#025 FaceNet: A Unified Embedding for Face Recognition and Clustering in PyTorch

Highlights: Face recognition represents an active area of research for more than 3 decades. This paper, FaceNet, published in 2015, introduced a lot of novelties and significantly improved the performance of face recognition, verification, and clustering tasks. Here, we explore this interesting framework that become popular for introducing 1) 128-dimensional face embedding vector and 2) triplet loss function. In addition to the theoretical background, we give an outline of how this network can be implemented in PyTorch.

Tutorial Overview:
- Introduction to face recognition with FaceNet
- Triplet Loss function
- FaceNet convolutional Neural Network architecture
- FaceNet implementation in PyTorch
1. Introduction to face recognition with FaceNet
This work is processing faces with the goal to answer the following questions:
- Is this the same person? – face verification
- Who is this person in the photo? – face recognition
- Who are similar persons? – face clustering
FaceNet method developed a novel design for the final layer of the CNN to embed the face image. This, so called, embedding vector is of size 128 elements. Think of it this way. We have all the face images in the world. They are represented with their embedding vectors with 128 numbers. If the images are of the same person, the distance between their 128 embedding vectors should be very small. This is an L2 or Euclidean distance that is calculated by subtracting element by elements, squaring the results, summing them and taking the square root as a final result.
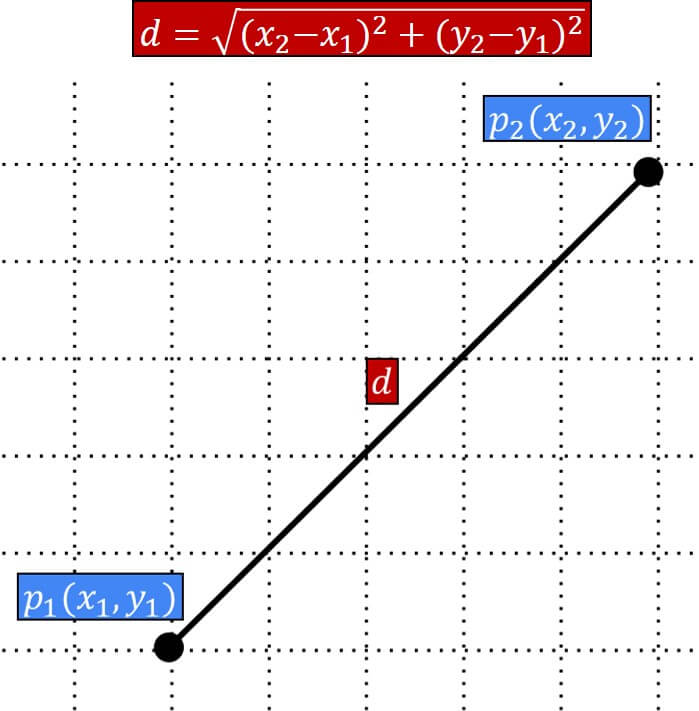
On the other hand, if the faces are from different persons these distances should be larger than a predefined margin value. The challenge being solved here is that the face images of the same person can be recorded under drastically different conditions. For instance, we can have different illumination condition, different angle and head pose. Have a look at the image below that illustrates this. If two images are identical, the L2 distance of the embedding vector will be 0. If the values are around 1, we will have high similarity, thereby implying that the face image is of the same person. Larger distances (e.g. >4) between two face images imply that we have different persons that do not look alike.

In the image above we can see the distances between:
- face images of the same person
- face images of different persons
If we are about to set a threshold to 1.1 we would achieve a perfect classification, that is, recognition.
In 2015, the idea of embedding was not new for the face recognition community. However, the previous approaches used this embedding within the intermediate CNN layers. In contrast, the novelty in this work is that it was applied to the final layer that generates 128 elements. In addition, FaceNet applied a direct training on the final output, thus generating a compact 128-D embedding using a triplet-based loss function. 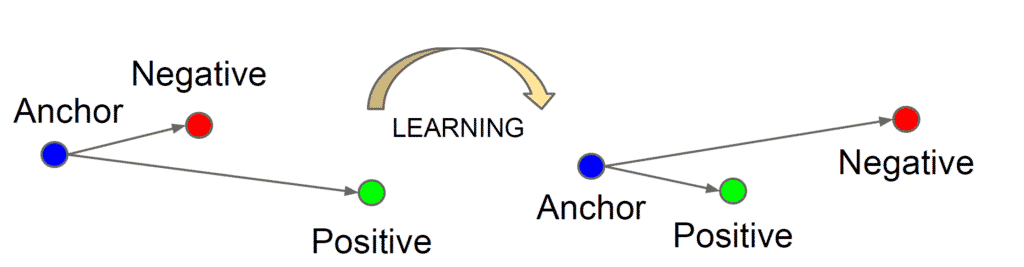
Triplet loss?? What is that? It’s a fairly simple and clever idea. You provide three images to the network during training. One image, we will call an anchor. A positive pair is the image of the same person as in the anchor. For this case, we want L2 distance to be minimized. On the other hand, we have also a negative sample pair. Now, this person is a different than the person in the anchor image. In addition, when we do the training, it would be wise not too use highly dissimilar face image as compared to the anchor face image. Then, it would be easy for a network to distinguish such examples and learning would be too slow and inefficient. Finally, observe one subtlety in the graph above. After successful learning we want distances to:
- decrease between the anchor and the positive pair
- increase between the anchor and the negative pair.

2. Triplet Loss function
Here, we will explore in a little bit more details a triplet loss function. We will assume that the embedding is represented as a function \(f(x)\in R^{d} \). We say that it embeds an input image \(x \) into a \(d \) – dimensional Euclidean space. In addition, there is a constraint so that \(\|f(x)\|_{2}=1 \) . If the anchor image is \(x_{i}^{a} \), then the distance with the positive \(x_{i}^{p} \) should be smaller than the distance between anchor and a negative \(x_{i}^{n} \). This is given with the following formula where \(\alpha \) is an enforced margin.
$$ \left\|f\left(x_{i}^{a}\right)-f\left(x_{i}^{p}\right)\right\|_{2}^{2}+\alpha<\left\|f\left(x_{i}^{a}\right)-f\left(x_{i}^{n}\right)\right\|_{2}^{2} $$
$$ \forall\left(f\left(x_{i}^{a}\right), f\left(x_{i}^{p}\right), f\left(x_{i}^{n}\right)\right) \in \mathcal{T} $$
where \(\alpha \) is a margin that is enforced between positive and negative pairs. \(\mathcal{T} \) is the set of all possible triplets in the training set and has cardinality \(N \).
The loss that is being minimized is then:
$$ L= \sum_{i}^{N}\left[\left\|f\left(x_{i}^{a}\right)-f\left(x_{i}^{p}\right)\right\|_{2}^{2}-\left\|f\left(x_{i}^{a}\right)-f\left(x_{i}^{n}\right)\right\|_{2}^{2}+\alpha\right]_{+} $$
The next thing to determine is how we are going to select these triplets. The image dataset is very large and creating such triplet pairs has to be selected with care since we cannot use all possible options. Try to figure out on your own how many combinations there are if we have for instance 100k training images. Good old probability and combinatorics 🙂 Therefore, the goal is to create such a dataset so that the training is efficient. That is, that the learning convergence is fast. Hence, the proposed solution is to select hard triplets, that are active and can contribute to the model improvement. In other words, when we select a triplet pair, we want that the distance between positive and anchor is maximal (hard positive), whereas the distance between negative and the anchor is minimal (hard negative). Mathematically, this can be summarized as:
For given \(x_{i}^{a} \), we want to select an \(x_{i}^{p} \) (hard positive) such that:
$$ argmax_{x_{i}^{p}}\left\|f\left(x_{i}^{a}\right)-f\left(x_{i}^{p}\right)\right\|_{2}^{2} $$
Similarly, we want to select an $x_{i}^{n}$ (hard negative) such that:
$$ argmin_{x_{i}^{n}}\left\|f\left(x_{i}^{a}\right)-f\left(x_{i}^{n}\right)\right\|_{2}^{2} $$
As we have already said, calculating all pairs would be impossible to find optimal triplet pairs. However, a nice solution to this is to calculate the distances among all pairs in a single mini batch. That would represent an online triplet generation. In the mini batch, there should be a few thousand exemplars. Within these exemplars there should be at around 40 faces per identity in every mini batch.
3. FaceNet convolutional Neural Network architecture
The original network is trained using Stochastic Gradient Descent (SGD) with standard backprop. The learning rate started at 0.05, and was iteratively decreased. Interestingly, this training required around 1,000-2,000 hours on a CPU cluster (in 2015)! Luckily, since then, many training recipes are developed, thereby enabling faster training time. Finally, in all blocks the authors applied ReLU activation function.
For FaceNet, two models were proposed using different CNN structures:
1. The approach proposed by Zeiler and Fergus (2014) and [1]
2. The GoogLeNet style Inception models. [2]
In the table below we have the network structure according to Zeiler and Fergus based on a model with 1×1 convolutions.
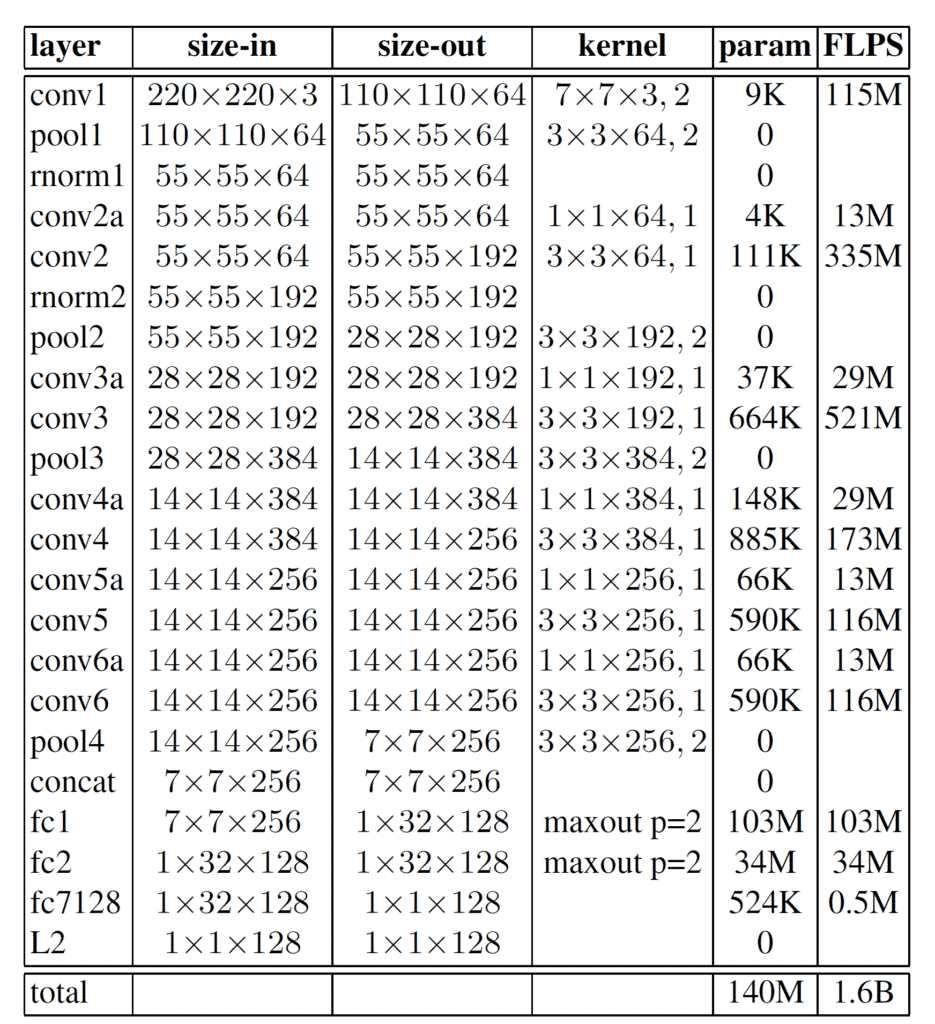
The second approach is shown in the following table. It is an interesting way in the original paper how the network is presented in a table with all the necessary details. One not so commonly used thing, is the difference that the authors used L2 norm pooling. This simply means, where specified in the table, that instead of the max, the L2 norm is calculated and used as the output result.
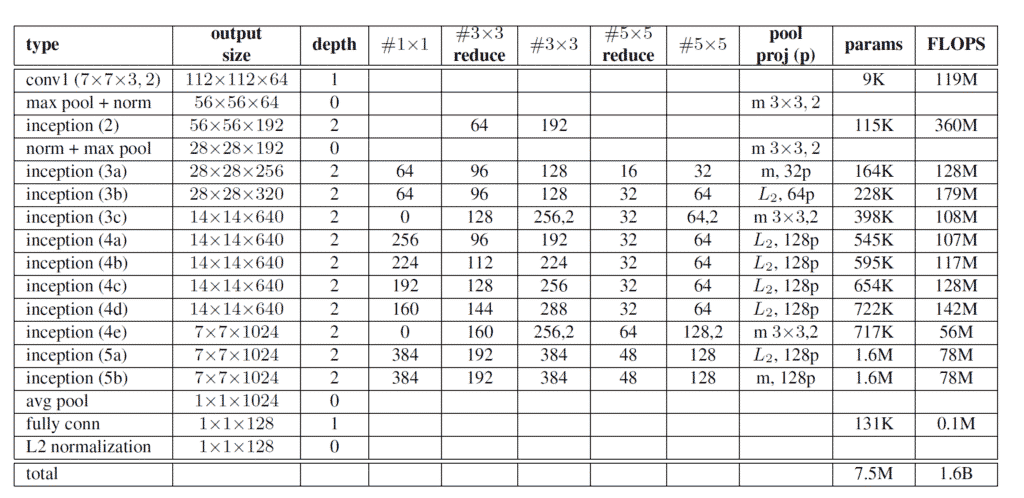
4. FaceNet Implementation in PyTorch
Similarly, as in the recent post from this series, we will analyze the basic blocks necessary for the development of the complete network from scratch. Hence, this can be seen as an instruction part of the post aiming to present the ideas on how to build certain blocks and apply Deep Learning strategies. Here, our code analysis we base on the following git repo [3].
So, we will start with the basic convolutional block. It consists of a 2d convolutional layer, a batch normalization layer, and finally a ReLU activation function. This order is specified in the forward function as well.
class BasicConv2d(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride, padding=0):
super().__init__()
self.conv = nn.Conv2d(
in_planes, out_planes,
kernel_size=kernel_size, stride=stride,
padding=padding, bias=False
) # verify bias false
self.bn = nn.BatchNorm2d(
out_planes,
eps=0.001, # value found in tensorflow
momentum=0.1, # default pytorch value
affine=True
)
self.relu = nn.ReLU(inplace=False)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x Since we defined a basic convolutional block, it is now convenient to create a more complex layer structure. Here, we have Block35. Note that this block is relatively simple, and no detailed explanations are needed. The block generates three branches. Next, they are concatenated and one additional Conv2d layer is added. Then, the skip connection is added as well. Here, this is achieved in the forward function with the command out = out * self.scale + x. The parameter scale is defined in the instantiation of this block.
class Block35(nn.Module):
def __init__(self, scale=1.0):
super().__init__()
self.scale = scale
self.branch0 = BasicConv2d(256, 32, kernel_size=1, stride=1)
self.branch1 = nn.Sequential(
BasicConv2d(256, 32, kernel_size=1, stride=1),
BasicConv2d(32, 32, kernel_size=3, stride=1, padding=1)
)
self.branch2 = nn.Sequential(
BasicConv2d(256, 32, kernel_size=1, stride=1),
BasicConv2d(32, 32, kernel_size=3, stride=1, padding=1),
BasicConv2d(32, 32, kernel_size=3, stride=1, padding=1)
)
self.conv2d = nn.Conv2d(96, 256, kernel_size=1, stride=1)
self.relu = nn.ReLU(inplace=False)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
out = torch.cat((x0, x1, x2), 1)
out = self.conv2d(out)
out = out * self.scale + x
out = self.relu(out)
return out Few more similar blocks are defined in the similar manner. We will omit them here, but refer to a repo [3] for your further self study analysis.
Now, we will present the block that implements the final network InceptionResnetV1.
class InceptionResnetV1(nn.Module):
"""Inception Resnet V1 model with optional loading of pretrained weights.
Model parameters can be loaded based on pretraining on the VGGFace2 or CASIA-Webface
datasets. Pretrained state_dicts are automatically downloaded on model instantiation if
requested and cached in the torch cache. Subsequent instantiations use the cache rather than
redownloading.
Keyword Arguments:
pretrained {str} -- Optional pretraining dataset. Either 'vggface2' or 'casia-webface'.
(default: {None})
classify {bool} -- Whether the model should output classification probabilities or feature
embeddings. (default: {False})
num_classes {int} -- Number of output classes. If 'pretrained' is set and num_classes not
equal to that used for the pretrained model, the final linear layer will be randomly
initialized. (default: {None})
dropout_prob {float} -- Dropout probability. (default: {0.6})
"""
def __init__(self, pretrained=None, classify=False, num_classes=None, dropout_prob=0.6, device=None):
super().__init__()
# Set simple attributes
self.pretrained = pretrained
self.classify = classify
self.num_classes = num_classes
if pretrained == 'vggface2':
tmp_classes = 8631
elif pretrained == 'casia-webface':
tmp_classes = 10575
elif pretrained is None and self.classify and self.num_classes is None:
raise Exception('If "pretrained" is not specified and "classify" is True, "num_classes" must be specified')
# Define layers
self.conv2d_1a = BasicConv2d(3, 32, kernel_size=3, stride=2)
self.conv2d_2a = BasicConv2d(32, 32, kernel_size=3, stride=1)
self.conv2d_2b = BasicConv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.maxpool_3a = nn.MaxPool2d(3, stride=2)
self.conv2d_3b = BasicConv2d(64, 80, kernel_size=1, stride=1)
self.conv2d_4a = BasicConv2d(80, 192, kernel_size=3, stride=1)
self.conv2d_4b = BasicConv2d(192, 256, kernel_size=3, stride=2)
self.repeat_1 = nn.Sequential(
Block35(scale=0.17),
Block35(scale=0.17),
Block35(scale=0.17),
Block35(scale=0.17),
Block35(scale=0.17),
)
self.mixed_6a = Mixed_6a()
self.repeat_2 = nn.Sequential(
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
)
self.mixed_7a = Mixed_7a()
self.repeat_3 = nn.Sequential(
Block8(scale=0.20),
Block8(scale=0.20),
Block8(scale=0.20),
Block8(scale=0.20),
Block8(scale=0.20),
)
self.block8 = Block8(noReLU=True)
self.avgpool_1a = nn.AdaptiveAvgPool2d(1)
self.dropout = nn.Dropout(dropout_prob)
self.last_linear = nn.Linear(1792, 512, bias=False)
self.last_bn = nn.BatchNorm1d(512, eps=0.001, momentum=0.1, affine=True)
if pretrained is not None:
self.logits = nn.Linear(512, tmp_classes)
load_weights(self, pretrained)
if self.classify and self.num_classes is not None:
self.logits = nn.Linear(512, self.num_classes)
self.device = torch.device('cpu')
if device is not None:
self.device = device
self.to(device)
To be applicable, obviously, this network has to be trained. Among others, two datasets can be used for this VGGFace2 or CASIA-Webface. Note that we can choose for this network the desired dataset and automatically download and load coefficients for this network (see [3] and function load_weights() ). We can say that the “intelligence” is stored in a few million parameters :-). Finally, we will have a look at the definition of the forward function.
def forward(self, x):
"""Calculate embeddings or logits given a batch of input image tensors.
Arguments:
x {torch.tensor} -- Batch of image tensors representing faces.
Returns:
torch.tensor -- Batch of embedding vectors or multinomial logits.
"""
x = self.conv2d_1a(x)
x = self.conv2d_2a(x)
x = self.conv2d_2b(x)
x = self.maxpool_3a(x)
x = self.conv2d_3b(x)
x = self.conv2d_4a(x)
x = self.conv2d_4b(x)
x = self.repeat_1(x)
x = self.mixed_6a(x)
x = self.repeat_2(x)
x = self.mixed_7a(x)
x = self.repeat_3(x)
x = self.block8(x)
x = self.avgpool_1a(x)
x = self.dropout(x)
x = self.last_linear(x.view(x.shape[0], -1))
x = self.last_bn(x)
if self.classify:
x = self.logits(x)
else:
x = F.normalize(x, p=2, dim=1)
return x
This block finally computes the embedding vector of 128 elements. The processing in the forward function is straightforward.
This covers the building blocks of how the FaceNet neural network can be implemented.
If you are ready to experiment, we recommend that you simply download the pre-trained models and start with FACE RECOGNITION!
In addition, once you have a 128-dimensional embedding vector for a face image you may develop other interesting projects or apps. You can do a face verification! For instance, just calculate the L2 norm distance between the image in your database, and the new image of a person (e.g. a person who is entering into a building). Then, just with a threshold comparison, you can decide whether this person should be admitted.
Moreover, if you have a set of face images you can calculate their embedding vectors. Then, you can search for similar faces. Also, you can find the most dissimilar faces. Have fun!!!

Moreover, in the folowing Github repo you can find the interesting code for face Recognition in Pytorch.
Summary
In this blog post, we have learned how to develop a face recognition system using FaceNet. It is a face recognition system developed in 2015 by researchers at Google. We have learned about novelties that authors introduced in this paper that significantly improved the performance of face recognition, verification, and clustering tasks. Finally, we learned how to develop a complete network from scratch.
References:
[1] Zeiler, Matthew D., and Rob Fergus. “Visualizing and understanding convolutional networks.” European conference on computer vision. Springer, Cham, 2014.
[2] Szegedy, Christian, et al. “Rethinking the inception architecture for computer vision.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[3] https://github.com/timesler/facenet-pytorch/blob/master/models/inception_resnet_v1.py