dH #020: Introduction to Retrieval Augmented Language Modeling
Highlight: Retrieval-augmented language modeling represents one of the most exciting frontiers in AI, combining the parametric knowledge of Large Language Models with the dynamic power of external knowledge retrieval. You’ll discover how groundbreaking systems like RETRO, RAG, and modern frameworks like RePlug are revolutionizing how AI accesses and utilizes information, moving beyond the limitations of static training data. Let’s begin!
Tutorial Overview:
- Introduction to Retrieval Augmented Language Modeling
- RETRO: Deep Dive into First Generation RALM
- Advanced RALM Approaches and Future Directions
1. Introduction to Retrieval Augmented Language Modeling
Overview
Hello and welcome back! In this post, we’re diving into retrieval-augmented language modeling – one of the most exciting areas in machine learning. This represents a fascinating intersection of two powerful approaches in natural language processing.
There’s a broad appreciation in the field that very large language models can effectively store world knowledge within their parameters. This knowledge storage capability emerges naturally because having access to world knowledge is tremendously useful for performing their primary objective, which is to predict the next word or to predict masked tokens during training. The models essentially learn to encode factual information as part of learning these prediction tasks.
This brings us to a compelling research question, “Can we make language models perform even better at answering queries about world knowledge by augmenting a large language model with a retrieval model?” The idea is to combine the parametric knowledge stored within the language model with the ability to dynamically retrieve relevant information from external knowledge sources, potentially giving us the best of both worlds. Let us explore why this combination might be particularly valuable.
Motivation for Retrieval Augmentation
Now, here’s the thing – there are several compelling reasons why augmenting a large language model with a retrieval model could be beneficial. First of all, large language models tend to hallucinate as the most probable next token isn’t necessarily the one that maximizes the truthfulness of the generated text. And this problem gets worse with model size.
You see this talked about a lot in the context of ChatGPT, where I asked ChatGPT what was the most influential paper on retrieval published in 2021, and ChatGPT gives me an answer that looks like it could be a paper on retrieval, but then if you go try to look it up, no such paper exists. It just predicted the most probable tokens in a language model sense, but it has no sense of whether this is true or not. This is really potentially a major problem for the trustworthiness of large language models.
Relatively speaking, people would like language models to cite sources. Well, that’s not what a language model does. It predicts the next token using all the 175 billion parameters that it learned through predicting the next token during training. But that is how retrieval works. You’ll see people ask, “why doesn’t ChatGPT give me its sources?” Well, it doesn’t have them, but if you augment it with retrieval, it would. It still might say something that is inconsistent with the source, but it would be more likely to be consistent with certain sources.
Pretty neat, right? Retrieval augmentation could allow a language model to use all of its capacity to learn language instead of using a bunch of its capacity to memorize facts. It could allow a smaller language model to more feasibly achieve the performance of a larger language model since the facts it needed would be stored in an offline database.
And it could allow the language model to incorporate new world knowledge at test time without requiring any additional training, which is important. Another complaint about large language models is that they were trained at a specific point in time and still think that Donald Trump is president or are outdated in various ways. So if you could have a language model connect with the internet, it would have more up-to-date knowledge.
RALM Architecture Foundations
General RALM Architectures
To understand how retrieval-augmented language modeling works, we need to start with the foundational architecture. In RALM, the core architecture consists of two primary components that work in tandem. The language model is typically implemented as a transformer decoder, such as GPT, or alternatively as a transformer encoder-decoder architecture like T5. Meanwhile, the retrieval model is generally structured as a transformer bi-encoder, which allows for efficient similarity computation between queries and potential retrieval candidates.
The fundamental challenge and opportunity in RALM lies in the design choices that determine how these two modules interact with each other. These architectural decisions specify the communication protocols between the retriever and the language model, including when retrieval occurs, how retrieved information is integrated into the generation process, and what mechanisms govern the flow of information between these components.
The effectiveness of any RALM system ultimately depends on how well these interaction patterns are designed to leverage the strengths of both retrieval and generation capabilities. Now, let’s examine how these principles were first put into practice.
First Generation Models
Building on these architectural foundations, let’s examine the first generation of retrieval-augmented language models, which represent the foundational approaches in this field. These pioneering models include REALM (Retrieval-Augmented Language Model Pre-Training), developed by Guu et al. in 2020, which introduced the concept of integrating a neural knowledge retriever with a language model during pre-training. Quite a breakthrough at the time!
Following this breakthrough, Lewis et al. presented RAG (Retrieval-Augmented Generation) in 2020, which demonstrated how to effectively combine parametric and non-parametric memory for language generation tasks.
The evolution continued with RETRO (Retrieval-Enhanced Transformer), published by Borgeaud et al. in 2021, which I believe was actually released in 2022. RETRO represented a significant advancement by showing how to retrofit existing language models with retrieval capabilities, allowing them to access and utilize external knowledge bases during inference.
These first-generation models established the core principles and architectural patterns that would influence all subsequent work in retrieval-augmented language modeling, demonstrating the substantial benefits of combining learned representations with explicit knowledge retrieval mechanisms.
2. RETRO: Deep Dive into First Generation RALM
RETRO Architecture
The RETRO model architecture provides a really great illustration of how people initially thought about retrieval-augmented language modeling. With GPT, you have this big language model that incorporates both language information and a lot of world knowledge all within the same system. However, the first idea behind RETRO takes a fundamentally different approach to this challenge.
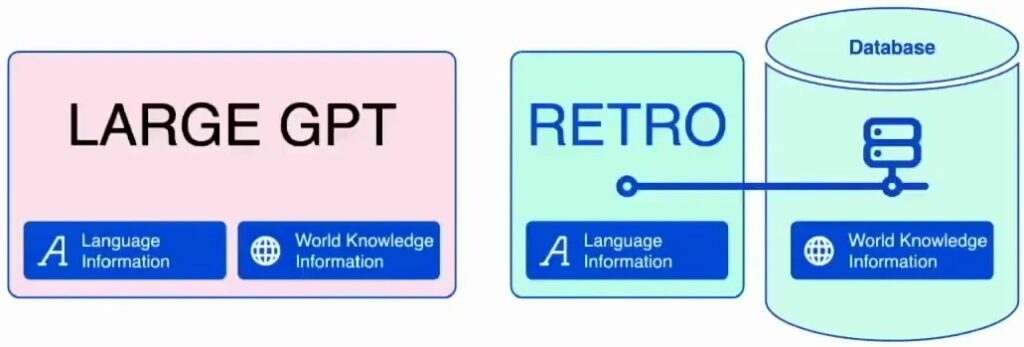
The core insight of RETRO is that the language model itself will be much, much smaller and will focus primarily on just language knowledge. Instead of storing all the world knowledge information within the model parameters, this information can be stored in an external database that the language model can consult when predicting the next token.
This separation allows for a more efficient and scalable approach to incorporating vast amounts of factual information into language generation, which brings us to the question of how this external database is actually structured.
Database Structure and Organization
Building on this architectural approach, let’s examine what this retrieval database actually looks like. The structure is quite straightforward – you have a key-value pair system where each entry contains specific components. The key represents the vector embedding, while the value contains two main pieces of information that work together to enable effective retrieval and generation.

The first component in the value is what we call the ‘neighbor’ – this is essentially the text representation that corresponds to the vector representation stored in the key. Think of it as the human-readable version of that mathematical embedding. The second component is the completion of that text, which provides the contextual information needed for generation.
Let me give you a concrete example to make this clearer. You might have a vector representation for the text ‘Dune is a 2021 American Epic science fiction film’ – that’s your neighbor text. Then you’d have the completion that follows naturally from that context, providing the full information needed for the retrieval-augmented generation process. This structure allows the system to efficiently match queries with relevant content and generate appropriate responses.
Training Data Analysis
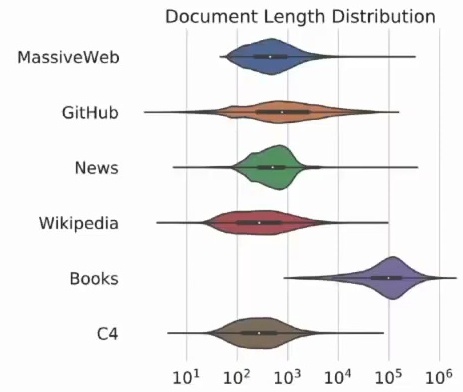
Dataset Composition and Weighting
Now, let’s dive into the specifics of this massive database we’re working with. We’re looking at trillions of tokens sourced from extensive text collections, primarily combining web text with the C4 dataset and other large-scale corpora. A significant portion of this data consists of books, though I should clarify that these aren’t from sources like Wider, which contains mostly copyrighted material. Instead, we’re drawing from public domain books that are freely available for use in training.
The dataset composition includes several key components with specific weightings. News articles receive a weight of 10% in our mixture, and these come from a corpus called Real News that our team has worked with quite extensively in previous research. We also incorporate Wikipedia content for its encyclopedic knowledge and GitHub repositories for code-related learning, creating a diverse and comprehensive training foundation that spans multiple domains of human knowledge and expression.
But to truly understand this dataset, we need to look at how these components break down across languages and document types.
Language and Length Distribution Analysis
Building on our understanding of the dataset composition, let’s examine how this content breaks down by language. While the dataset is technically multilingual, it’s overwhelmingly dominated by English content – the lion’s share comes from the English web. This linguistic distribution has significant implications for what kind of world knowledge gets encapsulated in the resulting model.
Though researchers often refer to it as “world knowledge,” the reality is that this knowledge base will be heavily skewed toward information available in English on the public domain internet.
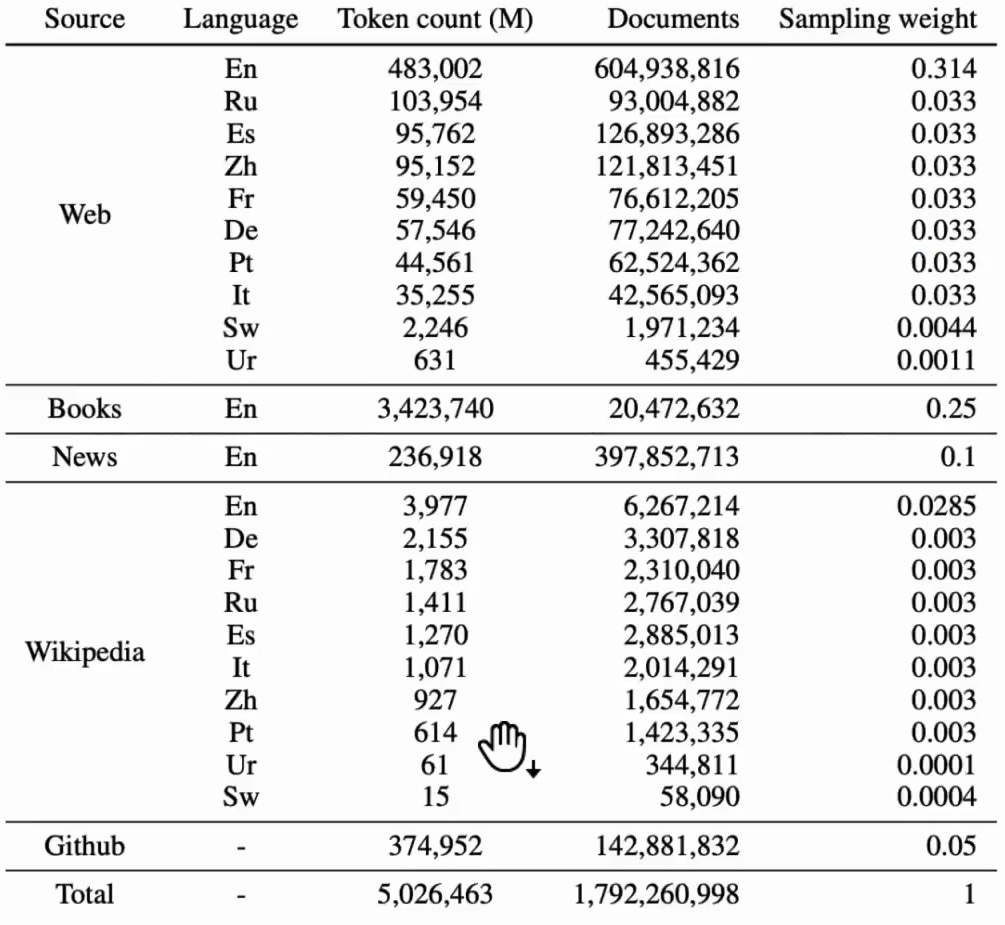
The document length distribution analysis reveals predictable patterns across different data sources. Not surprisingly, books tend to be much longer than other types of content, which makes intuitive sense given their nature as extended narratives or comprehensive treatments of topics. This variation in document length across sources is an important consideration for training, as it affects how models learn to process and generate text of different scales.
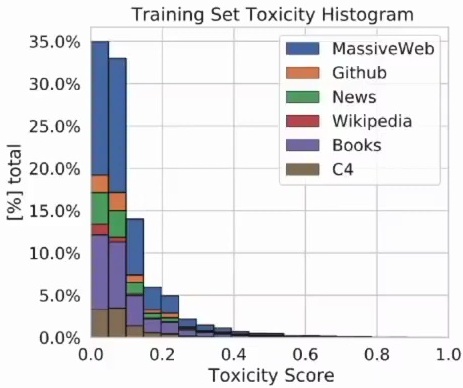
Another crucial aspect they examine is training set toxicity across different data sources. The results show a clear hierarchy in content quality and appropriateness. Wikipedia, being a curated encyclopedia, exhibits relatively low toxicity levels. In contrast, the broader internet content, particularly the massive web text, tends to be significantly more toxic.
This disparity highlights one of the key challenges in large-scale language model training – balancing the desire for comprehensive, diverse training data with the need to minimize exposure to harmful or inappropriate content. These quality considerations become even more important when we examine the specific domains contributing to our web corpus.
Domain Sources and Language Diversity
Now let’s examine the composition of this massive web corpus by looking at its top contributing domains. The data reveals a fascinating mix of academic, social, and technical sources that form the backbone of modern language datasets.
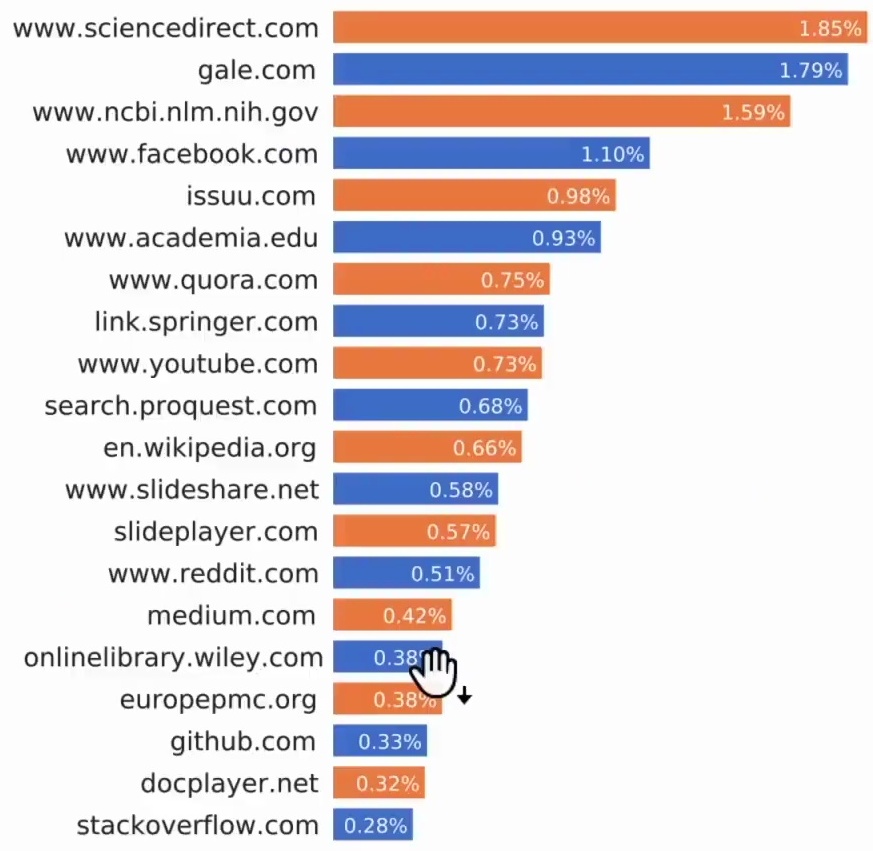
The top 20 domains paint a picture of diverse knowledge sources. We see Science Direct and NCBI representing the academic and scientific community, while Facebook captures social media discourse. Academia.edu and Chorus contribute additional scholarly content, and YouTube comments bring in conversational language patterns.
The presence of Wikipedia, Reddit, Medium, Wiley, GitHub, and Stack Overflow shows how technical documentation, collaborative knowledge, and community-driven content all play crucial roles in building comprehensive language models.
While English dominates the corpus as expected, the dataset doesn’t ignore the rich linguistic diversity of our global digital landscape. The representation of non-English languages ensures that world knowledge from different cultural and linguistic perspectives gets captured in the training data.
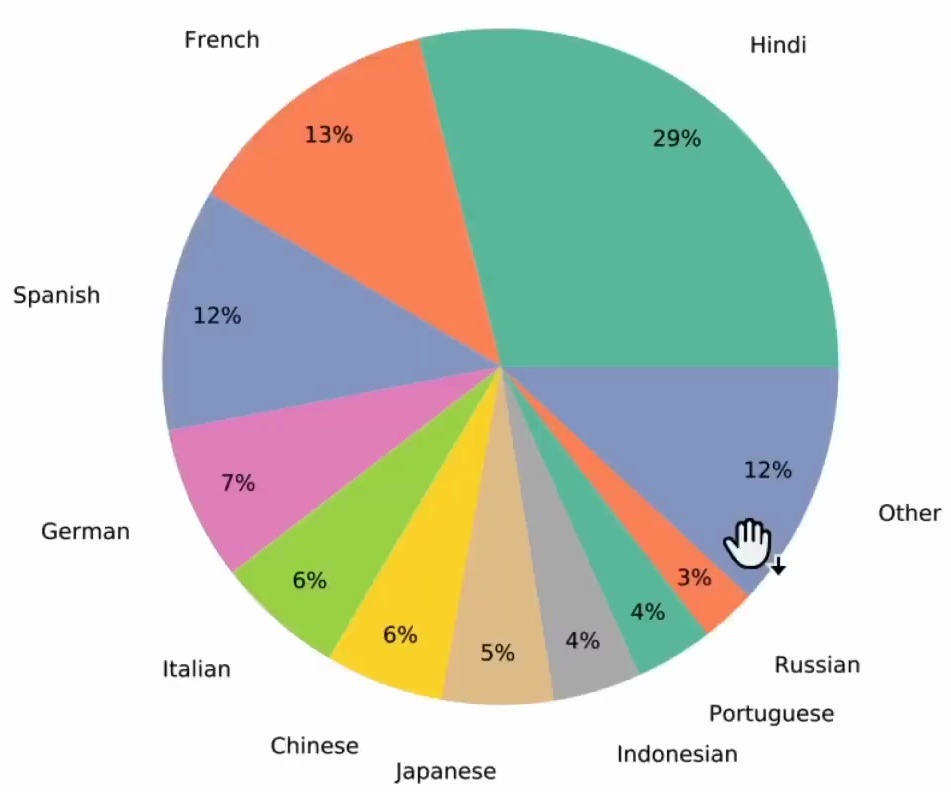
This multilingual representation is particularly important because it means our models aren’t just learning from English-speaking perspectives. With Hindi leading the non-English content at 29%, followed by French at 13% and Spanish at 12%, we’re seeing meaningful inclusion of major world languages that bring different cultural contexts and ways of expressing ideas into the training process.
To round out our understanding of training datasets, let’s look at another important example that’s publicly available.
Related Dataset: The Pile
To complement our analysis of proprietary datasets, it’s valuable to examine a publicly available example that demonstrates similar principles. When considering pre-trained models for various applications, it’s important to understand their inherent limitations, particularly regarding the data they were trained on.
While some datasets may not be truly massive in scale, they can still be highly correlated and valuable for training purposes. A prime example of this is a public domain massive text dataset called “The Pile,” which provides fascinating insights into what constitutes the knowledge base of large language models.
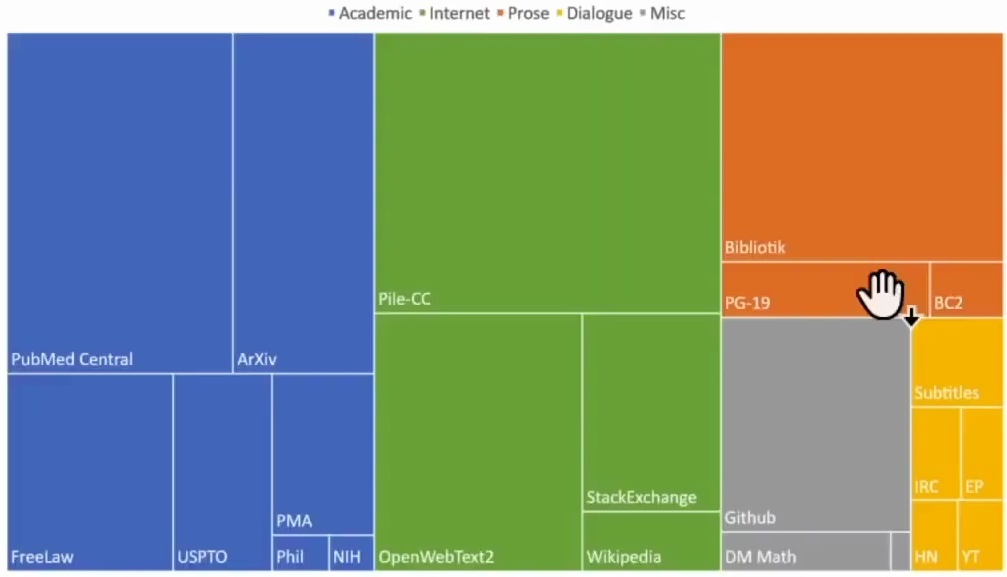
Looking at the composition of The Pile, you can see that PubMed plays a remarkably significant role in the dataset. This actually explains a lot about why modern language models demonstrate such impressive medical knowledge. I remember hearing about a doctor expressing amazement at GPT-4’s medical expertise, but when you see how much PubMed content is included in the training data, it suddenly makes perfect sense.
The dataset also includes substantial portions from ArXiv, Free Law, the US Patent Office, Stack Exchange, and notably, GitHub.
This breakdown gives us valuable insight into not just what large language models were trained on, but more specifically, what constitutes their “world knowledge database.” Understanding these data sources helps explain the strengths and potential biases of these models, and why they excel in certain domains while potentially struggling in others.
It’s this diverse mix of academic papers, legal documents, code repositories, and community discussions that forms the foundation of their knowledge representation.
RETRO Retrieval and Model Components
Database Querying Mechanisms
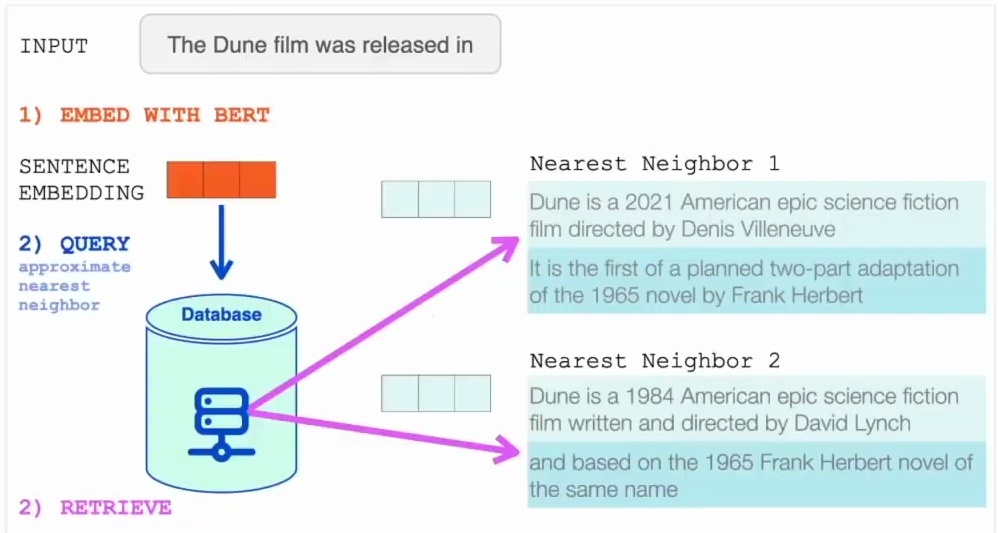
Let’s start by examining how RETRO handles database querying, which forms the foundation of its retrieval capabilities. When querying a neural database, the process begins with taking an input query, such as “The Dune film was released in,” and transforming it into a numerical representation that the system can work with.
This transformation involves computing a sentence embedding using averaged contextualized token embeddings, following the same approach we discussedx when covering sentence embeddings in previous lectures.
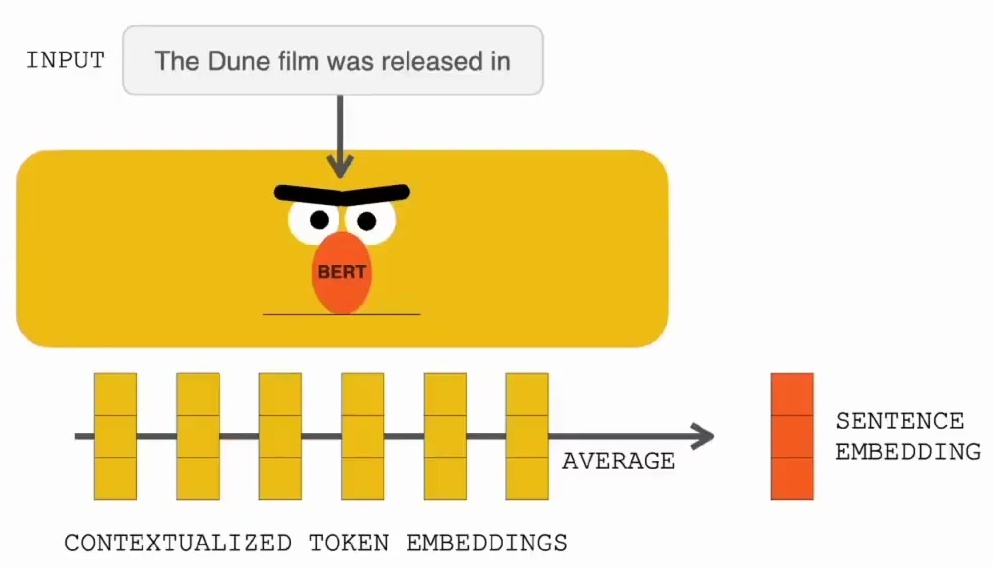
Once we have the sentence embedding, we use it to query the database through an approximate nearest neighbor search. This search mechanism efficiently identifies the two nearest neighbors in the embedding space, whose corresponding text will be incorporated into the language model input.
This retrieval process is crucial because it allows the model to access relevant contextual information that can help generate more accurate and informed responses, which then gets processed in a specific way.
Input Processing with Retrieved Context
Now that we understand how the database querying works, let’s see how RETRO processes the input along with the retrieved context. The input processing pipeline begins with the prompt, such as “The Dune film was released in,” which serves as the query for the retrieval system. This input undergoes vector representation and is matched against a knowledge base to identify the most relevant contextual information through nearest neighbor search.
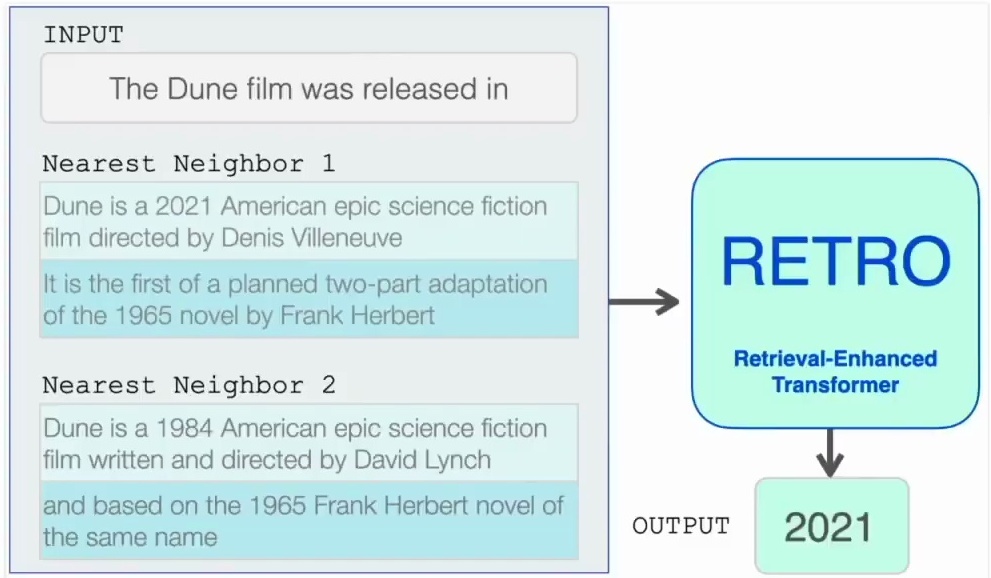
The retrieval mechanism identifies the closest matching text segments – nearest neighbor one and nearest neighbor two – along with their continuations from the knowledge base. These retrieved contexts provide relevant background information that complements the original input prompt.
The combined input, consisting of both the original prompt and the retrieved contextual information, is then fed into the RETRO transformer model, which processes this enriched input to generate the next token prediction – in this case, “2021” – demonstrating how retrieval-enhanced generation can produce more accurate and contextually appropriate outputs.
But how exactly is this RETRO transformer structured?
Model Architecture Overview
Let’s break down the architecture of the RETRO transformer, which represents a fascinating approach to retrieval-augmented language modeling. A RETRO transformer is fundamentally an encoder-decoder transformer model that cleverly separates the processing of retrieved information from the main text generation task. The model features an encoder stack specifically designed to process nearest neighbor examples and a decoder stack that handles the text prompt generation.
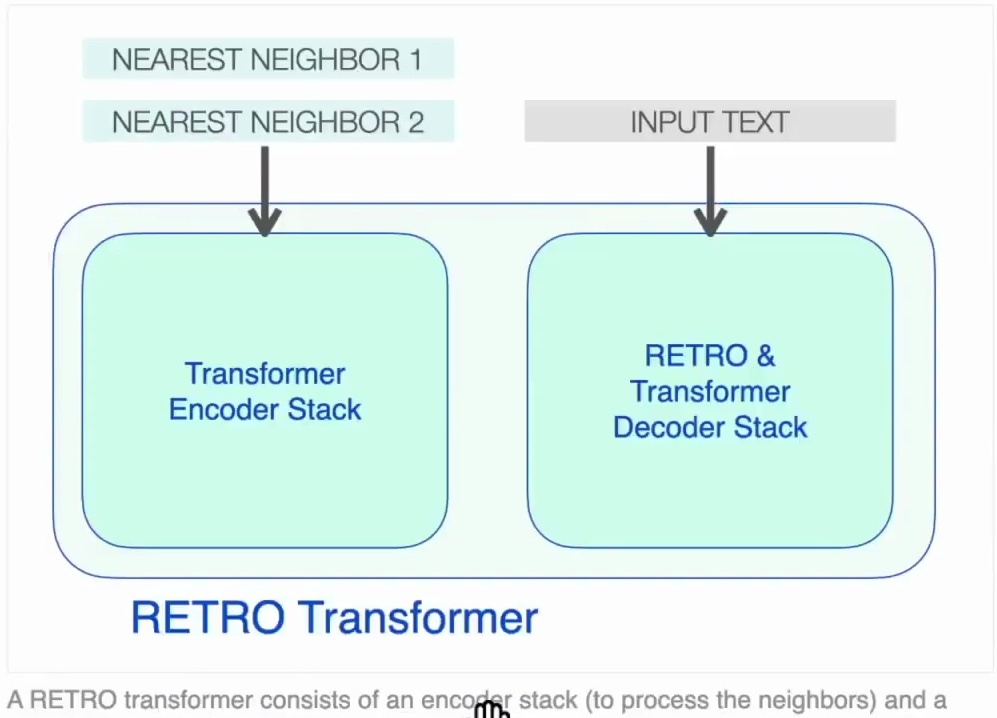
The encoder component operates much like the transformer encoder models we’ve already encountered, using standard encoder transformer blocks that combine self-attention mechanisms with feed-forward neural networks. You feed in your two nearest neighbors, and the encoder generates the key and value matrices from these retrieved examples, which will later be crucial for the cross-attention operations in the decoder.
The decoder stack is where things get particularly interesting, as it incorporates two distinct types of decoder blocks. First, there are standard transformer decoder blocks similar to those found in GPT models, which feature attention mechanisms and feed-forward layers that apply causal self-attention to the prompt, ensuring tokens can only attend to previous tokens in the sequence.
But the real innovation lies in the specialized RETRO decoder blocks, which not only perform self-attention but also implement chunked cross-attention to the encoder stack, allowing the model to dynamically incorporate information from the retrieved nearest neighbors during text generation. Let’s examine these specialized blocks more closely.
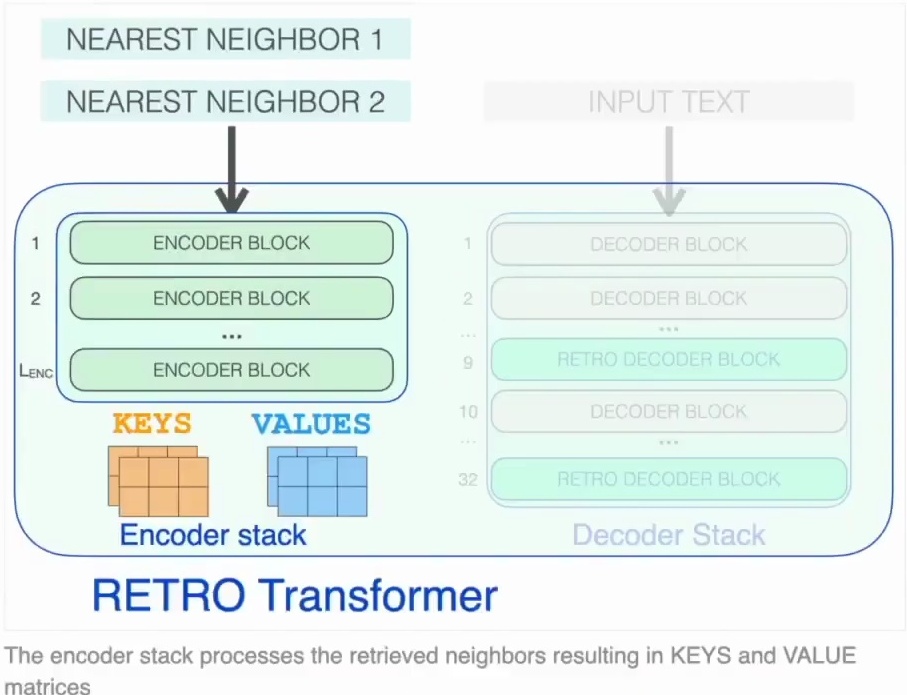
Figure 14: Architecture diagram of a RETRO Transformer model showing the encoder and decoder stacks. The encoder stack processes retrieved nearest neighbors to generate key and value matrices, while the decoder stack includes specialized RETRO decoder blocks. Demonstrates the integration of retrieval-based information into the transformer architecture through cross-attention mechanisms.
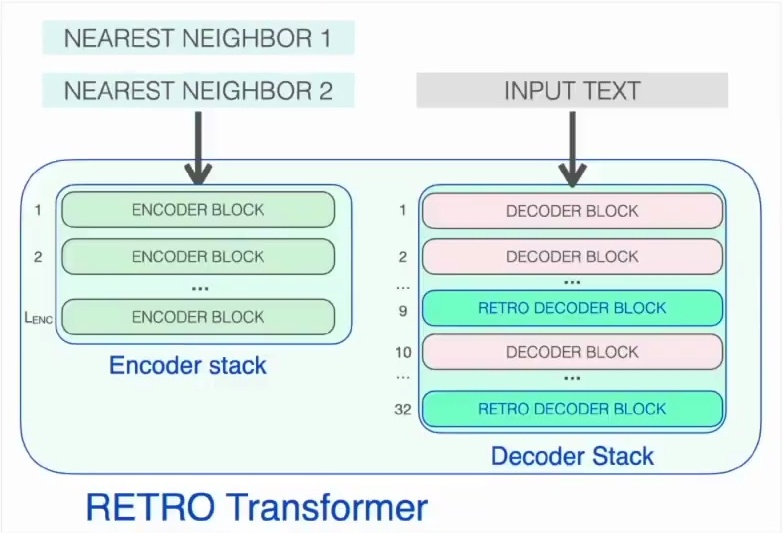
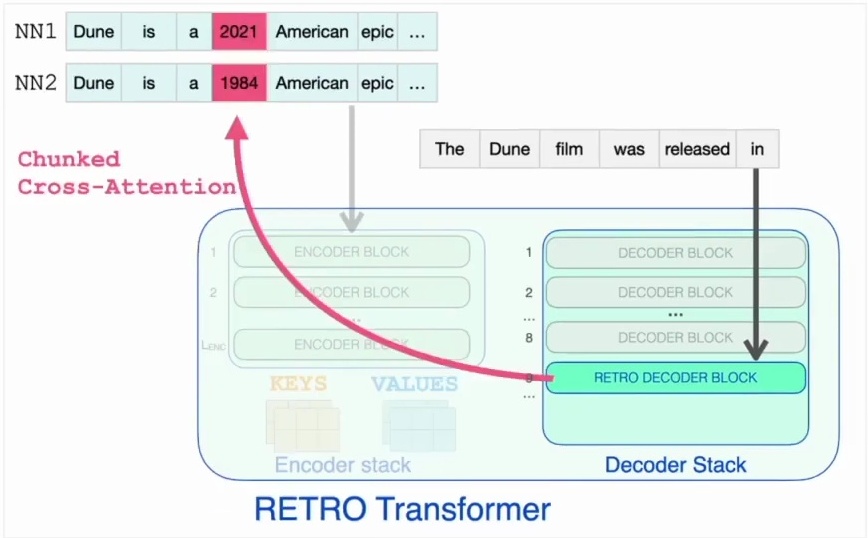
Retrieval Blocks and Cross-Attention
Now let’s dive deeper into how these specialized RETRO blocks actually work within the architecture. The RETRO architecture incorporates specialized retrieval blocks at strategic intervals throughout the transformer layers. These retro blocks appear every third block starting from layer nine, so you’ll find them at layers 9, 12, 15, and continuing all the way up to layer 32.
This systematic placement ensures that the model has regular opportunities to incorporate retrieved information as it processes the input sequence.
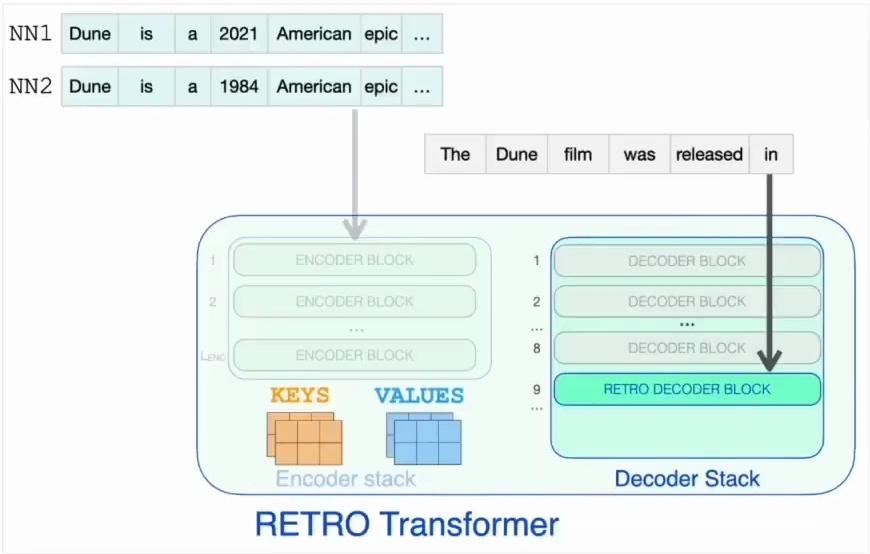
The key innovation of these retro blocks lies in their cross-attention mechanism to the retrieved neighbors. Unlike standard transformer blocks that only attend to previous tokens in the sequence, retro blocks can attend to specific external data that’s been retrieved from the database.
This cross-attention allows the model to focus on the particular information it needs to accurately predict the next word in the current query, effectively bridging the gap between the model’s internal representations and the external knowledge stored in the retrieval database.
Data Quality and Leakage Issues
Data Leakage in Retrieval Models
When working with retrieval models, we need to be particularly careful about data quality issues. A potential problem with evaluating the performance of retrieval models is data leakage – specifically when your query literally appears in your external database. This is actually quite likely to happen since many benchmarks are found in C4 and other large web text datasets.
When this occurs, the model will obviously be able to complete the query successfully because it has essentially seen the answer before during training or indexing.

The researchers acknowledge this concern and provide examples in their appendix where such data leakage occurs. However, they argue that this phenomenon doesn’t actually drive the overall performance of their model. This suggests that while some queries may benefit from having appeared in the training data, the model’s success isn’t primarily dependent on this form of memorization, but rather on its ability to effectively retrieve and utilize relevant information from the external database.
But how can we actually verify these claims about duplication?
Neural De-Duplication Methods
To get a better handle on this duplication issue, let’s examine what we discovered when we applied neural de-duplication methods to real news data, where the news portion comprised 10% of the overall dataset weight. When we used traditional hashing – literally implementing exactly the same method they used for duplicate detection – the results seemed to support their argument that duplication isn’t really a significant issue in their dataset.
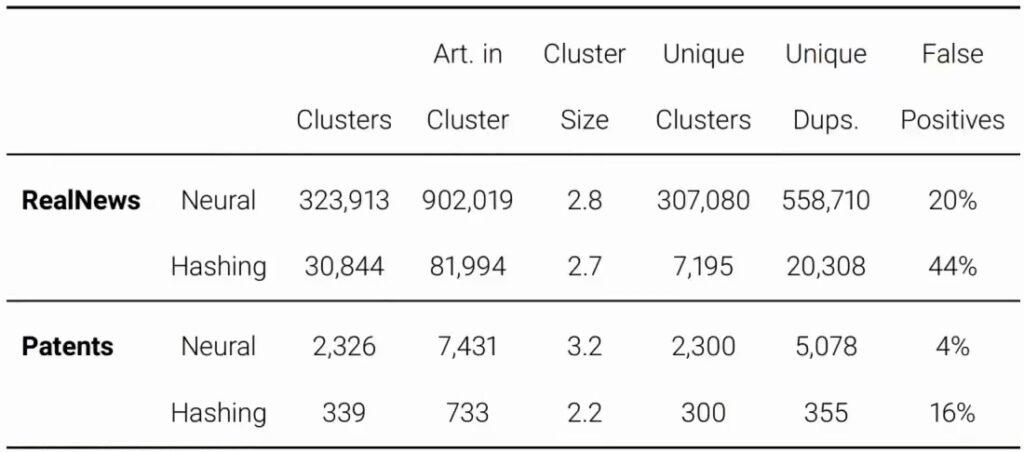
However, when we switched to our neural method, the picture changed dramatically. We discovered significantly more noisy duplicate clusters, and crucially, most of these turned out to be true positives rather than false positives. This suggests that the neural approach is much more effective at identifying subtle duplications that traditional hashing methods miss entirely.
Now, I want to be clear – this finding doesn’t invalidate the power of these neural architectures in any way. But it does raise an important consideration when you’re evaluating performance on benchmarks. You might want to ask yourself: is this benchmark data likely to literally appear in the training database? Because if it is, then it wouldn’t be particularly surprising to see relatively strong performance, and you’d want to account for that potential data leakage in your analysis.
3. Advanced RALM Approaches and Future Directions
Second Generation: Frozen Language Models
Frozen LM Approach Overview
Now let’s transition from first generation to second generation retrieval-augmented language models, where we see a fundamental shift in approach. RETRO and other early models from just a year or two ago froze the retriever and trained the language model instead. The reasoning behind this was quite practical – training the retriever would be prohibitively costly due to the re-indexing problem.
When you train the retriever, the embeddings you’re querying become outdated at each training step because they were created with the retriever from a previous iteration. This misalignment means you need to constantly update the index, re-embed everything, and re-index the entire corpus, which becomes computationally expensive very quickly.
However, second generation retrieval-augmented language models take the opposite approach – they freeze the language model and focus on developing sophisticated retrieval frameworks that can work effectively with very large frozen language models, like GPT behind an API.
The motivation here is compelling: these massive language models have become so capable that their performance gains outweigh the inability to fine-tune them. Even though we’re dealing with black box models behind APIs that we can’t directly modify, their raw capabilities are simply too valuable to forego.
Recent notable contributions in this space include systems like Replug and DSP, which exemplify this frozen language model approach and demonstrate how to effectively leverage these powerful but untrainable models. Let’s dive deeper into how RePlug specifically implements this frozen language model strategy.
RePlug Black Box Augmentation
RePlug represents a perfect example of this frozen language model philosophy, introducing a fundamentally different approach by treating the language model as a black box and augmenting it with a tunable retrieval model. Unlike prior retrieval-augmented language models that train the language model across attention mechanisms to encode the retrieved text, RePlug takes a much simpler approach.
Instead of the complex architecture you saw with Retro, where you passed the retrieved text through an encoder and then used a decoder with your query through cross-attention mechanisms, RePlug simply prepends the retrieved documents directly to the input for the frozen language model.
This elegant simplification means you’re essentially just taking the retrieved text and adding it to your prompt, eliminating the need for sophisticated cross-attention architectures. Another key insight of RePlug is that the language model itself can be used to supervise the training of the retrieval model, creating a self-reinforcing system where the language model guides the retrieval process.
The results speak for themselves – they find that RePlug improves the performance of GPT-3 by 6.3% on language modeling tasks, demonstrating that sometimes the simplest approaches can be remarkably effective in this second generation of retrieval-augmented systems.
RE-PLUG Architecture and Framework
Now let’s dive deep into the RE-PLUG framework and understand how it fundamentally differs from traditional retrieval-augmented generation approaches. Previously, you would have your query as the input, pass that to a frozen retriever to get the context, and then pass that to a language model that you trained. That language model would be relatively small, with less than 10 billion parameters.
In contrast, with RE-PLUG, you pass your query to a retriever which could be either frozen or trainable, get your context, and then you pass that into a black box language model – but here’s the key difference – this language model is going to be much larger, with more than 100 billion parameters.
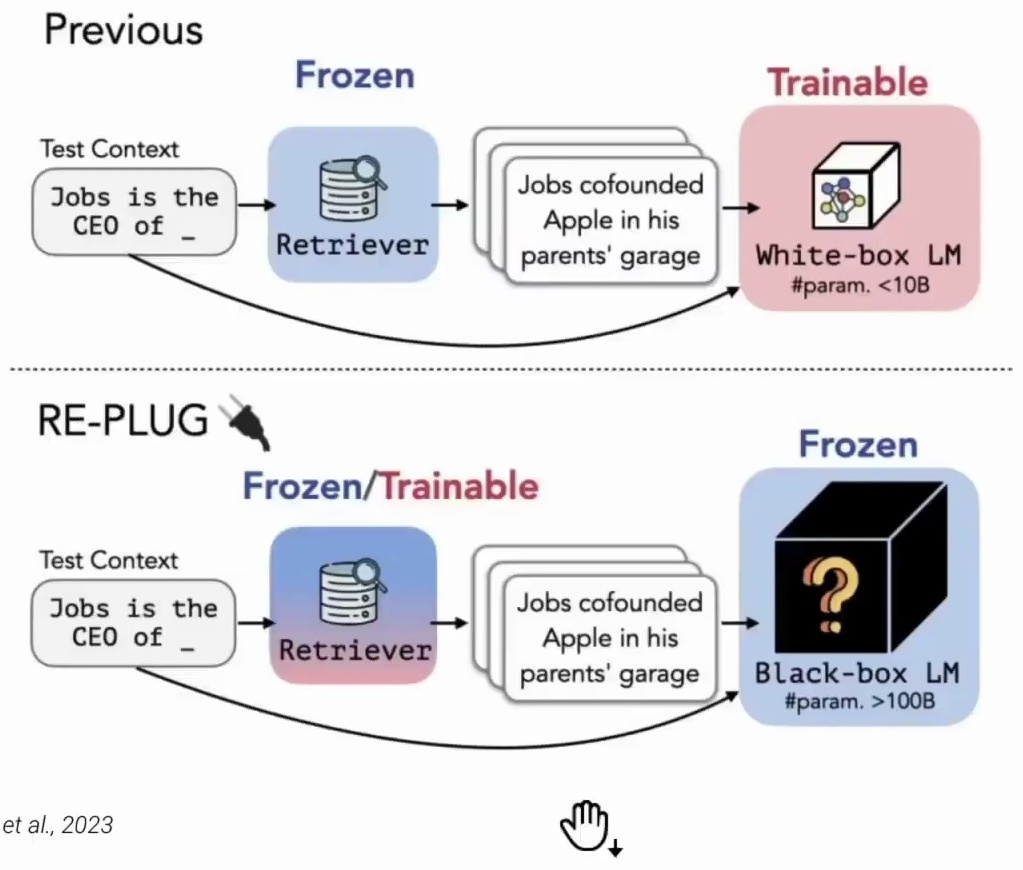
Figure 19: Comparison diagram showing two retrieval-augmented generation approaches. The top section shows a previous method with frozen retriever and trainable white-box language model, while the bottom section illustrates the RE-PLUG approach with a frozen/trainable retriever connected to a frozen black-box language model with significantly more parameters. Both systems process the same test context through retrieval and generation stages.
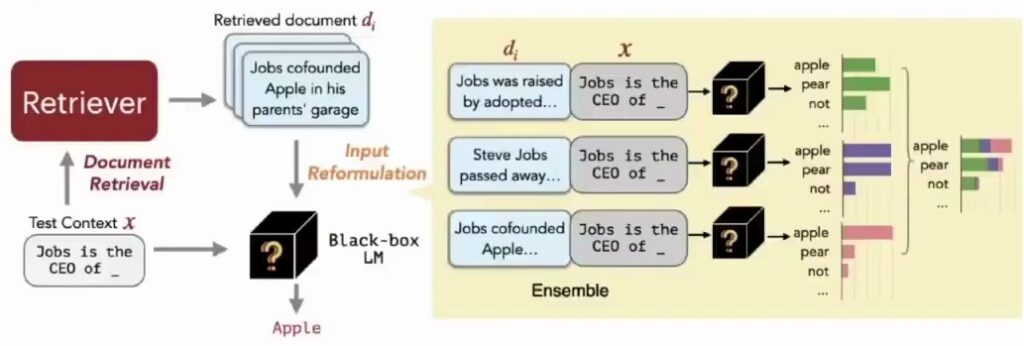
Now, let’s dive into how the RE-PLUG framework works more specifically. You start with your query as the input and pass that to the retriever to get your retrieved documents. Here’s where it gets interesting – you take each of those retrieved documents and append them to your original query.
Then you pass each of these augmented inputs into GPT, and you’ll get a probability distribution over the next words for each one. The final step is to ensemble those probabilities together and choose the most likely next word based on this combined information.
Training Methods and Optimization
With the architecture in place, the next crucial question is how to train the retriever component effectively. The training methodology for the retriever in RE-PLUG is based on an elegant alignment principle between retrieval and language modeling objectives. The core idea involves computing two distinct likelihood distributions: a retriever likelihood that estimates the probability that each retrieved document contains the answer to the query, and a language model likelihood that measures how well each document helps the language model generate the target output.
The training objective is to minimize the KL divergence between these two distributions, effectively teaching the retriever to prioritize documents that improve the language model’s performance.
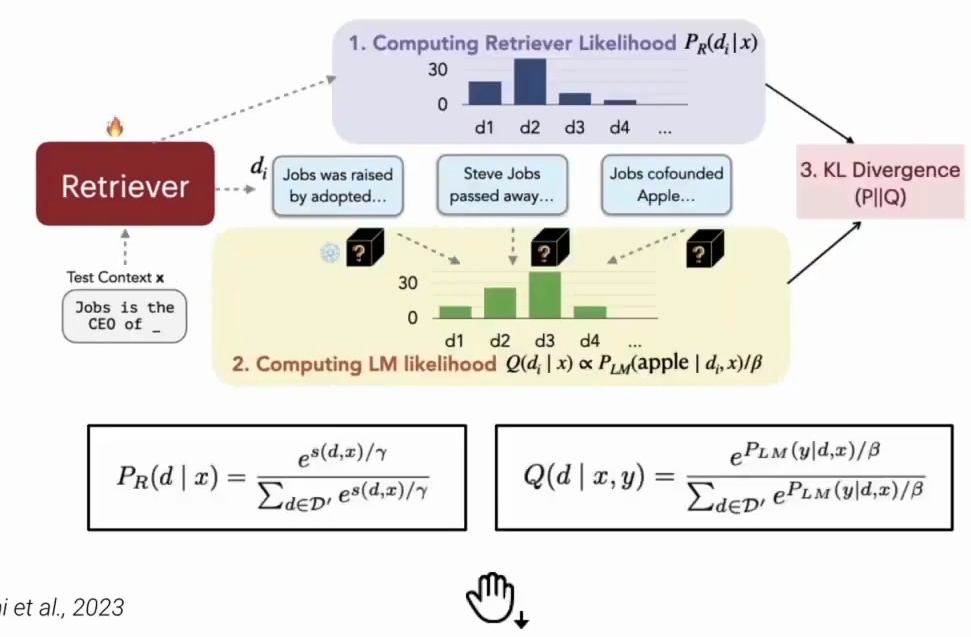
Figure 21: Diagram illustrating RE-PLUG training methodology with three main components: (1) Computing retriever likelihood \(P_R(d|x)\) showing document ranking, (2) Computing language model likelihood \(Q(d|x,y)\) with probability distributions, and (3) KL divergence optimization. Shows the flow from test context through retriever to document selection and final probability computation using the mathematical formulas \(P_R(d|x) = \frac{e^{s(d,x)/\tau}}{\sum_{d \in D’} e^{s(d,x)/\tau}}\) and \(Q(d|x,y) = \frac{e^{P_{LM}(y|d,x)/\beta}}{\sum_{d \in D’} e^{P_{LM}(y|d,x)/\beta}}\).
Specifically, the training process computes the language model probability of the ground truth output given both the input context and each retrieved document. Documents that yield higher probabilities are considered better at improving the language model’s perplexity. By updating the retrieval model parameters to minimize the KL divergence between the retrieval likelihood and the language model score distribution, the system learns to find documents that result in lower perplexity scores for the language model.
This approach represents another example of self-supervised training for retrievers, where the language model itself provides the supervisory signal for training the retrieval component. The retriever is incentivized to choose documents that make it more likely for the language model to predict the next word correctly.
However, since the retriever parameters are updated during training, the previously computed document embeddings become outdated, necessitating a rebuild of the efficient search index using the new embeddings every \(T\) training steps. This dynamic updating ensures that the retrieval system remains aligned with the evolving language model, and RE-PLUG can be successfully integrated with various language models to improve overall performance.
Interpretability and Attribution
While the training methodology shows promising results, there’s an important limitation we need to address regarding the interpretability of RE-PLUG systems. While retrieval-enhanced language modeling can be used with a variety of language models to improve performance, the authors point out a significant limitation: the method is not very interpretable.
It remains unclear whether the language model’s predictions rely on parametric knowledge learned during training or on the retrieved knowledge from external sources. This ambiguity creates a fundamental attribution problem that has practical implications for how we understand and trust these systems.
Consider this scenario: GPT gives you an answer and cites some retrieved documents as its sources, but that doesn’t necessarily mean that the answer actually came from those retrieved documents. It just means those retrieved documents were added into the context, and the model might still hallucinate something based on its parametric knowledge.
This could be a real issue in terms of what it means to cite your sources – are we getting genuine retrieval-based answers or are we seeing the model’s internal knowledge dressed up with seemingly relevant citations?
Interestingly, in their analysis of examples where RE-PLUG results in a decrease in perplexity, the authors find that the method is most helpful for rare entities. Their example is a Chinese poet like Li Bai, which makes intuitive sense when you consider that these models are trained disproportionately on the English internet.
This Chinese poet probably wasn’t mentioned very much in the training data, so it’s logical that retrieval-enhanced language modeling would be particularly beneficial for such cases where the parametric knowledge is sparse.
DSP: Demonstrate, Search, Predict Framework
DSP Framework Introduction
The second framework I want to mention is Demonstrate Search Predict, or DSP. This isn’t really a model so much as a framework for combining retrieval with language modeling. If you wanted to take the simplest possible approach to retrieval-augmented language modeling with a frozen retriever and a frozen language model, you would just insert the retrieved passages into the LM prompt – which is essentially what ReAug does when it freezes the retriever.
DSP aims to develop a more sophisticated framework that, as they put it in their abstract, “relies on passing natural language text and sophisticated pipelines between the language model and the retrieval model.”
The approach is quite reminiscent of chain-of-thought prompting in that it breaks problems into smaller transformations that can be handled more reliably by both the language model and the retrieval model. They find significantly improved performance relative to vanilla GPT-3.5 and standard retrieve-then-read pipelines. The key insight is in how they handle multi-hop reasoning through their search component.
Let me give you a concrete example of how this works. Consider the question “How many stories are in the castle David Gregory inherited?” A vanilla language model hallucinates a fictitious castle, while a retrieve-then-read model retrieves the wrong document.
But their multi-hop DSP program breaks this question down systematically: first asking “Which castle did David Gregory inherit?” and getting the answer “David Gregory inherited Kennedy castle in 1664.” Then it asks “How many stories does Kennedy castle have?” and retrieves “It’s a tower house having five stories.”
The real meat of this framework is in this multi-hop search capability, where they’re essentially doing chain-of-thought prompting but with retrieval steps integrated throughout the reasoning process.
DSP Search for Question Answering
Building on this multi-hop reasoning capability, another key part of this approach is its summarization capability. When multiple contexts are returned from the search, they wouldn’t necessarily all fit into a single prompt. However, the system leverages the remarkable summarization capacity of GPT to condense the retrieved documents so they can be incorporated into the prompt effectively.
This allows the model to work with a manageable amount of information while still accessing the relevant content from multiple sources.
The system then tasks itself to answer questions using these web documents, incorporating a rationale component through chain of thought prompting. This demonstrates one of the most emphasized features of very large language models – their capacity for in-context learning.
You can provide these models with examples and instructions, and they can perform the task without needing to tune their parameters. This phenomenon allows researchers to demonstrate the entire multi-hop procedure to GPT, showing it how to navigate through multiple reasoning steps to arrive at comprehensive answers.
In-Context Learning and Prompting Insights
This brings us to the broader implications of what DSP demonstrates. The main takeaway is that in-context learning, where a large language model performs a task just by conditioning on input-output examples without optimizing any parameters, is a really powerful tool.
Chain of thought prompting provides information that the models can more easily digest, allowing them to work through problems step by step rather than jumping directly to conclusions. We also see that rules make a comeback in this paradigm – you’re essentially designing rules about how to prompt the model that can make use of the in-context learning and the chain of thought prompting capabilities.
This approach leverages the summarization capabilities of GPT to do something really powerful without having to train a model at all. It shows how to achieve results that improve over vanilla GPT, but without having to train anything. Just by designing the prompts and the instructions that you give to GPT – how you retrieve information as well – in a way that is easier for these models to digest, you can get significant performance improvements.
Putting the language model behind an API and having it interact with external retrieval systems and databases like the internet is clearly the path for commercializing AI. This architecture allows for scalable deployment while maintaining the flexibility to incorporate new information and adapt to different tasks through clever prompting strategies rather than expensive retraining procedures.
Conclusion
As we wrap up our exploration of retrieval-augmented generation, it’s worth reflecting on the broader landscape we’re entering. Right now, there’s a huge race underway to see who can implement retrieval-enhanced language models the best and fastest, with technology firms competing to become the dominant player in this space.
The clear path for commercializing AI seems to involve putting large language models behind APIs and having them interact with external, retrievable databases like the internet. We’re already seeing this play out in real time with systems like Bing connecting to live web data, and I think we’ll likely see much more of this retrieval-enhanced approach because it addresses some of the most pressing problems with current chatbots – like quickly becoming out of date, potential reduction in hallucinations, and better source attribution, although there’s still no guarantee that cited sources actually generated the specific answer.
In our upcoming tutorials, we’ll explore how retrieval techniques can be applied to various social science applications, which presents some interesting challenges and opportunities. In many academic contexts, it’s hard to imagine that a frozen GPT or other massive language model paired with a frozen retriever could match the performance of self-supervised or supervised training on the target domain.
Our applications often differ drastically from commercial use cases – we work with languages that aren’t prevalent in training corpora, analyze historical texts, and tackle problems that diverge significantly from what these models encountered during their original training.
Despite these challenges, we believe there are likely some really powerful academic applications for these retrieval-enhanced approaches. This connects closely to our discussion of prompting techniques from a few weeks ago, and as we move forward in the course, I’m excited for us to explore these connections further in our upcoming class discussions.
The intersection of retrieval methods and domain-specific academic research presents fascinating possibilities that will continue to shape how we approach computational social science.
Summary
We’ve explored the fascinating world of retrieval-augmented language modeling, tracing its evolution from first-generation systems like RETRO to modern frameworks like RePlug and DSP. These approaches tackle fundamental limitations of traditional language models by combining parametric knowledge with dynamic retrieval capabilities.
The journey began with RETRO’s innovative dual-stack architecture, which separates language processing from world knowledge storage through an external database. We examined how this system processes massive datasets from diverse sources, implements sophisticated cross-attention mechanisms, and handles the complex challenges of data quality and leakage. The second generation marked a paradigm shift toward frozen language models, where systems like RePlug demonstrate that simple approaches – prepending retrieved documents to prompts – can achieve remarkable performance improvements with black-box models like GPT-3.
Looking ahead, the race to perfect retrieval-enhanced AI systems continues to accelerate, with clear implications for both commercial applications and academic research. While these systems show tremendous promise for addressing hallucination, source attribution, and knowledge currency issues, they also present new challenges around interpretability and domain adaptation that will shape the future of computational social science.
References:
[1] Guu et al. “REALM: Retrieval-Augmented Language Model Pre-Training” ICML 2020
[2] Lewis et al. “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” NeurIPS 2020
[3] Borgeaud et al. “Improving language models by retrieving from trillions of tokens” ICML 2022