#005 CNN Strided Convolution
Strided convolution
A strided convolution is another basic building block of convolution that is used in Convolutional Neural Networks. Let’s say we want to convolve this \(7 \times 7 \) image with this \(3 \times 3 \) filter, except, that instead of doing it the usual way, we’re going to do it with a stride of \(2 \).

Convolutions with a stride of two
This means that we take the element-wise product as usual in this upper left \(3 \times 3 \) region, and then multiply and sum elements. That gives us \(91 \). But then instead of stepping the blue box over by one step, we’re going to step it over by two steps. It’s illustrated how the upper left corner has gone from one dot to another jumping over one position. Then we do the usual element-wise product and summing, and that gives us \(100 \). Next, we’re going to do that again and make the blue box jump over by two steps. We obtain the value \(83\). Then, when we go to the next row, again we take two steps instead of one step. We will move filter by \(2 \) steps and we’ll obtain \(69 \) .
In this example we convolve \( 7 \times 7 \) matrix with a \(3 \times 3 \) matrix and we get a \(3 \times 3 \) output. The input and output dimensions turns out to be governed by the following formula:
$$ \lfloor \frac{n – f + 2p}{s} \rfloor +1 \times \lfloor \frac{n – f + 2p}{s} \rfloor +1 $$
If we have \(n \times n \) image convolved with an \(f \times f \) filter and if we use a padding \(p \) and a stride \(s \), in this example \( s=2 \), then we end up with an output that is \(n-f+2p \). Because we’re stepping \(s \) steps at the time instead of just one step at a time, we now divide by \(s \) and add \(1 \).
In our example, we have \((7+0-3)/2 +1 = 4/2 +1 =3 \) , that is why we end up with this \(3 \times 3 \) output. Notice that in this formula above, we round the value of this fraction, which generally might not be an integer value, down to the nearest integer.
Let’s summarize the dimensions in the following tabel.
| size of an input image | size of a filter | padding | stride | size of an output |
| $$ n\times n $$ | $$ f\times f $$ | $$ p $$ | $$ s $$ | $$ \lfloor \frac{n – f + 2p}{s} \rfloor +1 \times \lfloor \frac{n – f + 2p}{s} \rfloor +1 $$ |
Table with dimensions of values that we used for convolution
It is nice when we can choose all of these numbers so that the result is an integer, but rounding down is also fine.
Tehnical note on cross-correlation vs. convolution
Before moving on, there is a technical comment to make about cross-correlation vs convolution but depending the different math textbook or signal processing textbook there is one inconsistency in the notation .
A correlation is an overloaded metric that can have multiple interpretations, one of them is cross-correlation. A convolution is similar to cross-correlation.
Correlation is a measurement of the similarity between two signals/sequences.
Convolution is a measurement of the effect of one signal on the other signal.
The mathematical calculation of a correlation is the same as convolution in a time domain, except that the signal is not reversed before the multiplication step. If the filter is symmetric then the output of both expressions would be the same. More about this you can read here.
Convolution – when applied a filter is fliped
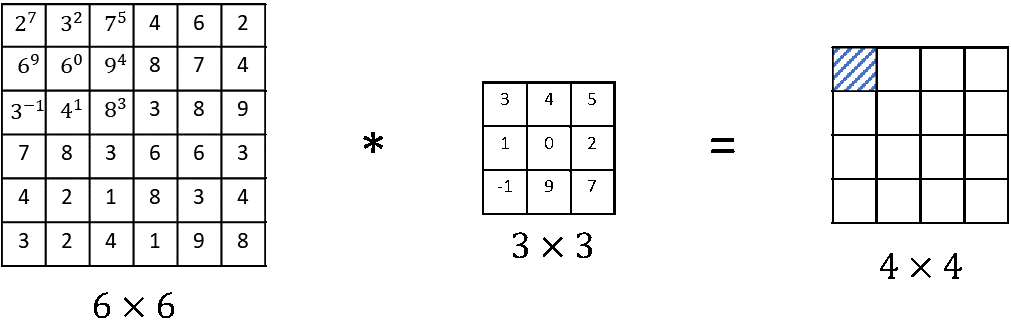
If we look at a typical math textbook the way that the convolution is defined, before doing the element-wise product and summing, there’s actually one other step that we would first take, which is to convolve this \(6 \times 6 \) matrix with the \(3 \times 3 \) filter. First, we would take the \(3 \times 3 \) filter and flip it on the horizontal as well as the vertical axis.
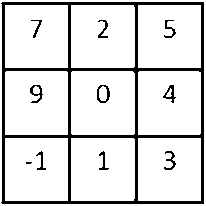
A flipped filter
This is really taking the \(3 \times 3 \) filter and mirroring it both on the vertical and the horizontal axis. And then it was this flipped matrix that we would then copy over here. So to compute the output, we would take \(2\times7 + 3\times2 + 7\times5 \) and so on. And we actually multiply out the elements of this flipped matrix in order to compute the upper left hand most element of the \(4 \times 4\) output as follows. And then we take those \(9 \) numbers and we put them over one by one and so on.
The way we’ve defined the convolution operation in these posts is that we’ve skipped this mirroring operation. In the deep learning literature by convention we just call this a convolution operation. To summarize, by convention in machine learning we usually do not bother with this flipping operation and technically this operation is maybe better called cross-correlation, but most of the deep learning literature just calls it the convolution operator.
We’ve now seen how to carry out convolution and we’ve seen how to use padding as well as strides for convolutions. So far we’ve been using convolutions over matrices. In our next post we will see how to carry out convolutions over volumes. This would suddenly make convolution much more powerful.
In the next post we will learn more about convolution in RGB image.