#013 PyTorch – Shallow Neural Network on MNIST dataset in PyTorch
Highlights: Hello everyone and welcome back. In the previous post we have seen how to build one Shallow Neural Network and tested it on a dataset of random points. In this post we will demonstrate how to build efficient Neural Networks using the nn module. That means that we are going to use a fully-connected ReLU network with one hidden layer, trained to predict the output \(y \) from given \(x \) by minimizing squared Euclidean distance. You will find that simpler and powerful. For demonstration purposes we will use the MNIST dataset. So without further ado, let’s roll.

Tutorial Overview:
- Setting up the Environment
- Load MNIST Dataset from TorchVision.
- Defining Neural Network.
- Training Neural Network.
- Evaluating the Network.
As we all know the MNIST dataset is a collection of grayscale handwritten digits ranging from 0, 1, 2, to 9. Each of these images has dimensions of \(28 \times 28 \) pixels. In our classification problem we want to identify what number is written in these images.
To access this dataset we will use the Torchvision package which comes along with PyTorch. This library allows us to use a large number of datasets and the models for tackling computer vision problems.
Download Code
Before we go over the explanation, we need to download code from our GitHub repo.

1. Setting up the Environment
One of the advantages of PyTorch over the other frameworks such as TensorFlow (prior to 2.0), CNKT and Caffe2, is that it has dynamic execution graphs. This means that the computation graph is created during the code execution. Literally on the fly.
Now let’s import necessary libraries.
# Import required packages
import numpy as np
from matplotlib import pyplot as plt
from torchvision import datasets, transforms
import torch
from torch import nn
from torch import optim
import torch.nn.functional as F
#import helper
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
# moves your model to train on your gpu if available else it uses your cpu
device = ("cuda" if torch.cuda.is_available() else "cpu")2. Load MNIST Dataset from TorchVision
# Define transform to normalize data
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))
])
# Download and load the training data
train_set = datasets.MNIST('DATA_MNIST/', download=True, train=True, transform=transform)
trainLoader = torch.utils.data.DataLoader(train_set, batch_size=64, shuffle=True)
validation_set = datasets.MNIST('DATA_MNIST/', download=True, train=False, transform=transform)
validationLoader = torch.utils.data.DataLoader(test_set, batch_size=64, shuffle=True)Once this cell is executed, our dataset is downloaded and stored in the variable train_set. In order to load the MNIST dataset in a handy way, we will need DataLoaders for the dataset. DataLoader() class combines a dataset and a sampler, and provides single or multi-process iterators over the dataset. We will use a batch_size of 64 which means that we will use 64 images for the training. Also, argument shuffle is set to True which means that we have the data reshuffled at every epoch.
You may notice these values 0.1307 and 0.3081. Why do we need these values with decimal places? It is crucial to understand the values are pre-calculated for the function transforms.Normalize() They represent the global mean and standard deviation of the MNIST dataset. Function transforms.ToTensor()converts the entire array into torch tensor and divides by 255. So values are between 0.0 and 1.0.
Additionally TorchVision offers a lot of handy transformations, such as cropping, resizing, scaling and more.
training_data = iter(trainLoader)
images, labels = training_data.next()
print(type(images)) # Checking the datatype
print(images.shape) # the size of the image
print(labels.shape) # the size of the labelsOutput:
<class 'torch.Tensor'>
torch.Size([64, 1, 28, 28])
torch.Size([64])
Now let’s turn our trainloader object into an iterator. For this we will use the function iter which allows us to access our images and labels from this generator. We can see the shape as \(64 \times 1 \times 28 \times 28 \). This means:
- 64: Represents 64 Images
- 1: One color channel => Grayscale
- 28 by 28 pixel: the shape of these images so we can visualize it.
By visualizing, we can see that this is an image with a handwritten number.. Notice that here we are using the function squeeze() which eliminates any dimension that has size of 1. So, it gives an output tensor with one fewer dimension than the input tensor.
plt.imshow(images[42].numpy().squeeze(), cmap='inferno')
3. Building the Network
Now let’s build our neural network using this object-oriented class method within nn.Module. We will use 3 fully-connected (or linear) layers. When we build a neural network, one of the choices we have to make is what activation functions to use in the hidden layers as well as at the output unit of the Neural Network. As an activation function, we will choose rectified linear units (ReLU for short). This function is a commonly used activation function nowadays. If you need more detailed explanation of the activation functions and their derivatives check out this link. Let’s look at the code.
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.fc1 = nn.Linear(784, 256)
self.fc2 = nn.Linear(256, 128)
self.fc3 = nn.Linear(128, 64)
self.fc4 = nn.Linear(64, 10)
self.dropout = nn.Dropout(p=0.5)
def forward(self, x):
x = x.view(x.size(0), -1)
x = self.dropout(F.relu(self.fc1(x)))
x = self.dropout(F.relu(self.fc2(x)))
x = self.dropout(F.relu(self.fc3(x)))
x = self.fc4(x)
return xWe also have a dropout layer because we want to avoid our model from over-fitting. Next, we need to implement our network’s forward() method which defines the way our output is being computed and then, finally, we’ll be ready to train our model. The forward()method implementation will use all of the layers we defined inside the constructor. In this way, this method defines the network’s transformation.
Most of the time when experimenting with more complex models it is advised-able to print out the tensor values for easier debugging. We also send our model to be trained on our GPU. It will be set to CPU if there is no GPU available.
Now, let’s initialize the network and define the optimizer.
model = Network()
model.to(device)Output:
Network(
(fc1): Linear(in_features=784, out_features=256, bias=True)
(fc2): Linear(in_features=256, out_features=128, bias=True) (fc3): Linear(in_features=128, out_features=64, bias=True) (fc4): Linear(in_features=64, out_features=10, bias=True) (dropout): Dropout(p=0.5, inplace=False) )
optimizer = optim.SGD(model.parameters(), lr=0.01)
criterion = nn.CrossEntropyLoss()After the forward pass, a loss function is calculated from the target output and the prediction labels in order to update weights for the best model selection in the further step. Setting up the loss function is a fairly simple step in PyTorch. Here, we will use the Cross–entropy loss, or log loss, which measures the performance of a classification model whose output is a probability value between 0 and 1. We should note that the Cross–entropy loss increases as the predicted probability diverges from the actual label.
Next, we will use the Stochastic Gradient Descent optimizer for the update of hyper-parameter. The function model.parameters() will provide the learnable parameters to the optimizer. lr represents a parameter of the SGD algorithm. We are setting its value to 0.003 which will define the learning rates for the parameter updates.
4. Training and evaluating the Model
Now comes the interesting part, the training. We will be iterating 50 times or 50 epochs and gather information about the training and validation loss, as well as the training and validation accuracy. We initialize our model training with the model.train() function. Iterating over every training image we make predictions and based on those predictions we can calculate our loss by passing the predicted label and true label into the loss function. After we have our loss we will do the back propagation and update our weights.
In order to calculate the accuracy our model has in every epoch we need to pass those predictions into a softmax function which will return us a probability. We compare this probability to the true label and see if our model got it correct. After doing this for all of our training images we can calculate the accuracy by dividing the total number of correctly classified images with the number of images in our training dataset.
After training we will evaluate our dataset, to check how our model is doing. Enter the evaluation mode by using the model.eval() function. This will tell our model that now we are evaluating and it will not calculate the gradients. We do the same thing as in the training step except the back propagation. Also we calculate the total accuracy and loss for the testing which will be compared as we progress in the epochs.
epochs = 20
train_loss, val_loss = [], []
accuracy_total_train, accuracy_total_val = [], []
for epoch in range(epochs):
total_train_loss = 0
total_val_loss = 0
model.train()
total = 0
# training our model
for idx, (image, label) in enumerate(trainLoader):
image, label = image.to(device), label.to(device)
optimizer.zero_grad()
pred = model(image)
loss = criterion(pred, label)
total_train_loss += loss.item()
loss.backward()
optimizer.step()
pred = torch.nn.functional.softmax(pred, dim=1)
for i, p in enumerate(pred):
if label[i] == torch.max(p.data, 0)[1]:
total = total + 1
accuracy_train = total / len(train_set)
accuracy_total_train.append(accuracy_train)
total_train_loss = total_train_loss / (idx + 1)
train_loss.append(total_train_loss)
# validating our model
model.eval()
total = 0
for idx, (image, label) in enumerate(validationLoader):
image, label = image.cuda(), label.cuda()
pred = model(image)
loss = criterion(pred, label)
total_val_loss += loss.item()
pred = torch.nn.functional.softmax(pred, dim=1)
for i, p in enumerate(pred):
if label[i] == torch.max(p.data, 0)[1]:
total = total + 1
accuracy_val = total / len(validation_set)
accuracy_total_val.append(accuracy_val)
total_val_loss = total_val_loss / (idx + 1)
val_loss.append(total_val_loss)
if epoch % 5 == 0:
print("Epoch: {}/{} ".format(epoch, epochs),
"Training loss: {:.4f} ".format(total_train_loss),
"Testing loss: {:.4f} ".format(total_val_loss),
"Train accuracy: {:.4f} ".format(accuracy_train),
"Test accuracy: {:.4f} ".format(accuracy_val))Output: Epoch: 0/20 Training loss: 1.8014 Testing loss: 0.7879 Train accuracy: 0.3595 Test accuracy: 0.7762 Epoch: 5/20 Training loss: 0.3816 Testing loss: 0.1970 Train accuracy: 0.8952 Test accuracy: 0.9431 Epoch: 10/20 Training loss: 0.2633 Testing loss: 0.1367 Train accuracy: 0.9302 Test accuracy: 0.9619 Epoch: 15/20 Training loss: 0.2036 Testing loss: 0.1108 Train accuracy: 0.9465 Test accuracy: 0.9673
After the forward pass and the loss, computation is done, we do a backward pass, which refers to the process of learning and updating the weights. We first need to set our gradient to zero: optimizer.zero_grad(). This is because every time a variable is backpropagated through the network multiple times, the gradient will be accumulated instead of being replaced from the previous training step in our current training step. This will prevent our network from learning properly. Then we run a backward pass by loss.backward() and optimizer.step() which updates our parameters based on the current gradient.
Let’s plot our loss and accuracies and see if they are falling or growing.
plt.plot(train_losses, label='Training loss')
plt.plot(test_losses, label='Test loss')
plt.legend()
plt.grid()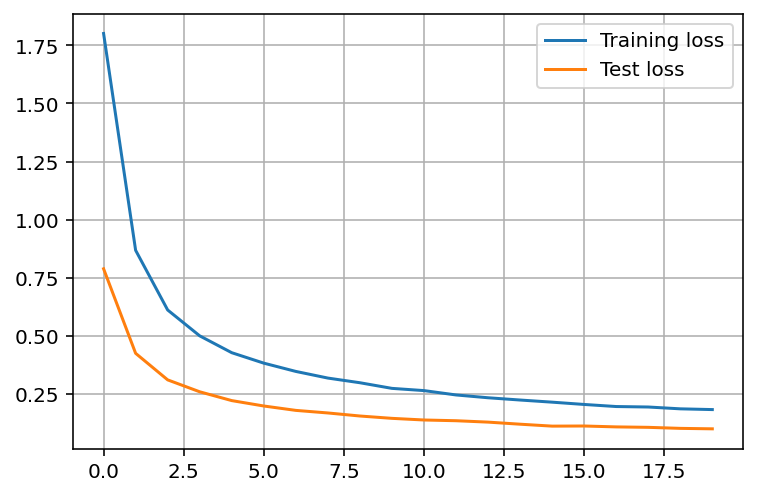
Our loss is slowly falling which is what we were looking for. Now let’s plot our accuracy.
plt.plot(accuracy_total_train, label='Training Accuracy')
plt.plot(accuracy_total_val, label='Test Accuracy')
plt.legend()
plt.grid()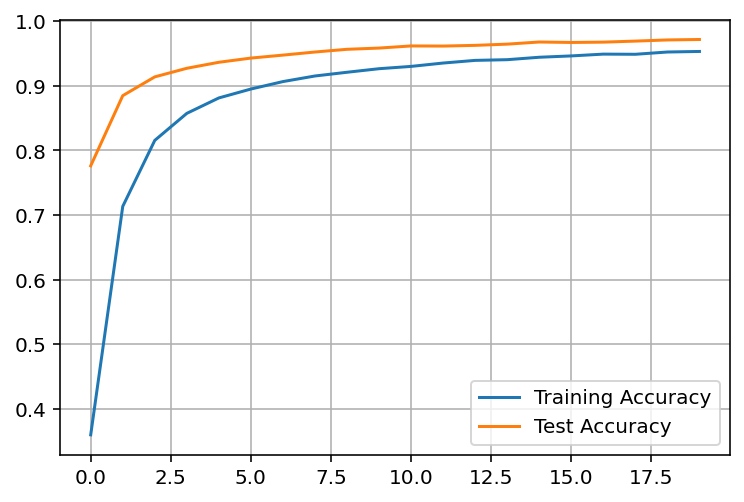
5. Evaluating the Network
Now that our model is trained, we can simply use the trained weights to make some new predictions by turning off the gradients. What our model returns to us are logits which are the models predictions. These logits represent a raw prediction of how much our neural network thinks that an image corresponds to a certain class. In this example it will return 10 numbers, because we have 10 classes. These logits are used as an input for the softmax function.
img = images[2].view(1, 784)
print(img.shape)
# we are turning off the gradients
with torch.no_grad():
logits = model.forward(img)
print(logits)Output:
torch.Size([1, 784])
tensor([[-1.2976, -0.5235, 1.7497, 0.9577, -1.5759, 1.6601, -0.4905, -2.4208, 3.6535, -2.2122]], device='cuda:0')
By passing these logits through a softmax function we get probability values as our output. Let’s visualize this.
# We take the softmax for probabilities since our outputs are logits
probabilities = F.softmax(logits, dim=1).detach().cpu().numpy().squeeze()
print(probabilities)
fig, (ax1, ax2) = plt.subplots(figsize=(6,8), ncols=2)
ax1.imshow(img.view(1, 28, 28).detach().cpu().numpy().squeeze(), cmap='inferno')
ax1.axis('off')
ax2.barh(np.arange(10), probabilities, color='r' )
ax2.set_aspect(0.1)
ax2.set_yticks(np.arange(10))
ax2.set_yticklabels(np.arange(10))
ax2.set_title('Class Probability')
ax2.set_xlim(0, 1.1)
plt.tight_layout()Output:
[0.00504854 0.01094837 0.10631441 0.04815479 0.00382203 0.0972028 0.01131562 0.001642 0.7135285 0.00202288]
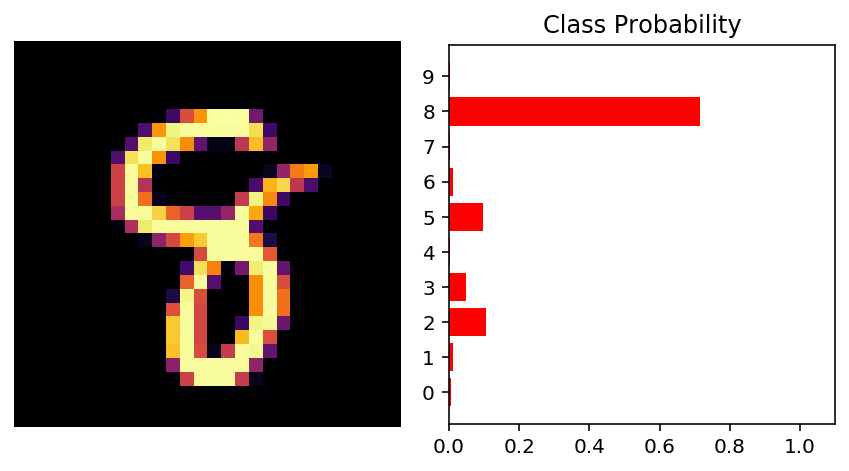
We can see the input image 8 matches the probability with the highest value in the probability class figure.
We are also going to see how many correct predictions our model made in one batch. We are going to take one batch as we did earlier with the iter() function and pass each image from that batch through our model, remember we need to turn off the auto gradient calculation with no_grad(). Then we are transforming our image into numpy arrays and turning off the GPU support with .cpu().
images, labels = next(iter(validation loader))
with torch.no_grad():
images, labels = images.to(device), labels.to(device)
preds = model(images)
images_np = [i.mean(dim=0).cpu().numpy() for i in images]
class_names = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]Let’s plot our images and the predictions our model made. If it got the number correct we will place blue colors and if not red.
fig = plt.figure(figsize=(10, 8))
fig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.5, wspace=0.05)
for i in range(64):
ax = fig.add_subplot(8, 8, i + 1, xticks=[], yticks=[])
ax.imshow(images_np[i], cmap='gray', interpolation='nearest')
color = "blue" if labels[i] == torch.max(preds[i], 0)[1] else "red"
plt.title(class_names[torch.max(preds[i], 0)[1]], color=color, fontsize=15)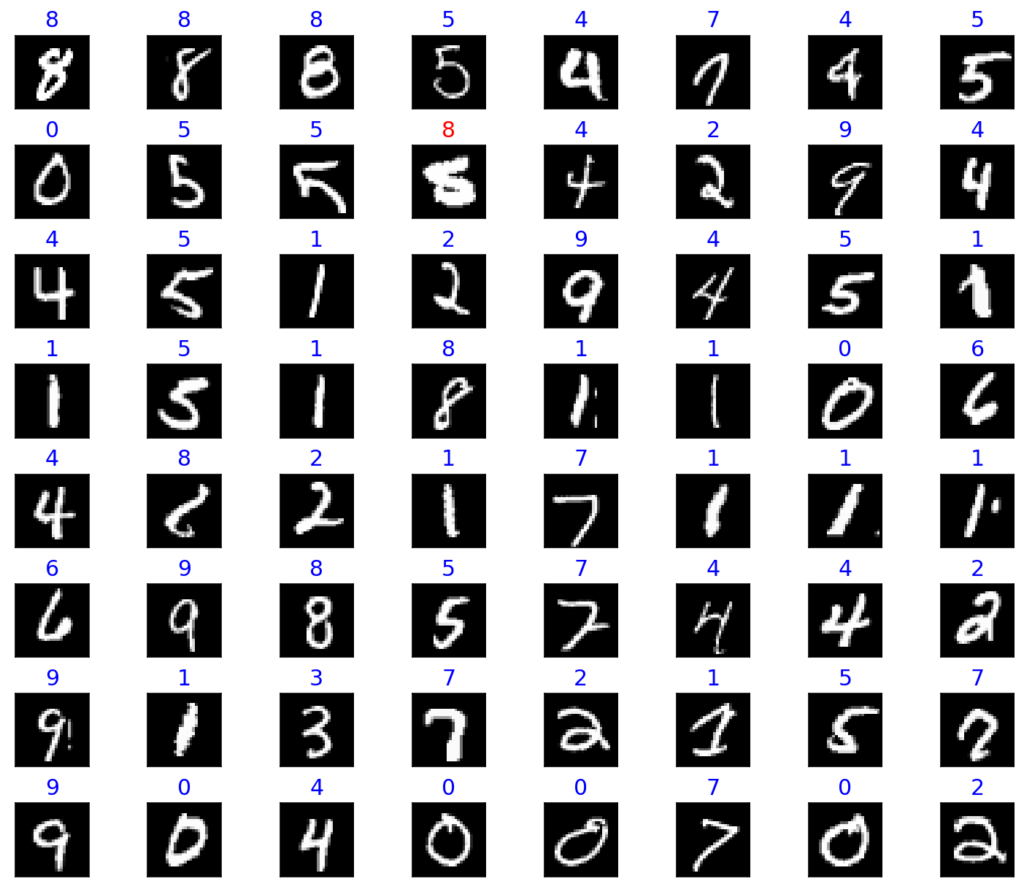
We can see that only 1 out of the 64 images was classified incorrectly, those are great results.
Summary
To sum it up, the training pass consists of four different steps. Which are:
- First, make a forward pass through the network.
- Use the network output to calculate the loss.
- Perform a backward pass through the network with loss.backwards() and this calculates the gradients.
- Then we make a step with our optimizer which updates the weights.
Now we have learned how to train our model to make accurate predictions for the digit dataset. In the next tutorial instead of only having linear layers on when defining our network, we will add some convolutional layers since convolutional neural networks tend to work well with images.
We also provide an interactive Colab notebook which can be found here ![]() Run in Google Colab
Run in Google Colab