#015 CNN Why ResNets work ?
Why \(ResNets \) work?
Why do \(ResNets \) work so well? Let’s go through one example that illustrates why \(ResNets \) work so well, at least in the sense of how we can make them deeper and deeper without really hurting our ability to get them to do well on the training set. Hopefully, doing well on the training set is usually a prerequisite to doing well on the test set. So, being able to at least train \(ResNet \) to do well on the training set is a good first step towards that.
In the last post we saw that if we make a network deeper, it can decrease our ability to train the network well on the training set. Therefore, we sometimes avoid having too deep neural networks. In contrast, \(ResNets \) training performance behaves differently. To illustrate this, let’s assume that we have \(x \) feeding into a big neural network (Big NN in the picture below) and this outputs some activation \(a^{\left [ l \right ]} \). Let’s try to make this big neural network even a little bit more deeper. Hence, the same Big NN we will extend with two extra layers. In other words, we have added one residual block.
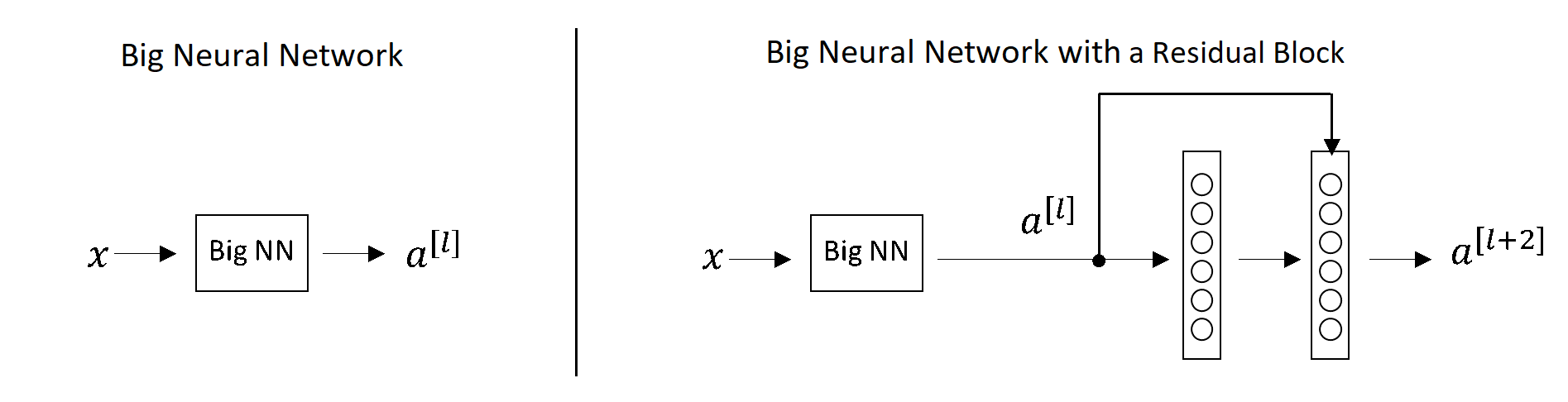
Big Neural Network (left); Big Neural with a Residual Block (right)
Throughout this network we are using the \(ReLU \) activation function, so all the activations are going to be greater than or equal to 0 with a positive exception of the input \(x \). That is because the \(ReLU \) activation outputs numbers that are either zero or positive, but \(X= a^{[0]} \) may not be greater than or equal to \(0 \).
Equations for the neural network with a residual block are:
\(a^{\left [ l+2 \right ]}=g\left ( z^{\left [ l+2 \right ]}+a^{\left [ l \right ]} \right ) \)
\(a^{\left [ l+2 \right ]}=g\left ( W^{\left [ l+2 \right ]}a^{\left [ l+1 \right ]}+b^{\left [ l+2 \right ]}+a^{\left [ l \right ]} \right ) \)
If we have \(W^{\left [ l+2 \right ]}=0 \) and \(b=0 \) then:
\(a^{\left [ l+2 \right ]}=g\left ( W^{\left [ l+2 \right ]}a^{\left [ l+1 \right ]}+b^{\left [ l+2 \right ]}+a^{\left [ l \right ]} \right )=g\left ( a^{\left [ l \right ]} \right )=a^{\left [ l \right ]} \)
As we have said, we’re using the \(ReLU \) activation function so all the activations are non-negative and \( g^{[l]} =a^{[l]} \) because \(g \) is applied to non-negative quantity.
This shows that the identity function is easy for residual block to learn and it’s easy to get \(a^{[ l+2]}= a^{[l]} \) because of a skipped connection. This means that having these two layers in a neural network it doesn’t really hurt our neural networks ability to do as well as this simpler network without these two extra layers, because it’s quite easy for it to learn the identity function to just copy \(a^{[l]} \) to \(a^{[l+2]} \) despite the addition of these two layers. This is the reason why adding two extra residual block layers in the middle or to the end of the big neural network doesn’t affect the performance.
Why do residual networks work?
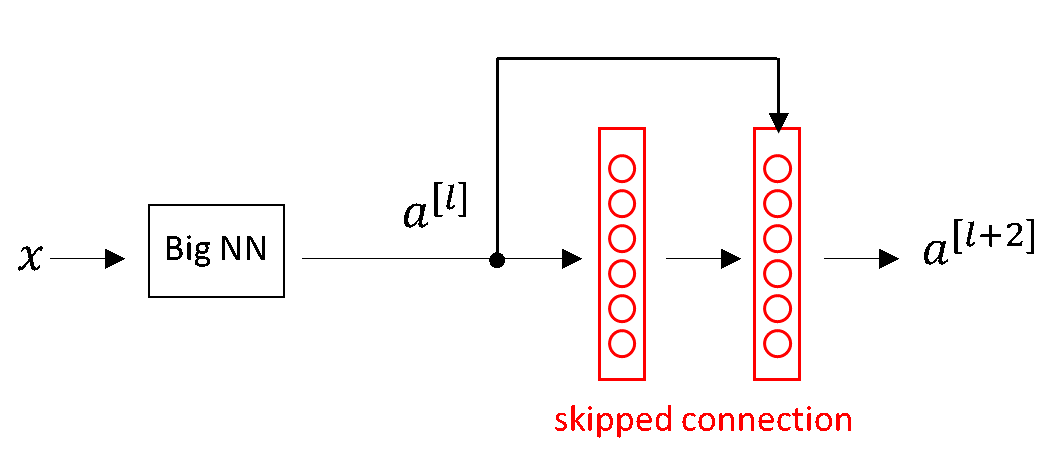
A big neural network with a “skipped connection”
By adding these two additional layers (painted in red in the picture above) we can see an improvement of the net’s performance.
In the very deep plain nets (without residual blocks) making the network deeper makes even the learning of an identity function quite difficult. Therefore, adding a lot of layers, starts to produce worse results instead of making them better.
On the other hand, the residual networks with the residual blocks:
- Can learn identity function
- Do not hurt performance
- And after a residual block, the gradient descent is capable to improve further on.
The main reason the residual network works is that it is so easy for those extra layers to learn the residual.
What if the input and the output of a residual block have a different dimensions?
Here we are assuming that \(z^{\left [ l+2 \right ]} \) and \(a^{\left [ l \right ]} \) have the same dimension. This is why in \(ResNets \) there is a lot of use of \(Same\enspace convolutions \). In this way the dimension of quantity on the input of a residual block is equal to the dimension on the output of the residual block. We can actually do this short connection because the \(Same \enspace convolution\) preserves dimensions and it makes easier for us to perform addition of two equal dimension vectors.
We are considering the following equation:
\(a^{\left [ l+2 \right ]}=g\left ( W^{\left [ l+2 \right ]}a^{\left [ l+1 \right ]}+b^{\left [ l+2 \right ]}+a^{\left [ l \right ]} \right ) \)
For example, if \(a^{\left [ l \right ]} \) is \(128 \) dimensional and \(z \), or therefore \(a^{\left [ l+2 \right ]} \), is \(256 \) dimensional. We would add an extra matrix \(W_{s} \in \mathbb{R}^{256\times 128} \) so then \(W_{s}\times a^{\left [ l \right ]} \) becomes \(256 \) dimensional and then we have addition between two \(256 \) dimensional vectors. \(W_{s} \) could be a matrix of parameters to be learned, a fixed matrix that just implement zero padding, so it takes \(a^{\left [ l \right ]} \) and then zero pads it to be a \(256 \) dimensional. Both versions could nicely work. Finally, let’s take a look at \(ResNets \) on images.
\(ResNets \) on images
This is an example of a plain network in which we input an image and then have a number of \(conv \) layers until eventually we have a \(softmax \) output at the end.
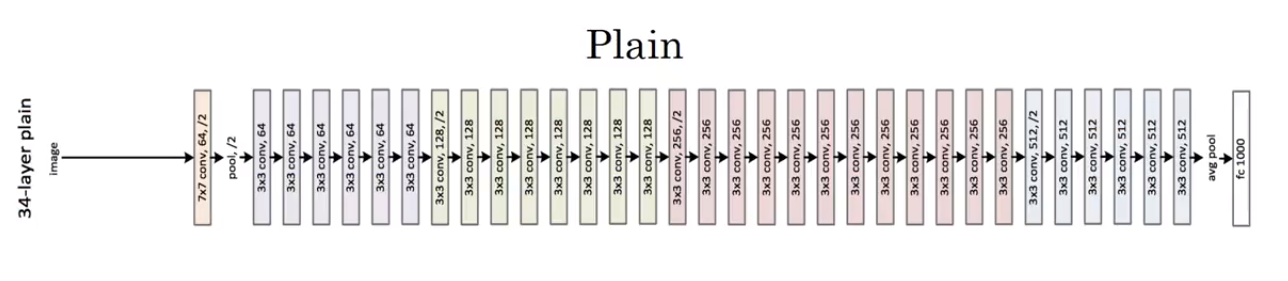 A Plain neural network
A Plain neural network
To turn this into a \(ResNet \) we add these skipped connections. There are a lot of \(3 \times 3 \) convolutions here and most of these are \(3 \times 3 \) same convolutions. That’s why we’re adding our equal dimension feature vectors.

A \(Residual \) network
Here are used \(same \) convolutions so the dimension is preserved, and the \(z^{\left [ l+2 \right ]}+a^{\left [ l \right ]} \) eqition makes sense. Similar to what we’ve seen in a lot of networks before, we have a bunch of convolutional layers and then pooling layers. In these networks we also have following layers: \(conv,\enspace conv, \enspace conv,\enspace pool,\enspace conv,\enspace conv,\enspace conv,\enspace pool,\enspace conv,\enspace conv,\enspace conv, \enspace pool \), and then at the end we have a \(Fully\enspace connected \) layer that then makes a prediction using a \(softmax \).
There’s a very interesting idea behind using neural networks with \(1\times1 \) filters, so called \(1\times1 \) convolutions. So, why a \(1\times1 \) convolution is good? Let’s go to next post.