LLMs Scratch #001 Introduction to LLMs and tokenization
Introduction to Large Language Models: From Scratch (Part 1)
🎯 What You’ll Learn
In this comprehensive introduction to large language models, we’ll explore why efficiency at scale is just as critical as raw compute power, showing how algorithmic improvements have outpaced Moore’s Law by 44X. You’ll understand why the “bitter lesson” is misunderstood, learn the critical difference between small and large-scale phenomena, trace the fascinating evolution from Shannon’s entropy estimates through Google’s massive N-gram models to the transformer revolution, and discover which knowledge transfers from small to large scale (and which doesn’t). This is about understanding every atom of how these systems work.
Tutorial Overview
- Why Build Language Models from Scratch?
- The Problem: Frontier Models are Out of Reach
- What You Can (and Can’t) Learn at Small Scale
- The Bitter Lesson – Misunderstood
- The Critical Role of Efficiency at Scale
- A Journey Through Language Model History
- The Open Source Movement
- Modern Architecture Improvements
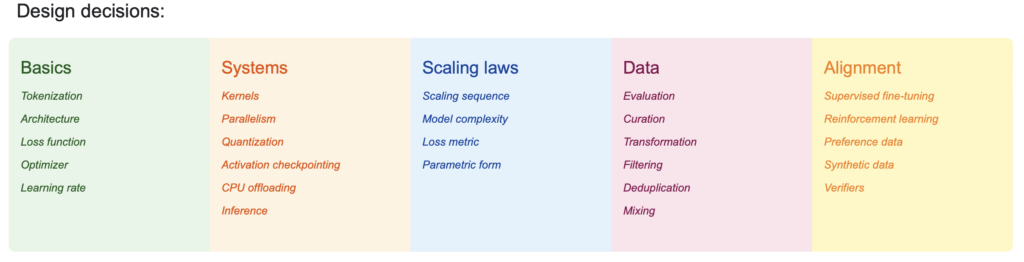
- Training Design Decisions
- The Systems Perspective
1. Why Build Language Models from Scratch?
The Core Philosophy
You have to build it from scratch to understand it. Learn by doing. This philosophy drives the entire approach to learning Large Language Models. While abstractions like prompting have unlocked enormous research progress, these abstractions are leaky – especially when it comes to LLMs where it’s just “string in, string out.”
The key insight: Fundamental research requires full understanding of the technology stack. You can’t rely on black boxes for innovation. Co-designing data, systems, and models requires carrying up the entire stack.
🔴 Why Abstractions Aren’t Enough
In contrast to programming languages or operating systems, you don’t really understand what the LLM abstraction is. There’s still a lot of fundamental research to be done that requires co-designing different aspects of the data, systems, and model.
Full understanding of this technology is necessary for fundamental research. That’s why building from scratch matters.
2. The Problem: Frontier Models are Out of Reach
The Industrialization of Language Models
💰 The Scale is Mind-Blowing
- GPT-4: Rumored to be 1.8 trillion parameters, cost $100 million dollars to train
- XAI: Building clusters with 200,000 H100s
- Investment: Over $500 billion over four years
- The catch: Zero public details on how they’re built
🔒 The Secrecy Problem
From OpenAI’s GPT-4 report (2022):
“Due to the competitive landscape and safety limitations, we’re going to disclose no details.”
This is the state of the world right now. Frontier models are out of reach – both in terms of compute requirements and information availability.
3. What You Can (and Can’t) Learn at Small Scale
The Challenge
When you build small language models, these might not be representative of large-scale behavior. Here are two critical examples that illustrate why.
🎯 Example 1: The Attention vs MLP Paradox
If you look at the fraction of FLOPs spent in attention layers versus MLP layers, this changes dramatically with scale:
- Small models: Attention and MLP layers use roughly comparable FLOPs
- 175B models: The MLP really dominates

Why this matters: If you spend time at small scale optimizing attention, you might be optimizing the wrong thing because at larger scale, it gets washed out. This is napkin math you can do without any computers, but the implications are huge.
⚡ Example 2: Emergent Behavior
Jason Wei’s 2022 paper showed something harder to predict: as you increase training FLOPs and look at accuracy on various tasks, for a while nothing happens. Then suddenly, you get emergent phenomena like in-context learning.
The problem: If you were at small scale, you’d conclude these language models don’t work – when in fact, you just need to scale up to see the behavior emerge.
📚 The Three Types of Knowledge
So what can we actually learn at small scale? We have to be precise about three types of knowledge:
✅ 1. Mechanics (Fully Teachable)
The mechanics of how things work – this is fully teachable:
- How BPE tokenizer works
- How transformers work
- How cross entropy loss works
- How Adam optimizer works
These transfer perfectly from small to large scale.
⚠️ 2. Priorities (Partially Transferable)
These can be misleading:
- The FLOP breakdown changes
- Which optimizations matter changes
- Where bottlenecks occur can shift
Be careful – what matters at small scale might not matter at large scale.
❓ 3. Phenomena (Unpredictable)
These are the most exciting and frustrating:
- When does in-context learning emerge?
- What capabilities appear at scale?
- How do complex behaviors develop?
You can’t predict these from small-scale experiments. They just emerge.
4. The Bitter Lesson – Misunderstood
What Rich Sutton Actually Said
Rich Sutton’s 2019 essay “The Bitter Lesson” has been widely cited, but often misunderstood. Here’s what he actually argued:
The thesis: General methods that leverage computation are ultimately most effective. Trying to build in human knowledge doesn’t work.
Examples given:
- Computer Chess: Attempts to build in human chess-playing knowledge didn’t work as well as search
- Computer Vision: Methods based on general principles (deep learning) worked better than hand-crafted features
🔴 The Misinterpretation
What people incorrectly conclude: “Just scale. Nothing else matters.”
Why this is wrong: Scale doesn’t mean algorithms don’t matter. In fact, algorithmic improvements are just as important – if not more important – than raw compute scaling.
The bitter lesson says that general methods that leverage computation win – not that computation alone wins.
5. The Critical Role of Efficiency at Scale
🚀 The Real Story: Algorithms Matter Just as Much as Compute
A 2020 Hernandez paper from MIT and Epoch AI measured how much effective compute has changed – not just the raw hardware, but the efficiency of algorithms.
The Mind-Blowing Numbers
The key insight: From 2012 to 2019, algorithmic improvements gave you 44X efficiency gains. Moore’s Law only gave you 2.5X from hardware. Combined: 110X improvement!
Algorithmic improvement outpaced Moore’s Law by more than an order of magnitude.
What This Means in Practice
To train ImageNet to the same accuracy:
- 2012: Took months of GPU time
- 2024: Takes 47 seconds on a single GPU
That’s not because GPUs got faster (though they did). It’s mostly because algorithms got better.
This is the real lesson: Algorithmic efficiency at scale is just as critical as raw compute power. Scale alone doesn’t solve everything – you need smarter algorithms too.
6. A Journey Through Language Model History
The Early Days
Language models have been around for a while. Going back to Shannon, who looked at language models as a way to estimate the entropy of English. In AI, they were prominent in NLP as components of large systems like machine translation and speech recognition [Brants, 2007].
💥 Fun Fact: Google’s 2007 N-gram Models
One thing that’s not as appreciated these days: in 2007, Google was training 30 large N-gram models. These were five-gram models over two trillion tokens – which is a lot more tokens than GPT-3!
We only got back to that token count in the last two years. But they were N-gram models, so they didn’t exhibit any of the interesting phenomena we know from language models today.
The 2010s: When All the Pieces Came Together
In the 2010s, the deep learning revolution happened and all the ingredients started falling into place:
- 2003: First neural language model from Bengio and colleagues’ group
- Seq2seq models: How to model sequences from Ilya and Google folks
- Adam optimizer: Still used by the majority of people, dating over a decade ago
- Attention mechanism: Developed for machine translation, leading to “Attention is All You Need” – the transformer paper in 2017
People were also looking at:
- How to scale mixture of experts
- How to do model parallelism
- How to train 100 billion parameter models
All the ingredients were in place by 2020.
The Rise of Foundation Models
Another important trend: foundation models that could be trained on lots of text and adapted to a wide range of downstream tasks.
ELMO, BERT, T5 – these were models that were, for their time, very exciting. We maybe forget how excited people were about BERT, but it was a big deal.
🏆 OpenAI’s Critical Contribution
This is abbreviated history, but one critical piece: OpenAI took all these ingredients, applied very nice engineering, and really pushed on the scaling laws – embracing it as the mindset piece.
This led to GPT-2 and GPT-3. Google was competing too, but OpenAI nailed the scaling mindset.
7. The Open Source Movement in Language Models
From Closed to Open
GPT-2 and GPT-3 were closed models – not released, only accessible via API. But this sparked an open model revolution starting with Eleuther right after GPT-3 came out.
Then came Meta, Alibaba, DeepSeek, AI-2, Bloom, and others – creating open models where the weights are released.
Understanding Different Levels of Openness
There are many levels of openness:
🔴 Closed Models
- Like GPT-4
- No weights released
- API access only
- Zero transparency
🟡 Open Weight Models
- Weights available
- Architectural details in paper
- But no dataset details
- Partial transparency
🟢 Open Source Models
- All weights and data available
- Paper tries to explain everything
- Maximum transparency
- But: can’t capture everything in a paper
There’s no substitute for learning how to build except for doing it yourself.
Today’s Frontier Model Landscape
Today there’s a whole host of frontier models from OpenAI, Anthropic, XAI, Google, Meta, DeepSeek, Alibaba, Tencent and others.
We’re going to revisit these ingredients and trace how these techniques work. Then try to get as close as we can to best practices on frontier models, using information from the open community and reading between the lines from what we know about closed models.
8. Modern Architecture Improvements: The Details That Matter
The Core: Transformers
The starting point is the original transformer – the backbone of basically all frontier models. It has attention layers, MLP layers, and normalization.
A lot has happened since 2017. There’s a sense that the transformer was invented and everyone just uses it. To a first approximation, that’s true – we’re still using the same recipe.
But there have been a bunch of smaller improvements that make a substantial difference when you add them all up.
Key Components
Tokenization
A tokenizer converts between strings and sequences of integers. Think of it as breaking up strings into segments and mapping each segment to an integer.
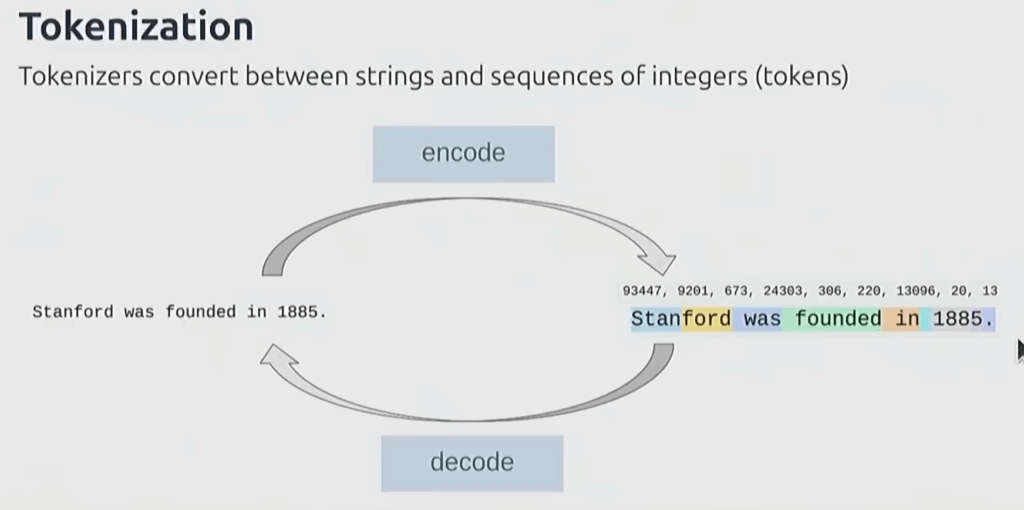
The sequence of integers goes into the model, which needs fixed dimensions.
The most common approach: BPE (Byte Pair Encoding) tokenizer – relatively simple and still widely used. There are promising tokenizer-free approaches that work with raw bytes, but they haven’t scaled to frontier yet.
Architectural Improvements
- Activation Functions: SwiGLU – a non-linear activation function
- Position Embeddings: Rotary position embeddings (RoPE)
- Normalization: RMS norm instead of layer norm – similar but simpler. Plus placement has changed from the original transformer
- MLP Variants: Dense MLP can be replaced with mixture of experts
- Attention Mechanisms: Full attention, sliding window attention, linear attention – all trying to prevent quadratic blowup. Lower dimensional versions like GQA and MLA
- Transformer Alternatives: State space models like Mamba – not doing attention but other operations. Sometimes hybrid models work best
9. Training Design Decisions That Make or Break Your Model
Key Training Decisions
Once you define your architecture, you need to train it. Design decisions include:
- Optimizer: Adam W (basically Adam fixed up) is still very prominent. More recent optimizers like Muon and SOAP show promise
- Learning rate schedule
- Batch size
- Regularization
- Hyperparameters
🔴 The Details Really Matter
You can easily have order of magnitude difference between a well-tuned architecture and something that’s just vanilla transformer.
This is where attention to detail pays off massively.
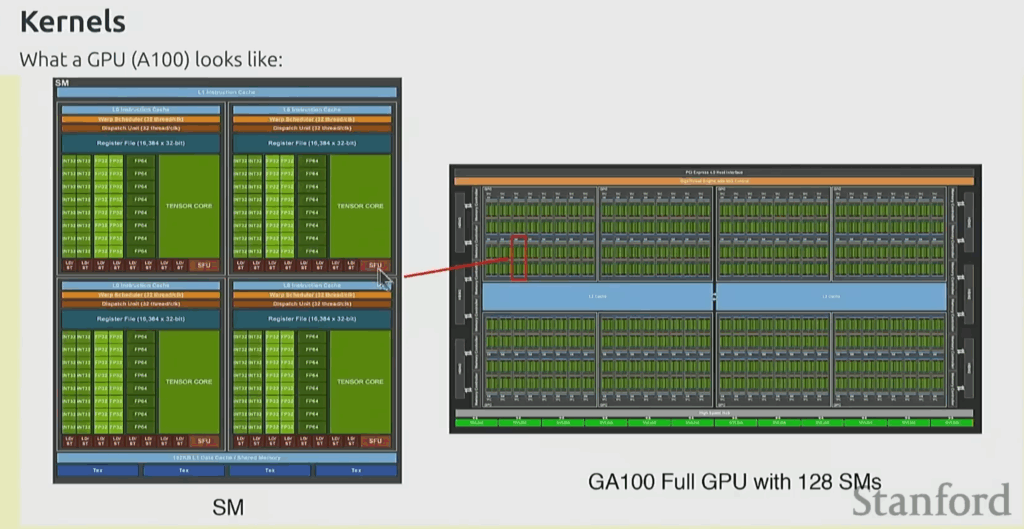
10. The Systems Perspective: Optimizing for Hardware
Getting the Most from Hardware
The systems part goes into how you optimize further – how do you get the most out of hardware? For this, we need to take a closer look at the hardware and how to leverage it.
Three key components:
- Kernels
- Parallelism
- Inference
Understanding GPU Architecture
A GPU is basically a huge array of little units that do floating point operations.
The key thing to note: the GPU chip has memory that’s actually off chip. Then there’s other memory like L2 caches and L1 caches on chip.
The basic idea: compute has to happen here, but your data might be somewhere else. How do you organize this efficiently?
This is the foundation of systems optimization for language models.
Introduction to Large Language Models: From Scratch (Part 2)
🎯 What’s Covered in Part 2
Building on the foundations from Part 1, we now dive into the practical systems and methods that make language models work at scale. You’ll learn how to implement parallelism strategies that enable training on multiple GPUs, understand the Chinchilla scaling laws that tell you the optimal model size for your compute budget, master the art of efficient benchmarking and profiling, explore the critical data pipeline decisions that make or break model quality, and implement tokenization from scratch using the BPE algorithm that powers models like GPT.
11. Systems Implementation: Parallelism and Benchmarking
Making Parallelism Work
Data parallelism is very natural when training language models – you can distribute your batch across multiple GPUs and aggregate gradients. This is the foundation of scaling training.
Model parallelism techniques like FSDP (Fully Sharded Data Parallel) are more complex to implement from scratch, but understanding the principles is crucial. In practice, you’ll implement simplified versions while learning about the full techniques.
🔴 The Most Important Practice: Benchmarking
You can implement things, but unless you have feedback on how well your implementation is going and where the bottlenecks are, you’re just flying blind.
Always benchmark and profile. This is probably the most important habit to develop. Without measurement, you can’t optimize effectively.
12. Scaling Laws: The Science of Compute Budgets
The Fundamental Question
If I give you a FLOPs budget, what model size should you use? This isn’t a trivial question – if you use a larger model, you can train on less data. If you use a smaller model, you can train on more data.
What’s the right balance? This has been studied extensively and figured out by a series of papers from OpenAI and DeepMind.
💡 Chinchilla Optimal: The 20:1 Rule
For every compute budget (number of FLOPs), you can vary the number of parameters in your model and measure how good that model is. This reveals an optimal parameter count for each level of compute.
The simple rule of thumb: If you have a model of size N parameters, multiply by 20 – that’s the number of tokens you should train on.
Example: A 1.4 billion parameter model should be trained on 28 billion tokens (1.4B × 20 = 28B).
⚠️ Important Limitation
This doesn’t take into account inference cost. The Chinchilla scaling laws tell you how to train the best model regardless of how big that model is.
In production, you often want smaller models that are cheaper to run, even if they’re slightly less accurate. Scaling laws give you the ceiling – business requirements determine where you land.
How Scaling Laws Work in Practice
The Process
The basic idea: for every compute budget, you train models with different parameter counts and plot the results. When you plot these optimal points, the relationship is remarkably linear.
You can fit a curve to this data and extrapolate. If you had, say, 1e22 FLOPs available, what should the parameter size be? The scaling laws give you the answer.
Real stakes: Once you run out of your FLOPs budget, that’s it. You have to be very careful in terms of how you prioritize what experiments to run – which is exactly what frontier labs face all the time.
13. The Data Pipeline: Where Quality Begins
🚀 Data is Everything
You’ve got scaling laws, you have systems, you have your architecture. Now comes the critical question: what data do you train on?
The Data Pipeline Components
The data pipeline involves several critical stages:
- Evaluation: How do you measure if your data is good?
- Curation: Selecting high-quality sources
- Transformation: Converting raw data into trainable format
- Filtering: Removing low-quality or harmful content
- Deduplication: Ensuring unique training examples
- Mixing: Combining different data sources in optimal ratios
Each of these stages has enormous impact on final model quality. Bad data in, bad model out – no matter how good your architecture is.
14. Tokenization: The Foundation Layer
💡 What is Tokenization?
Tokenization is the process of taking raw text (unicode strings) and turning it into a sequence of integers, where each integer represents a token.
We need procedures that:
- Encode strings to tokens
- Decode tokens back into strings
The vocabulary size is the number of unique tokens – essentially, the range of possible integer values.
How Tokenizers Actually Work
The most common approach is BPE (Byte Pair Encoding), used by GPT models. Here are some key observations from looking at real tokenizers:
- Spaces matter: Unlike classical NLP where spaces disappear, everything is accounted for. These are meant to be reversible operations.
- Space position: By convention, the space usually precedes the token. So “hello” and ” hello” are completely different tokens.
- Number handling: Numbers get chopped into pieces left-to-right, which isn’t semantic but reflects the statistical patterns in training data.
⚠️ Tokenization Quirks
The fact that “hello” and ” hello” are different tokens might make you a little squeamish. It can cause problems, but that’s how modern tokenizers work.
Why it matters: The model learns completely different representations for a word depending on whether it appears at the start of a sentence or in the middle. This affects model behavior in subtle ways.
Tokenization Metrics
Compression Ratio
An important metric is the compression ratio: the number of bytes divided by the number of tokens.
How many bytes are represented by a single token? For GPT-2’s tokenizer, the answer is approximately 1.6.
What this means: Every token represents 1.6 bytes of text on average. Higher compression ratios mean more efficient encoding, which translates to faster training and inference.
💡 The Round-Trip Test
A critical sanity check: when you encode a string to tokens and then decode it back, you should get exactly the original string.
This reversibility is essential. If your tokenizer loses information, your model can never learn to generate that information correctly.
15. Implementation: Building Your Own Tokenizer
The BPE Algorithm
The BPE process has two main stages:
- Pre-tokenization: Split text into initial units (usually by whitespace and punctuation)
- Tokenization: Iteratively merge the most frequent pairs of tokens
The pre-tokenizer puts the space at the front of words – this is built into the algorithm, not an accident.
⚠️ Implementation Warning
Implementing the BPE tokenizer from scratch has been surprisingly challenging for many students. It seems simple conceptually, but the devil is in the details.
Budget time accordingly: This part of the assignment takes more work than you might expect. The edge cases and efficiency considerations add up quickly.
16. Grading and Evaluation
How Assignments Are Evaluated
Grading has multiple components:
- Correctness: Did you implement the algorithm correctly? Tests must pass.
- Performance: Did your model achieve a certain level of loss?
- Efficiency: Is your implementation efficient enough?
Each problem part in the assignment has points associated with it, giving you granular feedback on what’s working and what needs improvement.
💡 The Leaderboard Challenge
For assignments with leaderboards:
- Scaling Laws: Minimize loss given your FLOPs budget
- Training: Minimize perplexity on open web text with 90 minutes on an H100
These competitive elements simulate real-world constraints where compute is expensive and you need to make every FLOP count.
Key Takeaways from Part 2
- Always benchmark: Measurement drives optimization
- Scaling laws work: The 20:1 rule (tokens to parameters) is remarkably reliable
- Data quality matters: No amount of compute can fix bad training data
- Tokenization is subtle: Small choices in tokenization ripple through the entire model
- Implementation details count: The gap between understanding and correct implementation is significant
What’s Next?
- Alignment techniques: supervised fine-tuning and reinforcement learning
- Preference data and synthetic data generation
- Advanced architecture optimizations
- Production deployment considerations
- Verifiers and evaluation frameworks
We’re building toward a complete understanding of the entire language model stack – from first principles to production systems.
References :
Building Large Language Models From Scratch – Stanford University, Youtube lecture 1