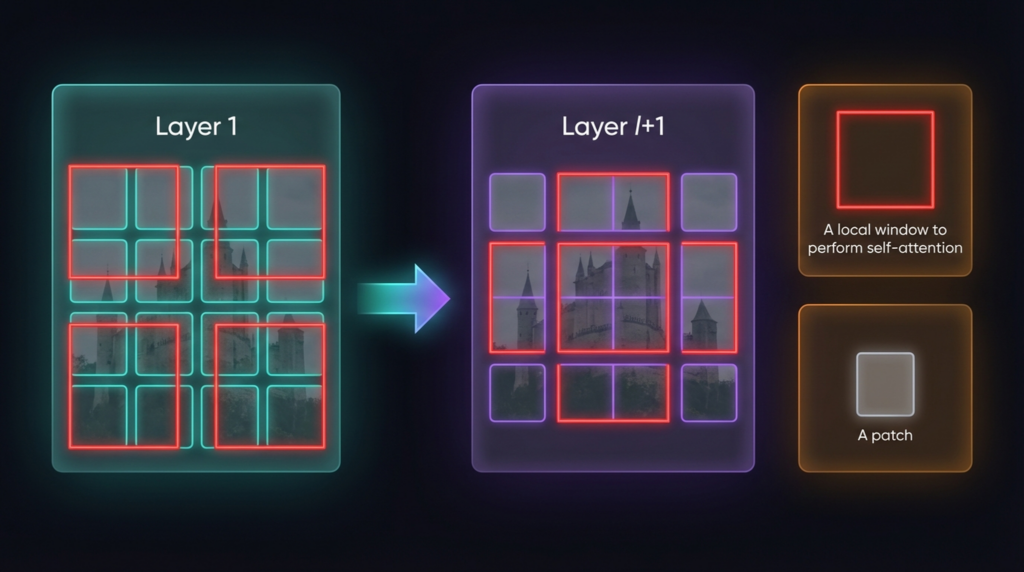
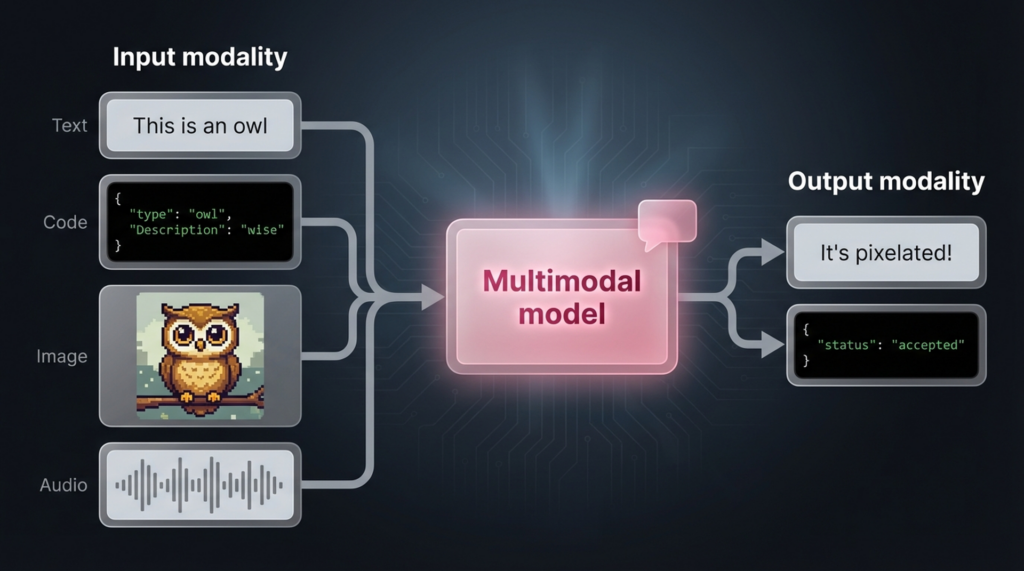
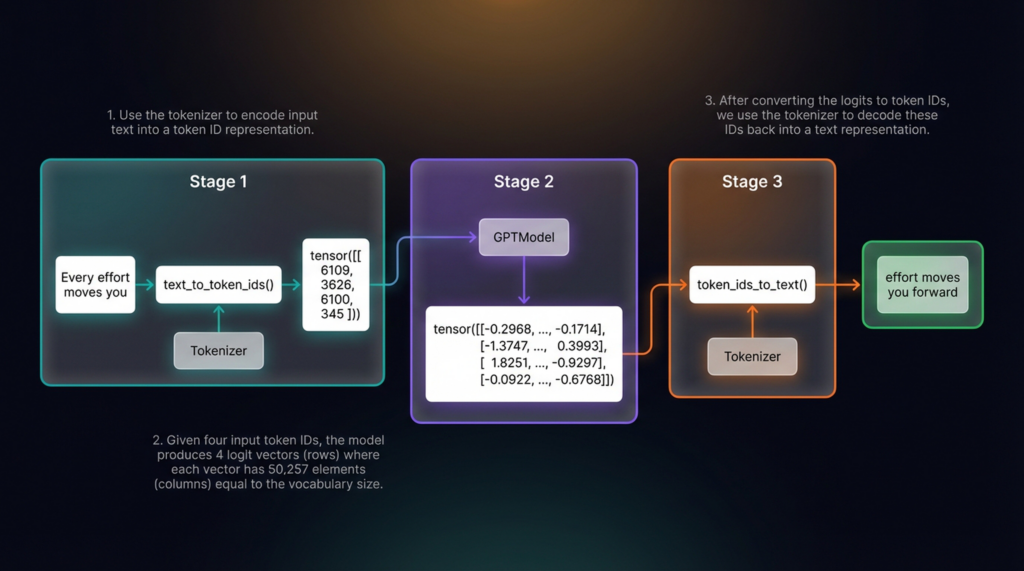
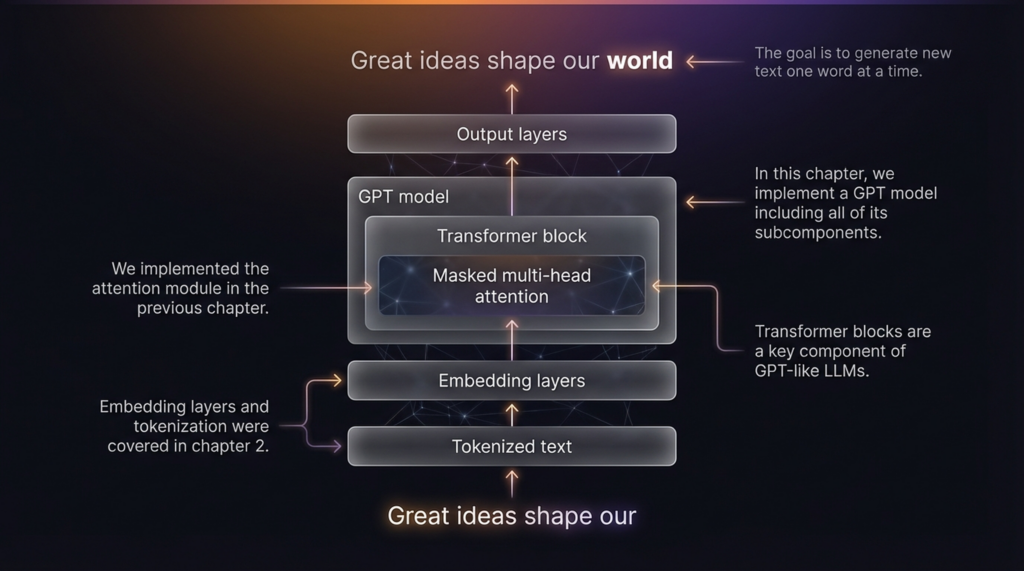
LLM_log #010 Understanding Diffusion Models Through 1D Experiments — From DDPM to Manifold Compactness
Highlights: We implement a complete DDPM from scratch on 1D sine waves — same math as image diffusion, but every intermediate state is plottable. We track 100 parallel trajectories, measure when the model “commits” to a specific sample, then design a controlled experiment that reveals manifold compactness as the key factor determining whether diffusion succeeds or fails. So let’s begin! Tutorial Overview: Why 1D? The Dataset Forward Process Model and Training Generating from Noise What…
Read more