#004 OpenCV projects – How to extract features from the image in Python?

Highlights: In this post, we are going to show how to detect distinct features in an image. We will describe the important properties of these features (keypoints) and we will learn how we can use them to better understand the structure and the content of an image. Furthermore, we will talk about the most common algorithms that can be used for feature detection. So, let’s begin.
Tutorial overview:
- What are keypoints?
- Detecting corners with Harris Corner Detector
- Detecting corners with Shi Tomasi Corner Detector – Good Features to Track
- Feature detection algorithms
- Scale Invariant Feature Transform (SIFT)
- Speeded Up Robust Features (SURF)
- Oriented FAST and Rotated BRIEF (ORB)
1. What are keypoints?
Have you ever wondered how the human brain is capable of recognizing many different objects so quickly? We can recognize patterns and shapes in a split of a second. For example, humans have a natural ability to recognize faces. New research shows that the baby’s brain recognizes faces from the earliest days. So, how can we do that? Well, the answer is simple. Because our brain is triggered by the most interesting points of an image. These interesting, distinct features we also call keypoints. In many computer vision and machine learning applications, we need these feature points that will assist us to compare and detect objects or scenes.
Let’s have a look at the following two pictures. What would you choose as the most interesting keypoints?

The second one is a natural choice. It is full of interesting details (boat, sand, mountains, clouds), whereas the first one does not have many interesting points.
So, why are features important? They are crucial for object detection, object tracking, and the process of building object recognition systems. We can say that features are an essential part of any process where we need to detect these distinct, interesting regions to create a signature for the image.
What are descriptors?
Along with the features we use the term descriptor It can be seen as the way to compare the keypoints by summarizing some characteristics about them. Let’s see some of the feature characteristics.
- Repeatability or precision means that, when we compare two images, if we find a feature point in the first image, we should better find it in the second image as well.
- Matchability means that feature should have a description that’s distinctive.
- Locality, means that the description of the feature is, dependent upon a neighborhood, but not too big a neighborhood.
Where can we find keypoints in the image?
The next question that we need to answer is where we can locate these points in the image? Well, we can find them in regions where we can detect rapid pixel intensity change. These areas are edges and corners. The edge represents an interesting set of points that can help us to better characterize the object in the image. Corners are even more distinct because they are located at the intersection of two or more lines.
If we have look at the following image we can differentiate two distinctive sets of points. The points located inside these geometric shapes are not that interesting because their small pixel neighborhood is completely identical. On the other hand, the edges of these objects are much more interesting because their local neighborhood is different. For example, if we look at the triangle in the following image we can see the pixels that create an edge are surrounded with pixels with different intensities. That means that the intensity of a pixel inside the triangle is different from the intensity of a pixel outside of a triangle.
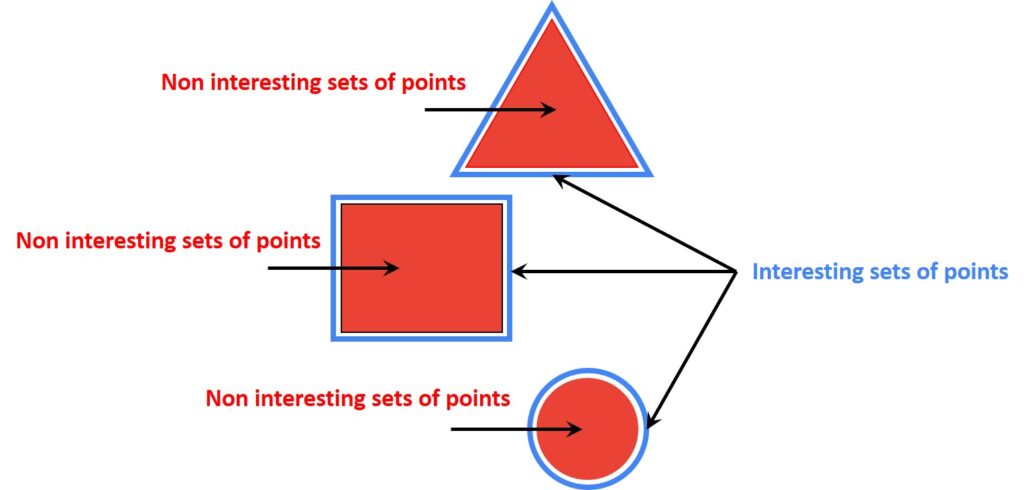
To conclude, in points where the local neighborhood does not produce any changes in pixel intensity (e.g. flat regions), we can not find any significant descriptor which we can use to characterize our image.
In the following paragraph, we will remind ourselves what is Harris Corner Detector and how it works.
2. Detecting corners with Harris Corner Detector
Now when we know that the most interesting parts of an image are corners, it is important to learn how to detect them. Among many algorithms, Harris Corner Detector is one of the most popular methods for feature detection due to its good results and robustness. If you want to understand Harris Corner Detector and the theory behind it you can check the following post.

First let’s import necessary libraries and load the image.
# Necessary imports
import cv2
import numpy as np
# Importing function cv2_imshow necessary for programing in Google Colab
from google.colab.patches import cv2_imshowimg = cv2.imread("Cybertruck.jpg")
cv2_imshow(img)
Next, we will convert our input image into a grayscale image. Then, we will use the function cv2.cornerHarris() to detect corners. This function consist of the following parameters:
- img – Input image that should be grayscale and
float32type. - blockSize – It is the size of the neighborhood considered for corner detection.
- ksize – Aperture parameter of Sobel derivative used.
- k – Harris detector free parameter in the equation.
Then, we will apply the process of dilation with the function cv2.dilate(). We use this function to increase the object area and to emphasize features. Finally, we need to apply a threshold for an optimal value that can vary depending on an image.
img = cv2.imread('img1.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray = np.float32(gray)
dst = cv2.cornerHarris(gray, 8, 3 , 0.04)
# Applying dilation to increase the object area and to emphasize features
dst = cv2.dilate(dst,None)
# Threshold for an optimal value. It may vary depending on the image.
img[dst>0.02*dst.max()]=[255, 0, 255]
cv2_imshow(img)Output:

Now, let’s see what will happen if a threshold for an optimal value is increased (only the threshold value has been changed, but the rest of the code is identical to the previous one).
Output:

We can see that when we decrease a threshold value the number of detected points will increase. So, when a value for a threshold was set to 0.02 * dis.max we detected just a few points that are the most dominant. That means that keypoints in the other three images are not as distinct as the points on the first image.
3. Detecting corners with Shi-Tomasi Corner Detector – Good Features to Track
Six years after the Harris Corner Detector has been introduced, in 1994, Jianbo Shi and Carlo Tomasi came up with an improved method for corner detection. They made a small modification to the Harris Corner Detector in their paper Good Features to Track. Using this method we can detect the strongest corners in the image by specifying the number of corners we want to find, minimum quality of corner, and minimum Euclidean distance between corners detected.
OpenCV has implemented a function cv2.goodFeaturesToTrack() which is very useful when we don’t need to detect every single corner to extract information from the image. The parameters for this function are:
- image – Input 8-bit or floating-point 32-bit, single-channel image
- maxCorners – Maximum number of corners to detect. If the number of corners on an image is higher than a number of maxCorners the most pronounced corners are detected
- qualityLevel – Parameter characterizing the minimal accepted quality of image corners. All corners below the quality level are rejected. The parameter value is multiplied by the best corner quality measure, which is the minimal eigenvalue of the Harris function response.
- minDistance minimal Euclidean distance between corners
Now, we can play a little bit with these parameters. For example, let’s see what will happen if we apply this function with different values for the parameter maxCorners.
img_1 = cv2.imread('img1.jpg')
gray = cv2.cvtColor(img_1,cv2.COLOR_BGR2GRAY)
corners = cv2.goodFeaturesToTrack(gray, 100, 0.01, 1)
corners = np.int0(corners)
for i in corners:
x, y = i.ravel()
cv2.circle(img_1, (x,y), 3, (255, 0, 255), -1)
cv2_imshow(img_1)
img_2 = cv2.imread('img1.jpg')
gray = cv2.cvtColor(img_2,cv2.COLOR_BGR2GRAY)
corners = cv2.goodFeaturesToTrack(gray, 500, 0.01, 1)
corners = np.int0(corners)
for i in corners:
x, y = i.ravel()
cv2.circle(img_2, (x,y), 3, (255, 0, 255), -1)
cv2_imshow(img_2)
img_3 = cv2.imread('img1.jpg')
gray = cv2.cvtColor(img_3,cv2.COLOR_BGR2GRAY)
corners = cv2.goodFeaturesToTrack(gray, 1000, 0.01, 1)
corners = np.int0(corners)
for i in corners:
x, y = i.ravel()
cv2.circle(img_3, (x,y), 3, (255, 0, 255), -1)
cv2_imshow(img_3)
For better comparison, let’s plot our outputs and stack them together. Note that when we plot our image with matplotlib, colors in our displayed image will be reversed. Therefore, we need to change the color order by splitting the original image into 3 channels and then merged them back together in RGB order.
b, g, r = cv2.split(img_1)
img_1 = cv2.merge([r, g, b])
b, g, r = cv2.split(img_2)
img_2 = cv2.merge([r, g, b])
b, g, r = cv2.split(img_3)
img_3 = cv2.merge([r, g, b])With the following code we will plot our images.
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(30, 20))
ax0 = fig.add_subplot(131)
ax0.imshow(img_1)
ax0.set_title('maxCorners = 100',fontsize= 25)
ax0.axis('off')
ax1 = fig.add_subplot(132)
ax1.imshow(img_2)
ax1.set_title('maxCorners = 200',fontsize= 25)
ax1.axis('off')
ax2 = fig.add_subplot(133)
ax2.imshow(img_3)
ax2.set_title('maxCorners = 500',fontsize= 25)
ax2.axis('off')
Now, let’s see what will happen if we change the parameter minDistance. This parameter determines the minimum possible distance between two detected points. So, when the actual distance between two or more points is smaller than the value for minDistance, the algorithm will pick the most dominant point.
img_1 = cv2.imread('img2.jpg')
gray = cv2.cvtColor(img_1,cv2.COLOR_BGR2GRAY)
corners = cv2.goodFeaturesToTrack(gray, 500, 0.01, 1)
corners = np.int0(corners)
for i in corners:
x, y = i.ravel()
cv2.circle(img_1, (x,y), 3, (255, 0, 255), -1)
cv2_imshow(img_1)
img_2 = cv2.imread('img2.jpg')
gray = cv2.cvtColor(img_2,cv2.COLOR_BGR2GRAY)
corners = cv2.goodFeaturesToTrack(gray, 500, 0.01, 10)
corners = np.int0(corners)
for i in corners:
x, y = i.ravel()
cv2.circle(img_2, (x,y), 3, (255, 0, 255), -1)
cv2_imshow(img_2)
img_3 = cv2.imread('img2.jpg')
gray = cv2.cvtColor(img_3,cv2.COLOR_BGR2GRAY)
corners = cv2.goodFeaturesToTrack(gray, 500, 0.01, 20)
corners = np.int0(corners)
for i in corners:
x, y = i.ravel()
cv2.circle(img_3, (x,y), 3, (255, 0, 255), -1)
cv2_imshow(img_3)
Let’s plot our outputs once again for better comparison.

So, we have learned to detect corners with two different functions. However, when we apply these methods for corner detection, one problem can occur. If the corners aren’t sharp enough, or if the image is enlarged, it is possible that the algorithm will not be able to detect them.
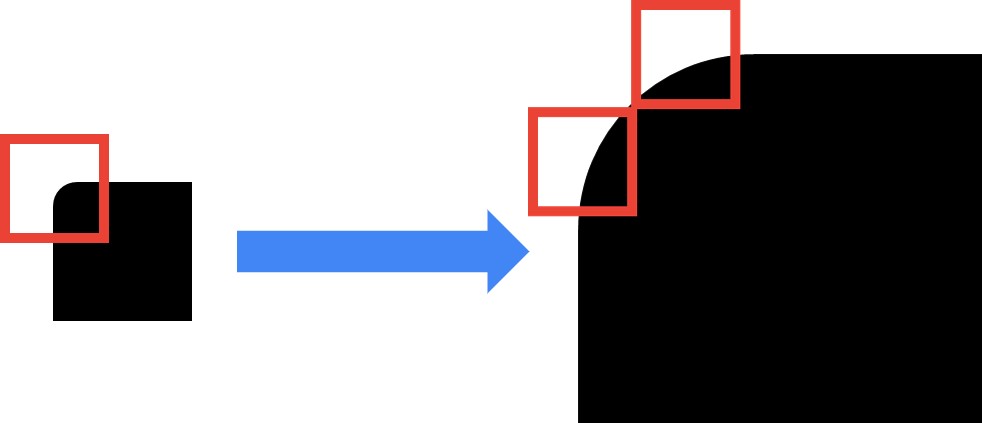
If we look at the image above we can see that a corner becomes flat when it is zoomed in the same window. However, our goal is to detect edges and corners even when the image is scaled. That is why we need to use different algorithms for feature detection that can overcome such a problem.
Yet, we must make one distinction. The claim that corner detection will not work when the image is enlarged can be found in many books and papers [1]. However, when we tested this claim in the Python code, we came to the conclusion that Harris is capable of detecting corners even when the image is enlarged multiple times. So, it is always good to test it for yourself.
from PIL import Image
img_test = Image.open("img1.jpg")# Cropping the desired area of the image
crop_img = img_test.crop((200, 200, 400, 400)).copy()
display(crop_img)# Resizing the cropped area
resized = crop_img.resize((1600, 1600))new_image = np.array(resized).copy()
gray = cv2.cvtColor(new_image, cv2.COLOR_BGR2GRAY)
gray = np.float32(gray)
dst = cv2.cornerHarris(gray, 8, 3 , 0.04)
# Applying dilation to increase the object area and to emphasize features
dst = cv2.dilate(dst,None)
# Threshold for an optimal value, it may vary depending on the image.
new_image[dst>0.02*dst.max()] = [255, 0, 255]
cv2_imshow(new_image)
As you can see corners are detected in the cropped image even when that area is enlarged up to 8 times. Let us know if your corners are as sharp as on the cyber track.
So far we have talked about methods that detect corners. However, there are other non-corner keypoints that can be interesting for some images.
4. Feature detection algorithms
Scale Invariant Feature Transform (SIFT)
One of the most popular algorithms in image processing is Scale Invariant Feature Transform or SIFT. This algorithm is perfectly suitable for our goal because it detects features that are invariant to image scale and rotation. Moreover, features are local and based on the appearance of the object in certain interesting points. They are also robust to changes in illumination, noise, and minor changes in viewpoint.
SIFT was first presented in 2004, by David G. Lowe from the University of British Columbia in the paper, Distinctive Image Features from Scale-Invariant Keypoints, This algorithm is patented, and it is included in the Non-free module in OpenCV. That is why we need to install the older version of OpenCV because SIFT is not included in the new OpenCV library. We can do that with the following code.
!pip install opencv-python==3.4.2.16
!pip install opencv-contrib-python==3.4.2.16First, we will convert the image into a grayscale one. For the feature detection with SIFT algorithm, we will use the function cv2.xfeatures2d.SIFT_create(). Then, we will detect keypoints with the function sift.detectAndCompute(). This function consists of two parameters. The first one is an image that we want to process, and the second parameter determines whether we want to use a mask or not. We can use the mask if we want to process a specific object in the image. If that is the case we can pass a mask that will cover everything else besides that object.
Finally, we can draw our keypoints with the function cv2.drawKeypoints().
img = cv2.imread('img1.jpg')
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
sift = cv2.xfeatures2d.SIFT_create()
keypoints = sift.detect(img_gray, None)
cv2_imshow(cv2.drawKeypoints(img, keypoints, None, (255, 0, 255)))
For better visualization, we can use a parameter for the cv2.drawKeypoints function flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS. When we pass this flag, the circle with keypoint size and orientation will be drawn around each keypoint.
img = cv2.imread('img1.jpg')
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
sift = cv2.xfeatures2d.SIFT_create()
keypoints = sift.detect(img_gray, None)
cv2_imshow(cv2.drawKeypoints(img, keypoints, None, (255, 0, 255), flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS))
Speeded Up Robust Features (SURF)
Although SIFT algorithm performs well in most situations it has one significant limitation. Its algorithmic implementation is too slow. To overcome this problem a new method called Speeded Up Robust Features(SURF) is developed. It is similar to SIFT algorithm, but way much faster. Its approach lies in its fast computation of operators using box filters.
So, let’s see how can we detect keypoints with the SURF algorithm. The code is almost identical as a code for detection with the SIFT algorithm, only this time we will use the function cv2.xfeatures2d.SURF_create().
img = cv2.imread('img1.jpg')
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
surf = cv2.xfeatures2d.SURF_create()
keypoints = surf.detect(img_gray, None)
cv2_imshow(cv2.drawKeypoints(img, keypoints, None, (255, 0, 255)))
Oriented FAST and Rotated BRIEF (ORB)
This algorithm was developed at OpenCV labs by Ethan Rublee, Vincent Rabaud, Kurt Konolige, and Gary R. Bradski in 2011. ORB was created as an alternative to SIFT and SURF feature detection algorithms mainly because SIFT and SURF are patented algorithms. On the other hand, the ORB algorithm is not a commercial one.
To detect features with the ORB algorithm, we will use the function cv2.ORB_create(). As a parameter, we need to define the number of features that we want to detect. Then, we will detect keypoints with the function orb.detectAndCompute(). and draw them using the function cv2.drawKeypoints().
orb = cv2.ORB_create(nfeatures=1500)
keypoints_orb, descriptors = orb.detectAndCompute(img, None)
cv2_imshow(cv2.drawKeypoints(img, keypoints_orb, None, (255, 0, 255)))
Now, we can play a little. In the function cv2.ORB_create()we can specify the number of keypoints that we want to detect. Let’s see what will happen if we set a different value for this parameter.
img_1 = cv2.imread('img1.jpg')
orb = cv2.ORB_create(nfeatures=100)
keypoints_orb_1, descriptors = orb.detectAndCompute(img_1, None)img_2 = cv2.imread('img1.jpg')
orb = cv2.ORB_create(nfeatures=500)
keypoints_orb_2, descriptors = orb.detectAndCompute(img_2, None)img_3 = cv2.imread('img1.jpg')
orb = cv2.ORB_create(nfeatures=1000)
keypoints_orb_3, descriptors = orb.detectAndCompute(img_3, None)
Next, if we apply the same code on the different image we will get the following output.

Summary
Now, let’s compare all detection algorithms that we have used in this post. We stack all five algorithms on one image in order to better visualize the differences between them.

We can say that each method has some pros and cons. At first glance, we can see that some of the methods are very similar. For example, GoodFeaturesToTrack and ORB detected almost identical points while SURF detected many more points than other algorithms. Furthermore, seems that Hariss Corner Detector and GoodFeaturesToTrack are more accurate in distinguishing between edges and corners. Also, we can see that SIFT, SURF, and ORB detected a significant number of features in the mountains as opposed to GoodFeaturesToTrack and Harris. It is interesting that none of the algorithms have detected anything on the road because it considers a road as a noninteresting flat region. Even in the part of a road with a shadow, there are no detected features. Also, in a flat region of a desert, there is a small number of detected features.
To summarize, we have learned how to detect keypoints in an image and how to use them to better understand the content of an image. Furthermore, we have learned how to use the most common algorithms for corner and feature detection like Harris, SIFT, SURF, and ORB. In the next post, we will learn we can use these features to create a panorama image.
References:
[1] OpenCV: Computer Vision Projects with Python by Joseph Howse, Prateek Joshi, Michael Beyeler
[2] Good Features to Track by Jianbo Shi and Carlo Tomasi
[3] Distinctive Image Featuresfrom Scale-Invariant Keypoints by David G. Lowe