#006 PyTorch – Solving the famous XOR problem using Linear classifiers with PyTorch

Highlights: One of the most historical problems in the Neural Network arena is the classic XOR problem where predicting the output of the ‘Exclusive OR’ gate becomes increasingly difficult using traditional linear classifier methods.
In this post, we will study the expressiveness and limitations of Linear Classifiers, and understand how to solve the XOR problem in two different ways. So let’s begin.
Tutorial Overview:
- Logistic Regression Model
- Simple Logical Boolean Operator Problems
- The XOR Problem: Intuitive Solution
- The XOR Problem: Formal Solution
- Solving the XOR Problem in Python using PyTorch
This post is inspired by the following YouTube video [1]
1. Logistic Regression Model
Let’s start by refreshing our memory with the basic mathematical representation of the Logistic Regression Model as seen below.
$$ \hat{y}=\sigma\left(\mathbf{w}^{\top} \mathbf{x}\right) $$
$$ \sigma(z)=\frac{1}{1+e^{-z}} $$
The above expression shows that in the Linear Regression Model, we have a linear or affine transformation between an input vector \(x \) and a weight vector \(w \). The input vector \(x \) is then turned to scalar value and passed into a non-linear sigmoid function. This sigmoid function compresses the whole infinite range into a more comprehensible range between 0 and 1.
Using the output values between this range of 0 and 1, we can determine whether the input \(x\) belongs to Class 1 or Class 0.
Let’s understand this better using an example of 2D Logistic Regression.
Example: 2D Logistic Regression
For better understanding, let us assume that all our input values are in the 2-dimensional domain. Observe the expression below, where we have a vector \(x\) that contains two elements, \(x_1\) and \(x_2\) respectively.
$$ \hat{y}=\sigma\left(\mathbf{w}^{\top} \mathbf{x}+w_{0}\right) $$
$$ \sigma(z)=\frac{1}{1+e^{-z}} $$
$$ \text { Let } \mathbf{x} \in \mathbb{R}^{2} $$
For each of the element of the input vector \(x\), i.e., \(x_1\) and \(x_2\), we will multiply a weight vector \(w\) and a bias \(w_0\). We, then, convert the vector \(x\) into a scalar value represented by \(z\) and passed onto the sigmoid function.
Let us represent this example using a graph.
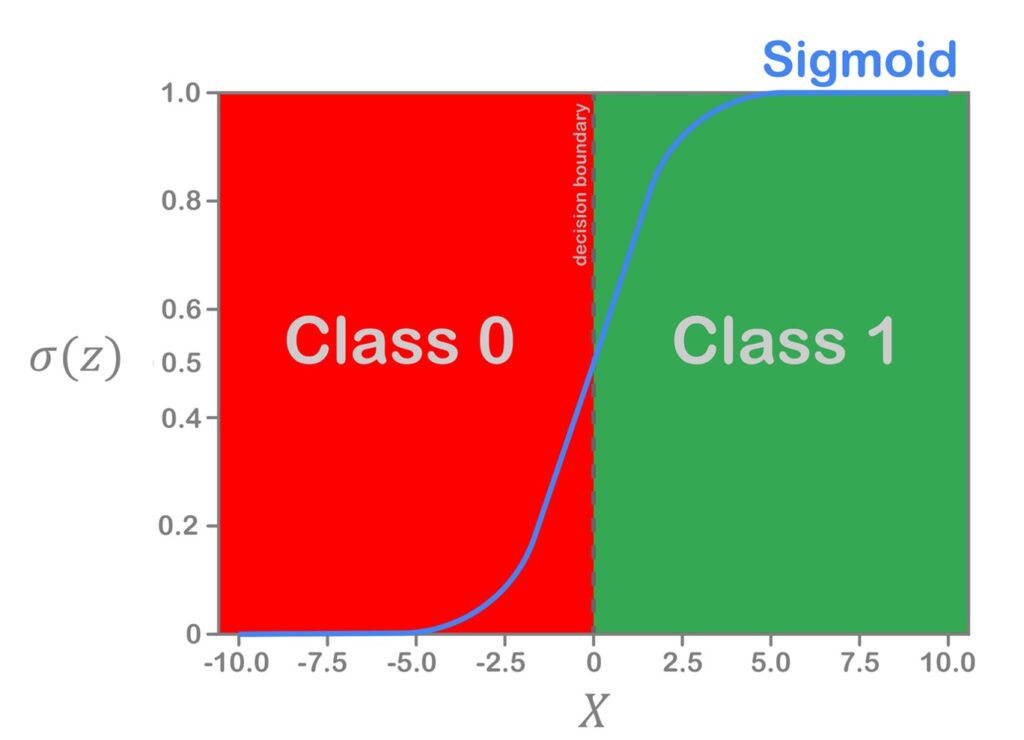
Notice how the Decision Boundary line for this example is exactly at 0. This is due to the fact that when \(z = 0 \), the sigmoid function changes from being below 0.5 to being above 0.5. In simpler words, the probability of the input belonging to Class 1 is higher on the right-hand side of the Decision Boundary line. And, the probability of the input belonging to Class 0 is higher on the left-hand side of the Decision Boundary line. The equation for this Decision Boundary line is written as follows.
$$ \mathbf{w}^{\top} \mathbf{x}+w_{0}=0 $$
To better visualize the above classification, let’s see the graph below.
A total of three scenarios arise as we can see above.
- If \(z<0\), where \(z= w^Tx+w_0\), we decide for Class 0
- If \(z=0\), where \(z= w^Tx+w_0\), we are at the Decision Boundary and uncertain of the Class
- If \(z>0\), where \(z= w^Tx+w_0\), we decide for Class 1
Now that we have a fair recall of the logistic regression models, let us use some linear classifiers to solve some simpler problems before moving onto the more complex XOR problem.
2. Simple Logical Boolean Operator Problems
Before we head over to understanding the problems associated with predicting the XOR operator, let us see how simple linear classifiers can be used to solve lesser complex Boolean operators.
The OR Problem
As seen above, the classification rule from our 2D logistic regression model is written as follows.
$$ \text { Class } 1 \Leftrightarrow \mathbf{w}^{\top} \mathbf{x}>-w_{0} $$
In the case of the OR operator, we have four possible inputs for the two elements of our input vector \(x\), namely \(x_1\) and \(x_2\) respectively. Let’s see how the OR operation outputs the result in the table below.
The above table can also be visualized in a graph, where the red points are representative of Class 0 and the green points represent Class 1.
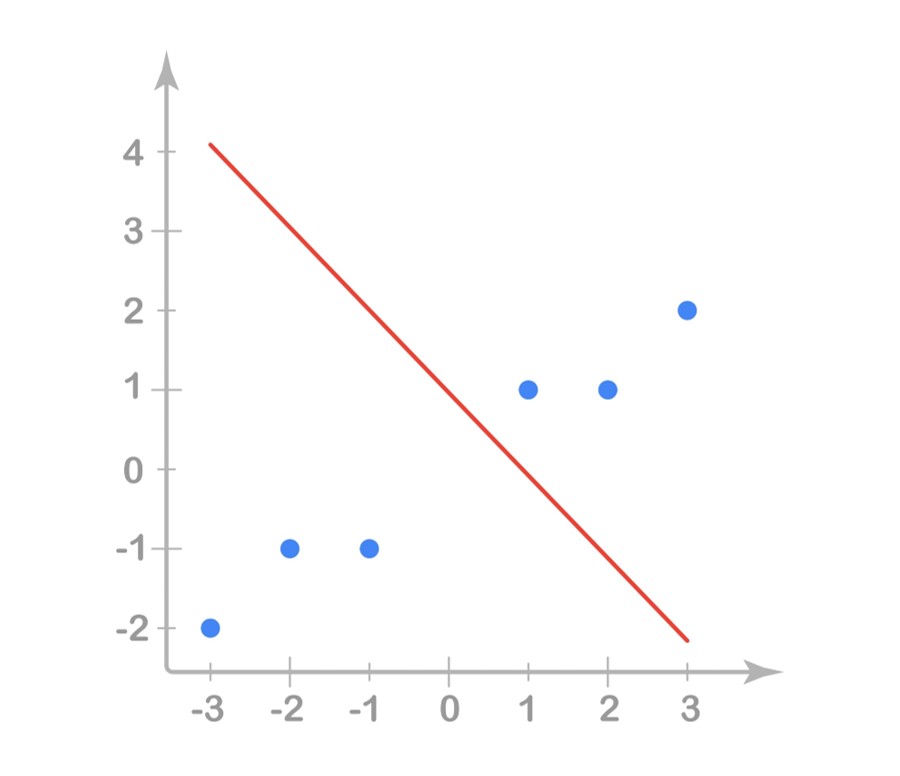
Now, in order to implement our classifier as seen above, we need to determine our two important parameters, the weight \(w\) and the bias \(w_0\) such that our decision boundary line clearly separates Class 1 (red) and Class 0 (green). Intuitively, it is not difficult to imagine a line that will separate the two classes.
Using some trial and error along with some intuition, we can arrive at suitable values for our parameters such that our weight \(w = (1,1)\) and our bias \(w_0 = -0.5\). Let’s see how our decision boundary line looks.
So, we have successfully classified the OR operator. Let’s see how we can perform the same procedure for the AND operator.
The AND Problem
Similar to the process we followed above, we can draw a decision table for the AND operator as follows: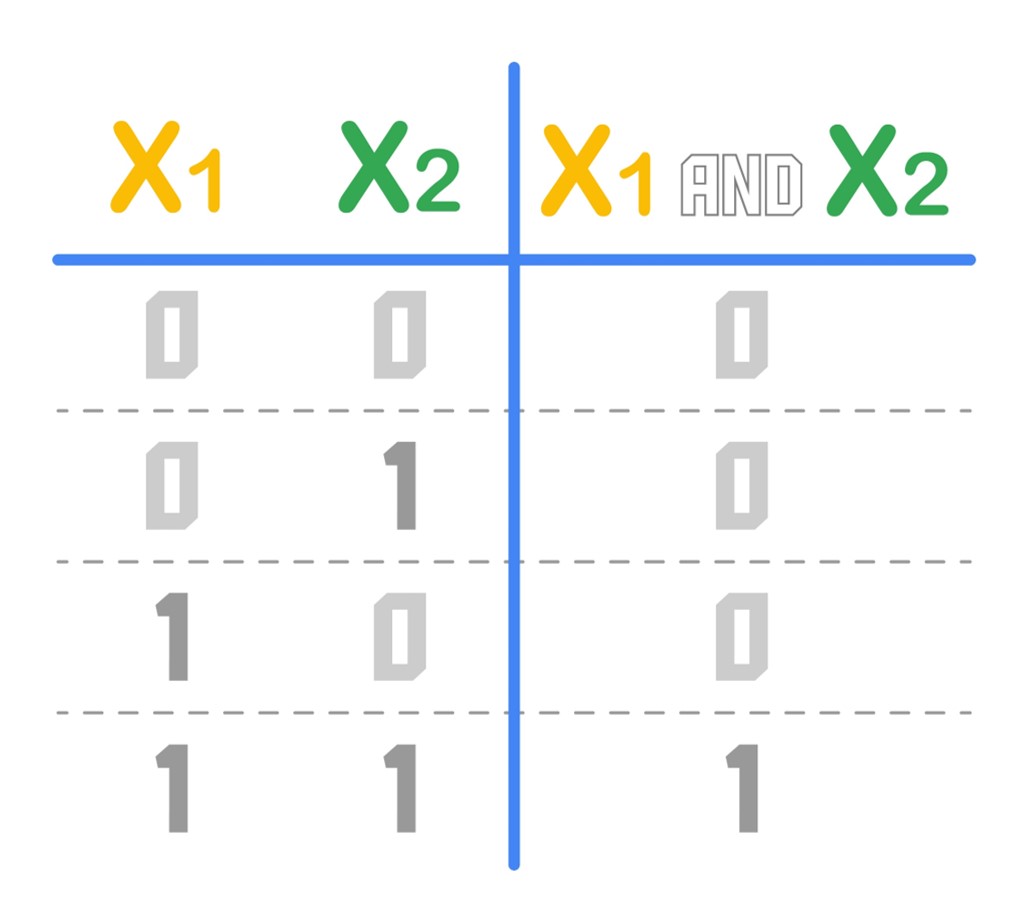
This can also be visualized in the form of a graph, where red dots signify Class 0 and the green ones represent Class 1.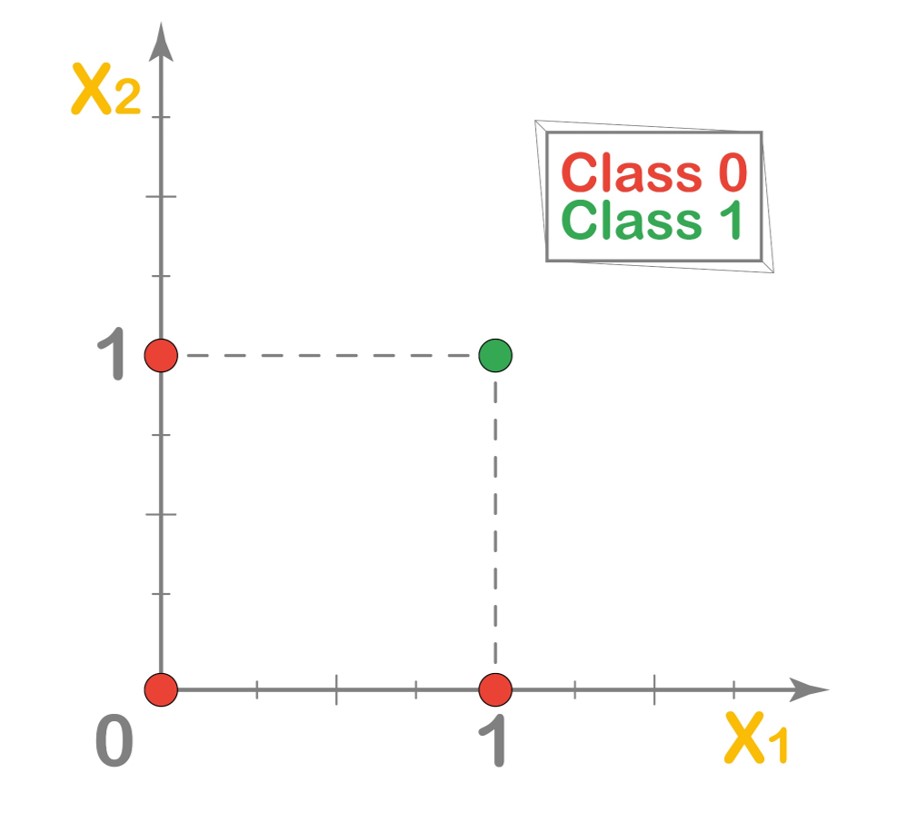
Again, our main task is to determine the optimal parameters, the weight \(w\) and the bias \(w_0\) to draw a decision boundary line separating the two classes. Using trial and error, and some intuition of course, we come to a conclusion that our parameter values should be \(w = (1,1)\) and \(w_0 = -1.5\) respectively. Let’s see how our decision boundary line appears on the graph.
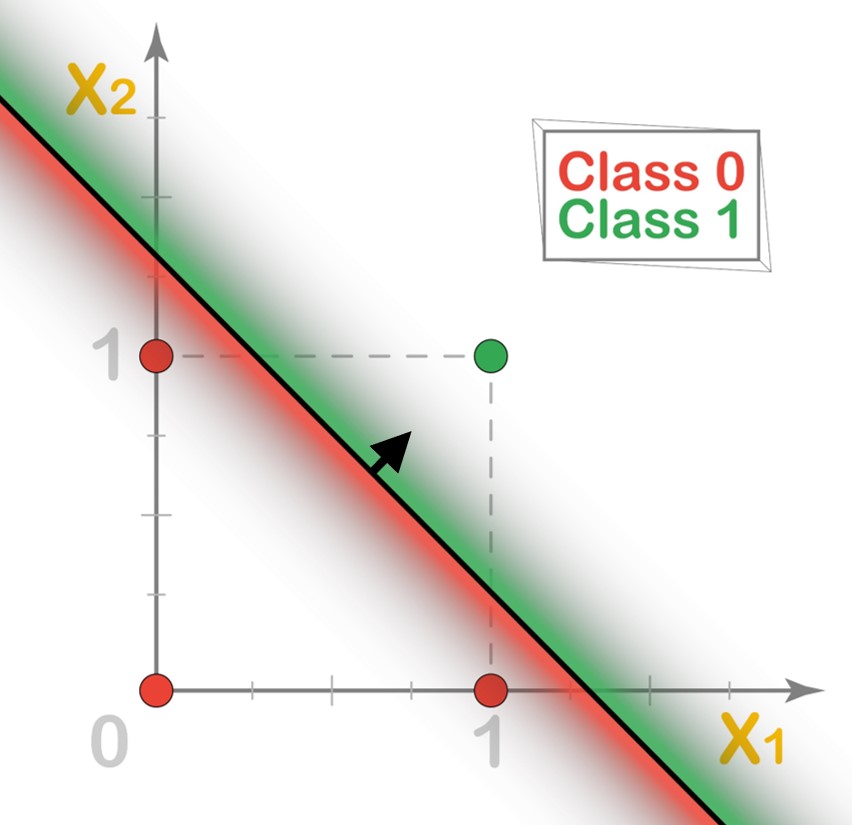
Great! Let’s look at NAND operation, next.
The NAND Problem
The decision table for the NOT AND or NAND operator looks like this: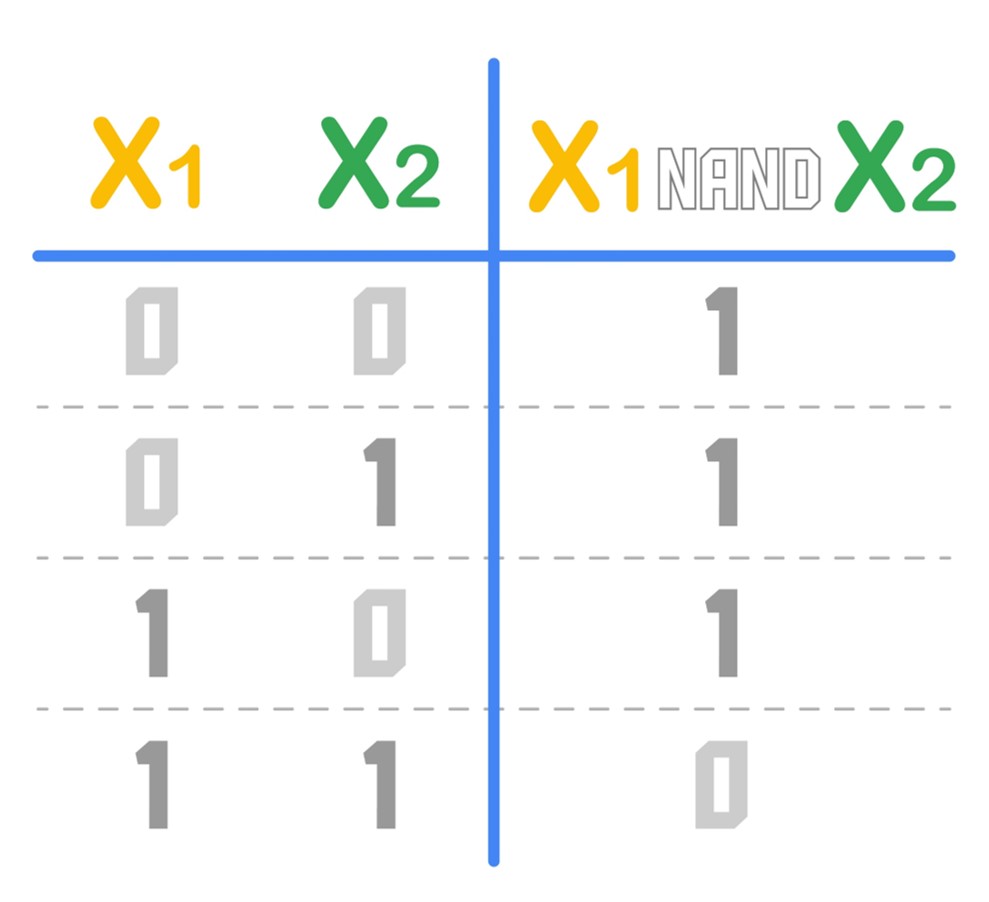
And, the graph of points with red points as Class 0 and green points as Class 1, can be seen below.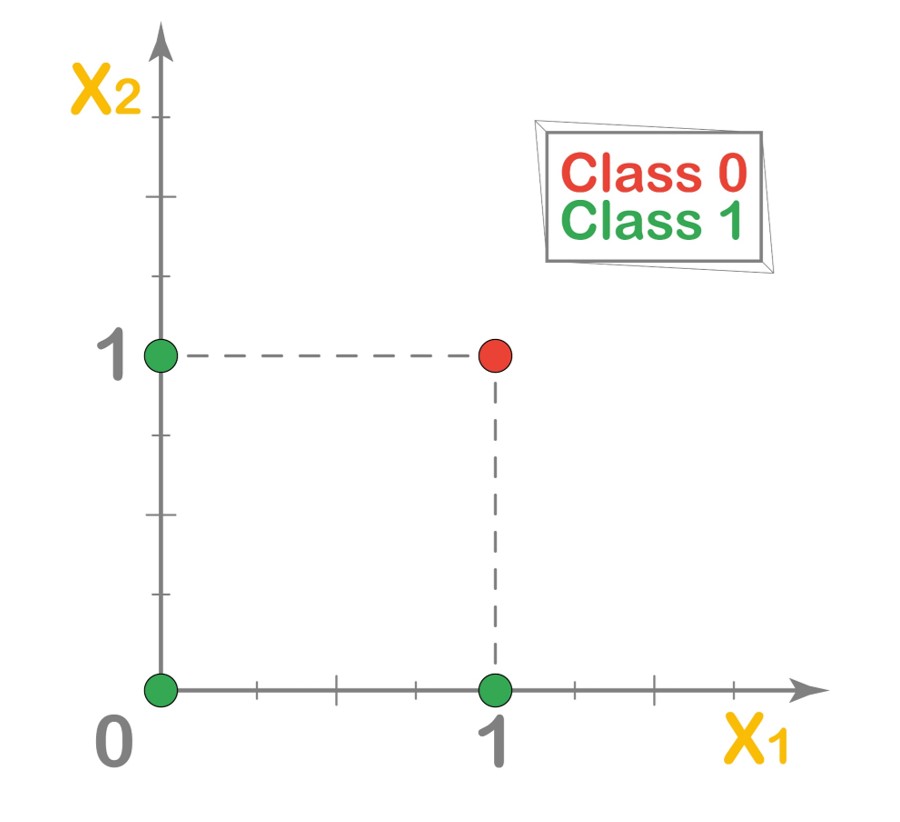
The values for our parameters that we can arrive at here are \(w = (-1,-1)\) and \(w_0 = 1.5\) such that the decision boundary line looks something like this.

As we saw above, simple linear classifiers can easily solve the basic Boolean operator problems. However, when it comes to the XOR operator, things start to become a little complex. Let’s move on to the classic XOR problem.
3. The XOR Problem: Intuitive Solution
Have a look at the decision table of the ‘Exclusive OR’ or XOR operator for our 2-dimensional input vector.
As you can see, the XOR operator outputs 1 only when the two elements are exclusive, i.e., have different values, and outputs 0 when the two elements are not exclusive, i.e., have the same values. Let’s represent the points on a graph where the red ones signify Class 0 and the green points are for Class 1.
Observe the points on the graph above. Our intuition fails to recognize a way to draw a decision boundary line that will clearly separate the two classes.
If we were to use the decision boundary line for the OR operator here, it will only classify 2 out of 3 points correctly.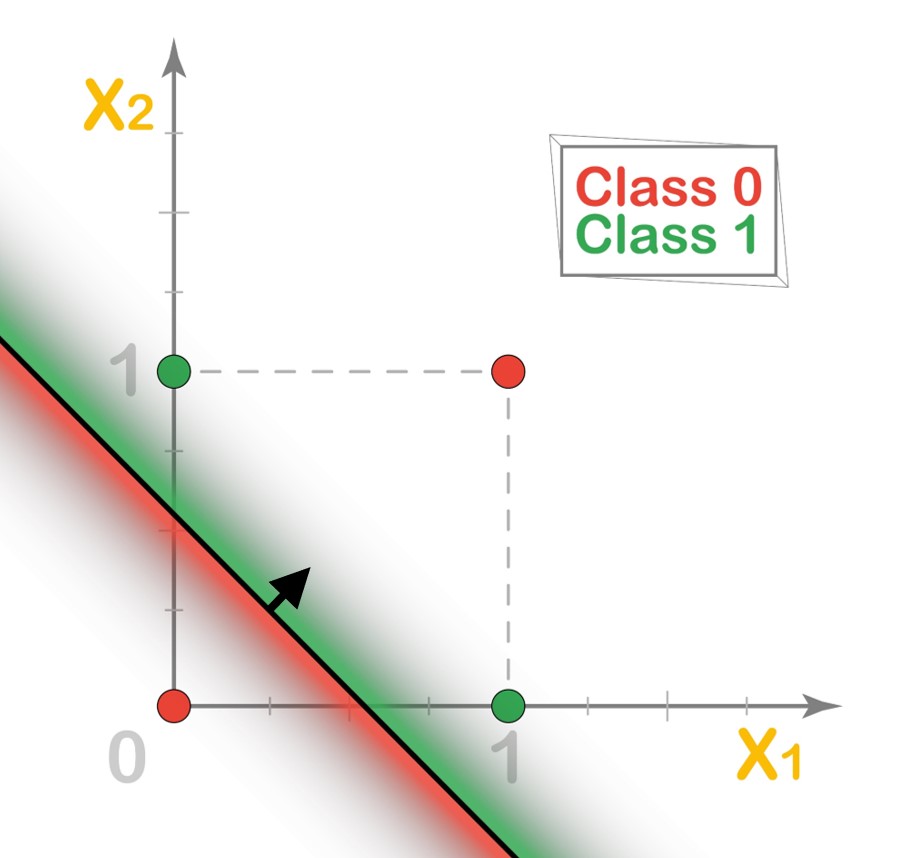
Similarly, if we were to use the decision boundary line for the NAND operator here, it will also classify 2 out of 3 points correctly.

It is evident that the XOR problem CAN NOT be solved linearly. This is the reason why this XOR problem has been a topic of interest among researchers for a long time.
However, more than just intuitively, we should also prove this theory more formally. We will take the help of Convex Sets to be able to prove that the XOR operator is not linearly separable. Let’s see how.
Convex Sets
Let’s consider a set \(S\).
The set \(S\) is said to be ‘convex’ if any line segment that joins two points within this set \(S\) lies entirely within the set \(S\). We can represent a convex set mathematically as follows:
$$ \mathbf{x}_{1}, \mathbf{x}_{2} \in \mathcal{S} \Rightarrow \lambda \mathbf{x}_{1}+(1-\lambda) \mathbf{x}_{2} \in \mathcal{S} $$
$$ \text { for } \quad \lambda \in[0,1] $$
Have a look at the two images below.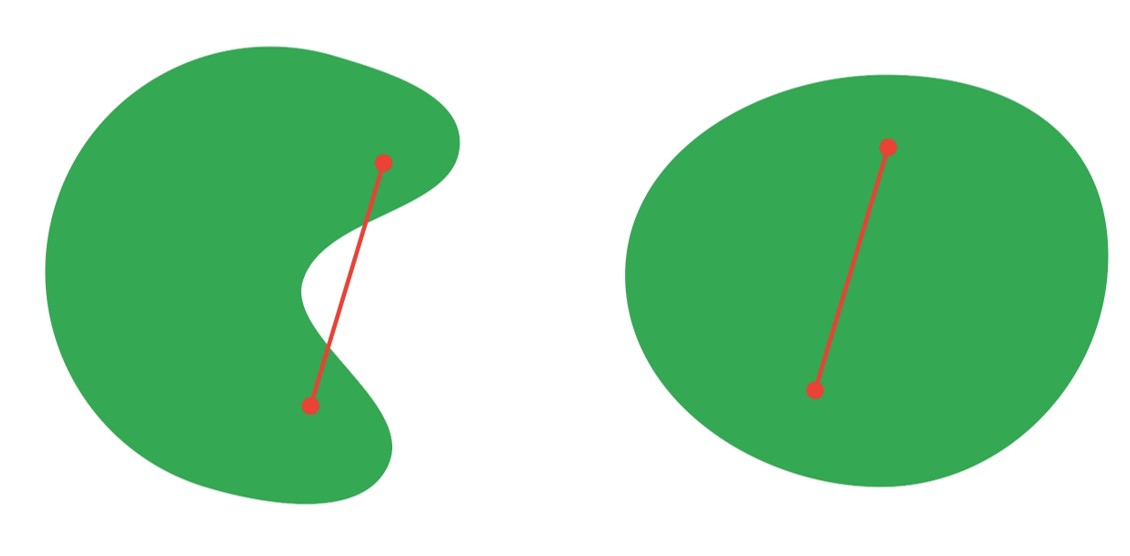
The image on the left cannot be considered to be a convex set as some of the points on the line joining two points from \(S\) lie outside of the set \(S\). On the right-hand side, however, we can see a convex set where the line segment joining the two points from \(S\) lies completely inside the set \(S\).
Now, convex sets can be used to better visualize our decision boundary line, which divides the graph into two halves that extend infinitely in the opposite directions. We can intuitively say that these half-spaces are nothing but convex sets such that no two points within these half-spaces lie outside of these half-spaces.
For our XOR problem, we can now assume that if the positive examples are in the positive half-space, the line segment in green will also be included within that half-space. And, similarly, the line segment in red will lie within the negative half-space.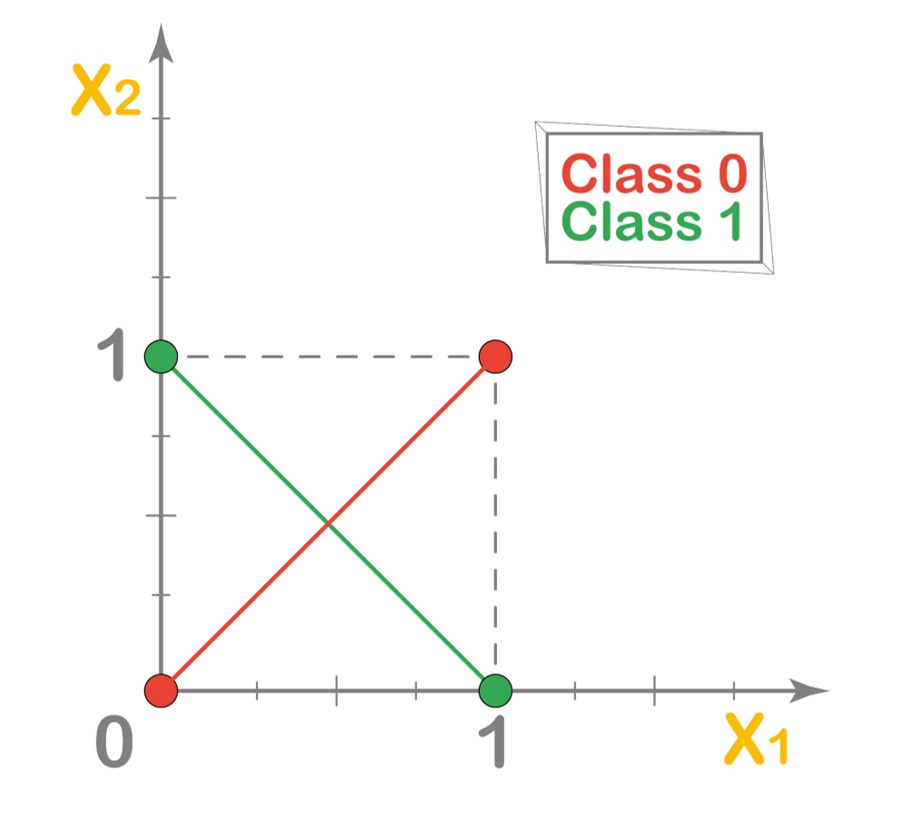
This is clearly a wrong hypothesis and doesn’t hold valid simply because the intersection point of the green and the red line segment cannot lie in both the half-spaces. This means that the intersection point of the two lines cannot be classified in both Class 0 as well as Class 1. Therefore, we have arrived at a contradiction.
This provides formal proof of the fact that the XOR operators cannot be solved linearly.
Historical Research On XOR
In the 1950s and the 1960s, linear classification was widely used and in fact, showed significantly good results on simple image classification problems such as the Perceptron.

Perceptron – an electronic device that was constructed in accordance with biological principles and showed an ability to learn [2]
However, with the 1969 book named ‘Perceptrons’, written by Minsky and Paper, the limitations of using linear classification became more apparent. It became evident that even a problem like the XOR operator, which looks simple on the face of it with just 4 data points, cannot be solved easily since the classifier models available to us at that time were only capable of making linear decisions.
Naturally, due to rising limitations, the use of linear classifiers started to decline in the 1970s and more research time was being devoted to solving non-linear problems.
Moving ahead, let’s study a Linear Classifier with non-linear features and see if it can help us in solving our XOR problem.
Linear Classifier with Non-Linear Features
In this case, we will consider an extended feature space such as the following:
$$ \mathbf{w}^{\top} \underbrace{\left(\begin{array}{c}x_{1} \\x_{2} \\x_{1} x_{2}\end{array}\right)}_{\psi(\mathbf{x})}>-w_{0} $$
Instead of an input vector \(x\), we will make use of a feature vector \(\psi (x)\) with three elements, \(x_1\), \(x_2\) and \(x_1 x_2\). Now, this changes our decision table for the XOR operator with some added features, as follows.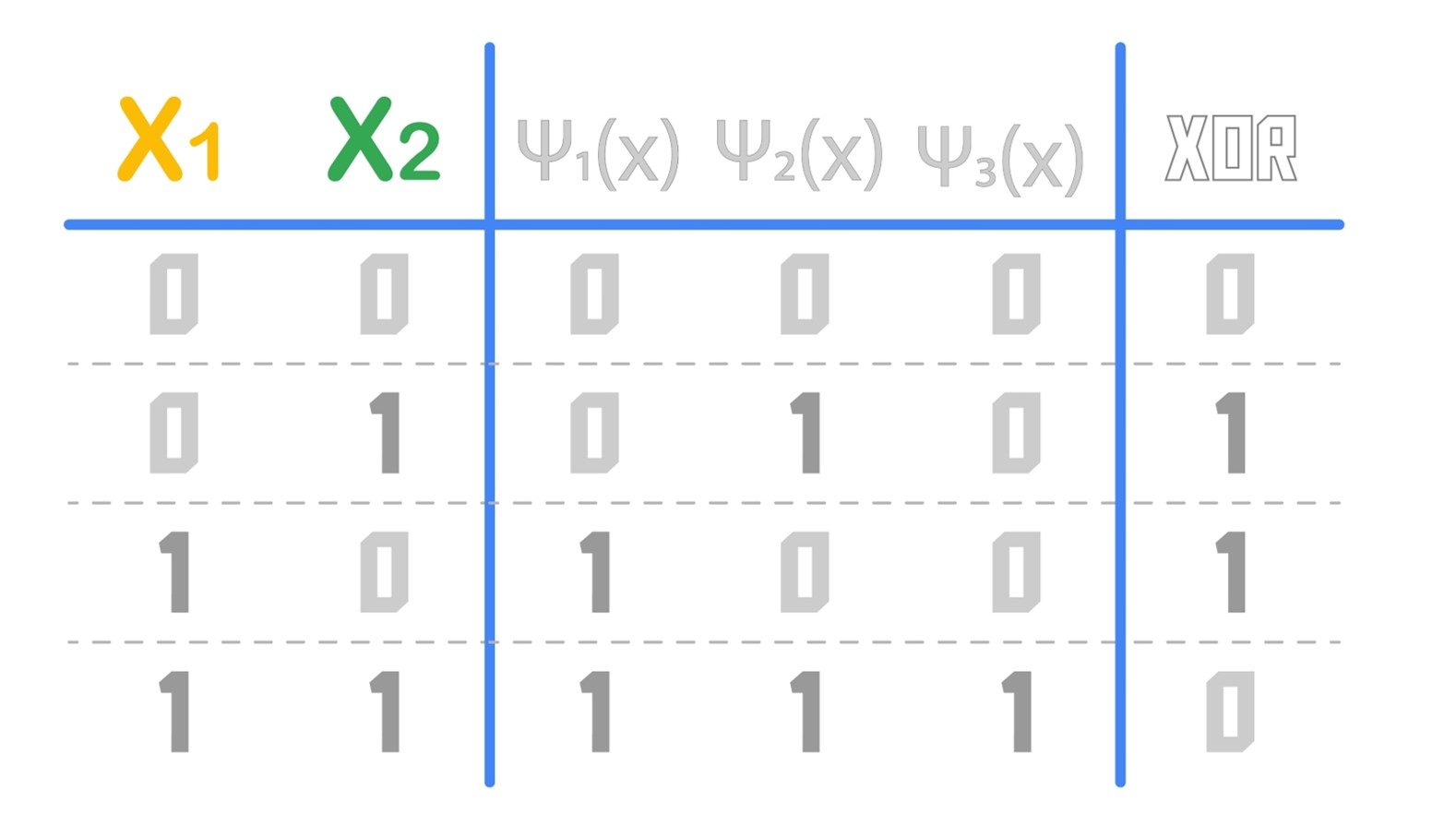
These non-linear features when represented on a 3-dimensional graph, allow linear classifiers to solve non-linear classification problems. This is analogous to polynomial curve fitting as well as Support Vector Machines wherein we use kernels to lift the feature vector space. Have a look at the 3-dimensional graph.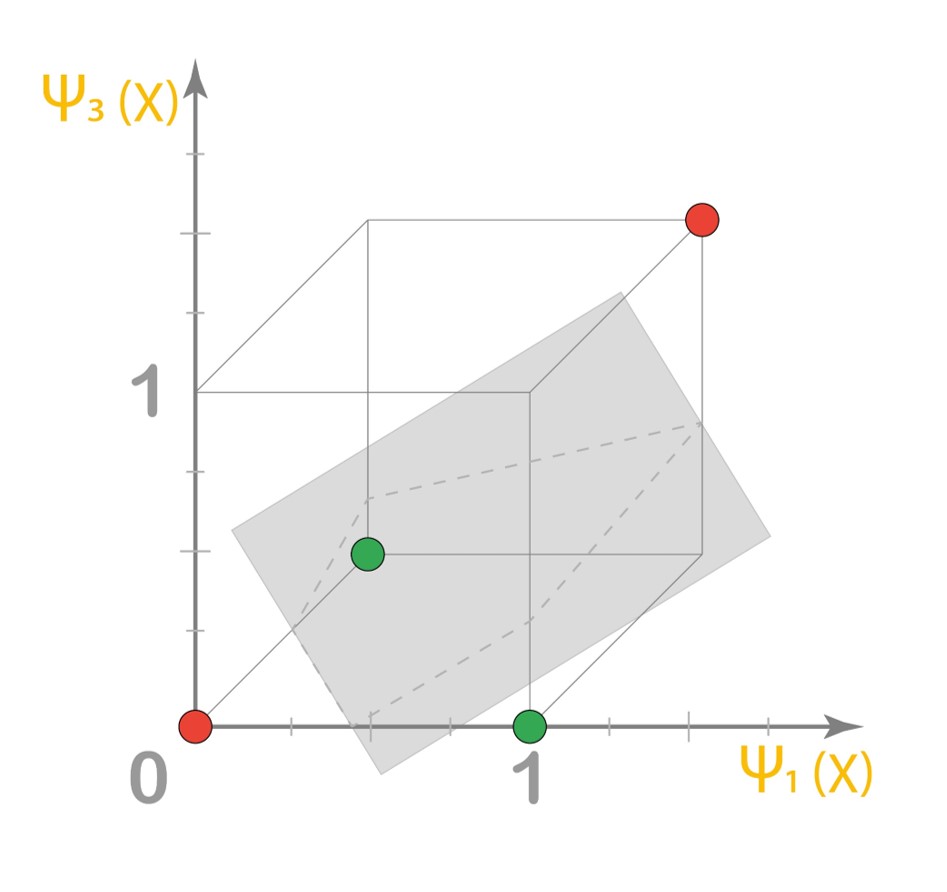
Observe how the green points are below the plane and the red points are above the plane. This plane is nothing but the XOR operator’s decision boundary.
So, by shifting our focus from a 2-dimensional visualization to a 3-dimensional one, we are able to classify the points generated by the XOR operator far more easily.
This exercise brings to light the importance of representing a problem correctly. If we represent the problem at hand in a more suitable way, many difficult scenarios become easy to solve as we saw in the case of the XOR problem. Let’s understand this better.
Representational Learning
Have a look at the two images below.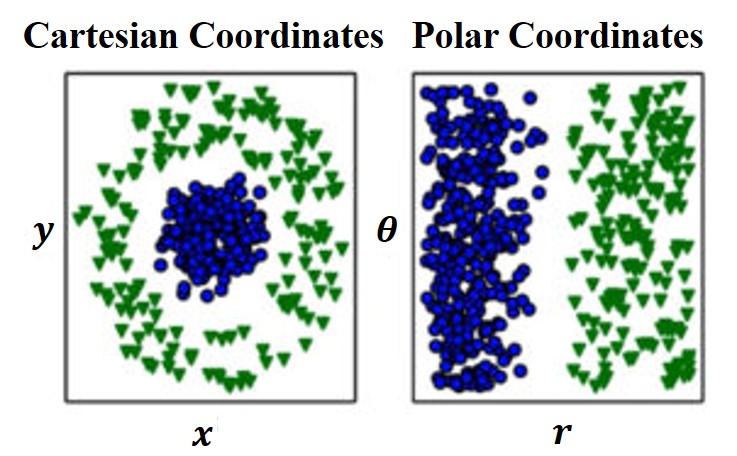
Notice the left-hand side image which is based on the Cartesian coordinates. There is no intuitive way to distinguish or separate the green and the blue points from each other such that they can be classified into respective classes.
However, when we transform the dataset to Polar coordinates, i.e., represent them in terms of radius and angle, we can notice how it becomes intuitively possible to draw a linear decision boundary line that classifies each point separately.
Representing data to help you make better decisions while creating your models is what Deep Learning is all about. But, how does one choose the right transformation?
Until the 2000s, choosing the transformation was done manually for problems such as vision, speech, etc. using histogram of gradients to study regions of interest. Having said that, today, we can safely say that rather than doing this manually, it is always better to have your model or computer learn, train, and decide which transformation to use automatically. This is what Representational Learning is all about, wherein, instead of providing the exact function to our model, we provide a family of functions for the model to choose the appropriate function itself.
Now that we have seen how we can solve the XOR problem using an observational, representational, and intuitive approach, let’s look at the formal solution for the XOR problem.
4. The XOR Problem: Formal Solution
One solution for the XOR problem is by extending the feature space and using a more non-linear feature approach. This can be termed as more of an intuitive solution. However, we must understand how we can solve the XOR problem using the traditional linear approach as well.
Let’s recall our original decision table and graph for the XOR operator. In the below figure, we can also see the decision boundary lines for the OR operator as well as the NAND operator, which only partially classify our points.
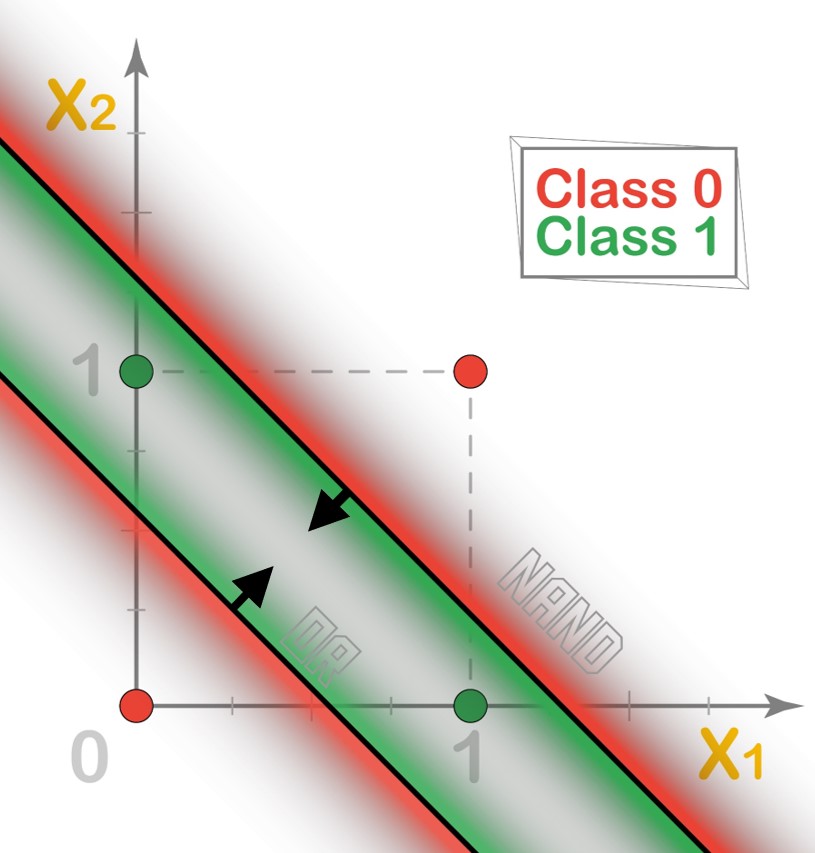
By combining the two decision boundaries of OR operator and NAND operator respectively using an AND operation, we can obtain the exact XOR classifier.
We can write this mathematically as follows:
$$ \begin{array}{c}\text { XOR }\left(x_{1}, x_{2}\right)= \\\text { AND(OR }\left(x_{1}, x_{2}\right), \text { NAND } \left.\left(x_{1}, x_{2}\right)\right)\end{array} $$
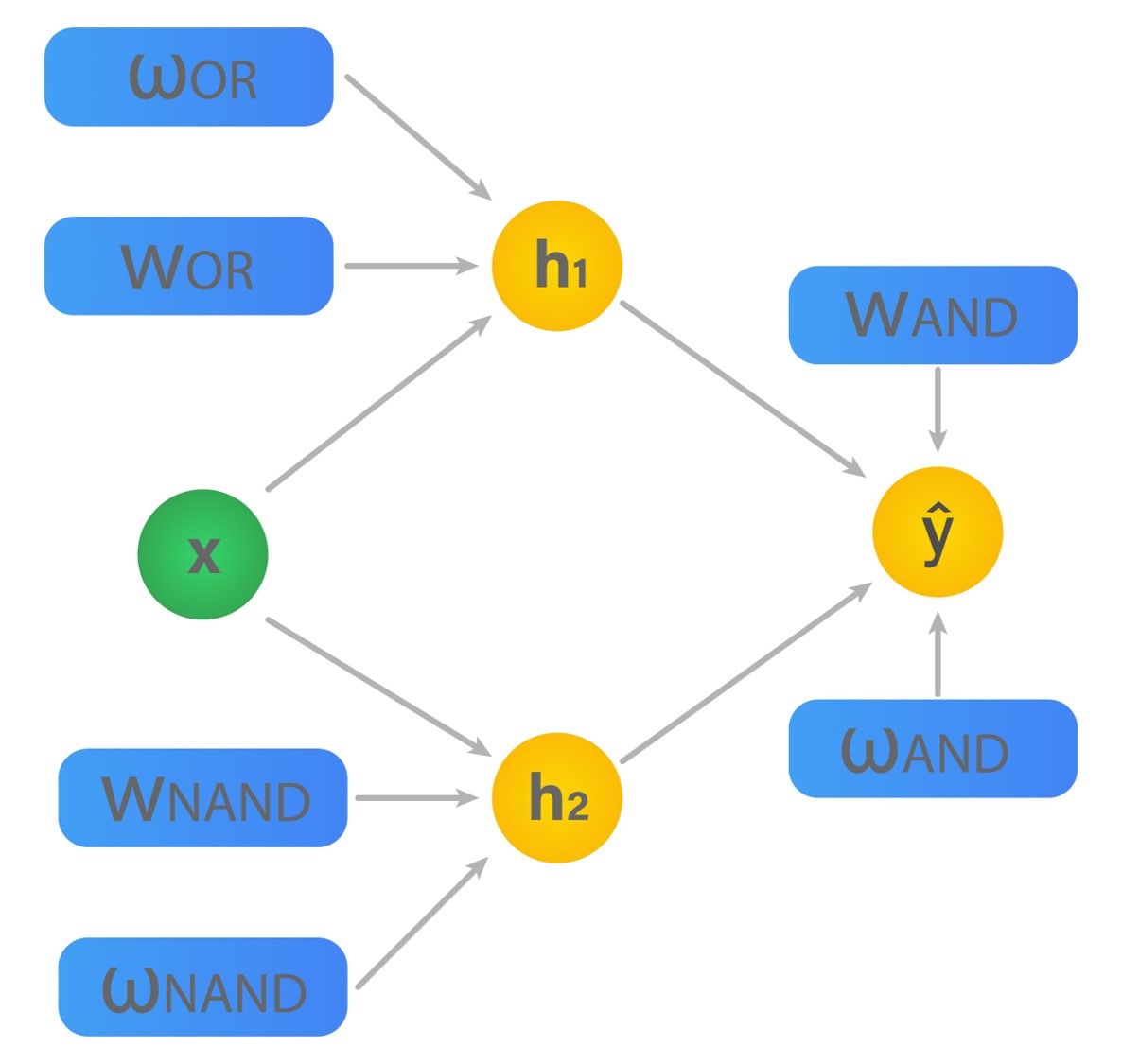
Now, the above expression can be rewritten as a program of multiple logistic regressions. Have a look.
$$ h_{1}=\sigma\left(\mathbf{w}_{O R}^{\top} \mathbf{x}+w_{O R}\right) $$
$$ h_{2}=\sigma\left(\mathbf{w}_{N A N D}^{\prime} \mathbf{x}+w_{N A N D}\right) $$
$$ \hat{y}=\sigma\left(\mathbf{w}_{A N D}^{\top} \mathbf{h}+w_{A N D}\right) $$
This multi-later ‘perceptron’ has two hidden layers represented by \(h_1\) and \(h_2\), where \(h(x)\) is a non-linear feature of \(x\). We can represent this network visually as follows.
We can, further, simplify the above 1D mappings as a single 2D mapping as follows.
$$ \mathbf{h}=\sigma\underbrace{\left(\begin{array}{c}\mathbf{w}_{O R}^{\top}\\\left.\mathbf{w}_{NAND}^{\top}\right)\end{array}\right)}_{\mathbf{W}}\mathbf{x}+\underbrace{\left(\begin{array}{c}w_{OR}\\w_{NAND}\end{array}\right)}_{\mathbf{w}} $$
$$ \hat{y}=\sigma\left(\mathbf{w}_{A N D}^{\top} \mathbf{h}+w_{A N D}\right) $$
The resultant computational graph for the above 2D mapping looks like this.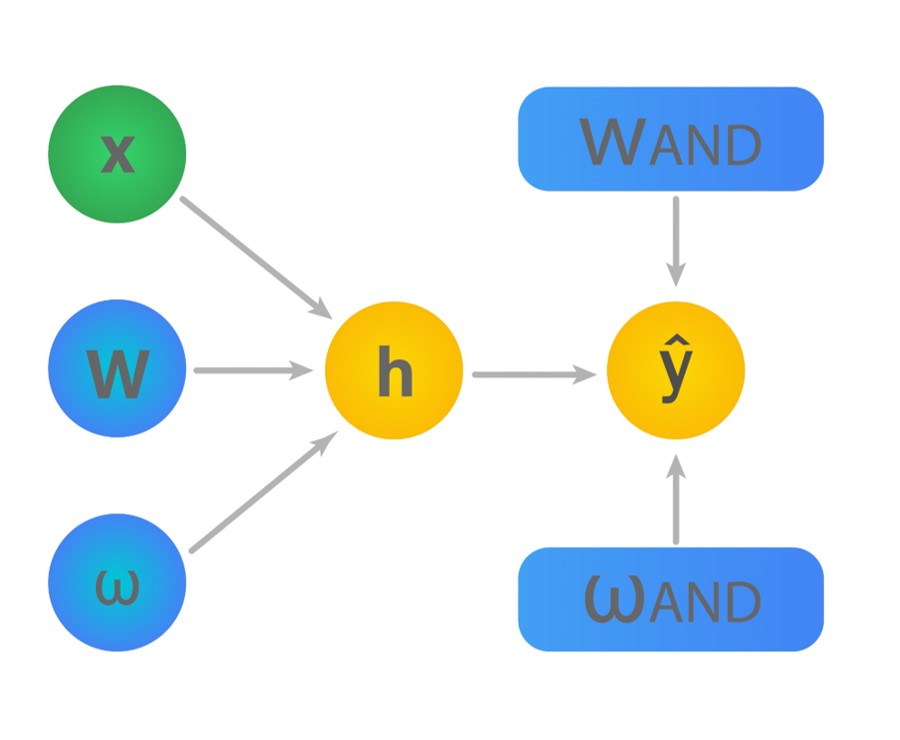
The biggest advantage of using the above solution for the XOR problem is that now, we don’t have non-differentiable step-functions anymore. Instead, we have differential equations sigmoid activation functions which means we can start with a random guess for each of the parameters in our model and later, optimize according to our dataset. This parametric learning is done using gradient descent where the gradients are calculated using the back-propagation algorithm.
Let’s now see how we can solve the XOR problem in Python using PyTorch.
5. Solving The XOR Problem in Python using PyTorch
Let’s start by importing the necessary libraries.
import numpy as np
import torch
import matplotlib.pyplot as pltSolving the AND problem
First, we’ll create the data for the logical operator AND. First, we will create our decision table were x1 and x2 are two NumPy arrays consisting of four numbers. These arrays will represent the binary input for the AND operator. Then, we will create an output array y, and we will set the data type to be equal to np.float32.
x1 = np.array ([0., 0., 1., 1.], dtype = np.float32)
x2 = np.array ([0., 1., 0., 1.], dtype = np.float32)
y = np.array ([0., 0., 0., 1.],dtype = np.float32)Now, we can scatter our data points. Here, x1 and x2 will be the coordinates of the points and color will depend on y. Let’s have a look at the following graph.
plt.scatter(x1, x2, c=y)Output:

We can see that just the yellow point will have a value of 1, while the remaining three points will have a value of 0.
The next step would be to create a data set because we cannot just train our data on these four points. So, we will create a function create_dataset() that will accept x1, x2 and y as our input parameters. Then, we will use the function np. repeat() to repeat every number in x1, x2, and y 50 times. In that way, we will have 200 numbers in each array.
def create_dataset(x1, x2, y):
# Repeat the numbers from x1, x2, and y 50 times
x1 = np.repeat(x1, 50)
x2 = np.repeat(x2, 50)
y = np.repeat(y, 50)
# Add noise to data points just to have some data variety
x1 = x1 + np.random.rand(x1.shape[0])*0.05
x2 = x2 + np.random.rand(x2.shape[0])*0.05
# Shuffle
index_shuffle = np.arange(x1.shape[0])
np.random.shuffle(index_shuffle)
x1 = x1.astype(np.float32)
x2 = x2.astype(np.float32)
y = y.astype(np.float32)
x1 = x1[index_shuffle]
x2 = x2[index_shuffle]
y = y [index_shuffle]
# Convert data to tensors
x1_torch = torch.from_numpy(x1).clone().view(-1, 1)
x2_torch = torch.from_numpy(x2).clone().view(-1, 1)
y_torch = torch.from_numpy(y).clone().view(-1, 1)
# Combine X1 and X2
X = torch.hstack([x1_torch, x2_torch])
# Split into training and testing
X_train = X[:150,:]
X_test = X[150:,:]
y_train = y_torch[:150,:]
y_test = y_torch[150:,:]
return X_train, y_train, X_test, y_testAfter this, we also need to add some noise to x1 and x2 arrays. We can do that by using the np.random.rand() function and pass width of an array multiplied with some small number (in our case it is 0.05).
The next step is to shuffle the data. We will create an index_shuffle variable and apply np.arrange() function on x1.shape[0]. This function will return 200 numbers from zero to 200. Next, we will use the function np.random.shuffle() on the variable index_shuffle.
After we set the data type to be equal to np.float32, we can apply this index shuffle variable on x1, x2 and y.
Now, remember, because we are using PyTorch we need to convert our data to tensors. Once we do that we will combine x1 and x2. We will create a variable X and apply the function torch.hstack() to stack horizontally x1_torch and x2_torch tensors.
The next step is to create a training and testing data set for X and y. So, we will create X_train, X_test, y_train and y_test. Then for the X_train and y_tarin, we will take the first 150 numbers, and then for the X_test and y_test, we will take the last 150 numbers. Finally, we will return X_train, X_test, y_train, and y_test.
Now we can call the function create_dataset() and plot our data.
X_train, y_train, X_test, y_test = create_dataset(x1, x2, y)
plt.scatter(X_train[:,0], X_train[:,1], c = y_train)Output:

The next step is to create the LogisticRegression() class. To be able to use it as a PyTorch model, we will pass torch. nn.Module as a parameter. Then, we will define the init() function by passing the parameter self.
class LogisticRegresion(torch.nn.Module):
def __init__(self, input_dim, output_dim):
super(LogisticRegresion, self).__init__()
self.linear = torch.nn.Linear(input_dim, output_dim)
def forward( self, x):
x = self.linear(x)
outputs = torch.sigmoid(x)
return outputsNow that we have created the class for the Logistic regression, we need to create the model for AND logical operator. So, we will create the variable model_AND which will be equal to LogisticRegression() class. As parameters we will pass number 2 and 1 because our x now has two features, and we want one output for the y. Then, we will create a criterion where we will calculate the loss using the function torch.nn.BCELoss() ( Binary Cross Entropy Loss). Also we need to define an optimizer by using the Stochastic Gradient descent. As parameters we will pass model_AND.parameters(), and we will set the learning rate to be equal to 0.01.
model_AND = LogisticRegresion(2,1)
criterion = torch.nn.BCELoss()
optimizer = torch.optim.SGD(model_AND.parameters(), lr=0.01)Now that we have defined everything we need, we’ll create a training function. As an input, we will pass model, criterion, optimizer, X, y and a number of iterations. Then, we will create a list where we will store the loss for each epoch. We will create a for loop that will iterate for each epoch in the range of iteration.
The next step is to apply the forward propagation. We will define prediction y_hat and we will calculate the loss which will be equal to criterion of the y_hat and the original y. Then we will store loss inside this all_loss list that we have created.
Now, we can apply the backward pass. To calculate the gradients and optimize the weight and the bias we will use the optimizer.step() function. Remember that we need to make sure that calculated gradients are equal to 0 after each epoch. To do that, we’ll just call optimizer.zero_grad() function. Finally, we will just return a list all_loss.
def train(model, criterion, optimizer, X, y, iter):
all_loss = []
for epoch in range(iter):
y_hat = model(X)
loss = criterion(y_hat, y)
all_loss.append(loss.item())
loss.backward()
optimizer.step()
optimizer.zero_grad()
return all_lossNow, we can train our data. We will call our train() function and set 50.000 for the number of iterations. After our data are trained, we can scatter the results.
all_loss = train(model_AND, criterion, optimizer, X_train, y_train, 50000)y_pred = model_AND.forward(X_test)
# We should get points (0,0,) and (1,1) if everything is correctly classified
plt.scatter(y_pred.detach().numpy(), y_test)Output:

As you can see, the classifier classified one set of points to belong to class 0 and another set of points to belong to class 1. Now, we can also plot the loss that we already saved in the variable all_loss.
plt.plot(all_loss)Output:
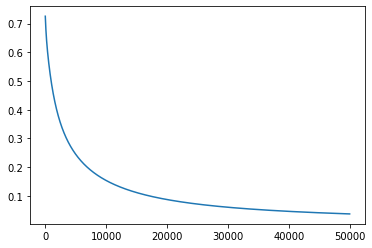
Solving the OR problem
Now we will conduct a similar experiment. The only difference is that we will train our data for the logical operator OR. Here the x1 and the x2 will be the same, we will just change the output y.
x1 = np.array ([0., 0., 1., 1.], dtype = np.float32)
x2 = np.array ([0., 1., 0., 1.], dtype = np.float32)
y = np.array ([0., 1., 1., 1. ],dtype = np.float32)
plt.scatter(x1, x2, c=y)Output:

X_train, y_train, X_test, y_test = create_dataset(x1, x2, y)
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train)Output:

model_OR = LogisticRegresion(2,1)
criterion = torch.nn.BCELoss()
optimizer = torch.optim.SGD(model_OR.parameters(), lr=0.01)all_loss = train(model_OR, criterion, optimizer, X_train, y_train, 50000)y_pred = model_OR.forward(X_test)
plt.scatter(y_pred.detach().numpy(), y_test)Output:

plt.plot(all_loss)Output:
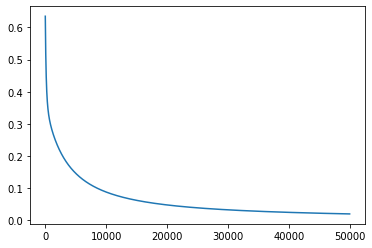
This is how the graph looks like for the OR model. We can see that now only one point with coordinates (0,0) belongs to class 0, while the other points belong to class 1.
Solving the NAND problem
After those steps, we can create the data for NAND. Again, we just change the y data, and all the other steps will be the same as for the last two models.
x1 = np.array ([0., 0., 1., 1.], dtype = np.float32)
x2 = np.array ([0., 1., 0., 1.], dtype = np.float32)
y = np.array ([1., 1., 1., 0.], dtype = np.float32)
plt.scatter(x1, x2, c=y)Output:

X_train, y_train, X_test, y_test = create_dataset(x1, x2, y)
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train)Output:

model_NAND = LogisticRegresion(2,1)
criterion = torch.nn.BCELoss()
optimizer = torch.optim.SGD(model_NAND.parameters(), lr=0.01)all_loss = train(model_NAND, criterion, optimizer, X_train, y_train, 50000)y_pred = model_NAND.forward(X_test)
plt.scatter(y_pred.detach().numpy(), y_test)Output:

plt.plot(all_loss)Output:
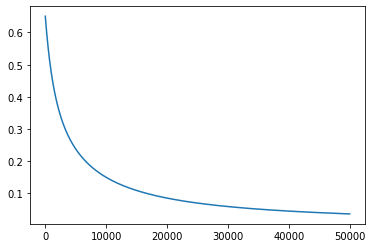
Solving the XOR problem
Now we can finally create the XOR data set. Everything is the same as before. We will just change the y array to be equal to (0,1,1,0).
x1 = np.array ([0., 0., 1., 1.], dtype = np.float32)
x2 = np.array ([0., 1., 0., 1.], dtype = np.float32)
y = np.array ([0., 1., 1., 0. ],dtype = np.float32)
plt.scatter(x1, x2, c=y)Output:

X_train, y_train, X_test, y_test = create_dataset(x1, x2, y)
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train)Output:

Here, we can see our data set. Now we can test our result on one number. For example, we can take the second number of the data set. Next, we will create two hidden layers h1 and h2. The hidden layer h1 is obtained after applying model OR on x_test, and h2 is obtained after applying model NAND on x_test. Then, we will obtain our prediction h3 by applying model AND on h1 and h2.
# Do a check for one data point
test = 2
h1 = model_OR.forward(X_test[test])
h2 = model_NAND.forward(X_test[test])
h3 = model_AND.forward(torch.tensor([h1, h2]))
print(h3)
print(y_test[test])tensor([0.0477], grad_fn=<SigmoidBackward>)
tensor([0.]# Do a check for one data point
test = 5
h1 = model_OR.forward(X_test[test])
h2 = model_NAND.forward(X_test[test])
h3 = model_AND.forward(torch.tensor([h1, h2]))
print(h3)
print(y_test[test])tensor([0.8993], grad_fn=<SigmoidBackward>)
tensor([1.])After printing our result we can see that we get a value that is close to zero and the original value is also zero. On the other hand, when we test the fifth number in the dataset we get the value that is close to 1 and the original value is also 1. So, obviously, this is correct.
Now, we can test our results on the whole dataset. To do that we will just remove indexes. Also in the output h3 we will just change torch.tensor to hstack in order to stack our data horizontally.
# Create a test for a full batch of data points
h1 = model_OR.forward(X_test)
h2 = model_NAND.forward(X_test)
h3 = model_AND.forward(torch.hstack([h1 , h2]))
plt.scatter(h3.detach().numpy(), y_test)Output:

Just by looking at this graph, we can say that the data was almost perfectly classified.
Creating the third dimension
Another very useful approach to solve the XOR problem would be engineering a third dimension. The first and second features will remain the same, we will just engineer the third feature.
For this step, we will take a part of the data_set function that we created earlier. However, we have to make some modifications. The only difference is that we have engineered the third feature x3_torch which is equal to element-wise product of the first feature x1_torch and the second feature x2_torch.
# Repeat the numbers from x1, x2, and y 50 times
x1 = np.repeat(x1, 50)
x2 = np.repeat(x2, 50)
y = np.repeat(y, 50)
# Add noise to data points just to have some data variety
x1 = x1 + np.random.rand(x1.shape[0])*0.05
x2 = x2 + np.random.rand(x2.shape[0])*0.05
# Shuffle
index_shuffle = np.arange(x1.shape[0])
np.random.shuffle(index_shuffle)
x1 = x1.astype(np.float32)
x2 = x2.astype(np.float32)
y = y.astype(np.float32)
x1 = x1[index_shuffle]
x2 = x2[index_shuffle]
y = y [index_shuffle]
# Convert data to tensors
x1_torch = torch.from_numpy(x1).clone().view(-1, 1)
x2_torch = torch.from_numpy(x2).clone().view(-1, 1)
x3_torch = torch.mul(x1_torch, x2_torch)
# Combine X1 and X2
X = torch.hstack([x1_torch, x2_torch, x3_torch])
y_torch = torch.from_numpy(y).clone().view(-1, 1)
# Split into training and testing
X_train = X[:150,:]
X_test = X[150:,:]
y_train = y_torch[:150,:]
y_test = y_torch[150:,:]Now comes the part where we create our logistic model. It will be the same logistic regression as before, with addition of a third feature. The rest of the code will be identical to the previous one.
model_XOR = LogisticRegresion(3,1)
criterion = torch.nn.BCELoss()
optimizer = torch.optim.SGD(model_XOR.parameters(), lr=0.01)all_loss = train(model_XOR, criterion, optimizer, X_train, y_train, 50000)y_pred = model_XOR.forward(X_test)
plt.scatter(y_pred.detach().numpy(), y_test)Output:

We can see that our model made pretty much good predictions. They are not as accurate as before, but if we change the iteration number the result will get even better.
That’s it! By understanding the limitations of traditional logistic regression techniques and deriving intuitive as well as formal solutions, we have made the XOR problem quite easy to understand and solve. In this process, we have also learned how to create a Multi-Layer Perceptron and we will continue to learn more about those in our upcoming post. Before we end this post, let’s do a quick recap of what we learned today.
Solving The XOR Problem
- Logistic Regression works by classifying operator points into Class 0 and Class 1 based on the decision boundary line
- Simple logistic regression methods easily solve OR, AND, and NAND operator problems
- Due to the unintuitive outcome of the decision boundary line in the XOR operator, simple logistic regression becomes difficult for XOR problems
- An intuitive solution for XOR involves working with a 3D feature plane rather than a 2D setup
- Formal solution for XOR involves a combination of decision boundary lines of OR and NAND operators
- Multi-layer perceptron can be built using two hidden layers and differentiable sigmoid activation functions
Summary
So how did you like this post on the classic XOR problem? By understanding the past and current research, you have come at par with researchers who are finding new ways to solve problems such as the XOR problems more efficiently. If you would like to practice solving other operator problems or even customized operator problems, do share your results with us. We’ll see you soon. Till then, keep having multi-layer fun! 🙂
References
[1] Deep Learning – Lecture 3.2
[2] Frank Rosenblatt with a Mark I Perceptron computer in 1960