OpenCV #013 Harris Corner Detector – Theory

Highlights: In this post we will learn about Harris Corner Detector and how can we use this method to detect corners. We will give a brief overview how this method works, but we’ll not go so seriously with mathematics. We promise 🙂
What is Harris Corner Detector?
In many computer vision and machine learning applications we need some feature points which we will track or which will assist us to compare and detect objects or scenes. We will explain that corners are in particular interesting for detection both visually and mathematically. Among many algorithms, Harris Corner Detector is one of the most popular methods for feature/point detection due to its good results and robustness.

Tutorial Overview:
- Intro
- Corner Detection
- Harris Corners
- Harris Corners Illustrated
- Small Shifts and Quadratic Approximation Simplification
1. Intro
In this post we are going to talk about finding corners, which is fundamental to a huge part of computer vision. First we need to talk a little bit about what makes a good feature. So here was an example of some feature points.

The first thing that makes a good feature is simply repeatability or precision, meaning if we find something in the left image, we better find that in the right image. Or if we have a sequence of images that we are trying to line, we want to find that same feature point. The other thing is that we should be able to be precise in our description. The idea is that if we find the point, we find it every time, and we find it more or less in the same place, with respect to the scene. The next important thing about a feature was the saliency or the matchability and what we mean by that is, that it should have a description that’s distinctive.
One of the reasons we are doing this, finding these features, is that we are going to use this constellation of features. This collection of features, is going to stand in for the image. So, if you remember for fundamental matrices, we needed eight points although a dozen or more is better, but the idea is that this is a number much smaller than the number of pixels. So compactness and efficiency say that we should find good features, but we should not find too many of them. The idea is that we are finding enough, but it’s much, much less than a number of pixels.
And finally, locality. Locality means that, the description of the feature is, dependent upon a neighborhood, but not too big a neighborhood. One of the reasons we said that if the neighborhood is too big, then if we change our view point a little bit and something is occluding part of that, even though we can still see the feature, the neighborhood might have been partially occluded and then the feature might not be detected anymore, or not described the same way. So, locality means that we want a descriptor based upon a region around it, but not too big a region.
2. Corner Detection
So, fundamentally to in terms of what makes a good feature, we need to talk about finding one and describing one. And in this post, we’re going to talk about the notion of finding these features, sometimes referred to as interest points.
So, let’s start thinking about an image pattern and imagine you’re looking at a large black square against the white wall. Would the middle of the square be a good interest point? The answer is no. Remember one of the things we need to be able to do is precisely locate this. Well, in order to try to find the middle of some big square, there’s like nothing there. It’s all black, we wouldn’t know where to land.
Well, what about along the edge? Again, the answer is no. If our edge was vertical we could tell which way to move left and right. But as we move up and down, nothing would really change.
Next, what about the top left-hand corner? Would that be a good point? Yes. The idea is that, we know exactly where that point is.
We could move that square up and down or left and right. And basically, the pixels underneath that square wouldn’t change very much. That’s what is referred to as a flat region. That is that there is no change in the intensity. This is shown in the following image.

Next, if we have put our square over the edge. So, what do we see? Well, it is the same thing we talked about before. Now, we do know about moving left and right. We would know exactly more or less where that edge is. But if we were to move up and down, we wouldn’t be able to see any difference, because there would be no change.
So finally, we get to the corners. And the idea is that in the corner, basically because we have gradients in more than one direction, no matter how we were to translate that square, the pattern underneath the square will change. And we can determine when we’ve lined up exactly where we were before. So, there’s this idea that we need the gradients to have more than one direction.
3. Harris Corners
So, Harris corners are based on an approximation model and an error model. And here is how we calculate it:
$$ E\left ( u,v \right )= \sum_{x,y}^{ }w \left ( x,y \right )\left [ I\left ( x+u,y+v \right )-I\left ( x,y \right ) \right ]^{2} $$
Let’s assume, that we have got an image \(I\) and it is the intensity image. What we are going to do is we’re going to say, if we shift that \(I\) by a little bit, by a \(u\) and a \(v\) and we were to sum up the square over some window. How much error, would we get? So stepping through that, \(I\) is our image intensity, so \(I\left ( x,y\right )\) is just the original image. The \(u\) and the \(v\) is some small shift, so if we were to pick up our window and move it over a little bit, we would now get some different image just shifted by a little bit.
We subtract them and square them, and then we are going to sum them up over some window. So, the window is going to be some area, around some point. That is written here as \(w\left ( x,y \right )\). The total value \(E\), is for error. But the idea is that we’re going to sum it up around that window.

But if you actually want to weight the pixels near the point you are thinking about, more than the pixels that are far away, you would use a window that falls off in intensity. A Gaussian window would be an example. Typically, our windows can be square, if we need to be really fast, or smooth, if we need to be really good.
4. Harris Corners Illustrated
Now we can start to graphically illustrate this.

On the left, we have an image \(I\left ( x,y \right )\). And on the right, we have the new function \(E\left ( u,v \right )\). Remember, \(E\) is the error. And we are going to put \(0\) in the middle. So this would be plus and minus in \(u\) and \(v\) direction. So, what if we just leave the square right in the same place? What if we make \(u\) and \(v\) be zero? How much error are we going to get? Well, none. \(E\left ( 0,0 \right )\) is \(0\). We just subtracting the same image from itself and that’s what this \(E\left ( 0,0 \right )\) is meant to show. And by the way, this little pixel in the middle is black. Why is that black? Because that’s zero. There is zero error \(E\left ( u,v \right )\).
Now suppose we move our window just a couple of pixels, like \(3\) in the \(u \) and \(2\) in the \(v\) direction.
So the error grows as we move away. Suppose that picture were perfectly gray, every pixel is the same value. That error would be zero at the middle, and as we moved it, it would still be zero. So that should give us some idea of where we are headed. We are looking for points where as we move in \((u, v)\) we get this nice change, no matter how we move in \((u, v)\).
5. Small Shifts and Quadratic Approximation Simplification
Next, we want to model how this error function changes for small shifts. We are going to move, maybe even just a fraction of a pixel or a small shift. Right near \(u\) and \(v\) being \((0,0)\), that is around no shift at all. And of course, what we would like to see is that we get a significant change even for a small shift, and that would tell us that this image is going to change as we move around, and maybe it’s corner-like. So how do you predict the value of a function for small shifts? The answer is calculus. Taylor expansions.
Here is a very simple, beautiful way of writing this. That this quadratic approximation, remember we are just looking at the square terms of the \( E\left ( u,v \right ) \) , it can be written matrix form as:
$$ E\left ( u,v \right )\approx\begin{bmatrix}u & v\end{bmatrix}M \begin{bmatrix}u\\ v\end{bmatrix} $$
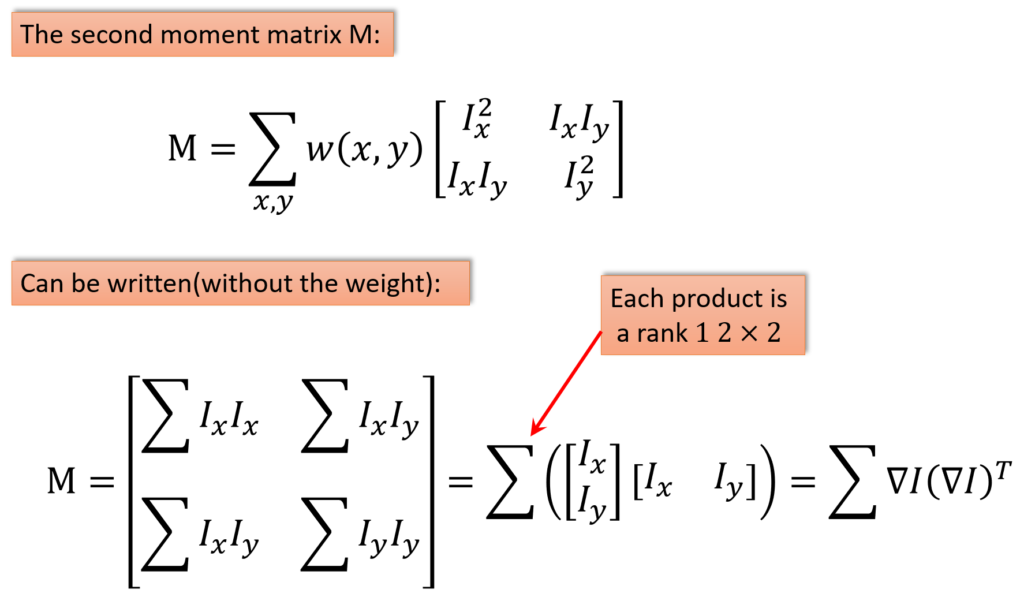
\(M\) is the second moment matrix written here:
$$ M= \sum_{x,y}^{ }w\left ( x,y \right )\begin{bmatrix}I_{x}^{2} & I_{x}I_{y} \\I_{x}I_{y} & I_{y}^{2}\end{bmatrix} $$
Again, what it has is it’s the weighted sum of the squares and of the product of the two different derivatives. We are going to write that \(M\) matrix without the weights at the bottom.
$$ M= \begin{bmatrix}\sum I_{x} I_{x} &\sum I_{x} I_{y} \\ \sum I_{x} I_{y} & \sum I_{y} I_{y}\end{bmatrix}= \sum \left ( \begin{bmatrix}I_{x}\\I_{y}\end{bmatrix}\begin{bmatrix}I_{x} &I_{y} \end{bmatrix} \right )= \sum \bigtriangledown I\left ( \bigtriangledown I \right )^{T} $$
And when we write it that way, we can see that this is just the sum of \(I_{x} I_{x}\), sum of \(I_{y} I_{y}\), and the cross sum. That can just be written as the sum, this is referred to as an outer product. So it’s the outer product of the single gradient. That’s what this says. One of these is just the outer product of one vector. It’s a \(2\times 2\) matrix but it’s an outer product of one vector. In linear algebra you realize that’s only a rank one matrix. Let’s just take the columns, the columns are just a multiple of \(I_{x}, I_{y}\). And each column is multiplied by a different scaler.
So when the two columns are scalar multiples of each other, it’s not a full rank matrix. So its \(2\times 2\) is actually rank one. And then of course, this thing is going to be summed over all of the points within the window.
What is it going to take for this matrix to be full rank, for this to be a well-behaved ellipse? We would actually have to have gradients in different directions over the window to be summing up a bunch of different rank one matrices and that would get us to a full rank.
Summary
Given these points, we covered some basic things important for Harris Corner Detector. In the next post we will continue working on it.