#010 C Random initialization of parameters in a Neural Network
Why do we need a random initialization?
If we have for example this shallow Neural Network:

Parameters for this shallow neural network are \( \textbf{W}^{[1]} \), \(\textbf{W}^{[2]} \), \(b^{[1]} \) and \(b^{[2]} \). If we initialize matrices \( \textbf{W}^{[1]} \) and \(\textbf{W}^{[2]}\) to zeros then unit1 and unit2 will give the same output, so \(a_1^{[1]}\) and \(a_2^{[1]}\) would be equal. In other words unit1 and unit2 are symmetric, and it can be shown by induction that these two units are computing the same function after every iteration of training. It also can be shown that if we calculate backpropagation it turns out that also \(dz_1^{[1]}\) and \(dz_2^{[1]}\) are equal.
Even if we have a lot of hidden units in the hidden layer they all are symetric if we initialize corresponding parameters to zeros. To solve this problem we need to initialize randomly rather then with zeros. We can do it in the following way (we consider the same shallow neural network with 2 hidden units in the hidden layer as above):
\(W_1 = np.ranom.randn((2,2))*0.01 \)
And then we can initialize \(b_1\) with zeros, because initialization of \(W_1\) breaks the symmetry, and unit1 and unit2 will not output the same value even if we initialize \(b_1\) to zero. So, we have:
\(b_1 = np.zeros((2,1)) \)
For the output layer we have:
\(W_2 = np.ranom.randn((1,2))*0.01 \)
\(b_1 = 0 .\)
Why do we multipy with \(0.01 \) rather then multiplying with \(100\) for example? What happens if we initialize parameters with zeros or randomly but with big random values?
If we are doing a binary classification and the activation in the output layer is \(sigmoid \) function or if use \(tanh\) activation function in the hidden layers then for a not so high input value these functions get saturated, for a not so big inputs they become constant (they output \(0\) or \(1\) for \(sigmoid \) or \(-1\) or \(1\) for \(tanh \) function).
So, we do the initialization of parameters \( \textbf{W}^{[1]} \) and \(\textbf{W}^{[2]} \) with small random values, hence we multipy with \(0.01\).
Random initialization is used to break symmetry and make sure different hidden units can learn different things.
If we initialize parmeters \(W_1\) and \(W_2\) with zeros, so if we change initialize_parameters functions, which we have defined in this post, to be like this
The results on the training and test set are presented in the following pictures. So, all examples are recognized as they were from class 0.
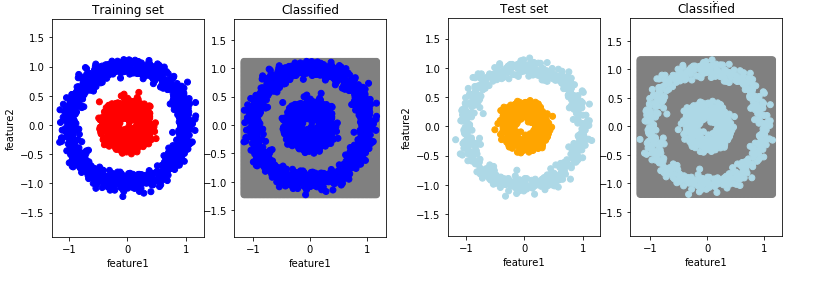
Results of classification with a shallow Neural Network when we initialize parameters with zeros

Machine Learning Memes for Convolutional Teens
If we initialize parameters with high random values, so if we change the function initialize_parameters to be like this:
The results on the training and test set are presented in the following pictures. All the other parts of the code remain the same.
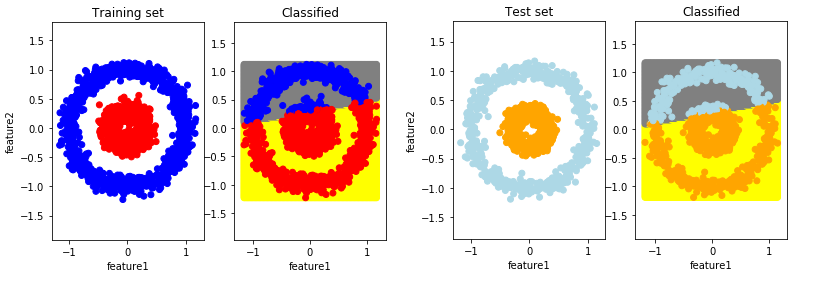
Results of classification with a shallow Neural Netrwork when we initialize parameters with big random values
We can see that algorithm will not work properly if we initialize parameters \( \textbf{W}^{[1]} \) and \(\textbf{W}^{[2]} \) with big random values.
We can conclude that we must initialize our parameters with small random values.
Well chosen initialization values of parameters leads to:
- Speed up convergence of gradient descent.
- Increase the likelihood of gradient descent to find lower training error rates
In the next post we will learn about Deep Neural Networks.