#014 Calculating Sparse Optical flow using Lucas Kanade method

Highlights: In this post, we will show how we can detect moving objects in a video using the Lucas Kanade method. This approach is based on tracking a set of distinctive feature points. Therefore, it is also known as a Sparse Optical Flow method. We will give a detailed theoretical understanding of the Lucas Kanade method and show how it can be implemented in Python using OpenCV.
Tutorial overview:
- Understanding the Concept of Motion
- Optical Flow and its types
- Optical Flow Constraint
- Gradient Component of Flow
- Lucas Kanade in Python
1. Understanding the Concept of Motion
Until now, we have covered many computer vision methods for object detection, object segmentation, and object tracking. However, in all these approaches one important piece of information is completely ignored. That information is the relationship between objects in two consecutive frames.
Let’s understand this using an example. Have a look at the GIF below that shows a sunrise motion. This GIF is nothing but a sequence of static frames combined together.

In examples such as above, our main objective is to capture the change that happens from one frame to another. In order to achieve that, we need to track the motion of objects across all frames, estimate their current position and then, predict their displacement in the subsequent frame.
Moreover, when we work with video sequences rather than static images, instead of using just space coordinates \(x\), and \(y\), we will also have to track a change of intensity of a pixel over time. Therefore, we will have one additional variable – time. This means that the intensity of a single-pixel can be represented as a function of space coordinates \(x\), \(y\), and time \(t\).

This approach is popularly known as Optical Flow. Let’s understand this better along with the various categorizations of Optical Flow.
2. Optical Flow and its types
Optical Flow can be defined as a pattern of motion of pixels between two consecutive frames. The motion can be caused either by the movement of a scene or by the movement of the camera.
A vital ingredient in several computer vision and machine learning fields such as object tracking, object recognition, movement detection, and robot navigation, Optical Flow works by describing a dense vector field. In this field, each pixel is assigned a separate displacement vector that helps in estimating the direction and speed of each pixel of the moving object, in each frame of the input video sequence.
If we were to categorize the technique of Optical Flow, we can divide it into two main types: Sparse Optical Flow and Dense Optical Flow.
- Sparse Optical Flow: This method processes the flow vectors of only a few of the most interesting pixels from the entire image, within a frame.
- Dense Optical Flow: Here, the flow vectors of all pixels in the entire frame are processed which makes this technique a little slower.
Have a look at the two GIF images below. The image on the left shows Sparse Optical Flow in action and the image on the right shows Dense Optical Flow.

As you must have realized by now, that tracking motion of objects from one sequence to another is a complicated problem due to the sheer volume of pixels in each frame. In the following paragraphs, we will give the necessary theoretical concepts, and finally, we will derive the equations for Lucas Kanade optical flow method.
3. Optical Flow Constraint
In the Lucas Kanade method, an important assumption was made, that there isn’t any significant change in the lighting between two consecutive frames. This assumption is called the Brightness Constancy Assumption. This means that if the object in the image moves or the camera moves, then, the colors of that object will remain the same, regardless of the lighting.
Brightness constancy constraint: Let’s assume that a pixel is moving in the direction \((u, v)\). That is \(u\) is the amount of movement in \(x\) direction, and \(v\) is the amount of movement in \(y\) direction when we get to \(t+1\). Here, \(t\) represents the time instance of the first frame where the consecutive frame is represented as \(t+1\).
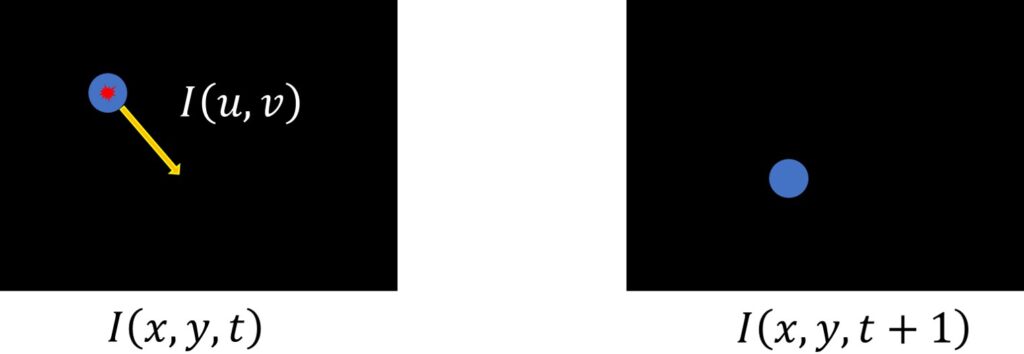
The brightness constancy constraint equation can be written as follows:
$$ I(x, y, t) = I(x+u, y+v, t+1) $$
In this equation, \(I(x, y, t)\) represents the pixel intensity at time \(t \) at location \((x, y) \). The Brightness Constancy Assumption states that the intensity at \(t+1 \) at location \(I(x+u, y+v) \) is going to be the same as in the frame \(t\). Here, \(u\) and \(v\) are displacements for wich the poin has mooved in \(x\) and \(y\) direction.
This can also be rewritten as:
$$ 0 = I(x+u, y+v, t+1) – I(x, y, t) $$
Small Motion: When a pixel moves between two consecutive frames we assume that a movement is relatively small. We can then use the Taylor expansion in order to approximate this equation:
$$ 0 \approx I(x, y, t+1)+I_{x} u+I_{y} v-I(x, y, t) $$
Here, we are substituting the value \(I(x+u, y+v, t+1)\) with the Taylor expansion. So, we have the \(I(x,y,t+1) \) plus the derivative part \(I_{x}u + I_{y}v \). Note that \(I_{x}u\) is the derivative in the \(x\)-direction, and \(I_{y}v\) is the derivative in the \(y\)-direction.
In addition, \(I_{x} = \frac{\partial I}{x}\) and \(I_{y} = \frac{\partial I}{y}\) for both \(t\) and \(t+1\). Here, we are going to assume that the things are changing slowly, so the derivative at a particular point is going to be the same both at \(t\) and \(t+1\).
$$ 0 \approx [I(x,y,t+1) – I(x, y, t)]+ I_{x}u + I_{y}v $$
Now, when we rearrange equation terms:
$$ 0 \approx I_{t} + I_{x}u + I_{y}v $$
This \(I_{t}\), is the difference between \(I(x,y,t+1) – I(x, y, t)\). So \(I_{t}\) is called the temporal derivative. In addition, \(I_{x}\) is the derivative of \(I\) in the \(x\)-direction and \(I_{y}\) is the derivative of \(I\) in the \(y\)-direction. Next, \(I_{t}\) is the derivative of \(I\) with respect to time. Our video is a function \(I(x,y,t)\), so a derivative can be taken with respect to \(x\), \(y\), and \(t\).
$$ 0 \approx I_{t} + \bigtriangledown I \cdot [u, v] $$
Here \( \bigtriangledown I \cdot [u, v] \) is the gradient of the image, dotted with the vector \([u, v]\). We talked about Image Gradient before and you can check it out.
Finally, the brightness constancy constraint equation can be written as:
$$ I_{x}u + I_{y}v + I_{t} = 0 $$
This is an equation with two unknowns and as such cannot be solved. This is known as the aperture problem of optical flow algorithms. To find the optical flow another set of equations is needed to impose an additional constraint.
$$ I_{x}u + I_{y}v = – I_{t} $$
Note that this can be written as a single vector equation:
$$\vec{\bigtriangledown}I \cdot \vec{u} = -I_{t}$$
where:
$$ \vec{\bigtriangledown}I = \begin{bmatrix}
I_{x}\\
I_{y}
\end{bmatrix}$$, and $$ \vec{u} = \begin{bmatrix}
u\\
v
\end{bmatrix}$$
4. Gradient Component of Flow
In the last paragraph we get to this equation, which is the brightness constancy constraint equation:
$$ I_{x}u+I_{y}v+I_{t}= 0 $$
A question is how many unknowns and how many equations per pixel do we have? Here, we have two unknowns \(u \) and \(v \) but only one equation per pixel.
The component of \(\left ( u,v \right ) \) that is in the direction of the gradient is something we can measure.
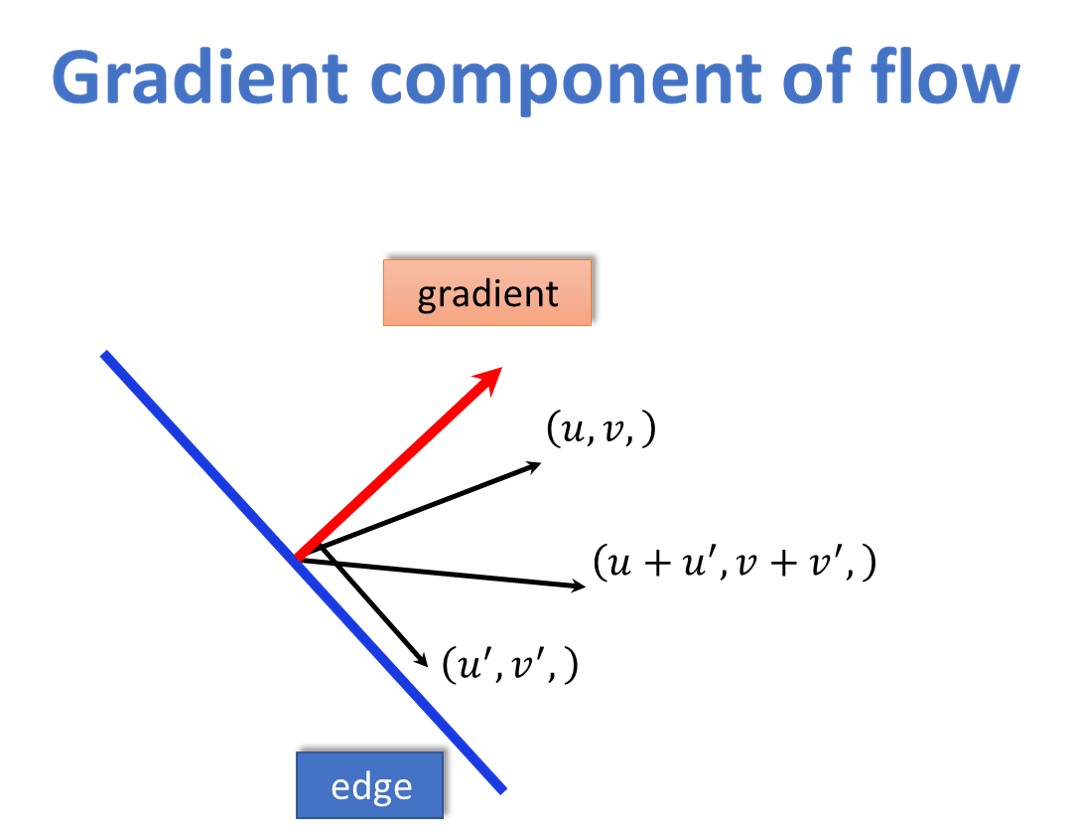
Here, we can see that this red line in the image above is in the direction of the gradient. We may suppose that we have a displacement vector \(\left ( u,v \right ) \) that needs to be determined. Also, we have a \(\left ( {u}’,{v}’ \right ) \) that is an extra component parallel to the edge. This new vector \(\left ( u+{u}’,v+{v}’ \right ) \) has the same amount perpendicular to the edge and in the direction of the gradient but a different amount along the edge. Locally we can only determine the amount of motion that is perpendicular to the edge in a local neighborhood. We can think of it as looking through a hole. That is called an aperture and this general problem is called the aperture problem.
Aperture Problem
Now, let’s see this interesting example. It is a line with two parts. Notice that it has a corner. In the following example it is moving down and to the right:

Let us put an aperture over the line. If we can observe only the green area we will get a wrong impression that the line is moving in the direction perpendicular to the edge.

Next, if we are observing the movement of the line through a yellow area we can estimate the movement accurately.

That is the aperture problem. We can only tell the motion locally in the direction perpendicular to the edge.
Solving the Aperture Problem
Now we are going to solve the aperture problem. To do this we have to impose additional local constraints in order to get more equations per pixel. For example, we will assume that in a local area of one pixel, the motion field is very smooth. In fact, we assume that in a small rectangular window around this pixel, the value is the same for every \(\left ( u,v \right ) \). For example, if we have a \(5\times 5 \) window, there are \(25 \) pixels in that window. Now, if we were assuming that there was one \(\left ( u,v \right ) \) for all of these the \(\left ( u,v \right ) \) for the center pixel, that would give us \(25 \) equations per pixel. Here they are:
$$ 0= I_{t}\left ( p_{i} \right )+\bigtriangledown I\left ( p_{i} \right )\cdot \begin{bmatrix}u & v \end{bmatrix} $$
$$ \begin{bmatrix}I_{x}\left ( p_{1} \right ) & I_{y}\left ( p_{1} \right )\\ I_{x}\left ( p_{2} \right )& I_{y}\left ( p_{2} \right )\\\vdots & \vdots \\I_{x}\left ( p_{25} \right ) & I_{y}\left ( p_{25} \right )\end{bmatrix}\begin{bmatrix}u\\v\end{bmatrix}= -\begin{bmatrix}I_{t}\left ( p_{1} \right )\\I_{t}\left ( p_{2} \right )\\\vdots \\I_{t}\left ( p_{25} \right )\end{bmatrix} $$
So we have the gradients dotted with \(\begin{bmatrix}u\\v\end{bmatrix} \) and that equals the negative of the temporal derivatives at each of those points. We can write this as:
$$Ad= b $$
where \(d \) is this displacement vector \(\begin{bmatrix}u\\v\end{bmatrix} \) and \(b \) is just this \(25\times 1 \) vector that is essentially the negative of all the temporal derivatives. So we have \(25 \) equations and \(2 \) unknowns.
The question is how do we solve a system when we have more equations than unknowns? Well, we will apply the least-squares approach and in that way, we will minimize the squared difference.
$$ Ad= b\rightarrow minimize\left \| Ad-b \right \|^{2} $$
$$ \left ( A^{T}A \right )d= A^{T}b $$
The way we do that is by using the standard pseudo-inverse method. So, we multiply \(A \) by \(A^{T} \) and we end up with this equation:
$$ \begin{bmatrix}\sum I_{x}I_{x} &\sum I_{x}I_{y} \\ \sum I_{x}I_{y}& \sum I_{y}I_{y}\end{bmatrix}\begin{bmatrix}u\\ v\end{bmatrix}= -\begin{bmatrix}\sum I_{x}I_{t}\\\sum I_{y}I_{t}\end{bmatrix} $$
These sums are calculated over the \(5 \times5 \) kernel window. This technique was first proposed by Bruce D. Lucas and Takeo Kanade way back in 1981.
Now, let’s first illustrate and visualize this solving method.

$$ I_{x}u+I_{y}v+I_{t}= 0 $$
$$ \bigtriangledown I\cdot \vec{U}+I_{t}= 0 $$
The idea is if we have a gradient in some direction (red arrows in the picture above) any \(\left ( u,v \right ) \) that’s along this blue line would be an acceptable solution.
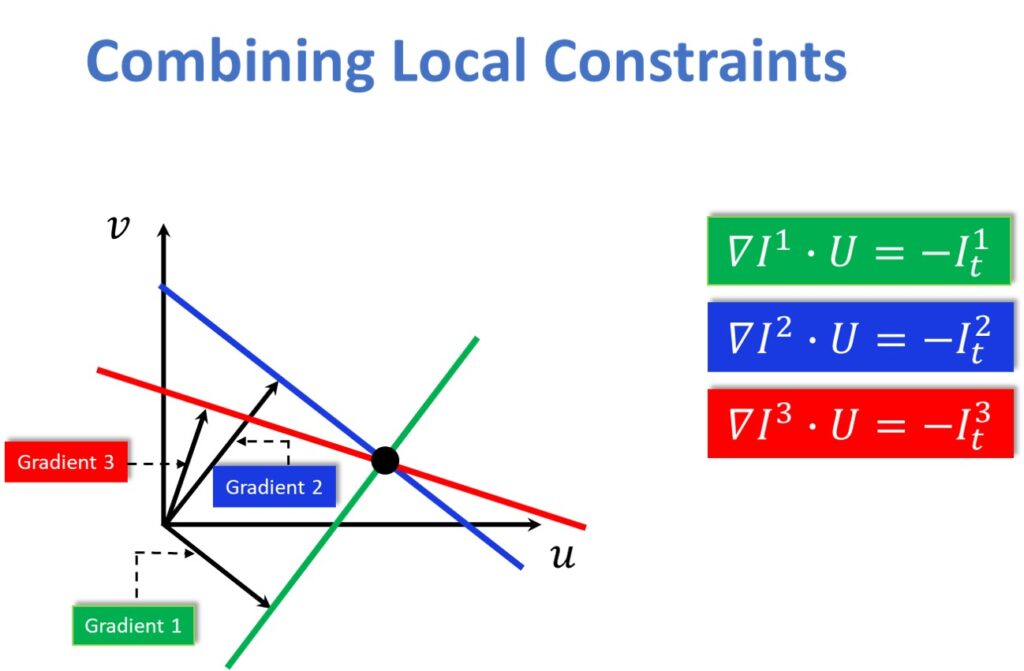
Combining Local Constraints
If we have a particular gradient in the \(\left ( u,v \right ) \) space, that gives us a single line. In the image below we can have a green line for the gradient vector 1. Next, we can have another gradient that is present in the same kernel window (5×5). For instance, it can be a gradient 2 – blue line. Moreover, we can have another gradient 3 that we connect with the red line. So, a solution for (u, v) should lie on these lines and it will be at the point of their intersection. This is illustrated in the image below.
RGB Version
If we are actually working with \(RGB\) images, we would have \(75\) instead of \(25 \) equations. That is, we have \(5\times 5\times 3 \), where 3 is the number of channels.
$$ 0= I_{t}\left ( p_{i} \right )\left [ 0,1,2 \right ]+\bigtriangledown I\left ( p_{i} \right )\left [ 0,1,2 \right ]\cdot \left [ u,v \right ] $$
$$ \begin{bmatrix}I_{x}\left ( p_{1} \right )\left [ 0 \right ]& I_{y}\left ( p_{1} \right )\left [ 0 \right ]\\ I_{x}\left ( p_{1} \right )\left [ 1 \right ]&I_{y}\left ( p_{1} \right )\left [ 1 \right ] \\ I_{x}\left ( p_{1} \right )\left [ 2 \right ]&I_{y}\left ( p_{1} \right )\left [ 2 \right ] \\\vdots & \vdots \\ I_{x}\left ( p_{25} \right )\left [ 0 \right ] &I_{y}\left ( p_{25} \right )\left [ 0 \right ] \\I_{x}\left ( p_{25} \right )\left [ 1 \right ] & I_{y}\left ( p_{25} \right )\left [ 1 \right ]\\ I_{x}\left ( p_{25} \right )\left [ 2 \right ] & I_{y}\left ( p_{25} \right )\left [ 2 \right ]\end{bmatrix}\begin{bmatrix}u\\ v\end{bmatrix}= \begin{bmatrix}I_{t}\left ( p_{1} \right )\left [ 0 \right ]\\I_{t}\left ( p_{1} \right )\left [ 1 \right ]\\I_{t}\left ( p_{1} \right )\left [ 2 \right ]\\\vdots \\I_{t}\left ( p_{25} \right )\left [ 0 \right ]\\I_{t}\left ( p_{25} \right )\left [ 1 \right ]\\I_{t}\left ( p_{25} \right )\left [ 2 \right ]\end{bmatrix} $$
We might say that our window was only a single pixel and then we had one equation and two unknowns but with \(RGB\) we now have three equations and two unknowns. Well, we can’t solve it. The problem is that the \(RGB\) images are quite correlated so we can’t just use the different color planes in order to solve it.
5. Lucas Kanade in Python
Now, after a lengthy theoretical overview, it is a perfect time to start with the code. We will show how to use Lucas Kanade using OpenCV in Python.
First, we will import the necessary libraries.
import cv2
import numpy as np
from google.colab.patches import cv2_imshow
# params for ShiTomasi corner detection
feature_params = dict( maxCorners = 100,
qualityLevel = 0.3,
minDistance = 7,
blockSize = 7 )
# Parameters for lucas kanade optical flow
lk_params = dict( winSize = (15,15),
maxLevel = 3,
criteria = (cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 0.03))As the first step, we will need to detect feature points. We will detect them in the initial frame (prev), that is, in the grayscale image (prevgray – first frame of the video transformed to a grayscale image). To do this, we will use a function called cv2.goodFeaturesToTrack(). It is an implementation of the Shi-Tomasi corner detector (an extension of the Harris corner detector). A nice property of this function is that we can specify a maximal number of feature points that we want to detect and track. Here, we will detect a maximum of 100 points.
We can visualize them in the following image.

cap = cv2.VideoCapture('cars.mp4')
# Take first frame and find corners in it
ret, prev = cap.read()
fourcc = cv2.VideoWriter_fourcc('M','J','P','G')
out = cv2.VideoWriter('output.avi', fourcc, 29, (1280, 720))
prevgray = cv2.cvtColor(prev, cv2.COLOR_BGR2GRAY)
p0 = cv2.goodFeaturesToTrack(prevgray, mask = None, **feature_params)
# Create a mask image for drawing purposes
mask = np.zeros_like(prev)
The next step is to use these points (p0), feed them to Lucas Kanade algorithm and track them (p1).
The function Lucas Kanade is implemented as cv2.calcOpticalFlowPyrLK(). It calculates an optical flow for a sparse feature set using the iterative Lucas-Kanade method with the pyramid. It uses the following parameters:
Parameters for the function cv2.calcOpticalFlowPyrLK(prevImg, nextImg, prevPts, nextPts):
- prevImg – The first 8-bit input image.
- nextImg – Second input image of the same size and the same type as prevImg.
- prevPts – Vector of 2D points for which the flow needs to be found.
- winSize – The size of the search window at each pyramid level.
- maxLevel – 0-based maximal pyramid level number; if set to 0, pyramids are not used (single-level). On the other hand, if set to 1, two levels are used. If pyramids are passed to input then the algorithm will use as many levels as pyramids have but no more than maxLevel.
- criteria – parameter, specifying the termination criteria of the iterative search algorithm.
Return:
- nextPts – Output vector of 2D points containing the calculated new positions of input features in the second image.
- status – Output status vector. Each element of the vector is set to 1 if the flow for the corresponding features has been found. Otherwise, it is set to 0.
- err – Status output vector of errors. Each element of the vector is set to an error for the corresponding feature. If the flow wasn’t found then the error is not defined (use the status parameter to find such cases).
This function accepts two grayscale images: prev and next. The set of detected data points are stored in the p0. Using indexing we can access the data points and check their shape.
# Note the shape of the p0 variable and how we can access the data points
print(p0.shape)
print(p0[0][0][0])
print(p0[0][0][1])Output:
(100, 1, 2)
981.0
390.0
The goal of the function is to return the coordinates of the initial feature points that are detected and tracked in the subsequent image p1 within the next image frame.
while (cap.isOpened()):
ret, frame = cap.read()
if ret == True:
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# calculate optical flow
p1, st, err = cv2.calcOpticalFlowPyrLK(prevgray, gray, p0, None, **lk_params)
# Select good points
good_new = p1[st==1]
good_old = p0[st==1]
# drawing
for i,(new,old) in enumerate(zip(good_new,good_old)):
a,b = new.ravel()
c,d = old.ravel()
mask = cv2.line(mask, (a,b),(c,d), (0,0,255), 2)
frame = cv2.circle(frame,(a,b),5, (0,0,255),-1)
img = cv2.add(frame,mask)
#cv2_imshow(img)
# Now update the previous frame and previous points
prevgray = gray.copy()
p0 = good_new.reshape(-1,1,2)
out.write(img)
else:
break
out.release()
cap.release()The image/video quality and the distinctiveness of the feature points will determine the accuracy of the tracking.
In case that we have a noisy video and feature points that are not distinctive (e.g. “not clear corners”), the LK algorithm can easily fail, so do not be surprised if that happens.
The final practical step of this experiment is to loop over the whole video and to iteratively call LK algorithm. In addition, it will be necessary to update a set of the tracked points. This is done within the statement p0 = good_new.reshape(-1,1,2) where we additionally adjust the shape of this array.
The other parts of the code are mainly used for visualizations. You can figure out on your own how we managed to add tracked points onto the final output video (e.g. dummy image mask)
At the end, we will visualize this process over the whole video sequence.

The connected points show the “movement of the car”. On the other hand, there are other detected points that are static. The LK detects that there are no displacements for these points.
Summary
In this post, we explained how to apply the Lucas Kanade method to detect moving objects in a video. It is a commonly used differential method for optical flow estimation. This method assumes that the flow is a constant in a local neighbourhood of the pixel and solves the basic optical flow equations for all the pixels in that neighbourhood.
References:
[1] Introduction to Motion Estimation with Optical Flow by Chuan-en Lin