#013 Optical Flow Using Horn and Schunck Method

Highlights: A common problem in computer vision applications is the estimation of motion of every pixel in a sequence of images or video sequences. While many methods have been proposed to solve this problem, Optical Flow stands out as one of the most efficient ones.
In this post, we will learn how to better understand a video sequence by analyzing how objects are moving across the frames using a popular Optical Flow estimation algorithm called the Horn and Schunck method. We will also program an OpenCV code to implement this method. So, let’s begin.
Tutorial Overview:
- Understanding the Concept of Motion
- Optical Flow and Its Types
- The Horn and Schunck Method
- Implementation Using Python Code
1. Understanding the Concept of Motion
In our previous posts on the blog, we have covered many common techniques for detecting objects to process video sequences in real-time and detect the object of interest in each frame separately. However, in all these approaches one important information is completely ignored. That information is the relationship between objects in two consecutive frames.
Let’s understand this using an example. Have a look at the GIF below that shows a sunrise motion on loop. This GIF is nothing but a sequence of static frames combined together.

In examples such as above, our main objective is to capture the change that happens from one sequence to another. In order to achieve that, we need to track the motion of objects across all frames, estimate their current position and then, predict their position in the subsequent frame.
Moreover, when we work with video sequences rather than static images, instead of using just space coordinates \(x \) and \(y \), we will also have to track a change of intensity of a pixel over time. Therefore, we will have one additional variable – time. This means that intensity of a single pixel can be represented as a function of space \(x \), \(y \) and time \(t \).

This approach is popularly known as Optical Flow. Let’s understand this better along with the various categorizations of Optical Flow.
2. Optical Flow and Its Types
Optical Flow can be defined as a pattern of motion of pixels between two consecutive frames. The motion can be caused either by the movement of a scene or by the movement of the camera.
A vital ingredient in several computer vision and machine learning fields such as object tracking, object recognition, movement detection, and robot navigation, Optical Flow works by describing a dense vector field. In this field, each pixel is assigned a separate displacement vector that helps in estimating the direction and speed of each pixel of the moving object, in each frame of the input video sequence.
If we were to categorise the technique of Optical Flow, we can divide it into two main types:
- Sparse Optical Flow: This method processes the flow vectors of only a few of the most interesting pixels from the entire image, within a frame.
- Dense Optical Flow: In this, the flow vectors of all pixels in the entire frame are processed which, in turn, makes this technique a little slower but more accurate.
Have a look at the two images below. The image on the left shows Sparse Optical Flow in action and the image on the right shows Dense Optical Flow.

As you must have realized by now, that tracking motion of objects from one sequence to another is a complicated problem due to the sheer volume of pixels in each frame.
In the next section, we will understand how we can estimate the motion of each pixel in a frame using some assumptions and some simplifications. We will do this by learning about a commonly used algorithm for Optical Flow, known as the Horn and Schunck method.
3. The Horn and Schunck Method
Interestingly, the whole conceptual idea of Optical Flow was introduced for the first time by the famous computer vision researcher, Berthold K. P. Horn, and his Ph.D. student Brian G. Schunck [2]. Their first published paper in 1981. proposed the idea of computing the motion between two frames and since then, it has become a classical Optical Flow estimation algorithm called the Horn and Schunck method.
In this proposed method, they made an important assumption that there isn’t any significant change in the lighting between two consecutive frames, calling it the Brightness Constancy Assumption. This means that if the object in the image moves or say, the camera moves, then, the colours of that object will remain the same, regardless of the lighting.
Of course, in real-life scenarios, we do not encounter ideal conditions that often since we usually deal with a lot of shadows and changes in brightness. However, taking this assumption, the problem of estimating motion between frames becomes a lot easier. Let’s see how.
The Brightness Constancy Assumption
Observe the diagram below and notice the correspondence between the two consecutive frames in a video sequence, represented by \(t \) and \(t+dt \), respectively.

Let’s say there is an object in the video which is in motion. Now, our main goal is to see the position of every pixel from Frame 1 in the next frame, Frame 2.
Observe a single pixel in the first frame, which is at the location \((x,y) \). As we discussed in the beginning of this post, since we are processing a video sequence, we need to introduce a third dimension to this function which is a time \(t \). Therefore, the intensity value at this particular pixel can now be denoted as \(f(x,y,t) \).
This pixel is shifted in the second frame in the \(x \) direction by a distance \(dx \); in the \(y \) direction by a distance \(dy \); and in the \(t \) direction by a distance of \(dt \).
To understand what Horn and Schunck proposed, we, first, need to remember the fact that each second of a video sequence usually consists of 30 frames. Therefore, if we analyze two consecutive frames in a video, we can assume that not many things will change between the scene in the first and the scene in the second frame.
This Brightness Constancy Assumption states that the intensities of a pixel in the first and the second frame are the same due to a short duration between the frames. It can be written using the following mathematical expression:
$$ f(x, y, t)= f(x+dx, y+dy, t+dt) $$
We can, now, approximate the above equation using the Taylor Approximation series, and thus, expanding the term \(f(x, y, t) \), assuming that it will be very close to \(f(x+dx, y+dy, t+dt) \). Here’s what the Taylor expansion looks like:
$$ f(x, y, t)=f(x, y, t)+\frac{\partial f}{\partial x} d x+\frac{\partial f}{\partial y} d y+\frac{\partial f}{\partial t} d t+\cdots \text { higher order terms } $$
After neglecting the higher order terms and simplifying the above expansion further, we can write the new expression as:
$$ 0=\frac{\partial f}{\partial x} d x+\frac{\partial f}{\partial y} d y+\frac{\partial f}{\partial t} d t $$
Next, we will perform certain notation changes such as \(\frac{\partial f}{\partial x}=f_{x} \); \(\frac{\partial f}{\partial y}=f_{y} \); and \(\frac{\partial f}{\partial t}=f_{t} \). We will further divide both sides by \(dt \) to arrive at the following equation:
$$ f_{x} \frac{d x}{d t}+f_{y} \frac{d y}{d t}+f_{t} \frac{d t}{d t}=0 $$
Here, we can say that every pixel with coordinates \((x,y) \) in the first image, moves along the motion vector \((u,v) \) where \(u \) is the pixel’s velocity in the \(x \) direction and \(v \) is the pixel’s velocity in the \(y \) direction, respectively.
Using the equation above, we can say that \(\frac{d x}{d t} \) – \(u \) is the pixel’s velocity in the \(x \) direction, and \(\frac{d y}{d t} \) – \(v \) is the pixel’s velocity in the \(y \) direction.
Furthermore, since we have sampled a video sequence for our example, we can say that we are working at discrete times and not continuous time. Thus, we can set \(dt=1 \) and arrive at the equation below.
$$ f_{x} u+f_{y} v+f_{t}=0 $$
This beautiful expression is known as the Optical Flow equation. Let’s see how we can interpret this equation in one dimension.
Interpretation of Optical Flow Equation
The Optical Flow equation has essentially two unknowns.
- Velocity of each pixel in the \(x \)-direction, represented by \(u \)
- Velocity of each pixel in the \(y \)-direction, represented by \(v \)
However, if you notice, we have an unconstrained system with two unknown variables and only one equation. If we were to better understand this situation, we should study the \((u,v) \) plot, which is nothing but an equation of a line.
$$ f_{y} v=-f_{x} u-f_{t} $$
$$ v=-\frac{f_{x}}{f_{y}} u-\frac{f_{t}}{f_{y}} $$
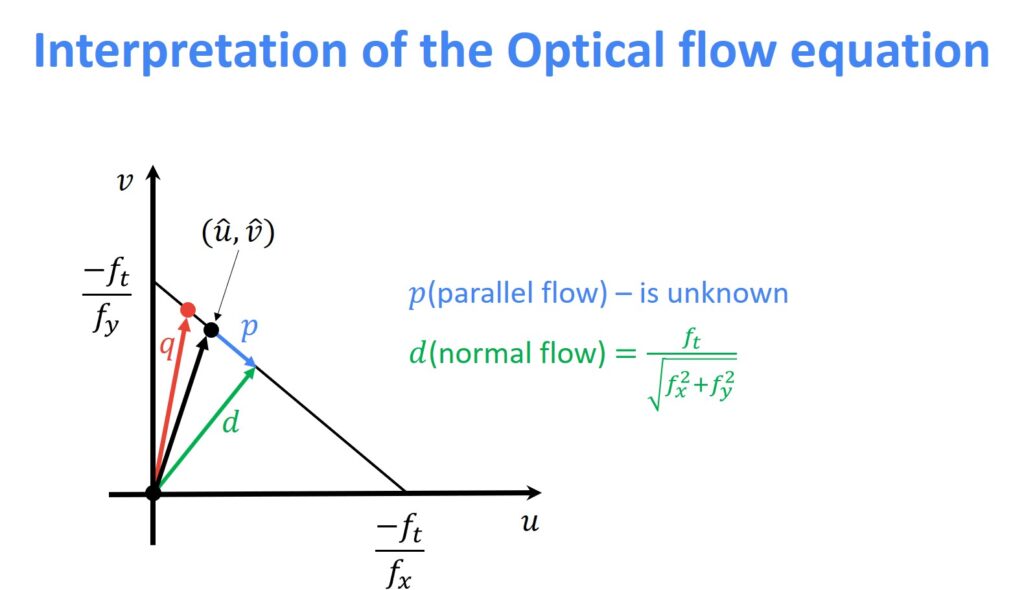
From the plot above, we can see that we can always determine normal component \(d \). We also know that solution for the \(u \) and \(v \) will lie on this parallel line. On the other hand, the parallel component \(p \) can not be determined because there are infinite possible values for \(u \) and \(v \). However, our aim is to find the exact point in the \((u,v) \) plane that represents specific values of \(u \) and \(v \).
This problem is also known as the aperture problem. To visualize it, let’s take a look at the following animation and try to guess the motion of the line.
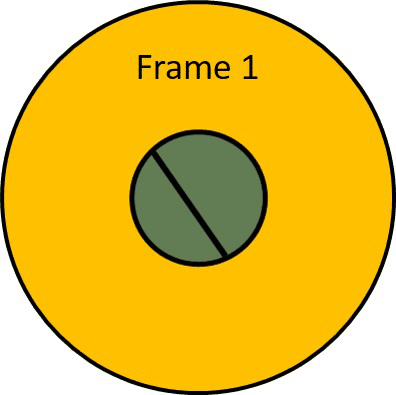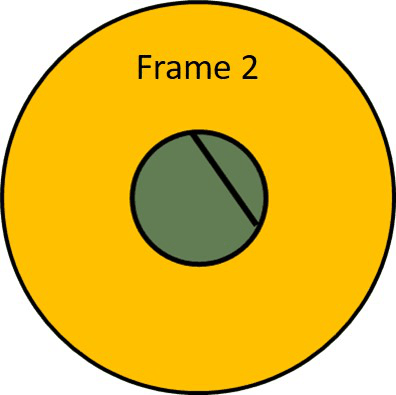
It looks like the line is moving up and to the right. However, the right answer is that we do not know in which direction this line is moving. Actually, it can move in any direction. That is because we are looking at the line through a small circle. If we make this aperture transparent we can see that actual movement of the line is horizontal.
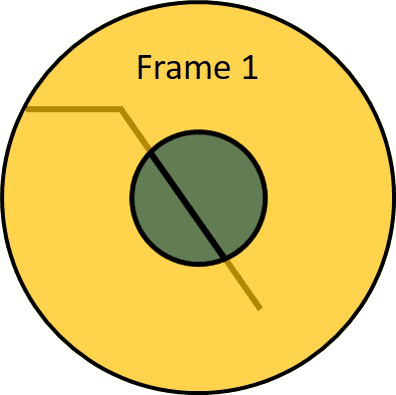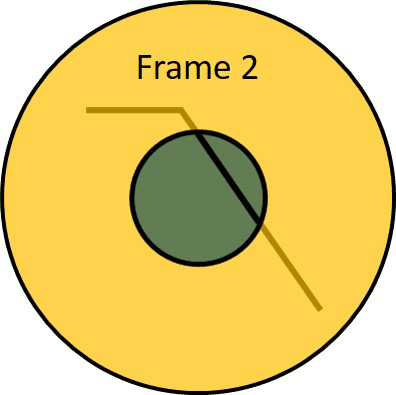
This means that we are only able to measure the component of optical flow that is in the direction of the gradient intensity. On the other hand, we are unable to measure the component perpendicular to the gradient intensity.
This is where the biggest shortcoming of the Brightness Constancy Assumption arises. In order to solve this problem, we need to make another assumption, as proposed by Horn and Schunck in their paper. This is called the Smoothness Constraint Assumption. Let’s see what it says.
The Smoothness Constraint Assumption
Let’s consider the following images.
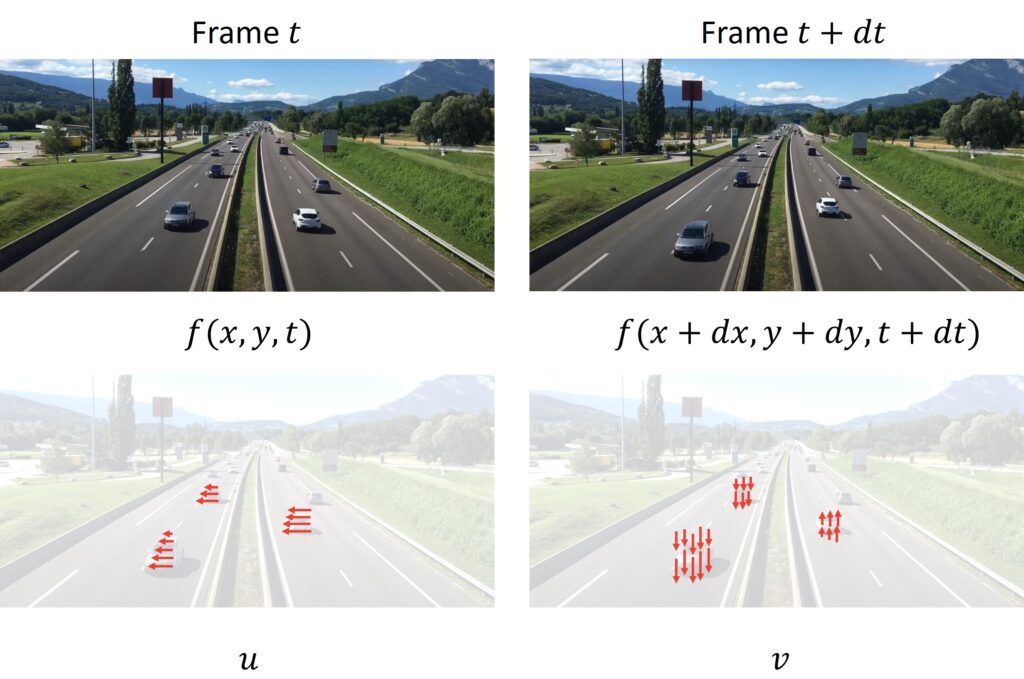
In the above image set, we can see two consecutive frames from a video sequence. The small arrows that we see in the images, represent each pixel of the car and gives a better visualization of directional velocities \(u\) and \(v\) in \(x\) and \(y\) directions, respectively.
The length of the arrow represents the magnitude of \(u \) and \(v \). We can represent each magnitude with a different color (if the magnitude is larger than the color is stronger, and vice-versa). Furthermore, we will represent the static pixels of the background in white color.
So, what the Smoothness Constraint Assumption essentially says is that if we consider a particular neighborhood within the image, we will notice that all pixels in that neighborhood move in the same direction. Therefore, pixels of a neighborhood which are next to each other have very similar optical flow vectors as well.
So, for example, if we record a scene with a non-moving object using a camera, all pixels that we see in the projected image will have very similar motion vectors. This also means that if we have a person in motion, the majority of the local pixels of that moving person will behave very similarly.
The only case where this assumption doesn’t work is when the the pixels are located between the object and the background. In such scenarios, the pixel within a background which is next to the pixel from an object, may be different flow vectors.
For this particular scenario, let’s calculate derivatives of \(u \) image and \(v \) image in both \(x \) and \(y \) direction. Below is the result that we will achieve.
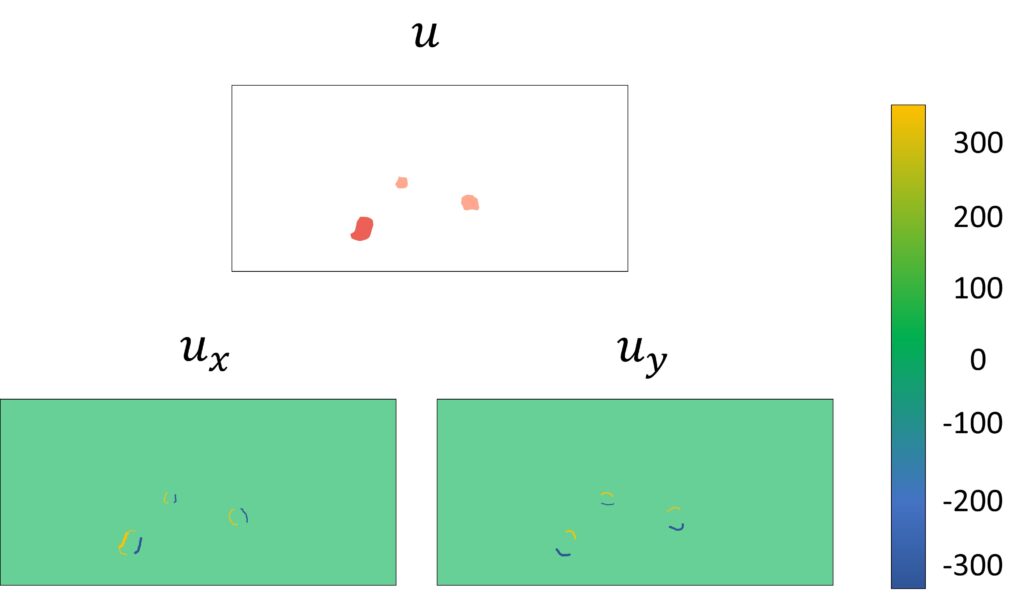

Indeed, both the resultant images are smooth, i.e., the pixels are not rapidly changing and have the same flow vectors in most parts of the image (the areas painted in 0), except around the places between the object and the background (the areas painted in yellow and blue). This tells us that if we take the square of \((u,v) \) vector with respect to \(x \) and \(y \), and add all pixels in the image, we will get a small value because the intensities of most of the pixels are equal to zero. Let’s represent this mathematically. Don’t be scared with this double integral. It just represents that this cost function will be calculated for each pixel and then these values will be summed.
$$ E=\iint_{x, y}\left(f_{x} u+f_{y} v+f_{t}\right)^{2}+\lambda\left(u_{x}^{2}+u_{y}^{2}+v_{x}^{2}+v_{y}^{2}\right) d x d y $$
This is called the Cost Function. In this cost function, the first term on the right hand side shows how well the pixels fit the Brightness constancy assumption. To this, we add some factor \(\lambda \) multiplied by the value that represents smoothness. In simpler terms, our aim with the above equation is to minimize the value for brightness constraint and the value for smoothness constraint.
Also, \(\lambda \), which is also known as the ‘regularizer’, is basically a weighting factor that decides how much importance needs to be given to either of the two constraints: the Brightness Constraint and the Smoothness Constraint, respectively. So, if \(\lambda \) has a large value, we need to put more weight on the smoothness constraint to get something very smooth and thereby, get a constant flow vector. This will result in every pixel moving exactly in the same direction and at the same speed.
On the other hand, if this regularizer factor is equal to zero, we won’t have a smooth vector and we need to tune \(\lambda \) further, to make the field smooth.
We can conclude by saying that our Cost Function is nothing but a function of the functions \(u \) and \(v \), or in more simpler terms, we can call it a ‘functional’. And, our goal is to find the minimum of this cost function, or ’functional’. Let’s learn how.
Consider the image as shown below.

In the image above, we considered two points and we need to find the minimum distance between these two points. Intuitively, the shortest length will be the straight line that connects the two points. This is an example of minimizing one simple cost function.
Now, in order to find the function of the curve with respect to some cost, or the length, we will use the Euler-Lagrange equations. What these equations will do is that they will take the partial derivative of the cost function \(E \) with respect to the variable we want to find out. Here, we will use the partial derivative \(E_{u} \) to find the value of \(u\), and then, subtract from it, a function of \(x \). The equations for minimizing the cost function as described above, are illustrated below.
$$ E_{u}-\frac{d u_{x}}{d x}-\frac{d u_{y}}{d y}=0 $$
$$ 2\left(f_{x} u+f_{y} v+f_{t}\right) f_{x}-2 \lambda\left(u_{x x}+u_{y y}\right)=0 $$
$$ \left(f_{x} u+f_{y} v+f_{t}\right) f_{x}-\lambda\left(\Delta^{2} u\right)=0 $$
Similarly, we will perform minimising operation to find the value of the other variable, \(v \) as follows:
$$ E_{v}-\frac{d v_{x}}{d x}-\frac{d v_{y}}{d y}=0 $$
$$ 2\left(f_{x} u+f_{y} v+f_{t}\right) f_{y}-2 \lambda\left(v_{x x}+v_{y y}\right)=0 $$
$$ \left(f_{x} u+f_{y} v+f_{t}\right) f_{y}-\lambda\left(\Delta^{2} v\right)=0 $$
Once we have the values for \(u\) and \(v\), we move ahead to putting appropriate thresholds for these optical flow magnitudes. We do this using moving object masks. Let’s understand these masks better.
Moving Object Masks
In the digital domain, we often use moving object masks and convolve them with the images. Consider the images below.
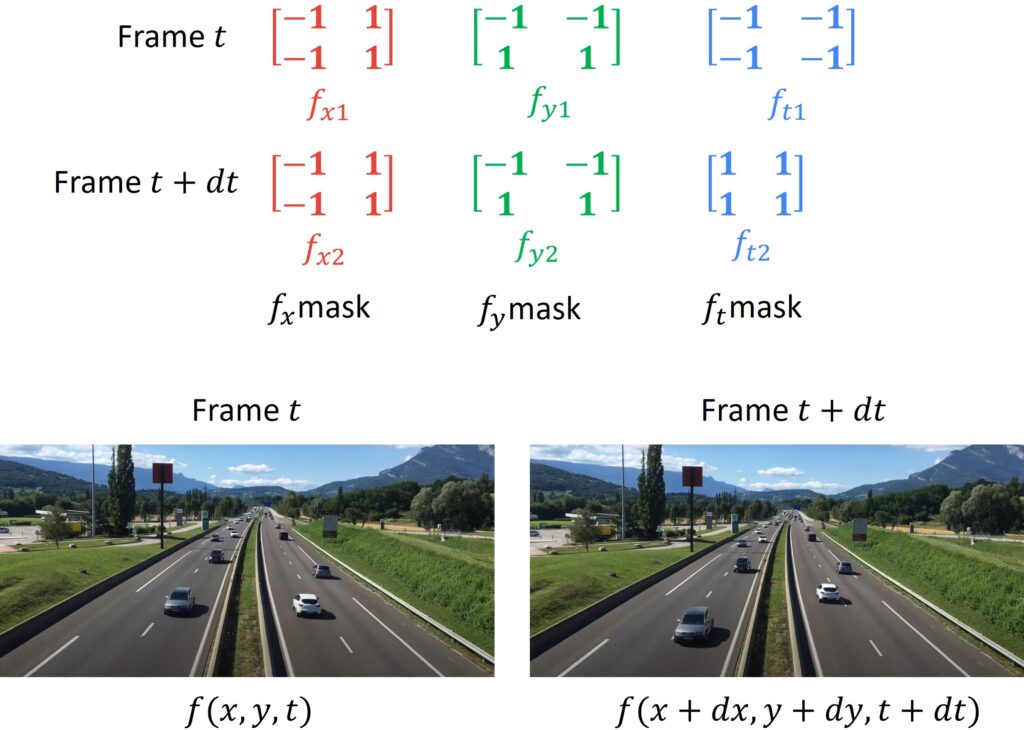
We will use a particular moving object mask in order to find the values of \(f_{x} \), \(f_{y} \) and \(f_{t} \), and then, convolve it with the \(t \) image. We will further use this mask with the image in the next frame, represented by \(t+dt \). Next, we will take the average of both these images while applying convolution, resulting in the value of \(f_{x} \). In the same way, we can find \(f_{y} \), which is the Slatex y $ direction of the mask, and \(f_{t} \), which is a derivation in time.
If we were to represent the entire masking process mathematically, this is how we do it. Note that in the following equations, asterisk \(\ast \) represents an operation of convolution.
$$ f_{x}=0.5\left((\text { Frame } t)^{*} f_{x 1}+(\text { Frame } t+d t)^{*} f_{x 2}\right) $$
$$ f_{y}=0.5\left((\text { Frame } t)^{*} f_{y 1}+(\text { Frame } t+d t)^{*} f_{y 2}\right) $$
$$ f_{t}=(\text { Frame } t)^{*} f_{t 1}+(\text { Frame } t+d t)^{*} f_{t 2} $$
Now that we have calculated \(f_{x} \), \(f_{y} \) and \(f_{t} \), we shall see how moving object masks can be used to reduce our method’s sensitivity to noise. This is done by computing the Laplacian operator \(\Delta ^{2}u \) by using a spatial filter or a Laplacian mask which is usually applied after the smoothing process of the image.
Consider the computation below.

As you can see in the above matrices, the diagonals are given lesser weight as compared to the four neighbour which have higher weightage. We can represent the Laplacian mask mathematically as written below.
$$ \left(\Delta^{2} u\right)=\left(u_{a v g}-u\right) $$
$$ \left(\Delta^{2} v\right)=\left(v_{a v g}-v\right) $$
In the equations above, \(u_{a v g} \) and \(v_{a v g} \) represent the average of neighborhood pixels, respectively. After we have found the average, we can write the middle pixel as an average of its neighboring pixels as \(u_{a v g} -u \). We can perform the same averaging operation for \(v\) as well.
If you look at it intuitively, we are simply converting an analog equation into a discrete equation. The only difference is that instead of using the term \(\Delta ^{2}u \), we are representing the same thing with the term \(u_{a v g} -u \) and \(u_{a v g} -u \), respectively.
Great! Looks like we have finally solved the unconstrained system problem that we were having earlier where we had a single equation but two variables to be calculated. Now, we have two equations and two unknowns. Let’s get to solving these two equations.
$$ \left(f_{x}{u}+f_{y} v+f_{t}\right) f_{x}-\lambda\left(u_{a v g}-u\right)=0 $$
$$ \left(f_{x}^{2} u+f_{x} f_{y} v+f_{x} f_{t}\right)-\lambda u_{a v g}+\lambda u=0 $$
$$ \left(f_{x}^{2}+\lambda\right) u+f_{x} f_{y} v=-f_{t} f_{x}+\lambda u_{a v g} $$
$$ \left(f_{x} u+f_{y} v+f_{t}\right) f_{y}-\lambda\left(v_{a v g}-v\right)=0 $$
$$ \left(f_{x} f_{y} u+f_{y}^{2} v+f_{y} f_{t}\right)-\lambda v_{a v g}+\lambda v=0 $$
$$ f_{x} f_{y} u+\left(f_{y}^{2}+\lambda\right) v=-f_{t} f_{y}+\lambda v_{a v g} $$
Here, we can use the Cramer’s rule by creating three determinants, represented by \(D \), \(D_{u}\) and \(D_{v}\) respectively. This is how we apply the Cramer’s rule to define these three determinants:
$$ D=\left|\begin{array}{cc}\left(f_{x}^{2}+\lambda\right) & f_{x} f_{y} \\f_{x} f_{y} &\left(f_{y}^{2}+\lambda\right)\end{array}\right| $$
$$ D_{u}=\left|\begin{array}{cc}-f_{t} f_{x}+\lambda u_{a v g} & f_{x} f_{y} \\-f_{t} f_{y}+\lambda v_{a v g} & \left(f_{y}^{2}+\lambda\right)\end{array}\right| $$
$$ D_{v}=\left|\begin{array}{cc}\left(f_{x}^{2}+\lambda\right) & -f_{t} f_{x}+\lambda u_{a v g} \\f_{x} f_{y} & -f_{t} f_{y}+\lambda v_{a v g}\end{array}\right| $$
Now, we solve these determinants further as follows.
$$ D=\left(f_{x}^{2}+\lambda\right)\left(f_{y}^{2}+\lambda\right)-\left(f_{x} f_{y}\right)^{2} $$
$$ =\gg f_{x}^{2} f_{y}^{2}+\lambda f_{y}^{2}+\lambda f_{x}^{2}+\lambda^{2}-\left(f_{x} f_{y}\right)^{2}=\gg \lambda\left(f_{y}^{2}+f_{x}^{2}+\lambda\right) $$
$$ D_{u}=\left(-f_{t} f_{x}+\lambda u_{a v g}\right)\left(f_{y}^{2}+\lambda\right)-\left(-f_{t} f_{y}+\lambda v_{a v g}\right) f_{x} f_{y}=\gg $$
$$ \left(-f_{t} f_{x} f_{y}^{2}-f_{t} f_{x} \lambda+f_{y}^{2} \lambda u_{a v g}+\lambda^{2} u_{a v g}+f_{t} f_{x} f_{y}^{2}-\lambda v_{a v g} f_{x} f_{y}\right) $$
$$ D_{v}=\left(-f_{t} f_{y}+\lambda v_{a v g}\right)\left(f_{x}^{2}+\lambda\right)-\left(-f_{t} f_{x}+\lambda u_{a v g}\right) f_{x} f_{y}=\gg $$
$$ \left(-f_{t} f_{x}^{2} f_{y}-f_{t} f_{y} \lambda+f_{x}^{2} \lambda v_{a v g}+\lambda^{2} v_{a v g}+f_{t} f_{x}^{2} f_{y}-\lambda u_{a v g} f_{x} f_{y}\right) $$
$$ u=\frac{D_{u}}{D}=\frac{\left(-f_{t} f_{x} \lambda+f_{y}^{2} \lambda u_{a v g}+\lambda^{2} u_{a v g}-\lambda v_{a v g} f_{x} f_{y}\right)}{\lambda\left(f_{y}^{2}+f_{x}^{2}+\lambda\right)} $$
$$ u=\frac{D_{u}}{D}=\frac{\left(-f_{t} f_{x}+f_{y}^{2} u_{a v g}+\lambda u_{a v g}-v_{a v g} f_{x} f_{y}\right)}{\left(f_{y}^{2}+f_{x}^{2}+\lambda\right)} $$
$$ v=\frac{D_{v}}{D}=\frac{\left(-f_{t} f_{y} \lambda+f_{x}^{2} \lambda v_{a v g}+\lambda^{2} v_{a v g}-\lambda u_{a v g} f_{x} f_{y}\right)}{\lambda\left(f_{y}^{2}+f_{x}^{2}+\lambda\right)} $$
$$ v=\frac{D_{v}}{D}=\frac{\left(-f_{t} f_{y}+f_{x}^{2} v_{a v g}+\lambda v_{a v g}-u_{a v g} f_{x} f_{y}\right)}{\left(f_{y}^{2}+f_{x}^{2}+\lambda\right)} $$
$$ u=\frac{D_{u}}{D}=\frac{\left(f_{y}^{2} u_{a v g}+f_{x}^{2} u_{a v g}+\lambda u_{a v g}-f_{x}^{2} u_{a v g}-v_{a v g} f_{x} f_{y}-f_{t} f_{x}\right)}{\left(f_{y}^{2}+f_{x}^{2}+\lambda\right)} $$
$$ u=\frac{D_{u}}{D}=\frac{u_{a v g}\left(f_{y}^{2}+f_{x}^{2}+\lambda\right)-f_{x}\left(f_{x} u_{a v g}+f_{y} v_{a v g}+f_{t}\right)}{\left(f_{y}^{2}+f_{x}^{2}+\lambda\right)} $$
$$ v=\frac{D_{v}}{D}=\frac{\left(f_{y}^{2} u_{a v g}+f_{x}^{2} v_{a v g}+\lambda v_{a v g}-f_{y}^{2} u_{a v g}-u_{a v g} f_{x} f_{y}-f_{t} f_{y}\right)}{\left(f_{y}^{2}+f_{x}^{2}+\lambda\right)} $$
$$ v=\frac{D_{v}}{D}=\frac{v_{a v g}\left(f_{y}^{2}+f_{x}^{2}+\lambda\right)-f_{y}\left(f_{x} u_{a v g}+f_{y} v_{a v g}+f_{t}\right)}{\left(f_{y}^{2}+f_{x}^{2}+\lambda\right)} $$
Finally, we will reach a simplified expression as our result which will give us the values of \(u\) and \(v\) respectively, as we have been aiming to do right from the beginning.
$$ u=u_{a v g}-f_{x} \frac{P}{D} $$
$$ v=v_{a v g}-f_{y} \frac{P}{D} $$
Here,
$$ P=\left(f_{x} u_{a v g}+f_{y} v_{a v g}+f_{t}\right) $$
$$ D=\left(f_{y}^{2}+f_{x}^{2}+\lambda\right) $$
We are super close to finding our two unknowns, \(u \) and \(v \), thereby, understanding the velocity of a particular pixel in both the \(x\)-direction as well as the \(y\)-direction.
However, we still have to figure out how to calculate \(u_{a v g} \) and \(v_{a v g} \). For this, we will design an iterative algorithm with certain specific steps that will help us finally reach our goal. Let’s see how.
The Algorithm
The algorithm is really simple. Here are the steps in brief, which we will take ahead to Python and understand the programmatic implementation of Optical Flow using Horn and Schunck method.
- Initialize \(u \) and \(v \) as zero matrices
- Compute \(f_{x} \), \(f_{y} \) and \(f_{t} \)
- Update \(u=u_{a v g}-f_{x} \frac{P}{D} \), and \(v=v_{a v g}-f_{y} \frac{P}{D} \)
- Repeat the above steps until the Cost Function is minimised
Now, let’s quickly get on to implementing the above Horn and Schunck algorithm using Python.
4. Implementation Using Python Code
We will start by importing the necessary libraries.
import cv2
import numpy as np
import matplotlib.pyplot as plt
from google.colab.patches import cv2_imshowNext, we will create two identical images with all zeros, of size \(256\times256 \) pixels, using the function np.zeros().
w,h = 256,256
gray_1 = np.zeros((w,h),dtype = np.uint8)
gray_2 = np.zeros((w,h),dtype = np.uint8)The following step is to create a ‘for’ loop and to iterate it over all pixel values, in order to create the grayscale transition along the diagonal of our images.
for i in range(256):
for j in range(256):
gray_1[i,j] = i//2+j//2
gray_2[i,j] = i//2+j//2Moving ahead, we will create a small mask of the size \(30\times30 \) in the top left corner of the first image using the function np.ones(). Next, we will set all pixel values to 200 and define the location of the mask in the first image along with the location of the mask in the second image. Notice that the location of the mask in the second image is shifted by 0 along the \(x\)-axis (\(dx=0\)), and by 2 along the \(y\)-axis (\(dy=2\)).
And, finally, we will subtract the first and the second image in order to see the difference in the displacement of the mask.
dx = 0
dy = 2
mask = np.ones((30,30),dtype = np.uint8)*200
gray_1[20:50,20:50] = mask
gray_2[20+dy:50+dy, 20+dx:50+dx] = mask
diff = cv2.subtract(gray_2, gray_1)cv2_imshow(gray_1)
cv2_imshow(gray_2)Output:


cv2_imshow(diff)Output:

Let’s print our result. Notice below, how we can see that all pixels in that image have values of zero except at the location where the mask was moved.
print(diff)Output:
[[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
...
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]]Now, we can use the function cv2.calcOpticalFlowFarneback() that computes a dense optical flow for each pixel using the Gunnar Farneback’s algorithm.
This function consists of the following parameters:
- prev – 8-bit single-channel input image
- next – Second input image of the same size and type as the first input image
- flow – Computed flow image with the same size as prev and type CV_32FC2
- pyr_scale – Parameter that specifies the image scale in order to build pyramids for each image;
pyr_scale =0.5represents a classical pyramid where each subsequent layer is twice as small as the previous one - levels – Number of pyramid layers including the initial image;
levels=1means that no extra layers are created and only the original images are used - winsize – Average window size where larger values increase the algorithm robustness to image noise and give more chances for fast motion detection, but yield more blurred motion field
- iterations – Number of iterations made at each pyramid level
- poly_n – Size of the pixel neighbourhood used to find polynomial expansion in each pixel. Larger values mean that the image will be approximated with smoother surfaces, yielding more robust algorithm and more blurred motion field. Generally, we take
poly_n =5orpoly_n =7 - poly_sigma – Standard deviation of the Gaussian that is used to smoothen the derivatives and is used as a basis for the polynomial expansion; for
poly_n=5, we can setpoly_sigma=1.1; forpoly_n=7, we can setpoly_sigma=1.5 - flags – This can be seen as a combination of the following:
- OPTFLOW_USE_INITIAL_FLOW uses the input flow as an initial flow approximation
- OPTFLOW_FARNEBACK_GAUSSIAN uses the Gaussian \(winsize\times winsize \)
- Filter instead of a box filter of the same size for optical flow estimation; usually, this option gives \(z\) more accurate flow than with a box filter, at the cost of lower speed; normally, winsize for a Gaussian window should be set to a larger value to achieve the same level of robustness.
flow = cv2.calcOpticalFlowFarneback(gray_1, gray_2, None, 0.5, 3, 39, 10, 11, 1.5,cv2.OPTFLOW_FARNEBACK_GAUSSIAN) Going ahead, we will now, remove the outliers generated from the optical flow process and then, plot this optical flow along the \(x\)-axis as well as along the \(y\)-axis.
#remove outliers
index = (np.abs(flow) > 100)
flow[index] = 0
index = (np.abs(flow)) < 0.001
flow[index] = 0
index_interesting = np.abs(flow) > 0.1#flow along y axis - v
plt.imshow(flow[:,:,1], cmap = 'gray')Output:

#flow along y axis - v
plt.imshow(flow[:,:,1], cmap = 'gray')Output:

An interesting tip here is that in order to estimate the average values for the flow, we can make use of a histogram, created for all points with absolute values larger than 0.1.
flow_hist = flow[index_interesting]
plt.hist(flow_hist.reshape(-1,1), bins = 50)Output:
(array([ 46., 56., 44., 33., 32., 15., 26., 7., 25.,
15., 14., 21., 20., 22., 14., 14., 31., 12.,
6., 10., 32., 6., 8., 9., 22., 9., 11.,
22., 11., 21., 13., 21., 16., 27., 20., 14.,
21., 23., 21., 20., 30., 26., 45., 36., 55.,
42., 74., 102., 201., 3073.]),
array([0.10095458, 0.13902189, 0.17708918, 0.2151565 , 0.25322378,
0.2912911 , 0.3293584 , 0.3674257 , 0.405493 , 0.4435603 ,
0.4816276 , 0.5196949 , 0.5577622 , 0.5958295 , 0.6338968 ,
0.6719641 , 0.7100314 , 0.74809873, 0.786166 , 0.8242333 ,
0.86230063, 0.9003679 , 0.9384352 , 0.97650254, 1.0145699 ,
1.0526371 , 1.0907044 , 1.1287718 , 1.166839 , 1.2049063 ,
1.2429737 , 1.2810409 , 1.3191082 , 1.3571756 , 1.3952428 ,
1.4333102 , 1.4713775 , 1.5094447 , 1.547512 , 1.5855794 ,
1.6236466 , 1.661714 , 1.6997813 , 1.7378485 , 1.7759159 ,
1.8139832 , 1.8520504 , 1.8901178 , 1.9281851 , 1.9662523 ,
2.0043197 ], dtype=float32),
<a list of 50 Patch objects>)
Observe the beautiful histogram above. As we can see that most of the pixels in the above histogram that have values greater than 0, are of the value 2. Now, let us plot these results using the HSV colourspace and observe the output.
hsv = np.zeros( (256,256,3), dtype = np.uint8)
hsv[...,1] = 255
mag, ang = cv2.cartToPolar(flow[...,0], flow[...,1])
hsv[...,0] = ang*180/np.pi/2
hsv[...,2] = cv2.normalize(mag,None,0,255,cv2.NORM_MINMAX)
rgb = cv2.cvtColor(hsv,cv2.COLOR_HSV2BGR)
plt.imshow(rgb)Output:

Now, let’s apply this code to the two consecutive frames of a video sequence. With the following command you can download images directly into your script.
!wget https://raw.githubusercontent.com/maticvl/dataHacker/master/DATA/Frame1.jpg -O "Frame1.jpg"
!wget https://raw.githubusercontent.com/maticvl/dataHacker/master/DATA/Frame2.jpg -O "Frame2.jpg" img1 = cv2.imread('Frame1.jpg')
img1 = cv2.cvtColor(img1,cv2.COLOR_BGR2RGB)
img2= cv2.imread('Frame2.jpg')
img2 = cv2.cvtColor(img2,cv2.COLOR_BGR2RGB)In order to calculate the Optical flow we need to resize our images.
img1.shape(358, 761, 3)img2.shape(357, 761, 3)img1 = cv2.resize(img1, (640, 320))
img2 = cv2.resize(img2, (640, 320))
M = np.zeros((2,3), dtype = np.float32)plt.imshow(img1)Output:

plt.imshow(img2)Output:

Here, we will subtract the first and the second frame.
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
plt.imshow(gray1, cmap = 'gray')
plt.imshow(gray2, cmap = 'gray')
gray_diff = cv2.subtract(gray1, gray2)
plt.imshow(gray_diff, cmap = 'gray')Output:

Finally, we can calculate the optical floe using the cv2.calcOpticalFlowFarneback()function.
flow = cv2.calcOpticalFlowFarneback(gray1, gray2, None, 0.5, 5, 15, 3, 5, 1.2, 0) hsv = np.zeros( (320,640,3), dtype = np.uint8)
hsv[...,1] = 255
mag, ang = cv2.cartToPolar(flow[...,0], flow[...,1])
hsv[...,0] = ang*180/np.pi/2
hsv[...,2] = cv2.normalize(mag,None,0,255,cv2.NORM_MINMAX)
rgb = cv2.cvtColor(hsv,cv2.COLOR_HSV2BGR)
plt.imshow(rgb)Output:

That’s a beautiful Optical Flow output that we have received above using the Horn and Schunck algorithm. We should be proud of what we have learnt today as Optical Flow is one of the deepest and the most complex topics to explore in the field of computer vision.
By understanding complex mathematical concepts and learning how to apply them in the most simplistic manner is how we efficiently build models in Machine Learning, and we would like to continue following this co-learning and co-sharing philosophy with our upcoming blog posts as well. Before you go, let’s summarise the learnings of today.
Horn and Schunck Algorithm For Optical Flow
- Optical Flow is the process of estimating the direction and velocity of each pixel in subsequent frames of a video sequence
- Unlike other methods, Optical Flow detects motion of a pixel in consecutive frames as well
- There are two types of Optical Flow: Sparse Optical Flow and Dense Optical Flow
- Horn and Schunck method is a classical optical flow estimation algorithm proposed in 1981
- Brightness Constancy Assumption proposes that lighting doesn’t change significantly between consecutive frames
- Smoothness Constraint Assumption fixes the shortcomings of the brightness constancy assumption
- Laplacian masks are used to reduce sensitivity to noise once smoothing is performed
Summary
Well folks, that’s it for this tutorial post! We hope you are enjoying our lessons. If you are facing any difficulty or have a suggestion for us on how to improve our teaching methodology, do leave us a comment. Also, share with us which is the first video on which you would think of applying the Horn and Schunck optical flow method. We will be back with some more interesting tutorials. Till then, keep it smooth! 🙂
Here you can download code from our GitHub repo.
References:
[1] Introduction to Motion Estimation with Optical Flow by Chuan-en Lin
[2] Horn, Berthold KP, and Brian G. Schunck. “Determining optical flow.” Techniques and Applications of Image Understanding. Vol. 281. International Society for Optics and Photonics, 1981.