires_grad parameter to be True which will automatically compute the gradients for us.
x = torch.tensor([1.,-2.,3.,-1.], requires_grad=True)Next, we will apply the torch.relu() function to the input vector X. The ReLu stands for Rectified Linear Activation Function. As we already explained it is an element-wise linear function that outputs the positive input values as they are, and negative input values as zero. As you can see our input vector x=[1.,-2.,3.,-1.] is returned as y =[1.,0.,3.,0.].
y = torch.relu(x)
print(y)Output:
tensor([1., 0., 3., 0.], grad_fn=<ReluBackward0>)Now we will create the upstream gradient dl_over_dy and apply the backpropagation step using the .backward() function. As a parameter to this function, we will pass the upstream gradient. In that way, we will automatically multiply this local Jacobian matrix with the upstream gradient and get the downstream gradient vector as a result.
dL_over_dy = torch.tensor([4,-1,5,9])
y.backward(dL_over_dy )x.gradOutput:
tensor([4., 0., 5., 0.])Backpropagation with tensors in Python using PyTorch
Now, let’s see how to apply backpropagation in PyTorch with tensors. Again we will create the input variable X which is now the matrix of size \(2\times3 \). We will also create the weight matrix W of size \(3\times4 \). Then, we will multiply X and W using the function torch.matmul(). In this way, we will produce the output Y of size \(2\times4 \).
X = torch.tensor( [[2.,1.,-3], [-3,4,2]], requires_grad=True)
W = torch.tensor( [ [3.,2.,1.,-1] , [2,1,3,2 ] , [3,2,1,-2] ], requires_grad=True)Y = torch.matmul(X, W)
print(Y)Output:
tensor([[-1., -1., 2., 6.],
[ 5., 2., 11., 7.]], grad_fn=<MmBackward>)Here, we can check the shape of the input matrix X, weight matrix W, and output matrix Y.
print(X.shape, W.shape, Y.shape)Output:
torch.Size([2, 3]) torch.Size([3, 4]) torch.Size([2, 4])Now we will create the upstream gradient dl_over_dy with the following code.
dL_over_dy = torch.tensor( [[2,3,-3,9],[-8,1,4,6]])
print(dL_over_dy, dL_over_dy.shape)Output:
tensor([[ 2, 3, -3, 9],
[-8, 1, 4, 6]]) torch.Size([2, 4])Finally, we can apply the backpropagation step using the .backward() function and calculate the downstream gradient.
Y.backward(dL_over_dy)
print(X.grad)Output:
tensor([[ 0., 16., -9.],
[-24., 9., -30.]])As you can see we obtained the same result as we did previously in the theoretical part of the post.
Well, that’s it. You now possess the basic understanding of backpropagation in computational graphs, not just using scalars but also vectors, matrices, and tensors. Now, you can work with tensors of any arbitrary dimensions by just keeping one important thing in mind: always go for implicit multiplication. Before you close the tab, let’s quickly revise today’s tutorial post.
Summary
We have come to the end of another fantastic concept. We hope you are learning as fast as we are making these posts. If you have any conceptual doubts, feel free to comment on this post or write to us directly. We will continue to learn great machine learning and deep learning concepts with many more such interesting posts. So, stay tuned and keep propagating! 🙂