#008 CNN An Example of A Convolutional Neural Network
A simple Convolutional Neural Network – A ConvNet
In the last post we saw the building blocks of a single convolutional layer in a \(ConvNet \). Now let’s go through a concrete example of a simple convolutional neural network. Let’s say we have an image and we want to do an image classification or image recognition. We want to take an image \(X \) as input and decide if this is a cat or not a cat.
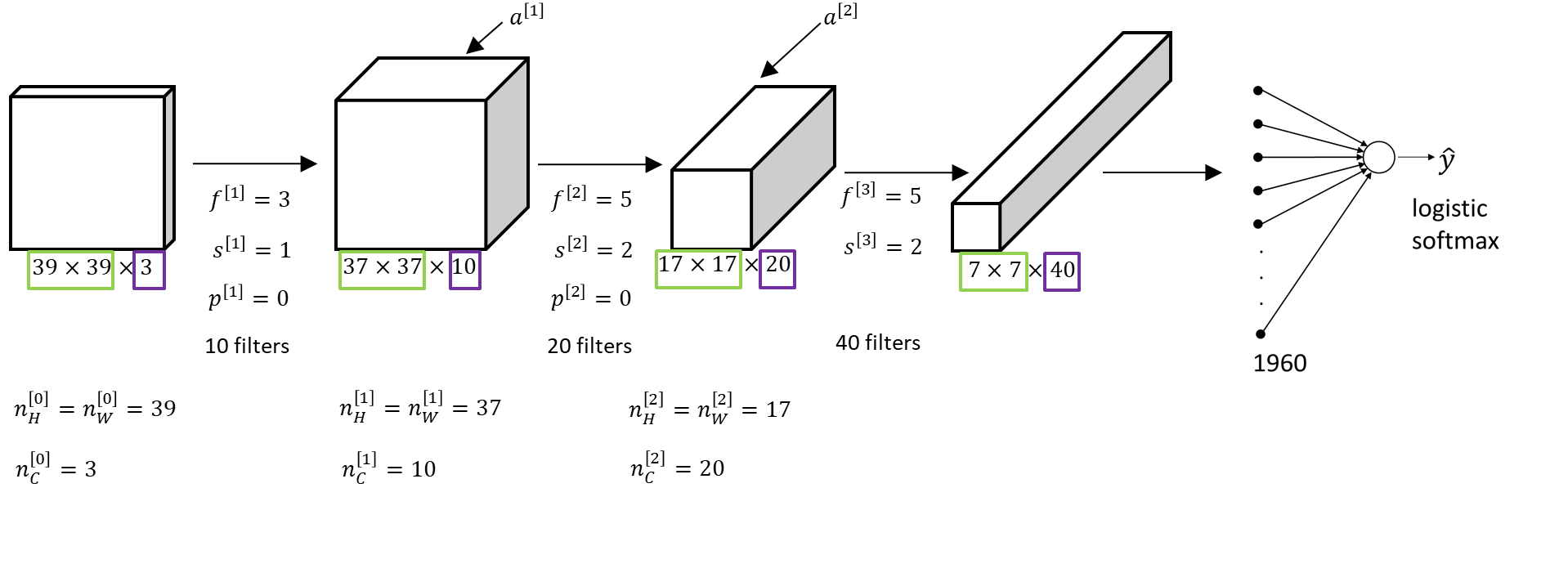
Let’s build an example of a \(ConvNet \) we could use. For this example, we’re going to use a fairly small image. Let’s say this image is \(39 \times 39 \times 3 \). So, \(n_{H}^{\left [ 0 \right ]}=n_{W}^{\left [ 0 \right ]}=39 \), and \(n_{C}^{\left [ 0 \right ]}=3 \) ( H – height, W – weight, C – channel).
Next, the first layer uses a set of \(3 \times 3 \) filters to detect features, so \(f^{\left [ 1 \right ]}=3 \) because we’re using \(3 \times 3 \) filters. Let’s say we’re using a stride of \(1 \). We are also using a \(valid \) convolution. Let’s say we have \(10 \) filters, and they will produce \(10 \) channels in the output volume.
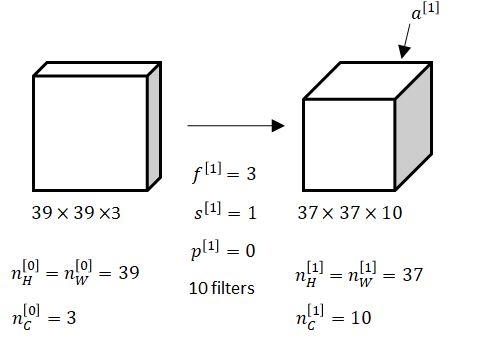
One layer of convolution using \(3 \times 3 \) with a stride of \(1 \) and no padding
The activations in this next layer of the neural network will be \(37 \times 37 \times 10 \). This \(10\) comes from the fact that we use \(10 \) filters and \(37 \) comes from this formula \((n+2p-f)/s+1 \). Then, we have a \((39+0-3)/1+1 = 37 \). That’s why the output is \(37 \times 37\), it’s a valid convolution and that’s the output size. In our notation we would have \(n_{H}^{\left [ 1 \right ]}=n_{W}^{\left [ 1 \right ]}=37 \), and \(n_{C}^{\left [ 1 \right ]}=10 \), is also equal to the number of filters from the first layer. So, this becomes the dimension of the activation at the first layer.
Let’s now say we have another convolutional layer, and we use \(5 \times 5 \) filters. So, in our notation \(f^{\left [ 2 \right ]} \) at the next layer of network is equal to \(5 \enspace (f^{ [ 2 ]}=5) \), and let’s say we use the stride of \( 2 , \enspace s^{ [2]}=2) \), and no padding \((p^{[ 2 ]}=0) \) and \(20 \) filters.
An example of a convolution
Then the output of this will be another volume, this time, it will be \(17 \times 17 \times 20 \). Notice that because we’re now using a stride of \(2\), so \((s^{\left [ 2 \right ]}=2) \) the dimension has shrunk much faster and \(37 \times 37\) has gone down in size by slightly more than \(2 \), to \(17 \times 17 \). Because we’re using \(20 \) filters, the number of channels is now \(20 \), so this activation \(a^{\left [ 2 \right ]} \) would be that dimension. And \(n_{H}^{\left [ 2 \right ]}=n_{W}^{\left [ 2 \right ]}=17 \) and \(n_{C}^{\left [ 2 \right ]}=20 \).
Let’s apply one last convolutional layer. Let’s say that we use a \(5 \times 5 \) filter again and, again a stride of 2. Eventually we end up with a \(7 \times 7 \). Finally, aif we use \(40 \) filters and no padding we end up with \(7 \times 7 \times 40 \).
Now our \(39 \times 39 \times 3 \) input image is processed and \(7 \times 7 \times 40 \) features are computed for this image. Finally, if we take the \(7 \times 7 \times 40 (=1960) \), and we flatten this volume or unroll it into \(1960\) units. By unrolling them into a very long vector we can feed into a \( softmax \) or into a logistic regression in order to make a prediction for the final output.
This would be a typical design of a \(ConvNet \). All of the work and designing a convolutional neural net is selecting its \(hyperparameters \): deciding what’s the filter size, what’s the stride, what’s the padding and how many filters to use. We will give some suggestions later and some guidelines for how to make these choices. At the moment, one thing to take away from this is that as we go deeper in the neural network, typically we start off with larger images \(39\times 39 \), and then the height and width will stay the same for a while and gradually trend down as we go deeper in the neural network. That is, the size has gone from \(39 \) to \(37 \) to \(17 \) to \(7 \) , whereas the number of channels generally increases (from \(3 \) to \(10 \) to \(20 \) to \(40 \)). We can see this general trend in a lot of other convolutional neural networks as well.
We’ll give more guidelines about how to design these parameters in the next posts, but we’ve now seen our first example of a convolutional neural network or \(ConvNet \) for short, so congratulations for that!
And it turns out that in a typical \(ConvNet \) there are usually three types of layers: one is the convolutional layer and often we’ll denote that as a \(ConvNet \). It turns out that there are two other common types of layers that you haven’t seen yet, but we’ll talk about them in our next posts. One is called a \(Pooling \enspace layer \), from now on called \(Pool \), and then the last is a \(Fully\enspace connected \enspace layer \), called \(FC \). Although it’s possible to design a pretty good neural network using just convolutional layers, most neural network architectures will also have a few pooling layers and a few fully connected layers. Fortunately, pooling layers and fully connected layers are a bit simpler than convolutional layers to define.
There are three types of layers in a convolutional network:
- \(Convolution \enspace (conv) \)
- \(Pooling \enspace (pool) \)
- \(Fully \enspace connected \enspace (FC) \)
In the next post we will explain in details how these layers work.