#014 PyTorch – Convolutional Neural Network on MNIST in PyTorch
Highlights: Hello everyone and welcome back. In the last posts we have seen some basic operations on what tensors are, and how to build a Shallow Neural Network. In this post we will demonstrate how to build efficient Convolutional Neural Networks using the nn module In Pytorch. You will find that it is simpler and more powerful. To demonstrate how it works, we will be using a dataset called MNIST.

Tutorial Overview:
- Setting up the Environment
- Load MNIST Dataset from TorchVision.
- Defining Neural Network.
- Training Neural Network.
- Evaluating the Network.
The MNIST is a bunch of gray-scale handwritten digits with outputs that are ranging from 0, 1, 2, 3 and so on through 9. Each of these images is 28 by 28 pixels in size and the goal is to identify what the number is in these images.
Having a detailed look at the documentation, each of the images is labeled with the digit that’s in that image. To access this dataset we will use the Torchvision package which came along when we were installing PyTorch. This library provides us with datasets, and models for tackling computer vision problems.
Do you know that 25 years ago MNIST was the hardest problem in Computer Vision at the time? 🙂 check out this amazing video of Yann LeCun .
1. Setting up the Environment
Let’s import it and use it here. Once that is complete we now define a variable device and in it contains a control flow statement which return GPU if available. Otherwise, it uses CPU. This will be crucial in the later steps to decide if we are going to train our network using GPU or CPU.
import numpy as np
from matplotlib import pyplot as plt
from torchvision import datasets, transforms
import torch
from torch import nn
from torch import optim
import torch.nn.functional as F
#import helper
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
# moves your model to train on your gpu if available else it uses your cpu
device = ("cuda" if torch.cuda.is_available() else "cpu")2. Load MNIST Dataset from TorchVision
# Define transform to normalize data
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))
])
# Download and load the training data
train_set = datasets.MNIST('DATA_MNIST/', download=True, train=True, transform=transform)
trainLoader = torch.utils.data.DataLoader(train_set, batch_size=64, shuffle=True)
validation_set = datasets.MNIST('DATA_MNIST/', download=True, train=False, transform=transform)
validationLoader = torch.utils.data.DataLoader(validation_set, batch_size=64, shuffle=True)Once this cell is executed, our dataset is downloaded and stored in the variable train_set and test_set. In order to load the MNIST dataset in a handy way, we will need DataLoaders for the dataset. We will use a batch_size of 64 for the training.
The values 0.1307 and 0.3081 used for transforms.Normalize() transformation represents the global mean and standard deviation of the MNIST dataset and transforms.ToTensor() converts the entire array into torch tensor and divides by 255. So values are between 0.0f and 1.0f.
TorchVision offers a lot of handy transformations, such as cropping e.t.c
training_data = enumerate(trainloader)
batch_idx, (images, labels) = next(training_data)
print(type(images)) # Checking the datatype
print(images.shape) # the size of the image
print(labels.shape) # the size of the labelsOutput:
<class 'torch.Tensor'>
torch.Size([64, 1, 28, 28])
torch.Size([64])
Now, let’s turn our trainloader object into an iterator with iter so we may access our images and labels from this generator. We can see the shape as \(64 \times 1 \times 28 \times 28 \). This means:
- 64: Represents 64 images
- 1 : One color channel ==>> Grayscale
- 28 by 28 pixel: the shape of these images so we can visualize it.
By visualizing we can see our images have nicely drawn numbers.
fig = plt.figure()
for i in range(4):
plt.subplot(2,2,i+1)
plt.tight_layout()
plt.imshow(images[i][0], cmap='inferno')
plt.title("Ground Truth Label: {}".format(labels[i]))
plt.yticks([])
plt.xticks([])
3. Building the Network
Now let’s build our network using this object-oriented class method within nn.module. We will use 2 fully convolutional layers, Relu activation function and MaxPooling. This will also be coupled along with 2 linear layers with a dropout probability of 0.2 per cent.
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
# Convolutional Neural Network Layer
self.convolutaional_neural_network_layers = nn.Sequential(
# Here we are defining our 2D convolutional layers
# We can calculate the output size of each convolutional layer using the following formular
# outputOfEachConvLayer = [(in_channel + 2*padding - kernel_size) / stride] + 1
# We have in_channels=1 because our input is a grayscale image
nn.Conv2d(in_channels=1, out_channels=12, kernel_size=3, padding=1, stride=1), # (N, 1, 28, 28)
nn.ReLU(),
# After the first convolutional layer the output of this layer is:
# [(28 + 2*1 - 3)/1] + 1 = 28.
nn.MaxPool2d(kernel_size=2),
# Since we applied maxpooling with kernel_size=2 we have to divide by 2, so we get
# 28 / 2 = 14
# output of our second conv layer
nn.Conv2d(in_channels=12, out_channels=24, kernel_size=3, padding=1, stride=1),
nn.ReLU(),
# After the second convolutional layer the output of this layer is:
# [(14 + 2*1 - 3)/1] + 1 = 14.
nn.MaxPool2d(kernel_size=2)
# Since we applied maxpooling with kernel_size=2 we have to divide by 2, so we get
# 14 / 2 = 7
)
# Linear layer
self.linear_layers = nn.Sequential(
# We have the output_channel=24 of our second conv layer, and 7*7 is derived by the formular
# which is the output of each convolutional layer
nn.Linear(in_features=24*7*7, out_features=64),
nn.ReLU(),
nn.Dropout(p=0.2), # Dropout with probability of 0.2 to avoid overfitting
nn.Linear(in_features=64, out_features=10) # The output is 10 which should match the size of our class
)
# Defining the forward pass
def forward(self, x):
x = self.convolutaional_neural_network_layers(x)
# After we get the output of our convolutional layer we must flatten it or rearrange the output into a vector
x = x.view(x.size(0), -1)
# Then pass it through the linear layer
x = self.linear_layers(x)
return xThe forward() pass defines the way our output is being computed. The line x.view(x.size(0), -1) flattens the output from the convolution layer into a vector. Most of the time when experimenting with more complex models it is advised-able to print out the tensor values for easier debugging.
Now by initializing our network the term model.to(device) sends the network we created into Cuda. Note: This only happens if you have a GPU. This helps to decrease the time it takes our network to train, then we define the optimizers we will use.
model = Network()
model.to(device)Output:
Network( (convolutaional_neural_network_layers): Sequential( (0): Conv2d(1, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(12, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): ReLU()
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) )
(linear_layers): Sequential(
(0): Linear(in_features=1176, out_features=64, bias=True) (1): ReLU()
(2): Dropout(p=0.2, inplace=False)
(3): Linear(in_features=64, out_features=10, bias=True) ) )
optimizer = optim.SGD(model.parameters(), lr=0.01)
criterion = nn.CrossEntropyLoss()After the forward pass, a loss function is calculated from the target output and the prediction labels in order to update weights for the best model selection in the further step. Setting up the loss function is a fairly simple step in PyTorch. Here, we will use the Cross–entropy loss, or log loss, which measures the performance of a classification model whose output is a probability value between 0 and 1. We should note that the Cross–entropy loss increases as the predicted probability diverges from the actual label.
Next, we will use Stochastic Gradient Descent optimizer for the update of hyper-parameters model.parameters() will provide the learnable parameters to the optimizer and lr=0.01 defines the learning rates for the parameter updates.
4. Training and Testing the Model
Our model is now ready to train. We begin by setting up an epoch size. Epoch is a single pass through the whole training dataset. In the example below, the epoch size is set to 10, meaning there will be 10 single passes of the training and weight updates.
epochs = 20
train_loss, val_loss = [], []
accuracy_total_train, accuracy_total_val = [], []
for epoch in range(epochs):
total_train_loss = 0
total_val_loss = 0
model.train()
total = 0
# training our model
for idx, (image, label) in enumerate(trainLoader):
image, label = image.to(device), label.to(device)
optimizer.zero_grad()
pred = model(image)
loss = criterion(pred, label)
total_train_loss += loss.item()
loss.backward()
optimizer.step()
pred = torch.nn.functional.softmax(pred, dim=1)
for i, p in enumerate(pred):
if label[i] == torch.max(p.data, 0)[1]:
total = total + 1
accuracy_train = total / len(train_set)
accuracy_total_train.append(accuracy_train)
total_train_loss = total_train_loss / (idx + 1)
train_loss.append(total_train_loss)
# validating our model
model.eval()
total = 0
for idx, (image, label) in enumerate(validationLoader):
image, label = image.cuda(), label.cuda()
pred = model(image)
loss = criterion(pred, label)
total_val_loss += loss.item()
pred = torch.nn.functional.softmax(pred, dim=1)
for i, p in enumerate(pred):
if label[i] == torch.max(p.data, 0)[1]:
total = total + 1
accuracy_val = total / len(validation_set)
accuracy_total_val.append(accuracy_val)
total_val_loss = total_val_loss / (idx + 1)
val_loss.append(total_val_loss)
if epoch % 5 == 0:
print("Epoch: {}/{} ".format(epoch, epochs),
"Training loss: {:.4f} ".format(total_train_loss),
"Testing loss: {:.4f} ".format(total_val_loss),
"Train accuracy: {:.4f} ".format(accuracy_train),
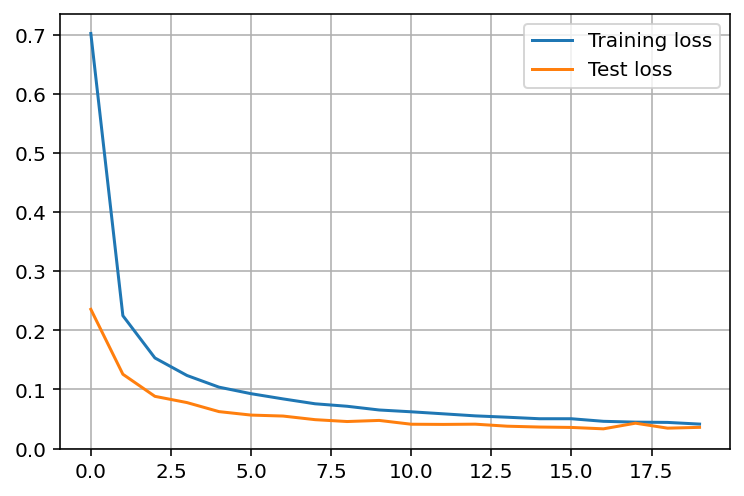
"Test accuracy: {:.4f} ".format(accuracy_val))Output: Epoch: 0/20 Training loss: 0.7024 Testing loss: 0.2356 Train accuracy: 0.7891 Test accuracy: 0.9298 Epoch: 5/20 Training loss: 0.0928 Testing loss: 0.0566 Train accuracy: 0.9715 Test accuracy: 0.9815 Epoch: 10/20 Training loss: 0.0621 Testing loss: 0.0411 Train accuracy: 0.9806 Test accuracy: 0.9866 Epoch: 15/20 Training loss: 0.0504 Testing loss: 0.0357 Train accuracy: 0.9846 Test accuracy: 0.9878
After the forward pass and the loss, computation is done, we do a backward pass, which refers to the process of learning and updating the weights. We first need to set our gradient to zero: optimizer.zero_grad(). This is because every time a variable is backpropagated through the network multiple times, the gradient will be accumulated instead of being replaced from the previous training step in our current training step. Which will prevent our network from learning properly. Then we run a backward pass by loss.backward() and optimizer.step() which updates our parameters based on the current gradient.
By training our network we may also test our model to see how it’s performing after each epoch. The most crucial method is to set model.eval() when you want to test your network to avoid updating the gradient during testing and when you want to start training, set model.train(), so your weights may be updated.
plt.plot(train_losses, label='Training loss')
plt.plot(test_losses, label='Test loss')
plt.legend()
plt.grid()Output:
Let’s check our training and validation accuracy. It is as simple as the code for plotting the loss.
plt.plot(accuracy_total_train, label='Training Accuracy')
plt.plot(accuracy_total_val, label='Test Accuracy')
plt.legend()
plt.grid()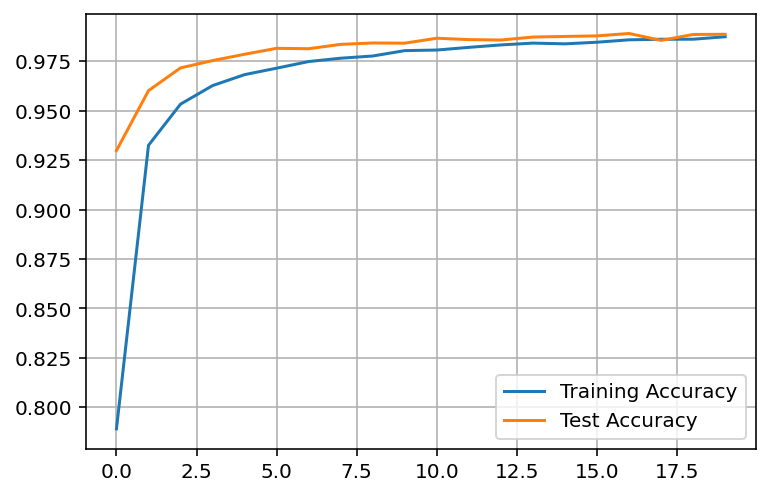
5. Evaluating the Network
Now that our model is trained, we can simply use the already pre-trained weights to make some new predictions by turning off the gradients. What our model returns to us are logits.
img = images[0]
img = img.to(device)
img = img.view(-1, 1, 28, 28)
print(img.shape)
# Since we want to use the already pretrained weights to make some prediction
# we are turning off the gradients
with torch.no_grad():
logits = model.forward(img)Output:
torch.Size([1, 1, 28, 28])
And by passing these logits through a softmax function we get probabilities values as our output. Let’s visualize this.
#We take the softmax for probabilites since our outputs are logits
probabilities = F.softmax(logits, dim=1).detach().cpu().numpy().squeeze()
print(probabilities)
fig, (ax1, ax2) = plt.subplots(figsize=(6,8), ncols=2)
ax1.imshow(img.view(1, 28, 28).detach().cpu().numpy().squeeze(), cmap='inferno')
ax1.axis('off')
ax2.barh(np.arange(10), probabilities, color='r' )
ax2.set_aspect(0.1)
ax2.set_yticks(np.arange(10))
ax2.set_yticklabels(np.arange(10))
ax2.set_title('Class Probability')
ax2.set_xlim(0, 1.1)
plt.tight_layout()Output:
[2.6115208e-09 2.8908722e-05 9.9405080e-01 3.0997768e-03 1.1587220e-10 9.2143854e-10 1.5127113e-11 4.3580212e-06 2.8162000e-03 2.7719542e-09]

We can see the input image 2 matches the probability with the highest value in the probability class figure.
Summary
To sum it up, the training pass consists of four different steps. Which are:
- First, make a forward pass through the network.
- Use the network output to calculate the loss.
- Perform a backward pass through the network with loss.backwards() and this calculates the gradients.
- Then we make a step with our optimizer which updates the weights.
Now we have learned how to train and test our model to make accurate predictions for the digit dataset. In the next tutorial we will experiment more on different datasets.
Download Code
You can download code from our GitHub repo