#001 GANs – Introduction To Generative Models

Highlights: In the last few years, Generative Adversarial Networks (GANs) have gained a lot of attention in both research and engineering circles. Generative Models of today are what Conv Nets were 4 to 8 years ago. We might say they are the trend these days.
In this tutorial, we will learn how and why GANs became this popular, their brief history, and their evolution over the past three decades. So let’s begin!

The face generation process that uses generative modeling has improved significantly in the last four years
Tutorial Overview:
- The Popularity Of GANs
- Historical Methods & Related Problems
- Existing Methods
- Cocktail Party Problem
- Problem With Existing Methods
- The Deep Learning Revolution
1. The Popularity of GANs
In a recent meme fest on the internet, we saw the former president of the United States, Barrack Obama, addressing the nation in a video. While that video was a glorious application of what we know as a ‘Deepfake Video’, it was practically impossible for a human to point out that it was a fraud. Such realistic videos that go viral are made using Generative models, which are Deep Learning-based approaches categorized under Unsupervised Learning.
Have a look at the video below which shows how a Deepfake Video can stump even the keenest observers.
Many such GAN applications have gained the attention of not only AI researchers but also of the broader AI community. Take the example of the fake face generator developed by NVIDIA, which was, without a doubt, fascinating but also a little scary. A LinkedIn CTO took offense to this and a new war against fake accounts began.

Reference: https://arxiv.org/abs/1812.04948
Some not-so-scary applications such as super-resolution colorization and restoration videos also became popular alongside some of these ‘Oldify’ video editing methods as shown below.
Looking at the pros of GANs, companies that develop photo editing software have started to welcome the development of such models as these help in effectively reducing human effort through automation.
Have a look at the snapshot below which shows the first AI painting to be auctioned for a whopping 432,500 USD. Isn’t it amazing how powerful and capable a GAN-enabled software can be?
https://twitter.com/ChristiesInc/status/1055479790361370624

This AI-generated self-portrait posed a valid question – Whose work is this really? Does the researcher who developed the AI model and trained GAN holds true ownership of this painting? Or is it the user who generated this painting using the technology and auctioned it? We are still debating this question.
Now let’s look at another interesting case wherein even the big players are joining the race. NVIDIA came up with its own self-generated scenery software, which is so sophisticated that it can generate photo-realistic images using simple inputs such as paintbrush sketches. Have a look.
This is an exciting new technology for sure. Back in 2014, when AI researchers including Ian Goodfellow introduced the use of GANs, it attracted many AI startups and companies. It started slow because it is usually built on advanced mathematics but it is catching up fast with practitioners, coders, and researchers across all sectors, as it matures and grows with time.
GAN has the power to shake our everyday reality. Due to the malicious applications involved with this technology, steps need to be taken to enforce its ethical use. For instance, the state of California expressed its concern regarding the creation of fake political news, especially the ones that came up 60 days prior to the election. A law prohibiting such activities was issued and it was directed to the creators of fictional content like this to specifically state that an image, audio, or video has been manipulated.
Let us understand how GANs originated and how they have evolved over time.
2. Historical Methods & Related Issues
Existing Methods
Well-known methods such as Principal Component Analysis (PCA) and their application in dimensionality reduction, have existed since the year 1901. They were extensively used for the detection of underlying generating principles within data before GANs came along.
Herein, the original coordinates are transformed to preserve the relation between data samples. The goal is to reduce the needed number of components to analyze them.
For instance, imagine that you’re trying to make a shadow puppet. You can think of a 3D model made by the hands and try to recognize the sign gesture demonstrated. This is happening in 3D, so we need three dimensions. And yet, we can project a shadow of the hands onto a wall as well with the help of a light. The wall is now a 2D space and the image also becomes two dimensional. Moreover, from this image, we can still conclude what the sign gesture is if we position the hands carefully enough, as shown below.

Apart from PCA, there are other sophisticated methods that exist such as Independent Component Analysis (ICA). This field of research was very active from the 1990s and into the 2000s. Several algorithms have been developed and are still quite popular viz. InfoMax, SOBI, JADE, robustICA, fastICA among others. These methods can be seen as tools for solving the so-called ‘Cocktail Party Problem.’
Cocktail Party Problem
Let’s say we put three microphones in a room, at different locations. The room is quite noisy with people talking, piano playing, breaking news on the TV running in the background.
Now, each microphone starts recording different mixtures of these noises depending on their respective proximity to the noise source and the loudness of the source. For instance, a microphone next to the piano will get the piano tune as the dominant sound. On the other hand, it will also capture the chatter noises of people talking.
Using Independent Component Analysis (ICA), we can use these microphone recordings, process them and accurately extract original sound sources. Have a look at the video below to get a deeper understanding and develop better intuition pertaining to the Cocktail Party Problem.
In other fields, such as face analysis and synthesis, there are many different methods that were used prior to the year 2010. for face image decomposition and generation. You can check this amazing comparison between these methods as an official scikit library tutorial. These results were interesting, but far from perfect or realistic.
Problem With Existing Methods
All these methods were what we nowadays call “shallow”. They were mainly linear (or nonlinear) and didn’t compress the information in the images as efficiently as it can be done nowadays. Neural Networks are a great solution but in the first decade of the 21st century, they were almost a taboo topic to discuss as Support Vector Machines were dominating the scene at that time.
3. The Deep Learning Revolution
You know the story of the Deep Learning revolution that took place starting in 2012 (Alex net paper).
It allowed more complex visual features to be captured and expressed by using a higher number of convolutional layers stacked together in Conv nets. In a similar way, this allowed autoencoders to extract significant features from an image and create the so-called latent variables.
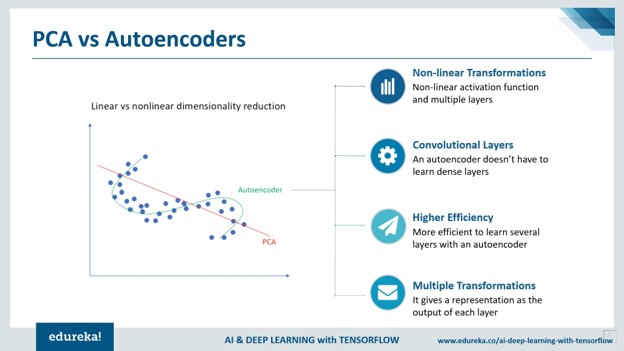
For instance, from MNIST or face dataset we can generate new latent variables. To some extent, you may think that the benefit of deep convolutional architectures is that you can better compress the information in the images, compared to the shallow models such as PCA or ICA. Have a look at the image that shows a comparison between PCA and Autoencoders.
So this was our blog post on a historic overview of generative models such as GANs. In the following posts we will go deeper into Generative Modeling, Variational Autoencoders, GANs and more of their latest applications. These topics are a bit advanced and require some basic Data Science Python programming skills. But don’t worry, Data Hacker is here to help you!
In case you need to master or refresh your skills, we highly recommend the following literature:
- Data Science Handbook:: Jake VanderPlas
- Deep Learning Coursera course:: Andrew NG
- Machine learning an algorithmic approach pdf
In addition, dataHacker.rs has similar tutorials so that you can easily grasp these concepts.
Before you go, let’s do a quick recap.
Introduction To Generative Models
- Generative Adversarial Networks (GANs) are extremely popular with their photo-editing applications
- Deepfake videos use generative models to create realistic transformations of faces
- There are many pros and cons of using GAN technology
- Earlier methods such as PCA and ICA were used before Autoencoders came into the picture
- These previous methods were shallow and not as efficient as the Deep Learning methods
Summary
That’s it, folks! We hope you enjoyed the start of a pretty interesting series on Generative Models. Many more tutorial posts will be posted in the coming weeks. So stay around and keep an eye out for our notification. In case you have any doubts or questions to ask us, feel free to drop a message in the comments section. We’ll see you next time. Take care 🙂