#012 PyTorch – How to implement Shallow Neural Network in PyTorch
Highlights: Welcome everyone! In this post we will learn how to use PyTorch for building a shallow neural network. If you want to go through a much detailed theoretical explanation about neural networks, and in particular a shallow neural network you can check out these blog posts. So, let’s start implementing one in PyTorch.

Tutorial Overview:
- Data Preparation
- Define Model Structure
- Loss Function (Criterion) and Optimizer
- Model Training
- Testing our Model
- Visualize our Predictions
1. Data preparation
Building a Shallow Neural Network using PyTorch is relatively simple. First, let’s import our necessary libraries. We will import a torch that will be used to build our model, NumPy for generating our input features and target vector, matplotlib for visualization. Finally, we will use sklearn for splitting our dataset and measuring the accuracy of our model.
# Necessary imports
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import matplotlib.cm as cm
# This line detects if we have a gpu support on our system
device = ("cuda" if torch.cuda.is_available() else "cpu")As the next step, using NumPy, we will create randomly generated samples. The samples will represent 2 different classes. The data features will be stored in the variable \(x \) and for each variable we will have a class membership function \(y \). This variable is also known as a target variable. In our code we created two classes – class 0 and class 1. Also we created a vector that contains the first 2000 elements from class 0, and second 2000 elements from class 1.
x1 = np.random.randn(2000)*0.5+3
x2 = np.random.randn(2000)*0.5+2
x3 = np.random.randn(2000) *0.5 + 4
x4 = np.random.randn(2000) *0.5 + 5
# Creating a Matrix
X_1 = np.vstack([x1, x2])
X_2 = np.vstack([x3, x4])
X = np.hstack([X_1, X_2]).T
# Creating a vector that contains classes (0, 1)
y = np.hstack([np.zeros(2000), np.ones(2000)])
print(X.shape)
print(y.shape)Output:
(4000, 2)
(4000,)
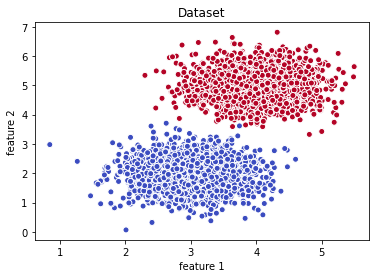
To visualize the created dataset, matplotlib has a built-in function to create scatter plots called scatter(). A scatter plot is a type of a plot that shows the data as a collection of points. The position of a point depends on its two-dimensional coordinates, where each value is a position on either the horizontal or vertical axes. The parameter c represents the color marker. Here, we parsed in the argument y, so the color will be determined by the value of our target vector. Also, edgecolor represents the edge color of the marker which in our case w shortens to white.
plt.scatter(X[:,0], X[:,1], c=y, cmap=cm.coolwarm, edgecolors='w');
plt.title('Dataset')
plt.xlabel('feature 1')
plt.ylabel('feature 2')Output:
Next, we need to split our input features X into two separate sets – X_train and X_test. We will also split our target vector y into two sets y_train and y_test. We can do this in the straightforward way by using the sklearn library. For splitting our datasets we use the well known function train_test_split(). This function contains the parameter test_size which is set to 0.2 in our code. That means that we will leave 20% of our data for testing.
Let’s look at the code:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=True)
# converting the datatypes from numpy array into tensors of type float
X_train = torch.from_numpy(X_train).type(torch.FloatTensor)
X_test = torch.from_numpy(X_test).type(torch.FloatTensor)
y_train = torch.from_numpy(y_train.squeeze()).type(torch.FloatTensor).view(-1, 1)
y_test = torch.from_numpy(y_test.squeeze()).type(torch.FloatTensor).view(-1, 1)
# checking the shape
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)Output:
torch.Size([3200, 2])
torch.Size([800, 2])
torch.Size([3200])
torch.Size([800])
If you have noticed above, the .squeeze() function is used when we want to remove single-dimensional entries from the shape of an array. Simply reducing the dimension into a rank-1 array.
2. Define the Model Structure
To define our model structure we will be using the nn.module to build our neural network. We will give it a class name ShallowNeuralNetwork. Then, we will subclass it from nn.module. Once that’s done, we need to call the super.__init() method. The super() function is used to return a proxy object that delegates method calls to a parent or sibling class of type. This is useful for accessing inherited methods that have been overridden in a class. Or in simple words, by using this function PyTorch will be able to keep track of what we are adding into the neural network. If you need a more detailed explanation of this you can visit official Python documentation.
class ShallowNeuralNetwork(nn.Module):
def __init__(self, input_num, hidden_num, output_num):
super(ShallowNeuralNetwork, self).__init__()
self.hidden = nn.Linear(input_num, hidden_num) # hidden layer
self.output = nn.Linear(hidden_num, output_num) # output layer
self.sigmoid = nn.Sigmoid() # sigmoid activation function
self.relu = nn.ReLU() # relu activation function
def forward(self, x):
x = self.relu(self.hidden(x))
out = self.output(x)
return self.sigmoid(out)
input_num = 2
hidden_num = 2
output_num = 1 # The output should be the same as the number of classes
model = ShallowNeuralNetwork(input_num, hidden_num, output_num)
model.to(device) # send our model to gpu if available else cpu.
print(model)Output: ShallowNeuralNetwork(
(hidden): Linear(in_features=2, out_features=2, bias=True)
(output): Linear(in_features=2, out_features=1, bias=True) (sigmoid): Sigmoid()
(relu): ReLU()
)
The nn.Linear() method is used to calculate the Linear transformation. It takes our input feature matrix X and multiplies it by weights and adds our bias terms. These parameters have been created by the object itself when called. All we need to do is to specify the size of the input and the output. For better understanding we will now write equations for one hidden layer neural network which is presented in the following picture.

To do calculations, we need a for loop that would look like this:
\(for\enspace i \enspace in \enspace range( m ): \)
$$ z^{[1](i)}=\mathbf{W}^{[1]} x^{(i)}+b^{[1]} $$
$$ a^{[1](i)}=\sigma\left(z^{[1](i)}\right) $$
$$ z^{[2](i)}=\mathbf{W}^{[2]} a^{[1](i)}+b^{[1]} $$
$$ a^{[2](i)}=\sigma\left(z^{[2](i)}\right) $$
If you need a more detailed explanation check out this blog post.
Next, we also want to create a ReLU()function as the activation and then sigmoid() for the output, since it’s a binary classification problem.
Now, all we need to do is to create a forward method, which receives an input tensor that passes through our hidden layer. This is going to be a linear transformation that we explained earlier, which is going to go through a ReLU()activation, another linear layer which is our output layer and finally through a sigmoid activation. Then, we can look at the structure that we have defined for our network. This means how many neurons we have in each layer, along with the activation functions.
3. Loss Function (Criterion) and Optimizer
After the forward pass, a loss function is calculated from the target y_train and the prediction y_pred in order to update weights for the improved model selection in the further step. Setting up the loss function is a fairly simple step in PyTorch. Here, we will use the Cross–entropy loss, or log loss. It measures the performance of a classification model whose output is a probability value between 0 and 1. We should note that the Cross–entropy loss increases as the predicted probability diverges from the actual label.
Next, we will use Stochastic gradient descent optimizer for the update of hyper-parameters. It is important to note that we can also use Adam optimizer which is one of the most commonly used optimizers. It is an optimization algorithm that can replace the classical stochastic gradient descent procedure to update network weights. But, since you are probably not familiar with Adam optimizer we will use a simple gradient descent. Here, a function model.parameters() will provide the parameters to the optimizer and lr=0.01 defines the learning rate for SGD algorithm.
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr = 0.01)4. Model Training
Our model is now ready to be trained. We begin by setting up an epoch size. Epoch is a single pass through the training dataset. In the example below, the number of epochs is set to 1000, meaning that there will be 1000 single passes of the training phase and weight updates.
if torch.cuda.is_available():
X_train = Variable(X_train).cuda()
y_train = Variable(y_train).cuda()
X_test = Variable(X_test).cuda()
y_test = Variable(y_test).cuda()
num_epochs = 1000
total_acc, total_loss = [], []
for epoch in range(num_epochs):
# forward propagation
model.train()
y_pred = model(X_train)
pred = np.where(y_pred > 0.5, 1, 0)
loss = criterion(y_pred, y_train)
# back propagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 50 == 0:
model.eval()
y_pred_test = model(X_test)
test_loss = criterion(y_pred_test, y_test)
total_loss.append(test_loss.item())
total = 0
pred = np.where(y_pred_test > 0.5, 1, 0)
for i in range(len(y_test)):
if int(y_test[i]) == int(pred[i]):
total += 1
acc = total / len(y_test)
total_acc.append(acc)
print('Epoch [{}/{}], Train Loss: {:.5f}, Test Loss: {:.5f}, Accuracy: {:.5f}'.format(epoch, num_epochs, loss.item(), test_loss.item(), acc))
print('\nTraining Complete')Output:
Epoch [0/1000], Train Loss: 0.66562, Test Loss: 0.66161, Accuracy: 0.82500
Epoch [50/1000], Train Loss: 0.55651, Test Loss: 0.55148, Accuracy: 0.72375
Epoch [900/1000], Train Loss: 0.24450, Test Loss: 0.23667, Accuracy: 0.96250
Epoch [950/1000], Train Loss: 0.23620, Test Loss: 0.22829, Accuracy: 0.96375 Training Complete
With the following line of code we can plot a loss and accuracy plot curve to better visualize our results.
fig = plt.figure(figsize=(12, 6))
ax = fig.add_subplot(1, 2, 1)
ax.plot(total_loss)
ax1 = fig.add_subplot(1, 2, 2)
ax1.plot(total_acc)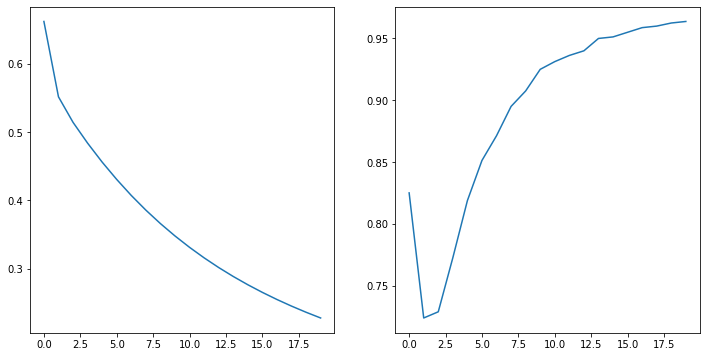
After the forward pass and the loss computation is done, we do a backward pass, which refers to the process of learning and updating the weights. First, we first need to set our gradient to zero which can be done with function optimizer.zero_grad(). This is because every time a variable is back-propagated through the network multiple times, the gradient will be accumulated instead of being replaced from the previous training step in our current training step. This will prevent our network to update its parameters properly. Then, we run a backward pass by loss.backward() and optimizer.step() which updates our parameters based on the current gradient.
5. Testing our model
Now, when our model is trained, we can simply make a new prediction by passing into the X_test matrix where we will store our feature vectors:
model.eval()
model_prediction = model(X_test)
model_prediction = np.where(model_prediction > 0.5, 1, 0)
model_prediction = model_prediction.reshape(-1)
print("Accuracy Score on test data ==>> {}%".format(accuracy_score(model_prediction, y_test) * 100))Output:
Accuracy Score on test data ==>> 100.0%
Finally, we get an accuracy score of 100%. If you are running this on your personal computer or through the interactive Google colab this accuracy score will vary constantly since the input features are randomly generated.
6. Visualize our Predictions
Finally, we may plot the result and visually compare the actual predictions with the predictions that our model has made. We may also test our result, by picking two points from the diagram and pass the values into our model to see what our model will predict.
fig, ax = plt.subplots(2, 1, figsize=(12, 10))
y_test = y_test.view(-1)
# True Predictions
ax[0].scatter(X_test[y_test==0, 0], X_test[y_test==0, 1], label='Class 0', cmap=cm.coolwarm)
ax[0].scatter(X_test[y_test==1, 0], X_test[y_test==1, 1], label='Class 1', cmap=cm.coolwarm)
ax[0].set_title('Actual Predictions')
ax[0].legend()
# Models Predictions
ax[1].scatter(X_test[model_prediction==0, 0], X_test[model_prediction==0, 1], label='Class 0', cmap=cm.coolwarm)
ax[1].scatter(X_test[model_prediction==1, 0], X_test[model_prediction==1, 1], label='Class 1', cmap=cm.coolwarm)
ax[1].set_title('Our Model Predictions')
ax[1].legend()
As you can see we obtained a perfect results. We managed to do that because our dataset was too easy.
Summary
To sum it up, we have learned how to train our neural network model to make accurate predictions for our random classification problem in PyTorch. We hope you enjoyed it. In the next post we will be working with the handwritten digit dataset.
We also provide an interactive Colab notebook which can be found here ![]() Run in Google Colab
Run in Google Colab
Here you can download code from our GitHub repo.