#001B Deep Learning, wait but why now?
Deep Learning, wait but why now?
If the basic technical idea behind deep learning neural networks has been around for decades, why are they only now taking off?
To answer this question, we plot a figure where on the x-axis we plot the amount of labelled data we have for a task, and on the y-axis, we plot the performance of our learning algorithm (accuracy).
For example, we want to measure the accuracy of our spam classifier or the accuracy of our neural net for figuring out the position of other cars for our self-driving car.
If we plot the performance of traditional learning algorithms such as Support Vector Machine or Logistic Regression as a function of the amount of data we will get the following curve:
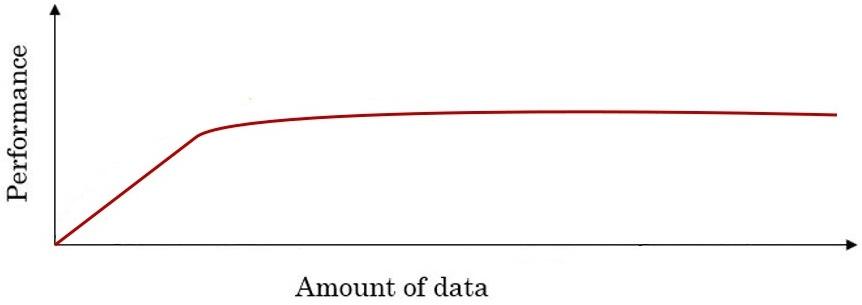
How to overcome the performance plateau problem?
In this regime of smaller training sets, the relative ordering of the algorithms is not very well defined.
Often, skill at hand engineering features is what determines performance!
Over the last 20 years, we accumulated a lot more data than traditional learning algorithms were able to effectively take advantage of. Enormous amount of human activity is now in the digital realm where we spend so much time on internet.
With neural
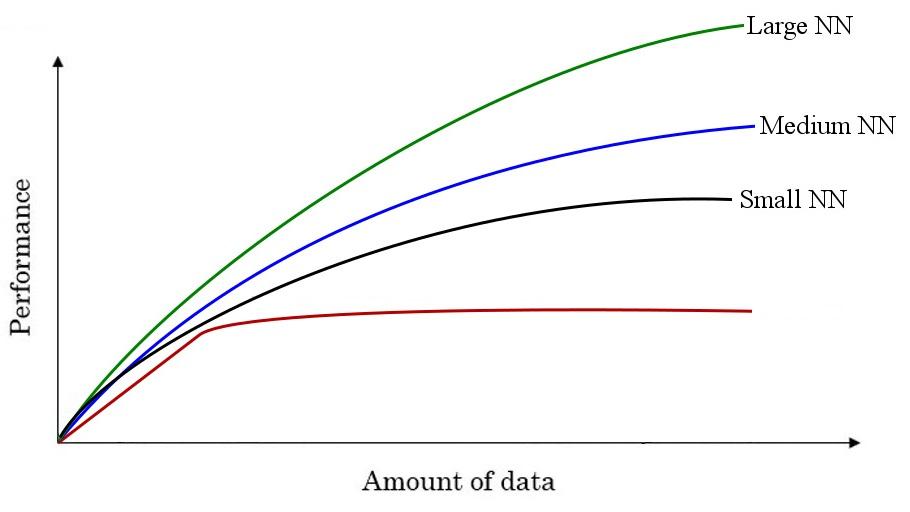
In the early days in the modern rise of deep learning, it was a scale of data and a scale of computation constraints which limited our ability to train very large neural networks on either a CPU or a GPU. But relatively recently, there have been tremendous algorithmic innovations that make neural networks run much faster.
For example, switching from a
Let’s look in more detail why switching from sigmoid to ReLU function did so well on neural network performance.
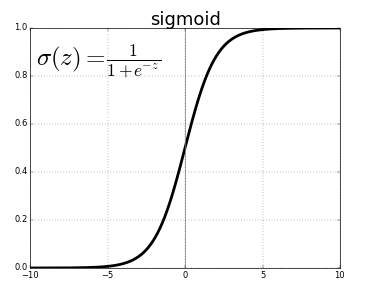
One of the problems of using sigmoid functions in machine learning arises in these regions: >5 and <-5. Here, the slope of the function of a gradient is nearly zero. That is, learning becomes slow when gradient descent is implemented.
When the gradient is nearly zero, the parameters change very slowly, yielding to very slow learning. If a gradient is zero parameters won’t change.
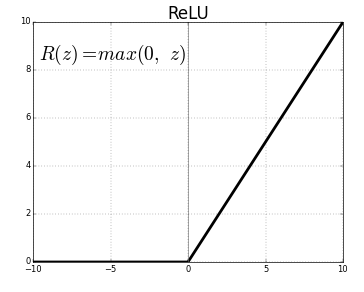
For the Rectified Linear Unit function, the gradient is equal to 1 for all positive values of input. The gradient is much less likely to gradually shrink to 0, and the slope of the line on the left is 0. In the end, just by switching from the sigmoid function to the ReLU function has made an algorithm called gradient descent to work much faster.
To conclude, often you have an idea
An entire deep
More resources on the topic:
For more resources about deep learning, check these other sites.