Top 10 GitHub Papers :: Image generation

Image generation is the process of generating new images from an existing dataset. For example, DeepFake which are artificial media in which a person in an existing image or video is replaced with someone else’s likeness.
They are different types of generations which are Unconditional generation and Conditional generation. Unconditional generation means the generated image doesn’t depend on the dataset i.e p(y). While Conditional generation means generating images based on the dataset i.e p(y|x)p(y|x).
In this section, you can find state-of-the-art, greatest papers for image generation along with the authors’ names, link to the paper, Github link & stars, number of citations, dataset used and date published. Enjoy.
1. Density estimation using Real NVP

Abstract: Unsupervised learning of probabilistic models is a central yet challenging problem in machine learning. Specifically, designing models with tractable learning, sampling, inference and evaluation is crucial in solving this task. We extend the space of such models using real-valued non-volume preserving (real NVP) transformations, a set of powerful invertible and learnable transformations, resulting in an unsupervised learning algorithm with exact log-likelihood computation, exact sampling, exact inference of latent variables, and an interpretable latent space. We demonstrate its ability to model natural images on four datasets through sampling, log-likelihood evaluation and latent variable manipulations.
- Authors: Laurent Dinh • Jascha Sohl-Dickstein • Samy Bengio
- Paper: https://arxiv.org/pdf/1605.08803v3.pdf
- Github: https://github.com/tensorflow/models/tree/master/research/real_nvp
- Dataset: ImageNet, CIFAR-10, Large-Scale Scene Understanding (LSUN), CelebFaces Attributes (CelabA)
- Github ⭐: 61,909 and the stars were counted on 27/02/2020
- Citations: Cited by 560
- Published: 27 May 2016
2. InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets

Abstract: This paper describes InfoGAN, an information-theoretic extension to the Generative Adversarial Network that is able to learn disentangled representations in a completely unsupervised manner. InfoGAN is a generative adversarial network that also maximizes the mutual information between a small subset of the latent variables and the observation. We derive a lower bound to the mutual information objective that can be optimized efficiently, and show that our training procedure can be interpreted as a variation of the Wake-Sleep algorithm. Specifically, InfoGAN successfully disentangles writing styles from digit shapes on the MNIST dataset, pose from lighting of 3D rendered images, and background digits from the central digit on the SVHN dataset. It also discovers visual concepts that include hair styles, presence/absence of eyeglasses, and emotions on the CelebA face dataset. Experiments show that InfoGAN learns interpretable representations that are competitive with representations learned by existing fully supervised methods.
- Authors: • Xi Chen • Yan Duan • Rein Houthooft • John Schulman • Ilya Sutskever • Pieter Abbeel
- Paper: https://arxiv.org/pdf/1606.03657v1.pdf
- Github: https://github.com/eriklindernoren/Keras-GAN
- Dataset: MNIST, FashionMNIST, SVHN, CelebA
- Github ⭐: 61,887 and the stars were counted on 27/02/2020
- Citations: Cited by 1643
- Published: 12 June 2016
3. Improved Techniques for Training GANs

Abstract: We present a variety of new architectural features and training procedures that we apply to the generative adversarial networks (GANs) framework. We focus on two applications of GANs: semi-supervised learning, and the generation of images that humans find visually realistic. Unlike most work on generative models, our primary goal is not to train a model that assigns high likelihood to test data, nor do we require the model to be able to learn well without using any labels. Using our new techniques, we achieve state-of-the-art results in semi-supervised classification on MNIST, CIFAR-10 and SVHN. The generated images are of high quality as confirmed by a visual Turing test: our model generates MNIST samples that humans cannot distinguish from real data, and CIFAR-10 samples that yield a human error rate of 21.3%. We also present ImageNet samples with unprecedented resolution and show that our methods enable the model to learn recognizable features of ImageNet classes.
- Authors: Tim Salimans • Ian Goodfellow • Wojciech Zaremba • Vicki Cheung • Alec Radford • Xi Chen
- Paper: https://arxiv.org/pdf/1606.03498v1.pdf
- Github: https://github.com/carpedm20/DCGAN-tensorflow
- Dataset: MNIST, CIFAR-10, SVHN, ImageNet
- Github ⭐: 6434 and the stars were counted on 27/02/2020
- Citations: Cited by 3007
- Published: 10 June 2016
4. Self-Attention Generative Adversarial Networks
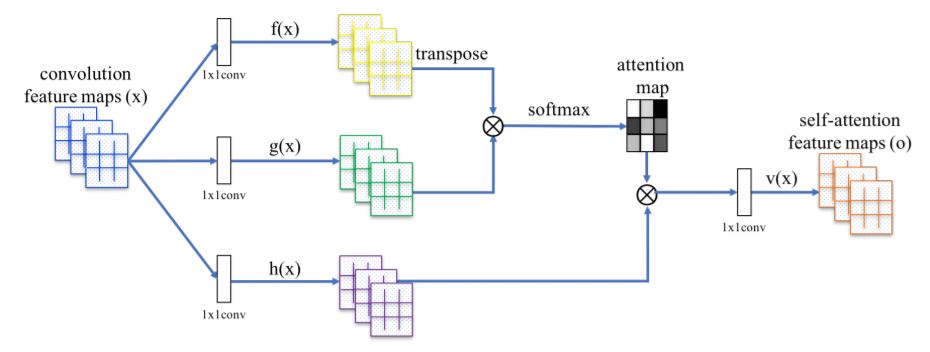
Abstract: In this paper, we propose the Self-Attention Generative Adversarial Network (SAGAN) which allows attention-driven, long-range dependency modeling for image generation tasks. Traditional convolutional GANs generate high-resolution details as a function of only spatially local points in lower-resolution feature maps. In SAGAN, details can be generated using cues from all feature locations. Moreover, the discriminator can check that highly detailed features in distant portions of the image are consistent with each other. Furthermore, recent work has shown that generator conditioning affects GAN performance. Leveraging this insight, we apply spectral normalization to the GAN generator and find that this improves training dynamics. The proposed SAGAN achieves the state-of-the-art results, boosting the best published Inception score from 36.8 to 52.52 and reducing Frechet Inception distance from 27.62 to 18.65 on the challenging ImageNet dataset. Visualization of the attention layers shows that the generator leverages neighborhoods that correspond to object shapes rather than local regions of fixed shape.
- Authors: Han Zhang • Ian Goodfellow • Dimitris Metaxas • Augustus Odena
- Paper: https://arxiv.org/pdf/1805.08318v2.pdf
- Github: https://github.com/brain-research/self-attention-gan
- Dataset: ImageNet
- Github ⭐: 9,252 and the stars were counted on 27/02/2020
- Citations: Cited by 558
- Published: 21 May 2018
5. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium
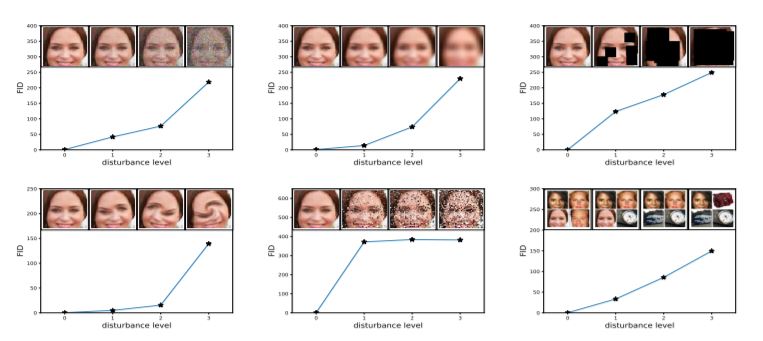
Abstract: Generative Adversarial Networks (GANs) excel at creating realistic images with complex models for which maximum likelihood is infeasible. However, the convergence of GAN training has still not been proved. We propose a two time-scale update rule (TTUR) for training GANs with stochastic gradient descent on arbitrary GAN loss functions. TTUR has an individual learning rate for both the discriminator and the generator. Using the theory of stochastic approximation, we prove that the TTUR converges under mild assumptions to a stationary local Nash equilibrium. The convergence carries over to the popular Adam optimization, for which we prove that it follows the dynamics of a heavy ball with friction and thus prefers flat minima in the objective landscape. For the evaluation of the performance of GANs at image generation, we introduce the “Fr\’echet Inception Distance” (FID) which captures the similarity of generated images to real ones better than the Inception Score. In experiments, TTUR improves learning for DCGANs and Improved Wasserstein GANs (WGAN-GP) outperforming conventional GAN training on CelebA, CIFAR-10, SVHN, LSUN Bedrooms, and the One Billion Word Benchmark.
- Authors: Martin Heusel • Hubert Ramsauer • Thomas Unterthiner • Bernhard Nessler • Sepp Hochreiter
- Paper: https://arxiv.org/pdf/1706.08500v6.pdf
- Github: https://github.com/jantic/DeOldify
- Dataset: MNIST, CIFAR-10, SVHN, ImageNet
- Github ⭐: 9252 and the stars were counted on 27/02/2020
- Citations: Cited by 1073
- Published: 26 June 2017
6. A Style-Based Generator Architecture for Generative Adversarial Networks

Abstract: We propose an alternative generator architecture for generative adversarial networks, borrowing from style transfer literature. The new architecture leads to an automatically learned, unsupervised separation of high-level attributes (e.g., pose and identity when trained on human faces) and stochastic variation in the generated images (e.g., freckles, hair), and it enables intuitive, scale-specific control of the synthesis. The new generator improves the state-of-the-art in terms of traditional distribution quality metrics, leads to demonstrably better interpolation properties, and also better disentangles the latent factors of variation. To quantify interpolation quality and disentanglement, we propose two new, automated methods that are applicable to any generator architecture. Finally, we introduce a new, highly varied and high-quality dataset of human faces.
- Authors: Tero Karras • Samuli Laine • Timo Aila
- Paper: https://arxiv.org/pdf/1812.04948v3.pdf
- Github: https://github.com/NVlabs/stylegan
- Dataset: FlickrFaces-HQ (FFHQ)
- Github ⭐: 8,988 and the stars were counted on 27/02/2020
- Citations: Cited by 520
- Published: 12 December 2018
7. Instance Normalization: The Missing Ingredient for Fast Stylization

Abstract: It this paper we revisit the fast stylization method introduced in Ulyanov et. al. (2016). We show how a small change in the stylization architecture results in a significant qualitative improvement in the generated images. The change is limited to swapping batch normalization with instance normalization, and to apply the latter both at training and testing times. The resulting method can be used to train high-performance architectures for real-time image generation.
- Authors: Dmitry Ulyanov • Andrea Vedaldi • Victor Lempitsky
- Paper: https://arxiv.org/pdf/1607.08022v3.pdf
- Github: https://github.com/lengstrom/fast-style-transfer
- Dataset: ImageNet, MS COCO
- Github ⭐: 8,737 and the stars were counted on 27/02/2020
- Citations: Cited by 656
- Published: 27 July 2016
8. Generating Diverse High-Fidelity Images with VQ-VAE-2
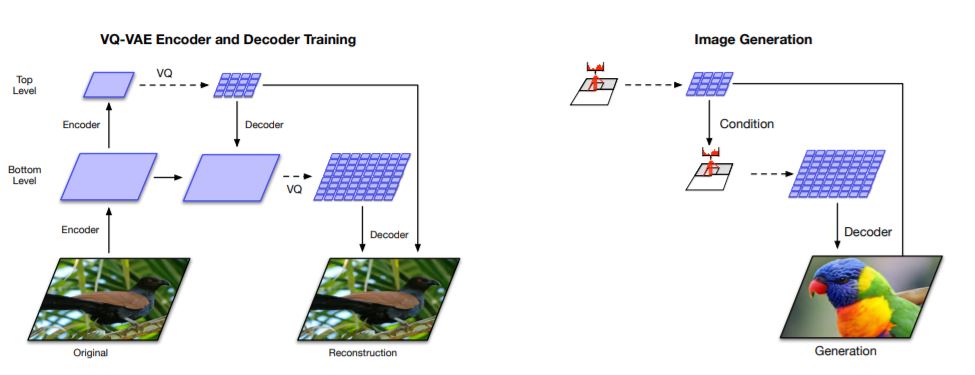
Abstract: We explore the use of Vector Quantized Variational AutoEncoder (VQ-VAE) models for large scale image generation. To this end, we scale and enhance the autoregressive priors used in VQ-VAE to generate synthetic samples of much higher coherence and fidelity than possible before. We use simple feed-forward encoder and decoder networks, making our model an attractive candidate for applications where the encoding and/or decoding speed is critical. Additionally, VQ-VAE requires sampling an autoregressive model only in the compressed latent space, which is an order of magnitude faster than sampling in the pixel space, especially for large images. We demonstrate that a multi-scale hierarchical organization of VQ-VAE, augmented with powerful priors over the latent codes, is able to generate samples with quality that rivals that of state of the art Generative Adversarial Networks on multifaceted datasets such as ImageNet, while not suffering from GAN’s known shortcomings such as mode collapse and lack of diversity.
- Authors: Ali Razavi • Aaron van den Oord • Oriol Vinyals
- Paper: https://arxiv.org/pdf/1906.00446v1.pdf
- Github: https://github.com/deepmind/sonnet
- Dataset: FlickrFaces-HQ (FFHQ)
- Github ⭐: 8,235 and the stars were counted on 27/02/2020
- Citations: Cited by 31
- Published: 2 June 2019
9. Improved Training of Wasserstein GANs

Abstract: Generative Adversarial Networks (GANs) are powerful generative models, but suffer from training instability. The recently proposed Wasserstein GAN (WGAN) makes progress toward stable training of GANs, but sometimes can still generate only low-quality samples or fail to converge. We find that these problems are often due to the use of weight clipping in WGAN to enforce a Lipschitz constraint on the critic, which can lead to undesired behavior. We propose an alternative to clipping weights: penalize the norm of gradient of the critic with respect to its input. Our proposed method performs better than standard WGAN and enables stable training of a wide variety of GAN architectures with almost no hyperparameter tuning, including 101-layer ResNets and language models over discrete data. We also achieve high quality generations on CIFAR-10 and LSUN bedrooms.
- Authors: Ishaan Gulrajani • Faruk Ahmed • Martin Arjovsky • Vincent Dumoulin • Aaron Courville
- Paper: https://arxiv.org/pdf/1704.00028v3.pdf
- Github: https://github.com/eriklindernoren/Keras-GAN
- Dataset: MNIST, CIFAR-10, LSUN bedrooms.
- Github ⭐: 6,569 and the stars were counted on 27/02/2020
- Citations: Cited by 2476
- Published: 31 March 2017
10. Wasserstein GAN
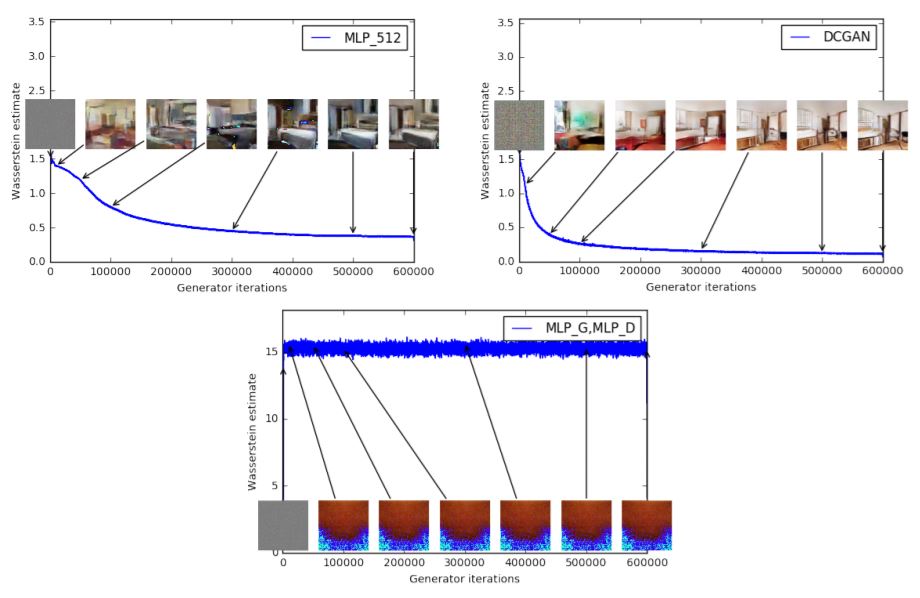
Abstract: We introduce a new algorithm named WGAN, an alternative to traditional GAN training. In this new model, we show that we can improve the stability of learning, get rid of problems like mode collapse, and provide meaningful learning curves useful for debugging and hyperparameter searches. Furthermore, we show that the corresponding optimization problem is sound, and provide extensive theoretical work highlighting the deep connections to other distances between distributions.
- Authors: Martin Arjovsky • Soumith Chintala • Léon Bottou
- Paper: https://arxiv.org/pdf/1701.07875v3.pdf
- Github: https://github.com/eriklindernoren/Keras-GAN
- Dataset: LSUN-Bedrooms
- Github ⭐: 6,569 and the stars were counted on 27/02/2020
- Citations: Cited by 3764
- Published: 26 July 2017