LLM_log #002: Tokenization in Large Language Modelling
Understanding Tokenization in Large Language Models
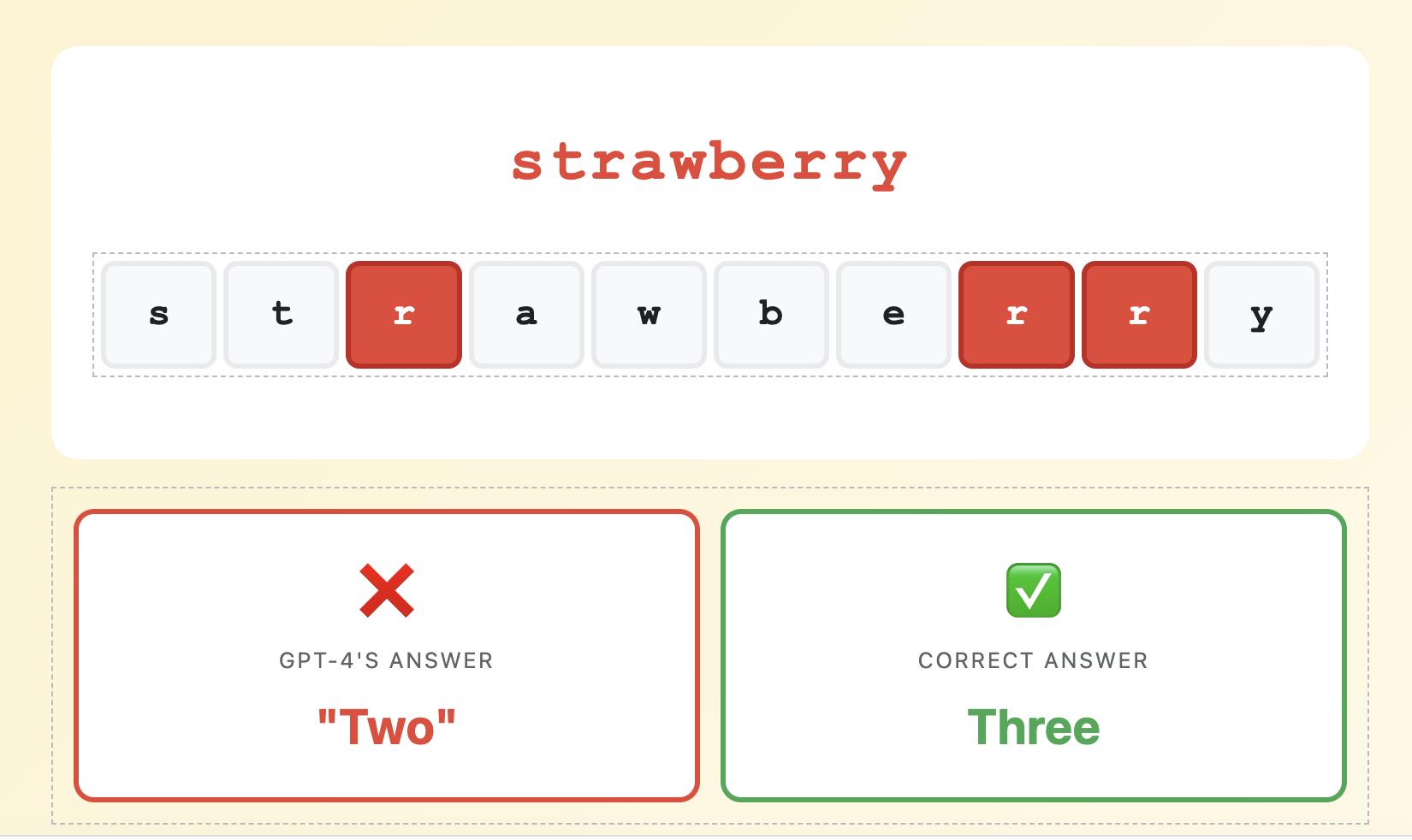
Why GPT-4 Can’t Count the Letters in “Strawberry”
VLADIMIR MATIC, PhD – DataHacker.rs – January 2025
| s | t | r | a | w | b | e | r | r | y |
|
❌
GPT-4’s Answer
“Two”
|
✅
Correct Answer
Three
|
In early 2024, this simple question stumped GPT-4. A billion-dollar AI model failed at counting letters in a 10-letter word. Why?
The answer lies in tokenization.
🔍 Why GPT-4 Gets This Wrong
GPT-4 never sees the word as individual letters.
It sees it as tokens (chunks of text).
👁 What You See
10 individual letters |
🤖 What GPT-4 Sees
2 tokens (chunks) |
This Isn’t a Bug – It’s How LLMs Work
GPT-4’s tokenizer learned that “strawberry” is efficiently represented as two chunks: “straw” + “berry”. The model can’t “see” the individual ‘r’s because they’re buried inside these tokens.
It’s like asking someone to count letters in a sealed envelope. The information exists, but it’s not directly accessible.
🎯 More Tokenization Failures
1. Reversing WordsTask: Reverse “hello”
GPT-4: “olleh” ✅Task: Reverse “strawberry” GPT-4: Often wrong ❌ Why? “strawberry” = [straw][berry]. The model can’t reverse what it can’t see letter-by-letter. |
2. Multi-Digit ArithmeticTask: 123 + 456
GPT-4: 579 ✅Task: 8732 x 9461 GPT-4: Often wrong ❌ Why? “870” might be one token, but “871” is [8][71]. Inconsistent tokenization makes patterns hard to learn. |
3. Multilingual CostEnglish: “Hello” = 1 token
Arabic: “marhaba” = 3-4 tokens Cost: 3-4x more! 💰 Why? Tokenizers trained on English are inefficient for non-Latin scripts. |
4. The Glitch TokenInput: “SolidGoldMagikarp”
GPT-3: Complete nonsense ❌ Why? This token existed in vocabulary but was never trained on, causing bizarre behavior. |
Why Tokenization Matters: Three Real-World Impacts
1. 💰 Cost
API pricing is typically based on token usage – the more tokens, the higher the cost. Token efficiency directly translates to money.
GPT-4 tokenizer: 7 tokensCost difference: 42% cheaper with GPT-4!
For a company making 1 million API calls per day with an average of 50 tokens per call:
- With GPT-2 efficiency: 50M tokens/day x $0.03/1K = $1,500/day = $547,500/year
- With GPT-4 efficiency: 35M tokens/day x $0.03/1K = $1,050/day = $383,250/year
- Savings: $164,250 per year just from tokenization efficiency!
2. 🌍 Fairness
Tokenizers trained primarily on English text penalize users of other languages. This isn’t just unfair – it’s a structural bias in how LLMs work.
Arabic: 6 tokens (3x cost)
Chinese: 4 tokens (2x cost)
Serbian: 5 tokens (2.5x cost)
This affects three critical areas:
- API costs: Non-English speakers literally pay 2-3x more for the same functionality
- Context window: Less actual content fits for non-English users (8K tokens = less text)
- Model performance: Fewer tokens means the model “sees” less context, degrading quality
3. 🎯 Capability
What the tokenizer can “see” fundamentally determines what the model can learn. This is why specialized models exist.
“def calculate(x): return x * 2”
= [“de”, “##f”, “calculate”, “(“, “x”, “)”, “:”, “return”, “x”, “*”, “2”]
= Lost indentation, “def” split into piecesStarCoder2 (2024) viewing the same code:
“def calculate(x): return x * 2”
= [“def”, “calculate”, “(“, “x”, “):”, “return”, “x”, “*”, “2”]
= “def” as single token, cleaner structure
StarCoder2’s tokenizer has:
- Single tokens for Python keywords (def, class, return)
- Single tokens for multiple spaces (handles Python indentation properly)
- Digit-by-digit number tokenization (better mathematical reasoning)
- Special tokens for code structure
How Tokenization Works
Now that you understand why tokenization matters, let’s explore how it actually works. When you type text into ChatGPT, a crucial transformation happens before the model even begins to “think.”
|
Input
“Have the bards who preceded…”
|
= |
Tokenization
Break into smaller pieces
|
= |
Numeric Representation
Token IDs and Embeddings
|
Think of it like this: If you’re trying to understand a book, but someone only gives you whole pages at a time (never individual words or sentences), your understanding would be limited. Similarly, if someone gives you individual letters, you’d spend all your time assembling them into words. Tokens are the “just right” level of granularity.
Let’s See It In Action
Here’s how to tokenize “strawberry” and see why GPT-4 can’t count the ‘r’s:
tokenizer = AutoTokenizer.from_pretrained(“gpt2”)# Tokenize “strawberry”
text = “strawberry”
tokens = tokenizer.tokenize(text)
token_ids = tokenizer.encode(text)
print(f”Tokens: {tokens}”)
print(f”Token IDs: {token_ids}”)
# Output:
# Tokens: [‘straw’, ‘berry’]
# Token IDs: [2536, 19772]
The model never sees “s-t-r-a-w-b-e-r-r-y”. It sees two tokens: 2536 and 19772. Those are just numbers referencing entries in the tokenizer’s vocabulary.
The Four Tokenization Paradigms
There are fundamentally different approaches to breaking down text. Modern LLMs use subword tokenization, but understanding all four paradigms reveals why.
📝 Word TokensAI
is amazing ! 🤖 ✓ Intuitive
✗ Can’t handle new words |
✨ Subword Tokens
|
🔤 Character TokensA
I . i s . a m a z … ✓ Can spell anything
✗ Very long sequences (3x more tokens) |
⚛ Byte Tokens01000001 01001001 00100000…
(A) (I) (space) ✓ Universal
✗ Extremely long (8x more tokens) |
Why subword tokenization wins: It’s the “Goldilocks” solution. Common words stay intact (“AI”, “is”), while rare words break into reusable pieces (“amaz” + “ing”). This allows the model to understand new words it’s never seen before.
“unthinkable” = [“un”, “think”, “able”]The model recognizes “un-” (negation prefix) and “-able” (capability suffix)
Even though it never saw “unthinkable”, it can understand it!
Comparing Real Tokenizers: The Evolution (2018-2024)
Over six years, tokenizers went from losing information ([UNK] tokens) to being 35% more efficient while handling emojis, multiple languages, and specialized domains like code.
Our Test Text
marhaba (Arabic) Privet (Cyrillic)# Python code
def calculate_price(tokens):
return tokens * 0.03 / 1000
| ✓ Special chars | ✓ Emojis | ✓ Multilingual | ✓ Code: def, return |
The pioneer. BERT introduced Transformers to NLP but had significant limitations.
Result: ~70 tokens
vladimir
mat
##ic
loves
ai
!
[UNK]
[UNK]
[UNK]
(
arabic
)
[UNK]
(
cy
##ril
##lic
)
#
python
code
de
##f
calculate
_
price
(
token
##s
)
:
return
token
##s
*
0
.
03
/
1000
[SEP]
Key Observations:
- Everything lowercase: “VLADIMIR” becomes “vladimir” (info lost)
- All emojis become [UNK]: Model is completely blind to emojis
- Arabic/Cyrillic text becomes [UNK]: Non-Latin scripts unrepresentable
- “def” split: Python keyword becomes “de” + “##f” (loses meaning)
The breakthrough. GPT-2 solved the [UNK] problem with byte-level encoding.
Result: ~85 tokens
AD
IM
IR
MAT
IC
loves
AI
!
mar
ha
ba
(
Arabic
)
Pri
vet
(
Cyr
illic
)
#
Python
code
def
calculate
_
price
(
tok
ens
)
:
return
tok
ens
*
0
.
03
/
10
00
Key Observations:
- Capitalization preserved: VLADIMIR stays uppercase
- No [UNK] tokens: Everything gets tokenized via byte-level fallback
- “def” as single token: Common keywords recognized
- Numbers chunked inconsistently: 1000 = “10” + “00” (not ideal for math)
The optimizer. Larger vocabulary makes tokenization 35% more efficient than GPT-2.
Result: ~55 tokens ✓
IMIR
MATIC
loves
AI
!
marhaba
(
Arabic
)
Privet
(
Cyrillic
)
#
Python
code
def
calculate
_
price
(
tokens
):
return
tokens
*
0.03
/
1000
Key Observations:
- 35% fewer tokens: Same text, 55 vs 85 tokens = significant cost savings!
- “MATIC” in one token: Larger vocabulary handles more words efficiently
- “tokens” as single token: Common programming words recognized whole
- “0.03” and “1000” as single tokens: Numbers grouped efficiently
The specialist. Optimized for code with digit-by-digit number tokenization.
Result: ~68 tokens
AD
IM
IR
MAT
IC
loves
AI
!
mar
ha
ba
(
Arabic
)
Pri
vet
(
Cyr
illic
)
#
Python
code
def
calculate
_
price
(
tok
ens
)
:
return
tok
ens
*
0
.
0
3
/
1
0
0
0
▲ Notice: 0.03 = [0][.][0][3] and 1000 = [1][0][0][0] – digit by digit!
Key Observations:
- Digit-by-digit numbers: 0.03 = [0][.][0][3], 1000 = [1][0][0][0]
- Why digit-by-digit? Makes 870 vs 871 differ by just one token – better math!
- “def” as single token: Code keywords optimized
- Trade-off: More tokens for numbers, but better mathematical reasoning
Evolution Insights
- 2018 to 2019: Byte-level fallback eliminated [UNK] tokens completely
- 2019 to 2023: Larger vocabularies achieved 35% efficiency gains
- 2023 to 2024: Domain specialization (code, math) became key
Design Trade-offs Revealed
Looking at this comparison, several fundamental trade-offs become clear:
Vocabulary size vs. Model size: GPT-4’s ~100K vocabulary makes tokenization more efficient, but the embedding layer (which maps token IDs to vectors) becomes larger. A 30K vocabulary needs 30K vectors; a 100K vocabulary needs 100K vectors. This is pure memory.
General vs. Specialized: GPT-4 optimizes for general text across many languages. StarCoder2 sacrifices some text efficiency (digit-by-digit numbers) to excel at code. You can’t optimize for everything simultaneously.
Efficiency vs. Capability: StarCoder2’s digit-by-digit tokenization uses more tokens (lower efficiency, higher cost) but enables better mathematical reasoning. When “870” and “871” tokenize as [8][7][0] and [8][7][1], the model sees the pattern that they differ by just one digit.
Language fairness vs. Optimization: To make English tokenization efficient, you need English-heavy training data for the tokenizer. This inevitably makes other languages less efficient. There’s no way around this with current approaches.
Comprehensive Comparison
| Property | BERT (2018) | GPT-2 (2019) | GPT-4 (2023) | StarCoder2 (2024) |
|---|---|---|---|---|
| Method | WordPiece | BPE | BPE | BPE |
| Vocabulary Size | 30,522 | 50,257 | ~100,000 | 49,152 |
| Total Tokens | ~70 | ~85 | ~55 ✓ | ~68 |
| Capitalization | ❌ Lost | ✓ Preserved | ✓ Preserved | ✓ Preserved |
| Special Chars | ❌ [UNK] | Multiple tokens | ✓ 1 token | ✓ 1 token |
| Emojis | ❌ All [UNK] | Multiple tokens | ✓ Efficient | Multiple tokens |
| Non-Latin Scripts | ❌ [UNK] | Multiple tokens | ✓ Efficient | Multiple tokens |
| “def” keyword | Split (de+##f) | 1 token | ✓ 1 token | ✓ 1 token |
| Best Use Case | Classification, NER | Text generation | General purpose | Code generation |
Try It Yourself – Complete Code
Here’s clean, runnable Python code to compare all tokenizers:
text = “””VLADIMIR MATIC loves AI!
marhaba (Arabic) Privet (Cyrillic)def calculate_price(tokens):
return tokens * 0.03 / 1000
result = 2**10 + 500″””
# Compare tokenizers
models = {
“BERT”: “bert-base-uncased”,
“GPT-2”: “gpt2”,
“StarCoder2”: “bigcode/starcoder2-3b”
}
for name, model_name in models.items():
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokens = tokenizer(text).input_ids
print(f”{name}: {len(tokens)} tokens”)
# For GPT-4 (requires tiktoken)
import tiktoken
enc = tiktoken.encoding_for_model(“gpt-4″)
print(f”GPT-4: {len(enc.encode(text))} tokens”)
Installation:
Expected output:
GPT-2: ~85 tokens
StarCoder2: ~68 tokens
GPT-4: ~55 tokens
Practical Takeaways for LLM Users
When Choosing a Model
- Test your actual content: Don’t assume token counts. Use tiktoken or the OpenAI tokenizer playground to see how YOUR prompts tokenize.
- Consider domain-specific models: Need code? StarCoder beats GPT-4. Need science? Galactica might be better. General purpose? GPT-4/Claude are optimal.
- Account for language bias: If you’re building for non-English users, factor in 2-3x token inflation in your cost estimates.
When Writing Prompts
- Be concise: Every word costs tokens. “Please explain” vs “Explain” is one extra token per request. Multiply by millions of requests.
- Avoid unnecessary formatting: Markdown bullets, headers, and emphasis all cost tokens. Use them only when they improve output quality.
- Front-load important context: Models pay more “attention” to recent tokens. Put critical information near the end of your prompt.
When Building Applications
- Monitor token usage: Track average tokens per request, per user, per feature. Find your inefficiencies.
- Implement token budgets: Limit context window usage. Don’t send entire documents when a summary would work.
- Cache tokenized inputs: If you’re sending the same system prompt on every request, cache the tokenized version.
- Chunk strategically: When splitting long documents, split at semantic boundaries (paragraphs, sections), not arbitrary token counts.
- Use traditional code for letter-level tasks: Don’t ask an LLM to count letters, reverse strings, or do arithmetic. Use Python for that.
Understanding the Limitations
Knowing how tokenization works helps you understand when LLMs will struggle:
- Letter-level tasks: Counting, reversing, anagrams – the model can’t see individual letters
- Exact arithmetic: Inconsistent number tokenization makes patterns hard to learn
- Spelling: The model can spell common words (they’re single tokens) but struggles with rare words
- Character-level patterns: Detecting repeated characters, palindromes, etc.
For these tasks, use traditional programming. For everything else – pattern matching, generation, understanding context – LLMs excel precisely because they work at the token level.
What’s Next?
Now that you understand tokenization – the first step in how LLMs process text – you’re ready for the next pieces of the puzzle:
- Embeddings: How do those token IDs become meaningful numeric vectors? What makes “king” – “man” + “woman” approximately equal “queen” work mathematically?
- The Transformer architecture: What happens inside the model after tokenization? How does self-attention work?
- Training dynamics: How do models learn from tokens? What’s the role of the tokenizer during training vs. inference?
- Advanced tokenization: BPE vs. WordPiece vs. Unigram – what are the differences? How are tokenizers trained?
These topics will be covered in future posts on DataHacker.rs. Understanding tokenization first makes everything else make more sense.
Key Takeaways
- Tokenization is invisible but crucial – It determines what the model can “see” and learn
- The strawberry problem is universal – LLMs struggle with letter-level tasks because of tokenization
- Evolution shows clear progress – From BERT’s [UNK] tokens to GPT-4’s efficiency
- Subword tokenization wins – Best balance between vocabulary size and flexibility
- Specialization matters – Code models need different tokenizers than general models
- Efficiency = Cost – Fewer tokens per text = lower API costs
- Multilingual bias exists – English is 2-3x cheaper than Arabic or Chinese
– Sennrich et al., 2016 – Neural Machine Translation of Rare Words with Subword Units (BPE)
– Kudo, 2018 – SentencePiece: A Simple and Language Independent Subword Tokenizer
– OpenAI Tokenizer Playground
Written by VLADIMIR MATIC, PhD
DataHacker.rs – Based on “Hands-On Large Language Models” by Jay Alammar and Maarten Grootendorst