Unveiling the Era of AI-Generated Content: From GANs to ChatGPT
Highlights:
In today’s digital world, three groundbreaking AI models are grabbing everyone’s attention – ChatGPT, DALL-E-2, and Codex. People are curious and eager to understand how these amazing tools work. These models belong to a fascinating area called Artificial Intelligence Generated Content (AIGC), wherein computers create pictures, music, and text. Come, let’s explore this exciting realm together and learn about the magic behind ChatGPT and its AI pals in our upcoming posts
In this first chapter, we will explore the evolution of AI Generative Models starting from GANs to ChatGPT. We will highlight their main applications and demystify a high-level idea of how these models work. So, without further ado, let’s dive in!
1. Introduction
In recent years, Artificial Intelligence Generated Content has gained a lot of attention with the mind-blowing results of ChatGPT, DALL-E-2, and Codex, to name a few.
These models are predominantly developed by tech giants who have also managed to train them with the help of large computational power. For instance, OpenAI is one of the leading companies in this area, followed by Google, Meta, Microsoft, and others.
Nowadays, we are all familiar with ChatGPT, which represents a conversational AI system that can interpret and interact with humans meaningfully. When it was launched, it became so popular that people started to speculate that it would soon replace Google’s search engine. Although that did not happen, Microsoft integrated its version of the AI language model (XiaoIce) into its search engine Bing as a rival to ChatGPT.
In contrast, DALL-E-2 is an AI agent that inputs text prompts and generates realistic images. OpenAI also develops it.
Have a look at Figure 1 above for some impressive examples.
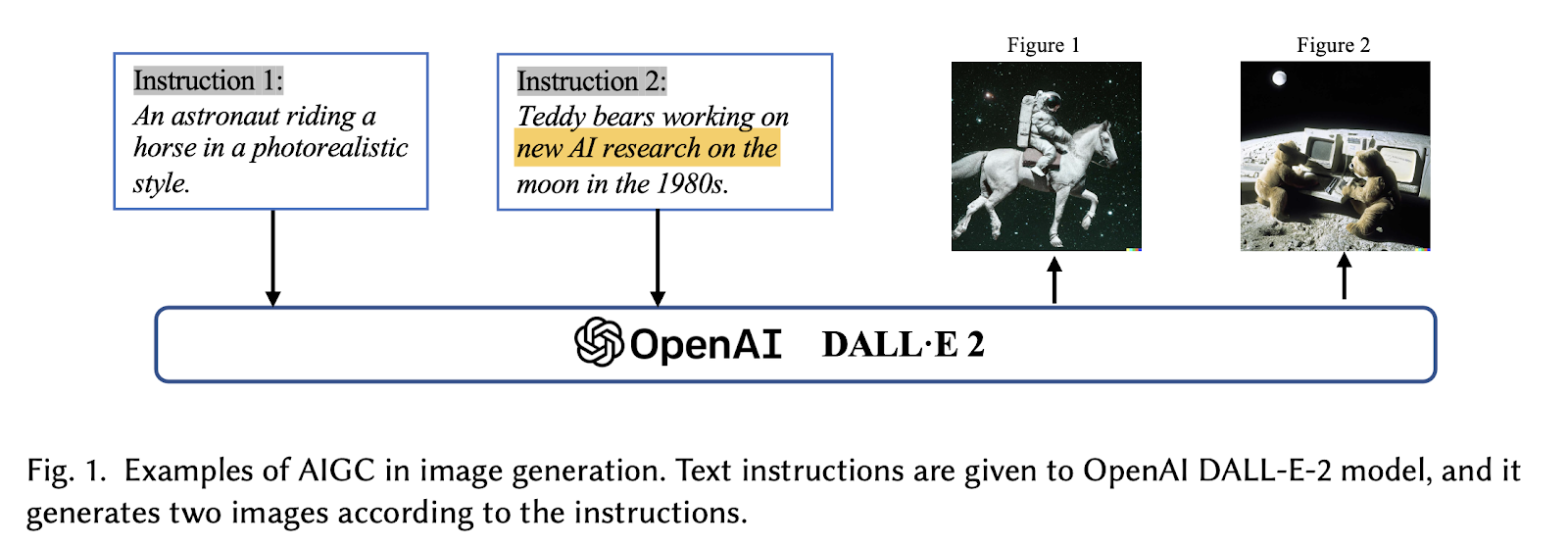
When we speak about AIGC, or Gen AI we recognize two steps:
- The human intent, i.e. a human prompt input
- The generative process according to the extracted intention
Although these steps are not new in AI, the quality of the generated results that the above models achieve is rather impressive.
For instance, while the core framework of GPT-3 remains similar to that of its predecessor, GPT-2, significant enhancements have been made in pre-training data and model size. GPT-3’s pre-training data size has expanded from WebText (38 GB) to CommonCrawl (570 GB after filtering), and its foundational model size has increased from 1.5 B to 175 B parameters. This way, GPT-3 shows better generalization ability on various tasks such as human intent extraction.
In addition to model size and training data, researchers are also exploring ways to utilize reinforcement learning and improve the model. For this, they rely on human feedback to study and score every output of these models. Using this, they can determine the most appropriate response, and thus, improve the model’s reliability and accuracy.
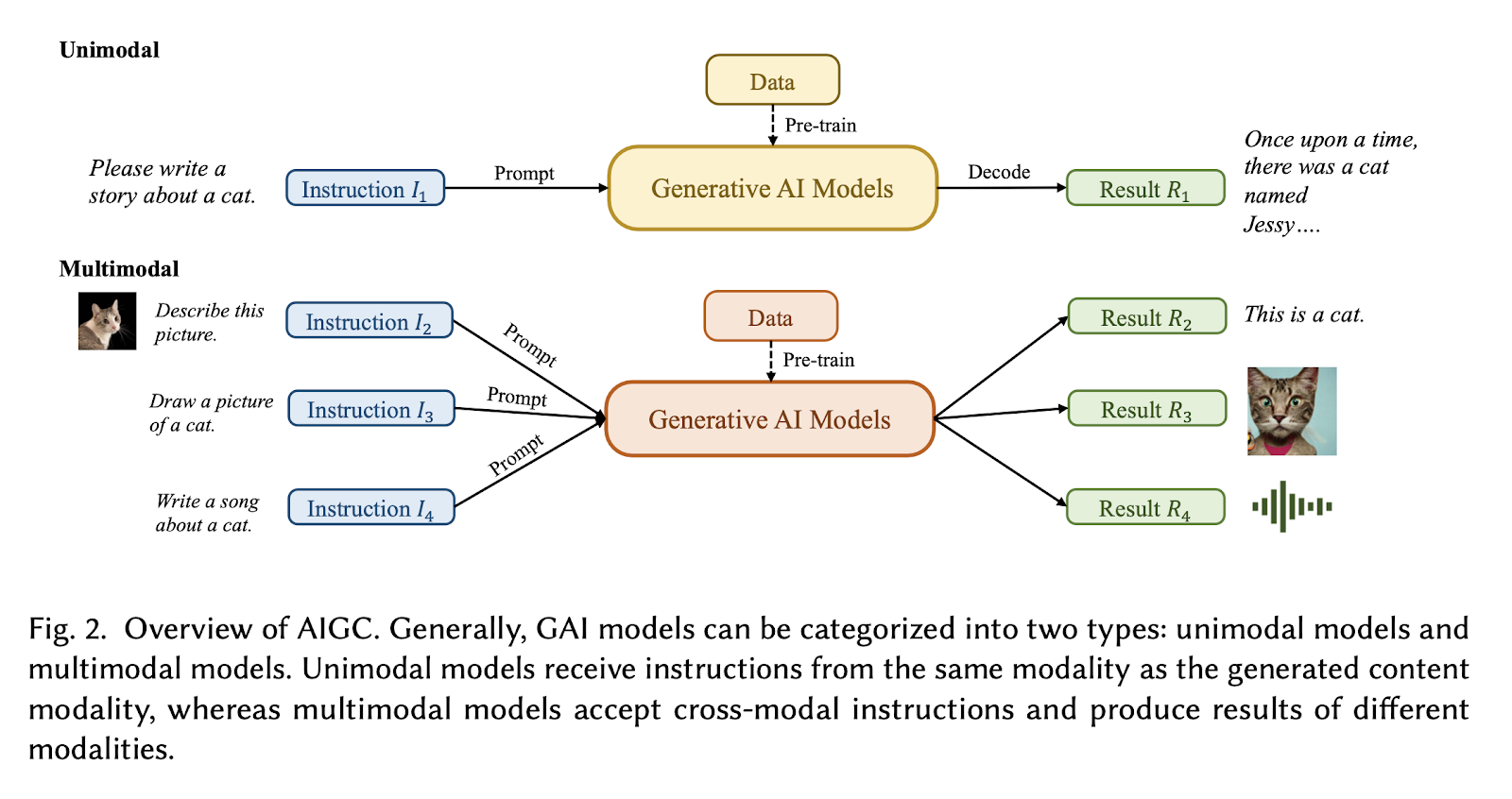
Let us now talk about Gen AI models which can be categorised into two classes.
The first one is Unimodal, like ChatGPT. It receives text as input and also generates text as output.
On the other hand, models like DALL-E-2 are called multimodal, wherein a text prompt is received as input but the output is in the form of images. An example of unimodal and multimodal AI systems can be seen in Figure 2 above, where distinct input-output relationships and functionalities are illustrated.
With that brief introduction, let’s learn about the history of Gen AI. Post that, we will discuss some of the historical ideas we studied and then finally, we will discuss their applications and point out the challenges, concerns and open up research questions.
2. History of Generative AI
Generative models boast a rich historical lineage, dating back to the 1950s with the advent of pioneering models like Hidden Markov Models (HMMs), autoencoders, and mixture models. Initially employed for tasks such as time series analysis and speech processing, their utility has soared in recent years, witnessing remarkable performance strides applicable to real-world scenarios.
Additionally, Recurrent Neural Networks (RNNs), renowned for their proficiency in language modeling, have emerged as formidable tools capable of capturing intricate linguistic structures and long-term dependencies. Augmenting this arsenal are Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs), pivotal in advancing NLP applications.
In the realm of computer vision, the era preceding deep learning models witnessed the use of image-generation techniques such as texture synthesis and mapping. These methods, often referred to as handcrafted features, were limited in their ability to produce diverse images. However, a monumental shift occurred in 2014 with the advent of generative adversarial networks (GANs). Alongside GANs, variational autoencoders and diffusion generative models also emerged, offering fine-grained control over the image generation process. These advancements have led to the production of exceptionally high-quality images, ushering in a new era of possibilities in computer vision.
Generative models, originating from diverse paths, have converged at a significant intersection – the transformer architecture. Initially introduced by Vaswani in 2017 for NLP tasks, transformers have since transcended their original domain and become a dominant backbone for generative models across various fields.
In natural language processing, the rise of large language models like BERT and GPT has showcased the prowess of transformer-based architectures, surpassing traditional models like LSTM and GRU. Simultaneously, the Vision Transformer (ViT) and SWIN transformers also emerged, leveraging transformer architecture to achieve remarkable results.
Furthermore, transformers have facilitated the integration of multiple modalities, enabling the development of multimodal models like CLIP. By combining visual and textual components within a transformer framework, CLIP can be trained on extensive datasets encompassing both text and image data. This breakthrough allows for the creation of encoders that accept textual prompts and generate corresponding images — a testament to the transformative capabilities of transformer-based architectures across diverse domains.
Have a look at Figure 3 below where the entire timeline of Gen AI model development in recent years is shown. We can also see the evolution of both text and image-generative models over the past decade.
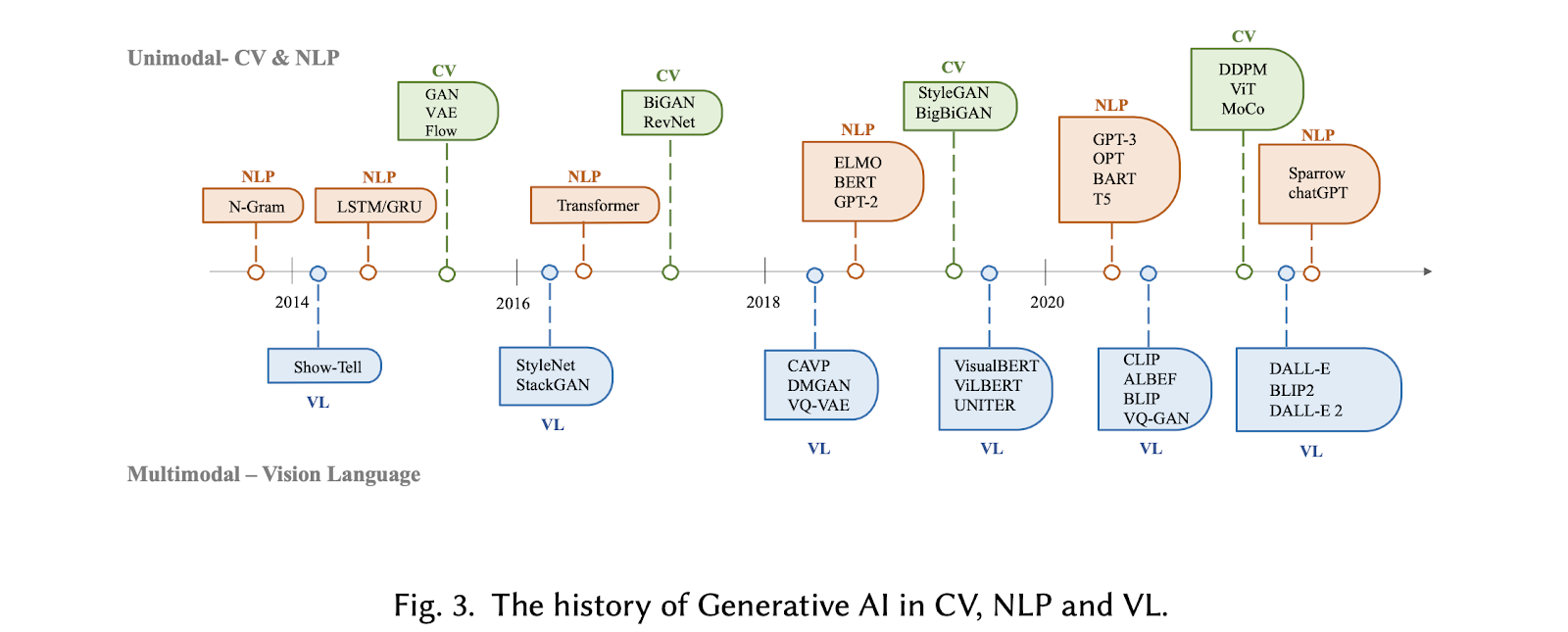
3. Foundations for AIGC (Artificial Intelligence Generated Content)
The transformer is one of the most pivotal models to emerge in the evolution of content generation through AI. It is the foundational architecture for a myriad of state-of-the-art models like GPT-3, DALL-E-2, and Codex. It addresses the limitations of traditional models such as RNNs in handling variable-length sequences and context awareness. At the heart of the transformer lies the self-attention mechanism, enabling a model to selectively focus on different segments within an input sequence.
Comprising both an encoder and a decoder, the transformer operates by processing input sequences to generate hidden representations, which are then utilised by the decoder to produce output sequences. Each layer of both the encoder and decoder is composed of multi-head attention and a feed-forward neural network, also known as a multi-perceptron. The multi-head component is of particular significance as it learns to assign varying weights to tokens based on their relevance, thus facilitating long-term dependency modeling and enhancing performance across a wide range of NLP tasks.
Another notable advantage of the transformer architecture is its high level of parallelizability, allowing for efficient large-scale pre-training. This inherent scalability and versatility have cemented the transformer’s status as a cornerstone in the landscape of generative AI models.
Pre-trained Large Language Models
Since the inception of the transformer architecture, it has emerged as the dominant choice for numerous NLP tasks, owing to its parallelism and learning capabilities. Pre-trained large language models, in particular, have garnered widespread adoption and are typically categorized based on their training tasks. These models commonly fall into two types:
- Autoregressive Language Modelling
- Masked Language Modelling
Autoregressive Language Models, exemplified by GPT-3, aim to predict the probability of the next token when provided with preceding tokens, effectively performing left-to-right language modeling.
Conversely, Masked Language Modelling, as seen in models like BERT, involves predicting the probability of a masked token within a sentence, leveraging context information. For instance, in a sentence composed of multiple tokens, a Masked Language Model predicts the likelihood of a masked token based on its surrounding context. While both approaches have their merits, Autoregressive Models are often preferred for generative tasks.
4. Vision Generative Models
GANs
Generative Adversarial Networks (GANs) have surged in popularity over the last decade since their introduction by Ian Goodfellow in 2014. Comprising two key components, the generator, and the discriminator, GANs operate on a unique adversarial principle.
The generator is tasked with learning the distribution of real data samples and generating new data samples accordingly. On the other hand, the discriminator acts as a sort of “police officer,” distinguishing between real and fake data by examining their characteristics. Its role is to identify whether the data originates from the real database or has been artificially generated by the generator. This adversarial interplay between the generator and discriminator drives the training process, ultimately leading to the generation of high-quality synthetic data.
One of the most renowned advancements in the realm of generative models is the Conditional Generative Adversarial Network (CGAN). This innovative approach enables explicit control over high-level attributes and their variations. By providing intuitive control and yielding superior performance in terms of quality metrics, interpolation, and disentanglement, CGAN has left an indelible mark on the field.
Other notable players include InfoGAN and ACGAN, where the generator and discriminator are augmented with additional information such as class labels or data from other modalities. Conditioning on specific attributes plays a pivotal role in these models, shaping their objective functions and guiding their training process. Key breakthroughs have been achieved with methods that ensure stable training of GANs and facilitate the convergence of generated data. Techniques such as WGAN (Wasserstein) and LSGAN (Least-squares) have significantly contributed to these advancements, propelling the field forward with their enhanced stability and convergence properties.
You can learn all about GANs in our previous posts here: <link>
If you want to know more about Autoencoders (AE) or go deeper into Variational Autoencoders, you can follow this link and read up: <link>
Diffusion Models
The latest class of generative models, known as Generative Diffusion Models (GDM), have garnered significant attention in the field of computer vision, boasting state-of-the-art results. These models operate on a novel mechanism wherein they progressively corrupt the data with multiple levels of noise perturbations and then attempt to reverse this process by learning to generate samples from corrupted data. GDMs can be broadly categorized into three basic types: Autoregressive Diffusion Models (ADMs), Markov Chain Diffusion Models (MCDMs), and Score-Based Generative Models (SGMs).
- Autoregressive Diffusion Models (ADMs): ADMs apply autoregressive models to iteratively update and refine the corrupted data, gradually reducing the noise levels and recovering the original samples.
Markov Chain Diffusion Models (MCDMs): MCDMs utilise Markov chains to iteratively update the noisy data, progressively refining it through a forward diffusion process. By learning Markov transition kernels, MCDMs aim to recover the original data distribution.
Score-Based Generative Models (SGMs): SGMs operate directly on the gradient of the log density of the data, also known as the score function. By perturbing data with multiscale noise and conditioning on noisy levels, SGMs aim to intensify the score function of all noisy data distributions through neural networks.
Multimodal Models
So far, we’ve delved into models that specialize in either text or image generation. However, the landscape is shifting towards multimodal models, capable of synthesizing diverse types of data within a unified framework. In our next exploration, we’ll venture into the realm of multimodal models, which play a central role in the realm of AI-generated content. Integrating different modalities, such as text and images, poses unique challenges, as the relationship between them can be intricate and difficult to learn. This complexity makes the representation space significantly more challenging to navigate compared to unimodal models. Nevertheless, the emergence of powerful modality-specific architectures and an increasing number of methodologies have been developed to address this issue.
One standout example is the state-of-the-art visual-language generation models, which excel in tasks such as generating textual descriptions from images or generating images from textual prompts. Additionally, graph generation models and text-to-code generative models are pushing the boundaries of multimodal AI. Importantly, many of these models are closely tied to real-world applications, highlighting their practical significance in various domains.
Have a look at Figure 4 below which shows an example of a language vision model.
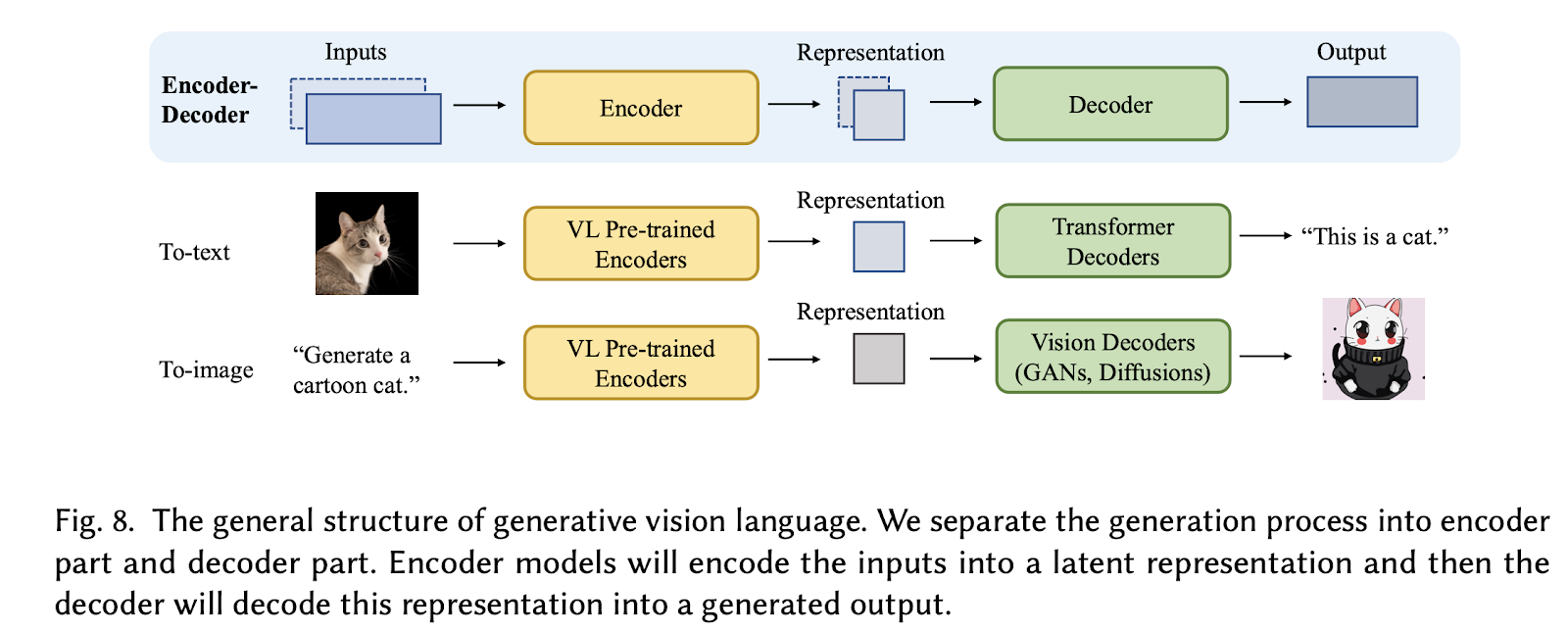
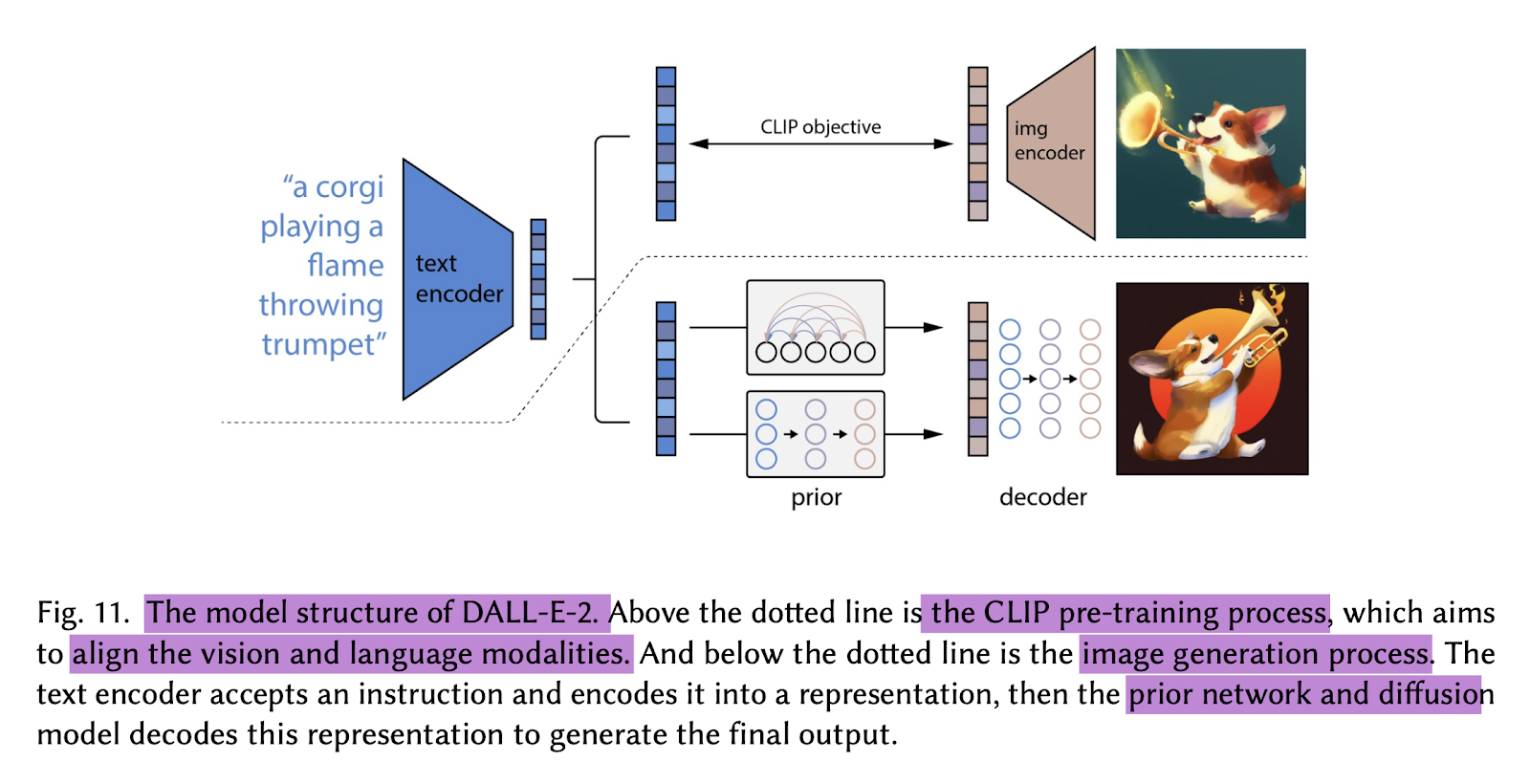
In Figure 5, we can see one of the most famous models we know of today, the DALL-E-2. DALL-E-2, an advanced version of the original DALL-E model developed by OpenAI, is renowned for its groundbreaking ability to generate highly realistic images from textual descriptions. It builds upon its predecessor’s capabilities, offering enhanced image generation with greater fidelity and creativity. Additionally, DALL-E-2 is closely integrated with CLIP (Contrastive Language-Image Pretraining), a powerful multimodal model that enables joint understanding of text and images, further enriching DALL-E-2’s capacity to generate contextually relevant and visually appealing images based on textual prompts.
Furthermore, within the realm of generative models, various modalities have been explored, including text, audio, music, graph, knowledge graphs, semantic parsing, molecule generation, and notably, text-to-code generation.
Text-to-code generation involves mathematically generating programming code from natural language descriptions, offering valuable assistance to programmers. Recent advancements in large language models have showcased remarkable potential in text-to-code generation, enabling the translation of natural language descriptions into executable code. However, aligning these diverse modalities poses a significant challenge, as they each operate within distinct spaces and require intricate synchronization.
5. Applications
Chatbots
Chatbots are computer programs designed to engage in conversations with human users via text interfaces, responding to queries and interactions in a manner that simulates natural conversation. They can be programmed to perform a variety of tasks, from providing customer support to answering frequently asked questions directly. This versatility and ability to interact with users in real-time makes chatbots invaluable tools in various domains.
Art
AI art represents a significant advancement in the field of creative expression, allowing for the creation of original artworks using generative AI models trained on vast datasets of existing art. Through machine learning techniques, these models can generate new pieces of art that embody various styles and artistic directions. Notable mentions include diffusion-based models like DALL-E 2, developed by OpenAI, renowned for its ability to rapidly generate high-quality images and push the boundaries of artistic exploration. Artists have embraced AI art as a means to explore novel artistic directions and expand the realm of creative possibilities.
In addition, music, coding and education are important areas where Gen AI is progressively applied.
6. Efficiency in Gen AI Models
In the past decade, machine learning models have undergone a transformative evolution, catalyzed by milestones like the ImageNet competition, which spurred the development of increasingly deep and complex models. Models such as BERT and GPT-3 have emerged with staggering numbers of parameters, posing challenges related to both training and inference.
The question arises – “who has the capability to train such models, given their intensive computational requirements?” This not only concerns expensive hardware but also touches on issues of inference efficiency, particularly regarding real-time applications. While tech giants typically possess the resources to train such models using powerful hardware setups and distributed training across multiple devices, considerations of training efficiency and data volume remain paramount in achieving optimal performance.
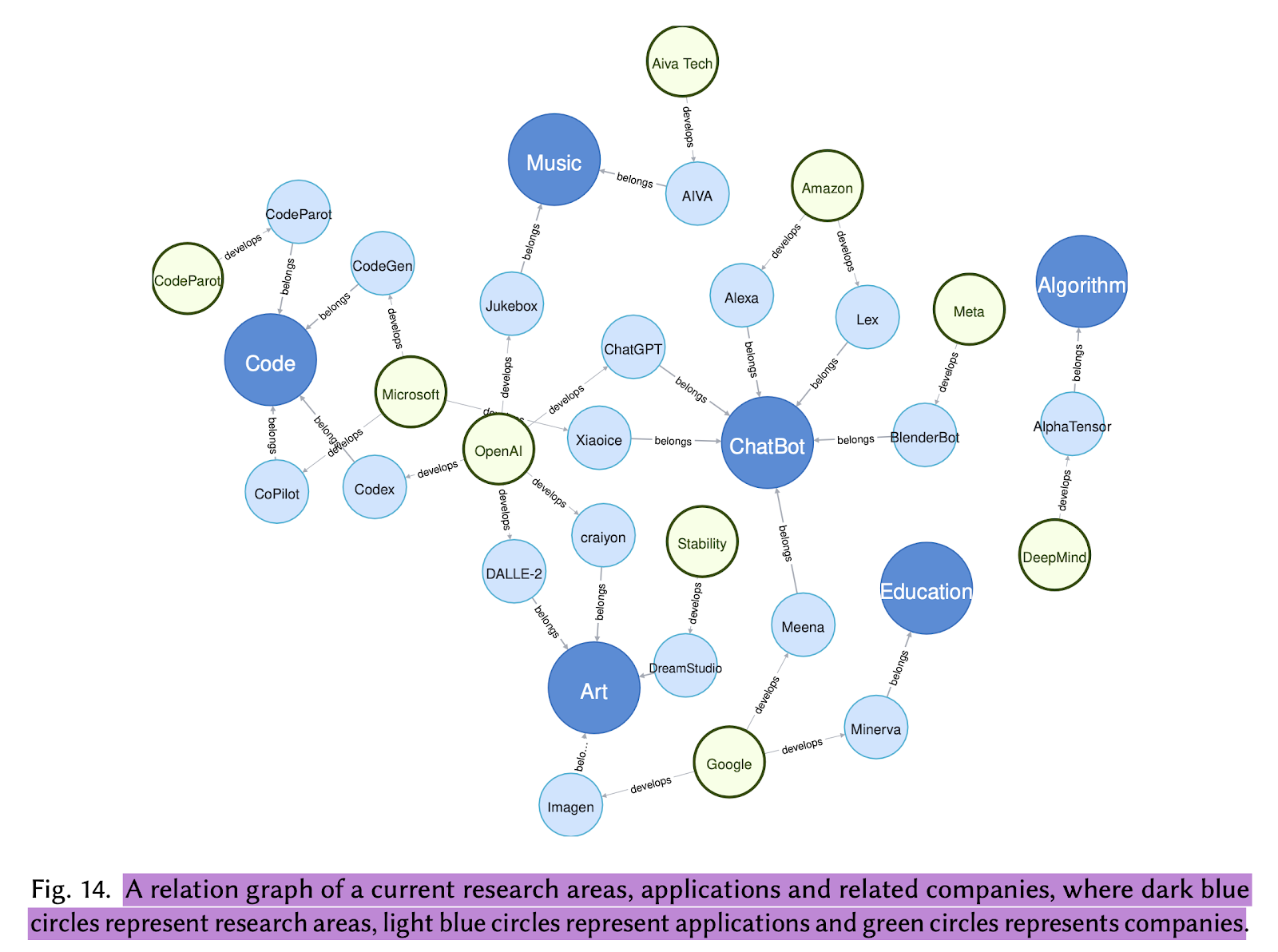
Figure 6 below shows a graph that represents popular AI tech companies, domain applications, and model names.
7. Trustworthy & Responsible Gen AI
Generative AI holds immense potential to assist humans across various applications; however, it also raises significant concerns regarding security and privacy, often referred to as the “dark side” of generative AI.
One major concern is the generation of misleading or unreliable content by models like ChatGPT, which may produce factual-sounding but inaccurate outputs, posing a threat to the integrity of information. Similarly, multimodal generators like Stable Diffusion have the capability to create convincing images, raising worries about the dissemination of harmful or biased content. To mitigate these risks, it’s crucial to ensure that AI-generated content is helpful, harmless, and free from biases or misinformation. Human feedback mechanisms play a vital role in rewarding accurate answers and suppressing irrelevant information, but improvements are still needed.
Privacy is another critical issue, with membership inference attacks being a particular concern. These attacks aim to determine whether a specific data point belongs to the training set, potentially leading to the leakage of sensitive information. Advanced techniques like text-to-image generation and diffusion-based models are vulnerable to such attacks, as they rely on memorization properties inherent in large-scale models.
Recent research suggests that diffusion models, including Stable Diffusion, are more susceptible to privacy breaches compared to earlier generative adversarial networks. Addressing these security and privacy challenges is essential for ensuring the responsible and safe use of generative AI technologies.
8. Open Problems & Future Directions
So far, we’ve witnessed the successful utilization of generative AI across numerous applications. Yet, its application in high-stakes domains like healthcare, finance, and autonomous vehicles remains limited due to the critical nature of these fields and their requirement for high accuracy and reliability. To bridge this gap, specialized datasets and continuous learning mechanisms are crucial, ensuring models are up-to-date and capable of handling diverse scenarios. However, while generative AI models exhibit remarkable capabilities, they still struggle with tasks requiring common sense reasoning. Prompting methods offer a promising approach to address this challenge.
Looking ahead, scaling up poses a significant challenge in large-scale training, given constraints such as compute budget and dataset availability. Furthermore, the development of generative AI raises important social concerns, including bias and the impact of AI-generated content on various stakeholders.
9. Conclusion
To summarize, this overview was aimed at providing you with a concise yet comprehensive understanding of generative AI models, their applications, concerns, and future directions. We delved into both unimodal and multimodal AI models and discussed issues of trustworthiness and responsibility. We hope we have equipped you with the knowledge to explore specific applications of generative AI further. We’ll be back with more posts soon.
Literature
This introductory tutorial post is based on the following paper:
Cao, Yihan, Siyu Li, Yixin Liu, Zhiling Yan, Yutong Dai, Philip S. Yu, and Lichao Sun. “A comprehensive survey of ai-generated content (aigc): A history of generative ai from gan to chatgpt.” arXiv preprint arXiv:2303.04226 (2023).


