#029 CNN Yolo Algorithm
YOLO ALGORITHM
In this post, we will finish with the theory behind object detection. We will combine last few posts together to complete the \(Yolo \) object detection algorithm.
As the first step, let’s see how we can construct our training set. Let’s suppose that we are trying to train an algorithm to detect three objects: pedestrians, cars and motorcycles. In addition, we will need to explicitly define the background class, so we just have \(3 \) class labels.

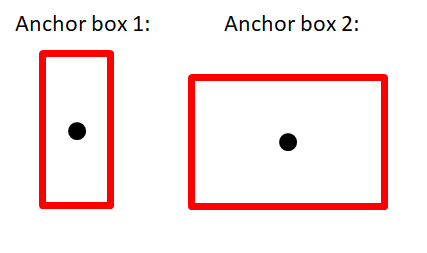
For instance, we are using \(2 \) anchor boxes (these anchor boxes are presented in the above picture). This means that our output \(y \) will be \(3\times3\times2\times8 \). The dimension \(3\times 3\) comes from the size of grid cell that we have applied on our input image.
In every grid cell, we use \(2 \) anchor vectors and each anchor vector is described with \(8 \) parameters (numbers). These \(8 \) parameters are :
| \(p_c \) | probability that there is an object in that particular cell |
| \(b_x, \enspace b_y \) | position of center of the object |
| \(b_h,\enspace b_w \) | the size of the bounding box |
| \(c_1, \enspace c_2, \enspace c_3 \) | labels for our \(3 \) classes |
To create a training set we go through each of these \(9 \) grid cells, and we form the corresponding target vector \(y\). In the first grid cell (purple), none of the object classes is present. Hence, for the value of the class presence for both anchors we will have zero values. Subsequently, we are not interested in the remaining vector values. Next, the target \(y \) corresponding to that grid cell will be:
$$ y = \begin{bmatrix} 0\\?\\?\\?\\?\\?\\?\\?\\0\\?\\?\\?\\?\\?\\?\\ \end{bmatrix} $$
For the majority of the grid cells, as there are no objects of interest inside them, we will have the same values for the output target vector.
On the other hand, for the grid cell marked in green, we will have the target vector \(y \) where for the first anchor box we have zeros, but for the second one we have specific values both for the membership of the class as well as for the bounding box values (marked in red).
Anchor boxes
If we assume that the anchor boxes have tall and wide shape, our car will be assigned to the anchor box 2, which slightly better fits the shape of the car in the image. If you ask yourself which anchor box should you choose, an easy way is just to check which one has the higher Intersection over Union (\(IoU\)) with an ideal object box. Notice then that \(p_c \) associate anchor box \(1\) is equal to \(0\), so we don’t care for the rest of the values. For the ancor box \(2\), \(p_c=1 \) because we detected a car with this anchor box. So, we go through this and for each of our \(9 \) grid positions ( \(3\times3 \) grid positions ) we will create a \(16 \) dimensional vector.
So, this was a training phase! We train a \(convnet \) that inputs an image, for example a \(100\times100\times3 \) image and our \(convnet \) will output this output \(3\times3\times16\) or \(3\times3\times2\times8\) volume.
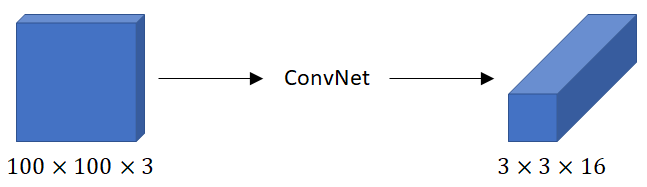
The color image is of \(100\times100\times 3\) dimensional and it is an input of a \(Convnet \). The output is as we explained \(3\times3\times 16 \)
Next, let’s have a look at how our algorithm can make predictions.
For a given input image, our neural network will output this \(3\times3\times2\times8\) volume where for each of the \(9 \) grid cells we get one vector.
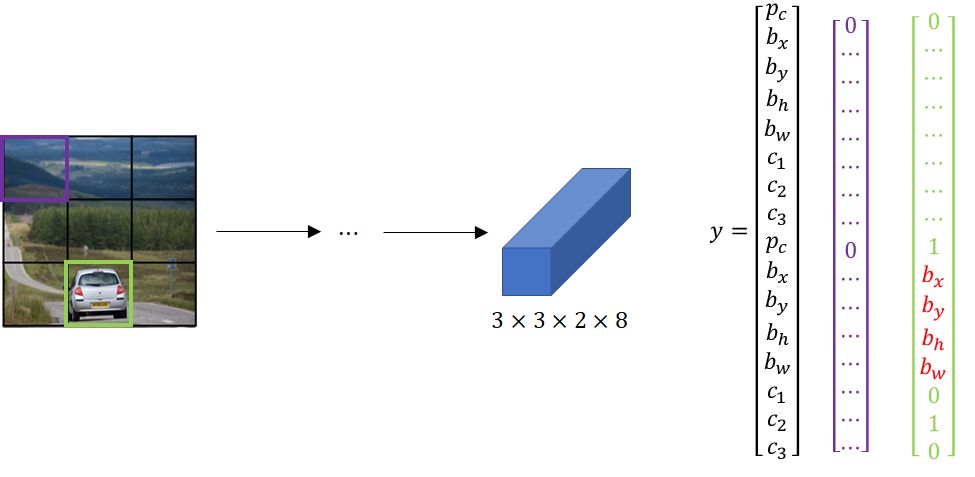
Picture is divided with a \(3 \times 3 \) grid cell. It is an input to the \(convnet \). On the right, there are two examples of the output vectors for each cell. The general form of the output for one grid cell is represented as the first vector \(y\). The output vector of the grid cell where we don’t have an object is the second one and the output of a cell where we have a car detected with anchor box $2 is the third vector
In the picture above, in the upper left grid cell (which is painted in purple) there is no object and our neural network will output \(p_c = 0 \) for both anchor vectors. We will say that we don’t care for the other values (a purple vector corresponds to a purple bounding box).
How do we run a non-max suppression?
In this step we will explain with a new test image. If we are using \(2 \) anchor boxes, then for each of the \(9 \) grid cells we will get two predicted bounding boxes. Some of them will have a very low probability that there is an object in them, so very low \(p_c \). For example, we have these bounding boxes in the picture below. Notice that some of the bounding boxes can go outside the grid cell it came from. Here we have two bounding boxes for each object, so we need to get rid of wrong ones and preserve only one bounding box. In order to do this, we run a \(Non-max \enspace suppression \).

Examples for \(Non-max \enspace suppression \); each object is detected with 2 Anchor boxes, but probabilities \(p_c \) are different (left); a result when we apply a \(Non-max\enspace suppression \) (right)
Next, we get rid of the low probability predictions. For example, we can try to detect \(3\) classes, pedestrians, cars, and motorcycles. What we do is for each of the \(3\) classes, we run non-max suppression independently, after which we have the final predictions. And the output of this is hopefully that we will have detected all the cars and all the pedestrians in this image.
\(YOLO \) object detection algorithm is one of the most effective object detection algorithms in computer vision. In the following post, we will implement this idea of \(Yolo\) algorithm.