#002 CNN Edge detection
Convolutional operation
The operation of the convolution is one of the foundations of the convolutional neural networks. From the Latin word \( convolvere \), “to convolve” means to roll together. For mathematical purposes, a convolution is the integral measuring how much two functions overlap as one passes over the other. Think of a convolution as a way of mixing two functions by multiplying them.
Using the edge detection as a starting point, we will see how the convolution operator works. Usually, earlier layers of the standard neural network can detect the edges, and then some later layers can detect parts of the objects as we can see in the pictures below. Furthermore, later layers can detect parts of complete objects such as faces.

Example of an edge (left), feature (center) and face detection (right)
In this post we will see how we can detect the edges in the picture, as the essential task in a computer vision.
Edge detection – vertical and horizontal edge detection
Given an image, we want the computer to understand which objects are in this image. The first thing and the simplest we can do is to detect the vertical and horizontal edges.
How can we discover the edges in the picture?
Let’s have a look at an example!
We have a \(6 \times 6 \) pixel image. Since this is a gray image, we will have a \(6 \times 6 \times 1 \) dimension, instead of \(6 \times 6 \times 3 \), because in this case there are no RGB channels.
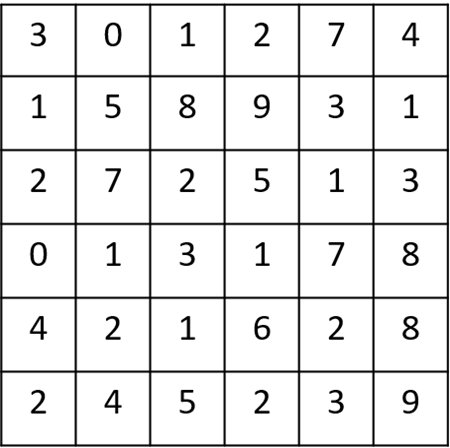
An example of a \(6 \times 6 \) image and it’s pixel intensity values
Detecting a vertical edge
In order to discover the vertical edges in this image, we can construct a \(3 \times 3 \) matrix. Using the terminology of the convolutional neural networks, we will call it a filter. Sometimes researchers call this a kernel instead of a filter, but we will use the filter terminology. We take a picture of \(6 \times 6 \) pixels and perform a convolution operation with \(3 \times 3 \) filter. The convolution operation is marked with an asterisk \(*\). You may be confused with this mild disagreement in notation. Namely, in mathematics, the star is a standard symbol for a convolution, but in Python this also means the multiplication or perhaps the element by element multiplication. We will be clear in the following posts by indicating when this star refers to the convolution.
The final product of this convolution process will be a \(4 \times 4 \) matrix that can be interpreted as a \(4 \times 4 \) image. The way we calculate this \(4 \times 4 \) output is as follows: in order to calculate the first element (top left-hand corner) of this \(4 \times 4 \) matrix, we take a \(3 \times 3 \) filter and paste it to the top of the \(3 \times 3 \) region of the original input image.
Then we should take a product of elements. The first one will be \(3 \times 1 \), the second will be \(1 \times 1 \) and so on. Thus, we have calculated the upper left-hand element of the \(4 \times 4 \) output matrix, which is \(-5 \). By repeating this procedure, we get the remaining elements.

Next, we can see that the images and filters are actually matrices of different dimensions. However, the left-hand matrix is appropriately interpreted as an image, whereas the one in the middle should be interpreted as a filter. The matrix on the right side can be interpreted as an output (filtered) image. This filtering process represents a vertical edge detector.
If we want to implement this process in a certain programming language, we will use “of-the shelf” functions instead of a star that denotes a convolution. For example, there is a tf.nn.conv2d function in the TensorFlow library, while in Keras there is a function called Conv2D. In all the frameworks of deep learning that have a good support for a computer vision, there will be a function for the convolution operator, already implemented. The question arises, why is this filtering, a vertical edge detector? Let’s look at another example.
To illustrate this, we will use a simplified picture. Here is a tiny picture of \(6 \times 6 \) pixels, where the left half of an image are 10s, and the right half are \(0s \).

Edge detection – an original image (left), a filter (in the middle), a result of a convolution (right)
Assuming that this is a picture, it might be sketched as the left half having brighter pixel intensity values, and the right half having darker values. We use a shade of gray color to mark zero values. Obviously, in the middle of this picture there is a strong vertical edge because it passes from white to darker colors. We will convolve this with the \(3 \times 3 \) filter that can be visualized as follows. We see brighter pixels on the left \((1) \), then there is light gray tone for zeros in the middle, and the dark tone on the right for the negative values \((-1) \). The result of the convolution is the matrix on the right (with \(0s \) and \(30s \) ).
We can easily check the calculation of the output matrix using the convolution formula:
$$ 10\times 1+10\times 0+10\times \left ( -1 \right )+10\times 1+10\times 0+10\times \left ( -1 \right )+0\times 1+0\times 0 +0\times \left ( -1 \right )= 0 $$
If we interpret the matrix on the right as an image, there will be a lighter region (white) in the middle, that corresponds to the vertical edge detected in the center of an original \(6\times 6 \) image.
In case that the dimensions looked odd, that is, if the detected edge looks thick, that’s just because we work with very small images in this case. If we use a picture of \(1000\times 1000 \) instead of \(6\times 6 \), then we will discover that the convolution works remarkably well when we are detecting the vertical edges in the picture. In this example, the bright region in the middle is just the way of the output image to say that there is a strong vertical edge right in the middle of the image.
In the next post we will learn more about edge detection.