Highlights: Every computer vision pipeline that touches color starts with the same mistake: using RGB. RGB is built for screens, not for human perception. In this post we build a complete color scoring system for living room images — from the right color space (Lab), through palette extraction (K-means), to a two-color harmony scorer tested on 10 global brand palettes. We discover why luxury brands deliberately score low, and what that means for your model.…
Read more
LLM_log #016: RGB is for Screens. Lab is for Humans — Color Scoring for Living Room Images

LLM_log #015: Fine-Tuning LLMs — Teach a 3B Model to Call Functions with QLoRA + Unsloth on Free Colab T4
Highlights: Every modern LLM agent — from ChatGPT plugins to Claude tools — relies on a single learned skill: outputting a structured JSON function call instead of free text. In this post we teach that skill to a 3-billion parameter model using QLoRA on a free Google Colab T4. We start from the fundamentals — why fine-tuning, when LoRA, how quantization works — then build the full training pipeline from scratch. By the end, your…
Read more
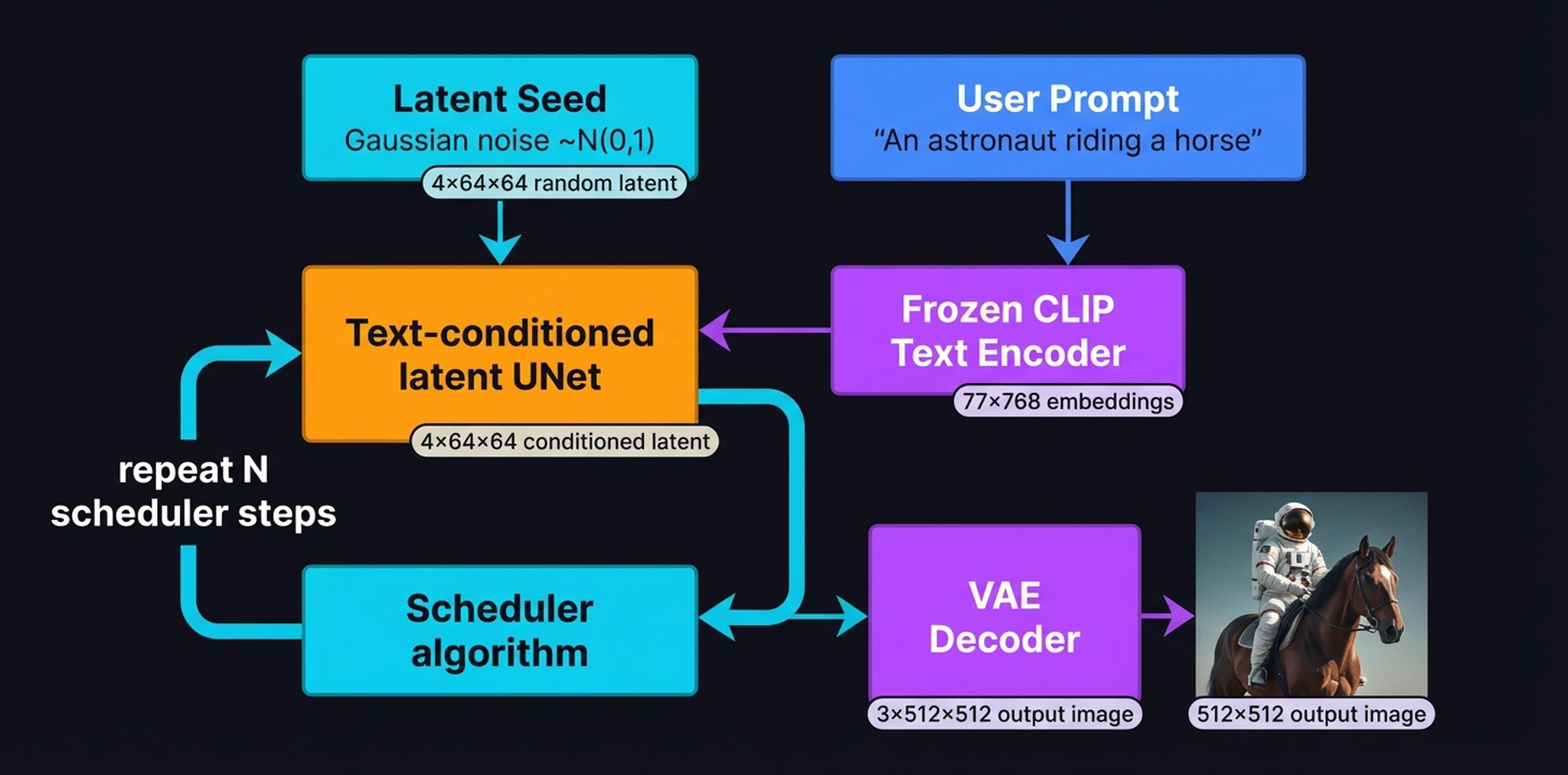
LLM_log #014: Stable Diffusion & Conditional Latent Diffusion — From VAE Compression to Cross-Attention Conditioning
Highlights: Stable Diffusion doesn’t paint an image in one shot — it sculpts one from static, guided by your words. In this post we disassemble the entire machine. We start with the VAE that compresses pixels into a tractable latent space, walk through the forward and reverse diffusion processes, open up the UNet to see how cross-attention physically connects text tokens to spatial regions, and finish with the complete Latent Diffusion architecture diagram that ties…
Read more

LLM_log #013: Latent Space — From AutoEncoders to the Engine Inside Stable Diffusion
Highlights: Every time you use Stable Diffusion, DALL-E, or Sora, the model never touches a single pixel during its main computation. It works entirely inside a compressed, structured space of floating-point numbers — a latent space learned by a VAE. In this post we build that space from scratch. We start from the simplest possible compression — an AutoEncoder on MNIST digits — understand why it fails at generation, fix it with the VAE’s probabilistic…
Read more
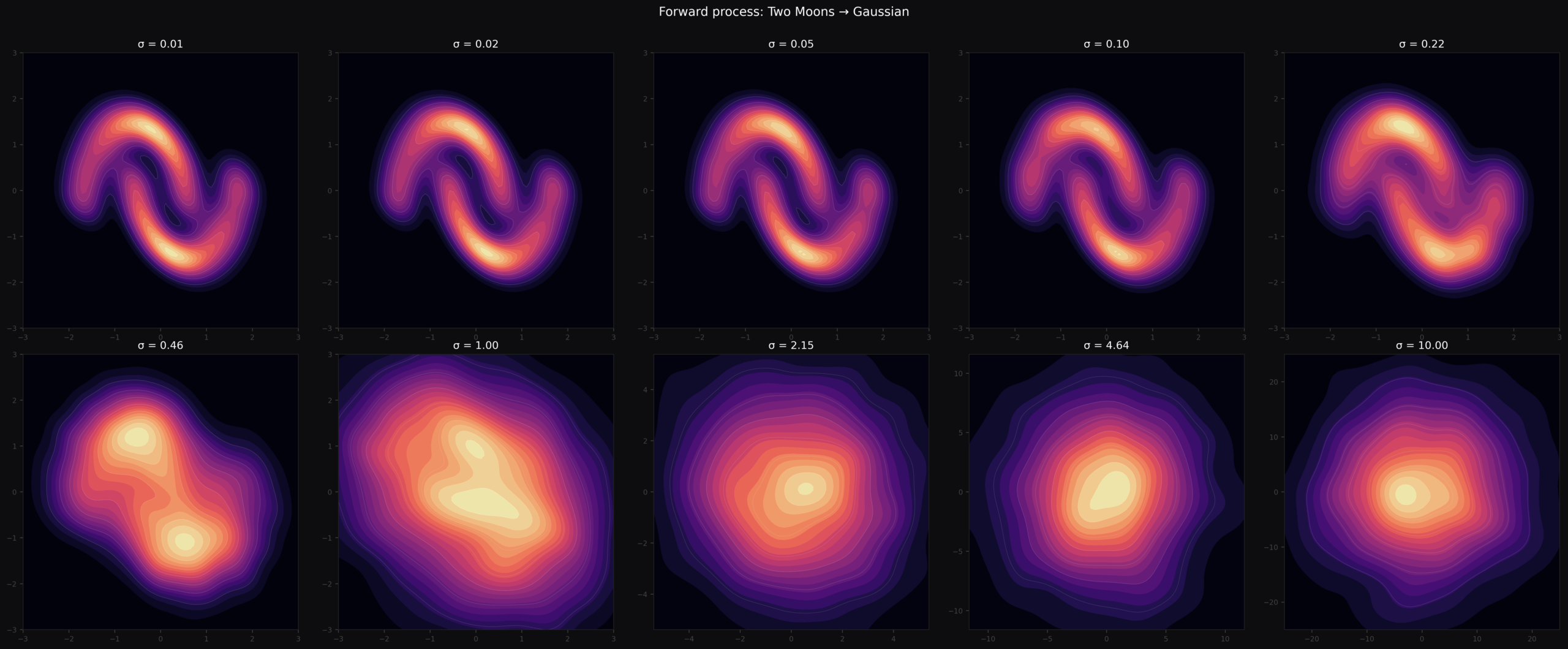
LLM_log #012: Introduction to Diffusion Models — From Noise to Geometry to Sampling
Highlights: In this post we build a complete understanding of diffusion models from the ground up — what they are, how images are represented, how the network is trained, what it geometrically learns, and finally how we turn that geometry into samples using DDIM and DDPM. Every formula is accompanied by concrete numbers you can verify by hand. So let’s begin! Tutorial Overview: What Are Diffusion Models? How Images Are Represented The Denoiser Network Noise…
Read more

LLM_log #011: Diffusion Models — From Noise to Wolves, Training from Scratch
In this post we build a complete diffusion model from scratch — training a UNet on a custom dataset, implementing the full DDPM pipeline, and understanding the math that makes iterative denoising work. We cover noise schedules, the reparameterization trick, FID evaluation, and three diffusion objectives (ε, x₀, v). By the end you’ll have generated novel images from pure Gaussian noise, and understand why diffusion models overtook GANs as the dominant paradigm for image generation.…
Read more

LLM_log #010 Understanding Diffusion Models Through 1D Experiments — From DDPM to Manifold Compactness
Highlights: We implement a complete DDPM from scratch on 1D sine waves — same math as image diffusion, but every intermediate state is plottable. We track 100 parallel trajectories, measure when the model “commits” to a specific sample, then design a controlled experiment that reveals manifold compactness as the key factor determining whether diffusion succeeds or fails. So let’s begin! Tutorial Overview: Why 1D? The Dataset Forward Process Model and Training Generating from Noise What…
Read more
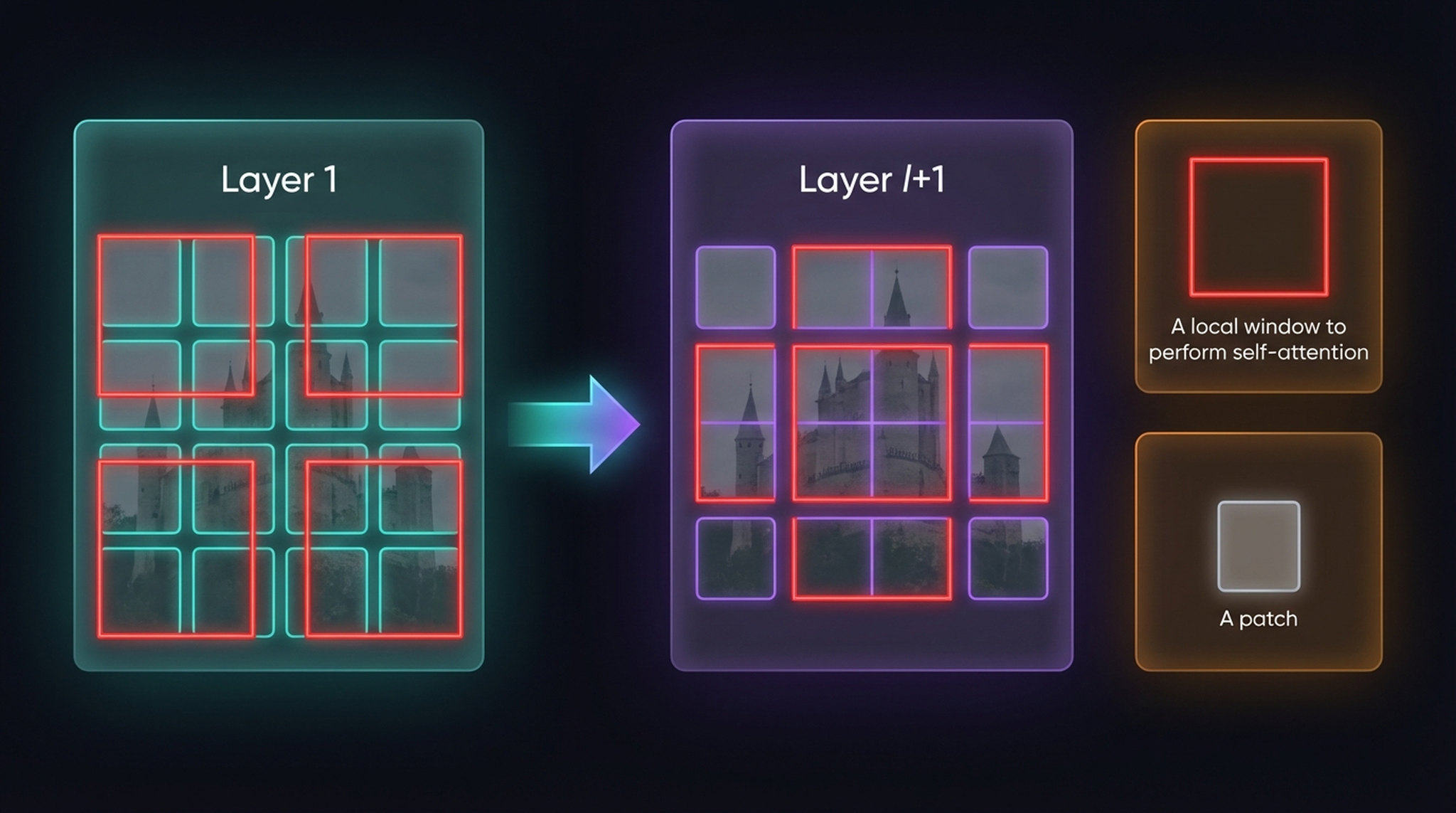
LLM_log #009: An Image is Worth 16×16 Words — From Transformers to Vision Transformers and SWIN
Highlights: In this post, we take a deep dive into the architecture that changed everything — the Transformer — and trace its evolution from NLP into computer vision. We start with the original encoder-decoder model, walk through self-attention and multi-head attention step by step, and then show how Vision Transformers (ViT) apply the exact same mechanism to image patches instead of words. Along the way, we answer the questions that trip everyone up: if we…
Read more

#004 How to smooth and sharpen an image in OpenCV?
Highlight: In our previous posts we mastered some basic image processing techniques and now we are ready to move on to more advanced concepts. In this post, we are going to explain how to blur and sharpen images. When we want to blur or sharpen our image, we need to apply a linear filter. You will learn several types of filters that we often use in the image processing In addition, we will also show…
Read more

#000 How to access and edit pixel values in OpenCV with Python?
Highlight: Welcome to another datahacker.rs post series! We are going to talk about digital image processing using OpenCV in Python. In this series, you will be introduced to the basic concepts of OpenCV and you will be able to start writing your first scripts in Python. Our first post will provide you with an introduction to the OpenCV library and some basic concepts that are necessary for building your computer vision applications. You will learn…
Read more

#006 Linear Algebra – Inner or Dot Product of two Vectors
Highlight: In this post we will review one of the fundamental operators in Linear Algebra. It is known as a Dot product or an Inner product of two vectors. Most of you are already familiar with this operator, and actually it’s quite easy to explain. And yet, we will give some additional insights as well as some basic info how to use it in Python. Tutorial Overview: Dot product :: Definition and properties Linear functions…
Read more

#008 Linear Algebra – Eigenvectors and Eigenvalues
Highlight: In this post we will talk about eigenvalues and eigenvectors. This concept proved to be quite puzzling to comprehend for many machine learning and linear algebra practitioners. However, with a very good and solid introduction that we provided in our previous posts we will be able to explain eigenvalues and eigenvectors and enable very good visual interpretation and intuition of these topics. We give some Python recipes as well. Tutorial Overview: Intuition about eigenvectors…
Read more

#011 TF How to improve the model performance with Data Augmentation?
Highlights: In this post we will show the benefits of data augmentation techniques as a way to improve performance of a model. This method will be very beneficial when we do not have enough data at our disposal. Tutorial Overview: Training without data augmentation What is data augmentation? Training with data augmentation Visualization 1. Training without data augmentation A familiar question is “why should we use data augmentation?”. So, let’s see the answer. In order…
Read more