Attention is all you need – Transformers
Highlights:
- What is attention?

Starting with this post, we delve into the intriguing concept of ‘attention’ in visual perception. It’s natural to focus on certain elements when we see an image. We instinctively find the most significant components of that image and examine it more than other elements. This concept is exemplified by a process which is known as ‘saliency’ in the field of computer vision and is visualized as a heat map. This ‘heat map’ reveals where the average human eye would typically linger on an image, a metric quantifiable with an eye-tracking device. By deriving the most focused aspects of an image, we decipher the essence of that image while simultaneously disregarding peripheral elements such as background scenery or extraneous objects. Thus, the sky, forests, or roads fade into insignificance if they lack relevance to the focal point.
The Origin of ‘Attention’ in Computer Vision
Historical Context
Before 2017, AI fields operated relatively independently of each other. After 2012, and the introduction of AlexNet, the Deep Learning field exploded and research papers started to look something like as shown in Figure 2 below.
Within computer vision, there exists a subfield known as Object Detection. In earlier research, developers would devise algorithms like the Histogram of Oriented Gradients (HOG) to tackle specific tasks such as identifying cars in images. However, these algorithms, often handcrafted and engineered, typically fell short in practical applications due to their limited performance.
Figure 3 below shows a research paper that studies and showcases the challenges and limitations of methods like HOG. The paper makes evident the need for more robust and efficient solutions and makes a shift towards more sophisticated approaches in AI research and development.
 |  |
| Example of a paper describing an algorithm for scene classification | False positive detections: In this case, a tree is classified as a car with a very high accuracy of 99%. |
- Using RNNs for ‘Attention’
The emergence of attention mechanisms and transformers marked a pivotal moment in the field of artificial intelligence, particularly with the publication of the paper “Attention is All You Need” by Vaswani et al. in 2017 [2]. Initially focused on addressing challenges in Natural Language Processing (NLP), this paper introduced a groundbreaking approach to machine translation, exemplified by the automatic translation of text from German to English.
Since many state-of-the-art algorithms started relying on attention mechanisms and transformers, the study of their fundamental concepts becomes even more essential for advanced research and development. Let’s try and dive further into the details of attention, the origins of attention-based models from NLP, and their widespread adoption in various AI fields, including Computer Vision.
During the period spanning 2014 to 2017, many challenges in Natural Language Processing (NLP) were tackled using Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) sequence architectures. A prominent example is the machine translation problem, which can be framed as a sequence-to-sequence problem. In such setups, encoder and decoder structures were commonly employed, akin to various other AI fields. The encoder’s role was to distill knowledge from the training database into a coherent latent space, while the decoder would then utilize this latent space to search and reconstruct the original data.
Although this architecture was prevalent, its limitations became increasingly apparent, paving the way for transformative approaches such as attention mechanisms and transformers.
If you want to learn more about encoder/decoder architectures, you can read one of our earlier posts here: https://datahacker.rs/gans-004-variational-autoencoders-in-depth-explained/
Now, RNNs are not ideal as they have some limitations as well.:
- Computation for long sequences is challenging
- Vanishing and exploding gradients are problematic in RNN architectures
- Combining information if input sentences are long is difficult was difficult to combine information if the input sentences were too long
- Introducing the transformer
The transformer is essentially made up of two main blocks:
- Encoder
- Decoder
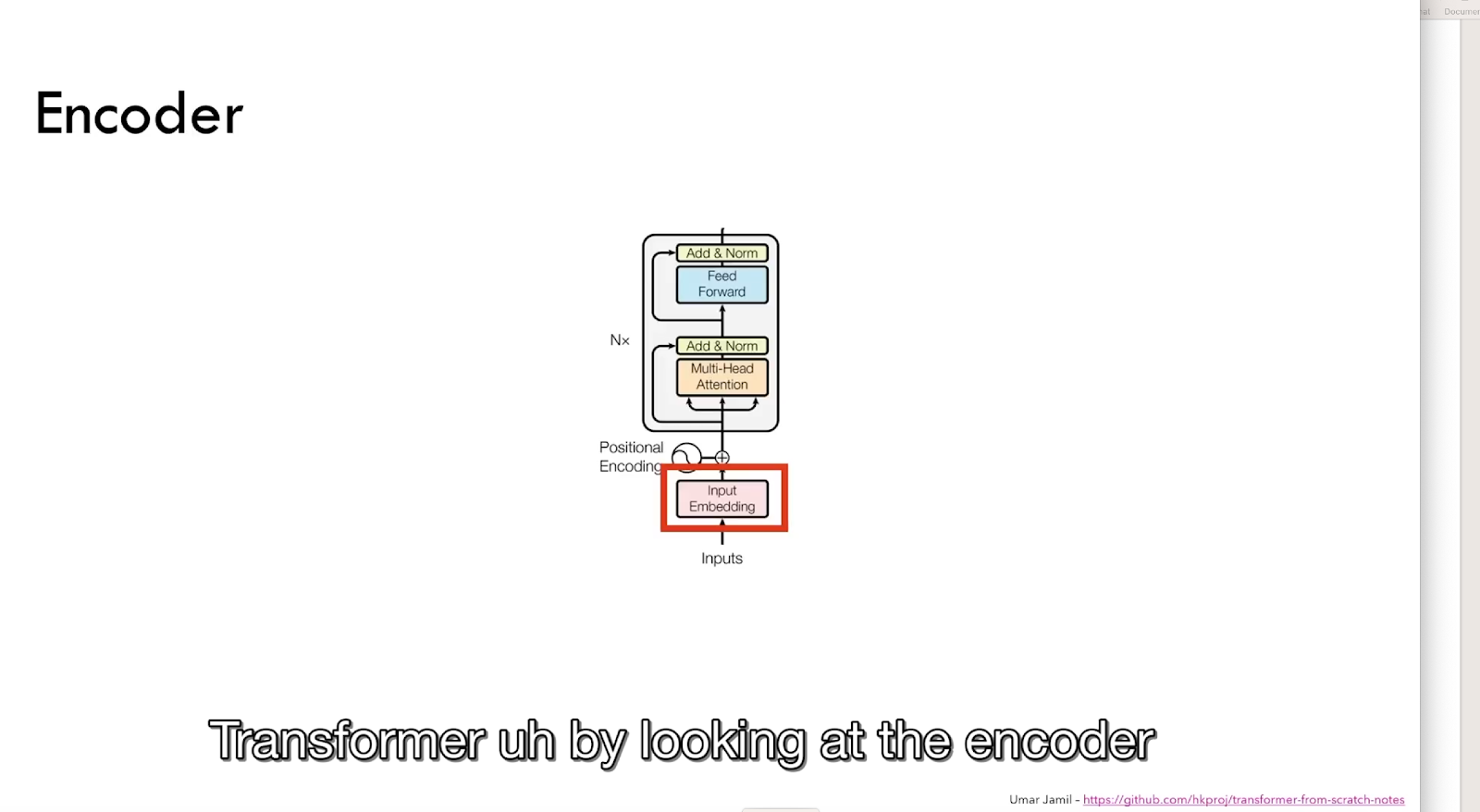
Let’s start with the encoder block and learn about the first process within the encoder, i.e., the input embedding.
What is an input embedding?
Let’s take an example wherein we assume that our input sentence consists of 6 words/tokens.

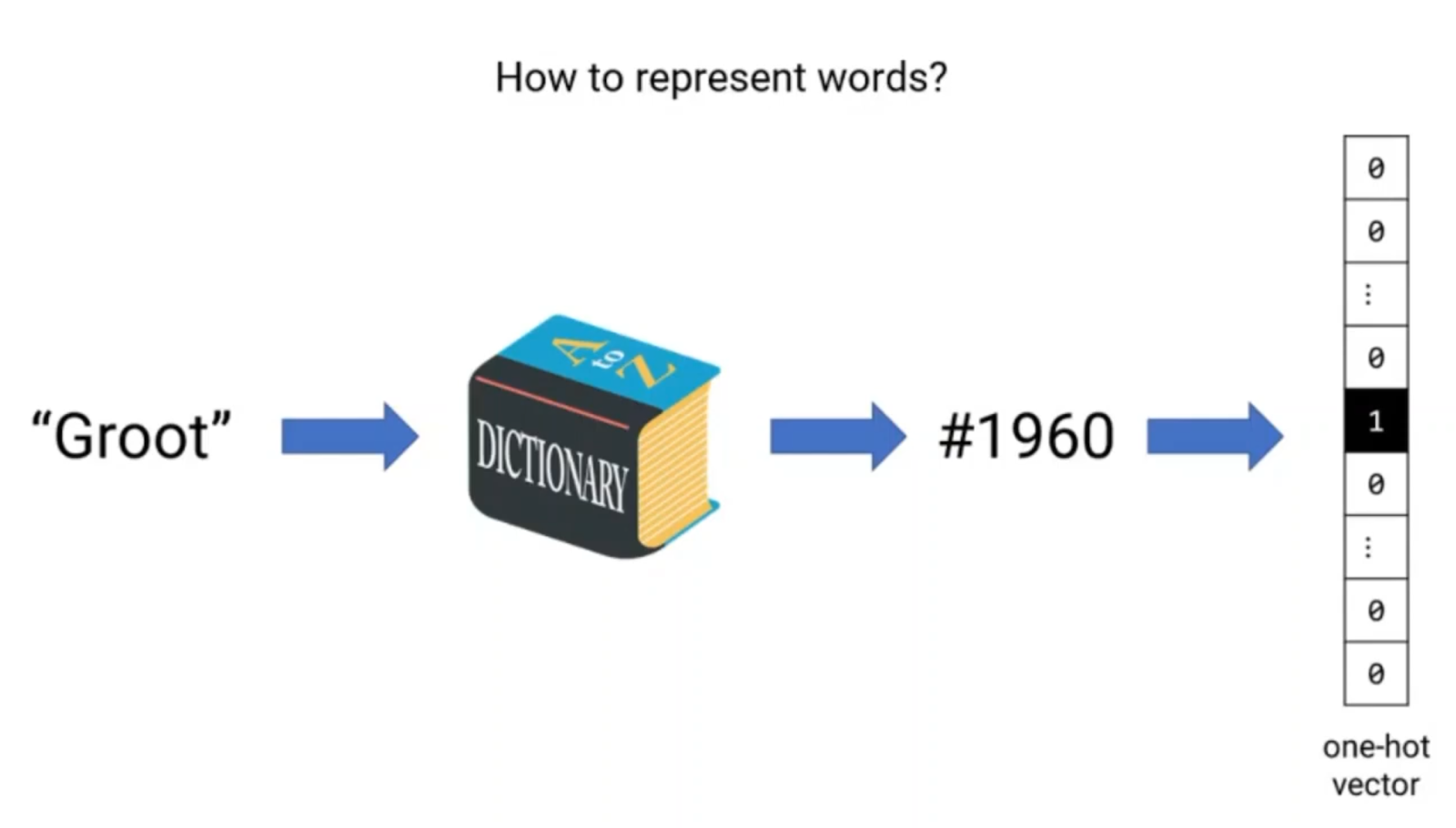
Now, the first step is to determine the Input IDs of these words from the word’s dictionary.
In the dictionary, we may assume that we have collected all words from the English language.
Every word will have the same Input ID regardless of where it appears in the sentence. For instance, the word ‘CAT’, in both occurrences in the sentence, will be assigned the same Input ID number.
Figure 6 above shows the process of assigning Input IDs.Now, this can be also viewed as a one-hot vector. This means that we have a value of 1 at the Input ID position. This is shown in Figure 7 below.

[ adjust/change the word in the image and #position … change image make our own. ]
Next, we map each of these Input IDs with a new vector via a process called input embedding.
This input embedding will result in a new vector (of size 512). In this way, similar words are mapped into the same vectors, and in this way, the same word will be mapped into the same vector.
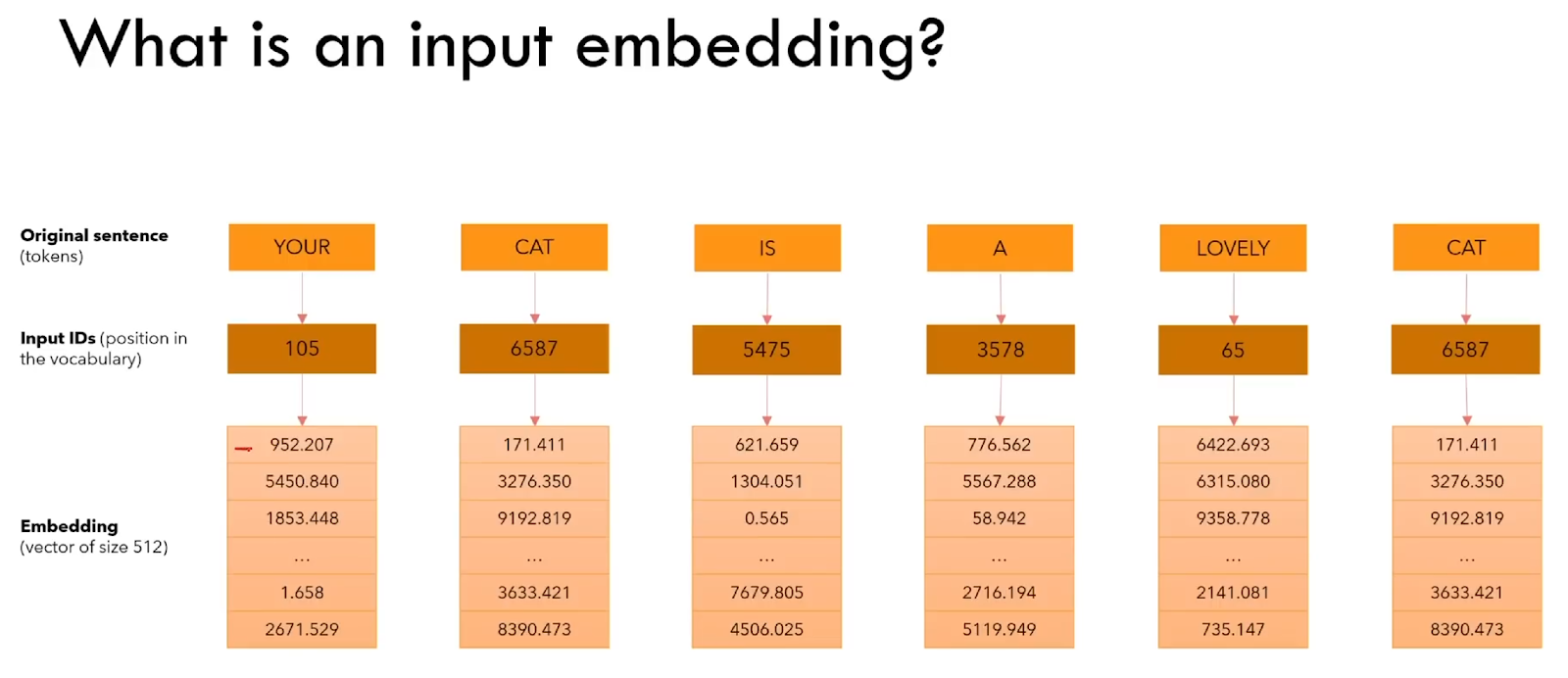
For instance, ‘cat’ embedded vectors will be the same. This may change during the training process with the values changing according to the training algorithm.
Note that the size of the embedding vector is defined in the original paper [2] as d_model.
You may be puzzled by the embedding step. Figure 8 below illustrates the input embedding process simply. Notice how similar objects (words) are relatively close to each other in the embedded space. For instance, ‘dogs’ and ‘cats’ will be relatively next to each other. On the other hand, the word “car” will be relatively far away from both of these two words.
What is positional encoding?
Apart from input embedding, the model needs additional information about the relative position of the words in our input sequence.
For instance, if we want a model to be able to determine which words are close or next to each other in a sentence, or if we want the model to determine which ones are distant or relatively far from each other in a sentence, a simple process called ‘naive positional encoding’ can be applied.
It is important to understand that the position of words in a sentence can change the meaning of the sentence, that is why positional encoding becomes all the more important.
Positional encoding is a simple extension of the embedding vector in such a way that we concatenate the position value at the end of the vector.

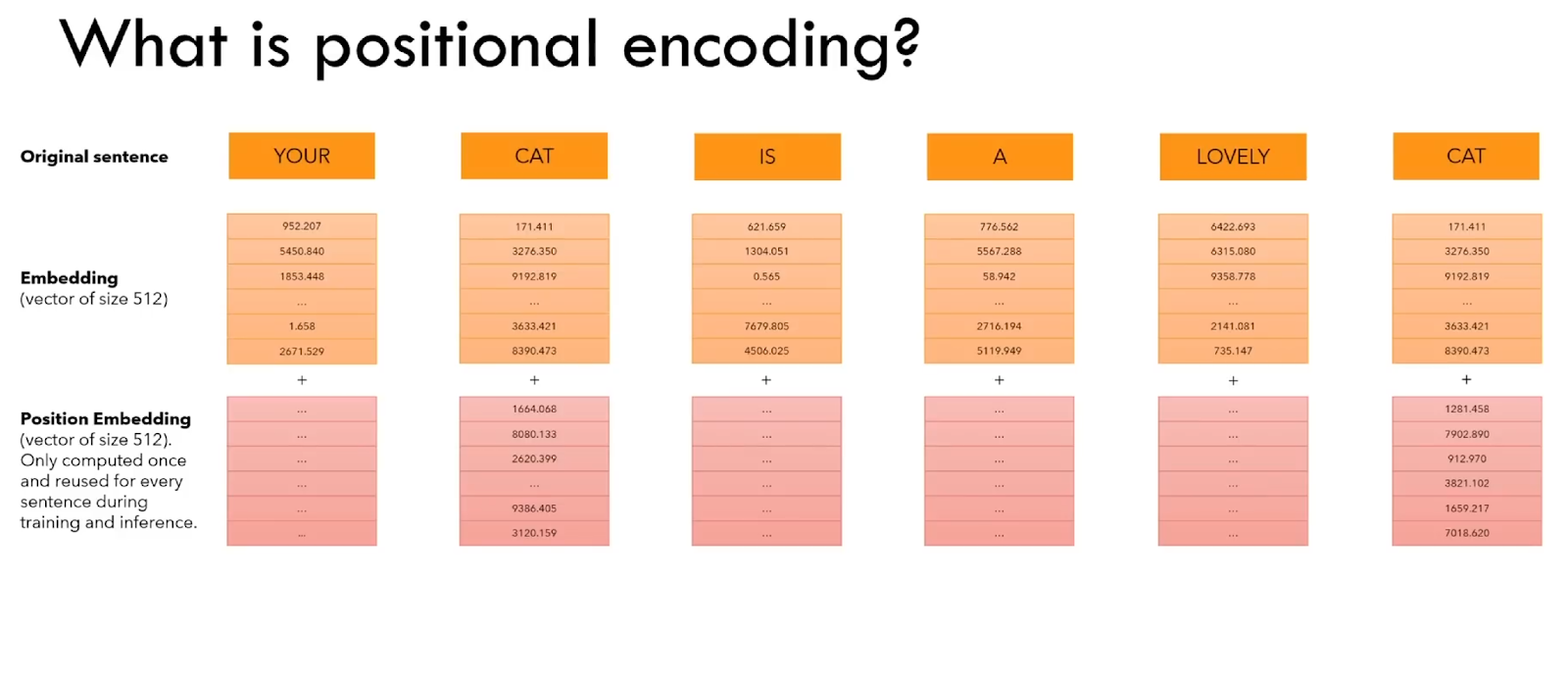
In practice, however, an idea is developed to construct a vector of the same size as the original and to sum it to the input vector. This is depicted in Figure 9.
This positional embedding is calculated only once, and then, the vectors are simply added (summed) to the original embedded input vector. Naturally, for summation to be possible, both vectors are defined as 512-element long vectors [2].
Let us quickly and briefly discuss how the positional embedding vector is calculated. For this, we will use the following formula:
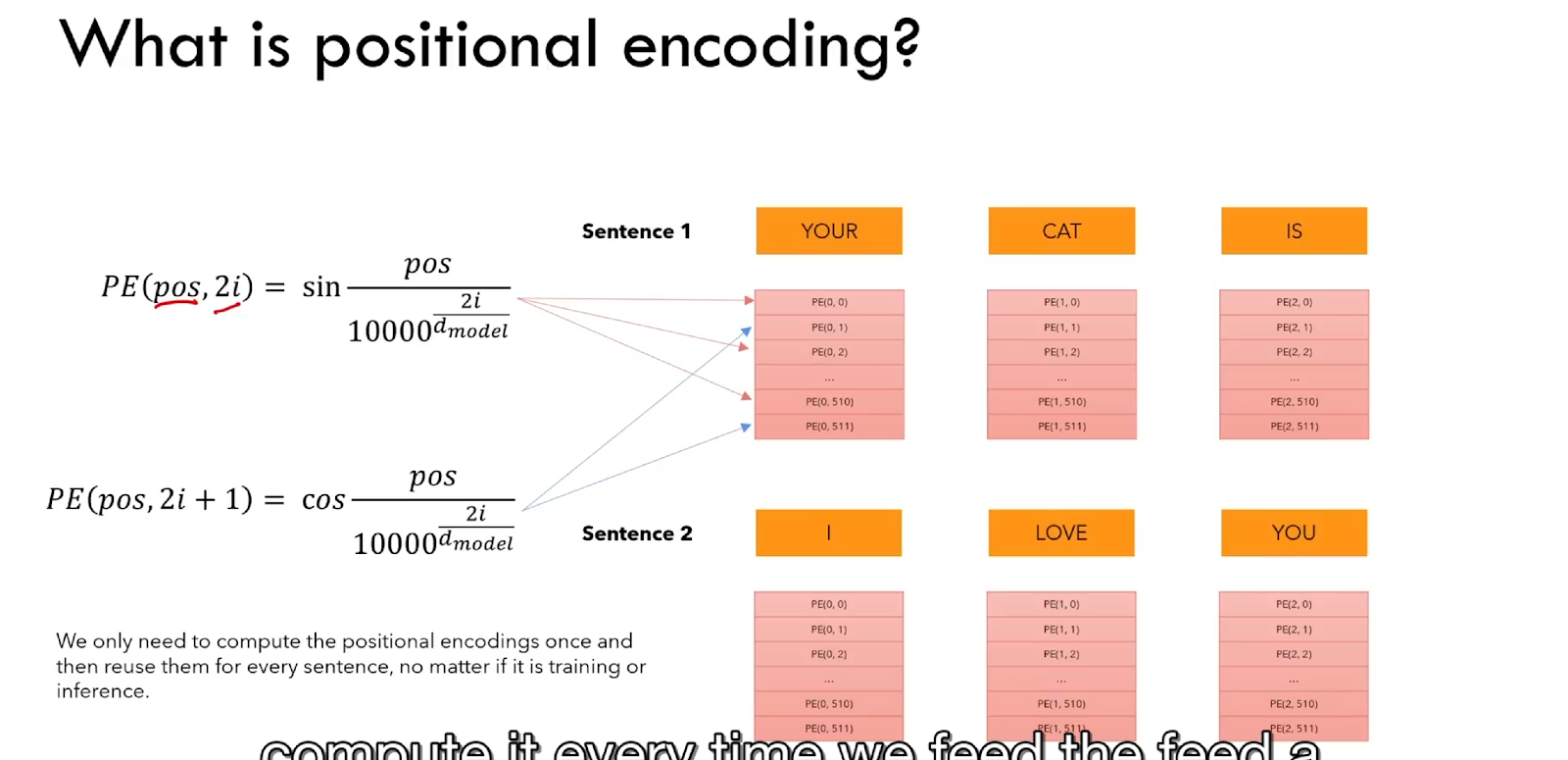
It is interesting to note that position embedding vectors are calculated only once, and these values will be the same for every sentence. For instance, PE(pos, 2*i) or PE(pos, 2*i+1) will have the same values for different sentences, at the corresponding positions. This means that PE(0, i), will be the same vector of 512 elements calculated for all the first words in all input sentences. Note that these variables in the formula (pos) determine the frequency of the sine/cosine wave, whereas the variable i can be seen as a discrete-time that will adjust the sine wave values throughout the vector of length 512.
One illustration, how this can be of help, can be seen in Figure 10 below, where different sine waves are shown.
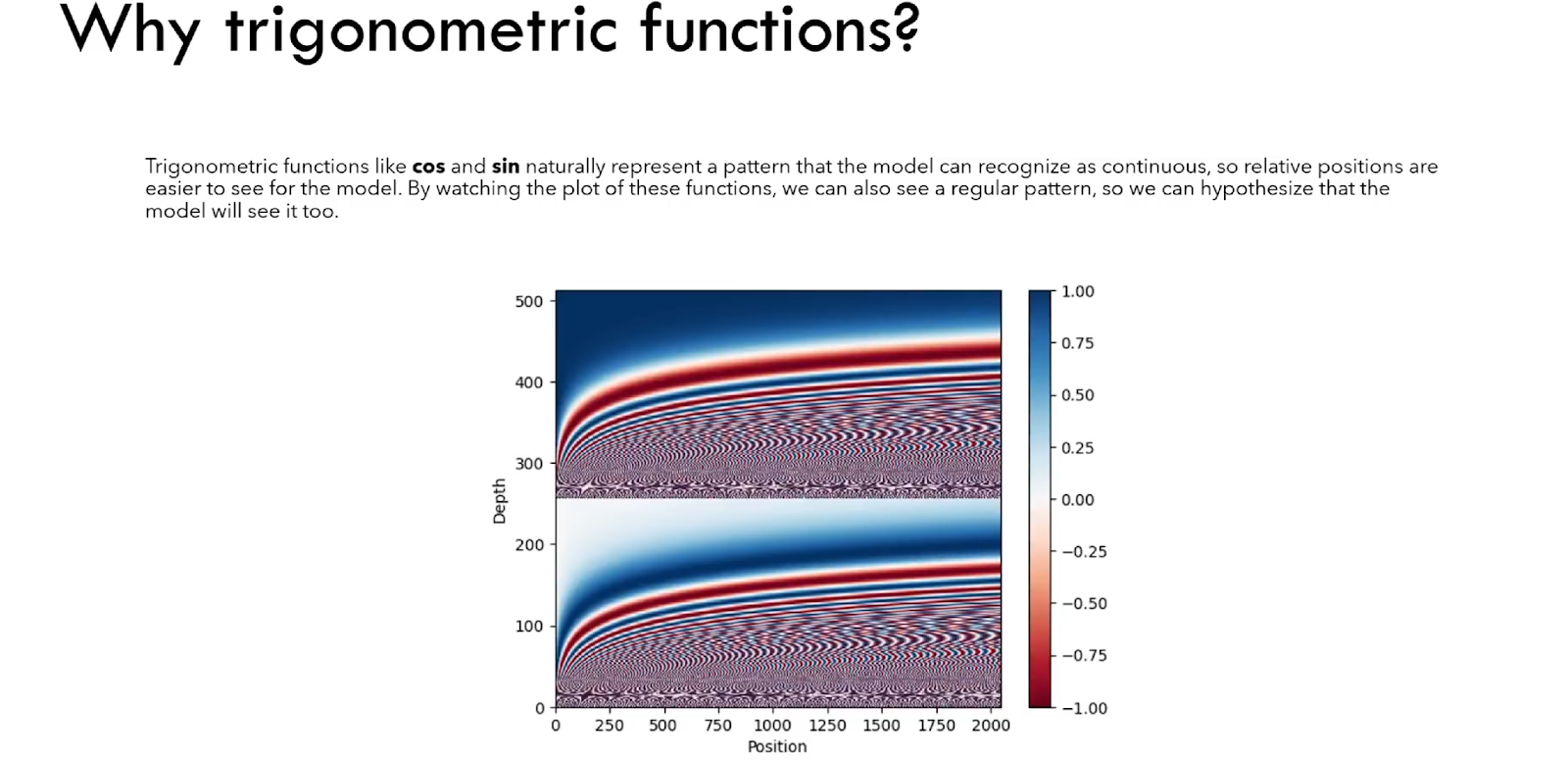
We can see that along the y-axis on the graph, we have an embedding vector’s length (512). And, the position variable on the x-axis is depicted up to the values of 2000. The sine/cosine values will cover a continuous interval from -1 till 1 as can be seen in the legend of the graph.
Hopefully, the model is expected to also “see” and understand these regular “sine patterns” and to better model the relative position of the words.
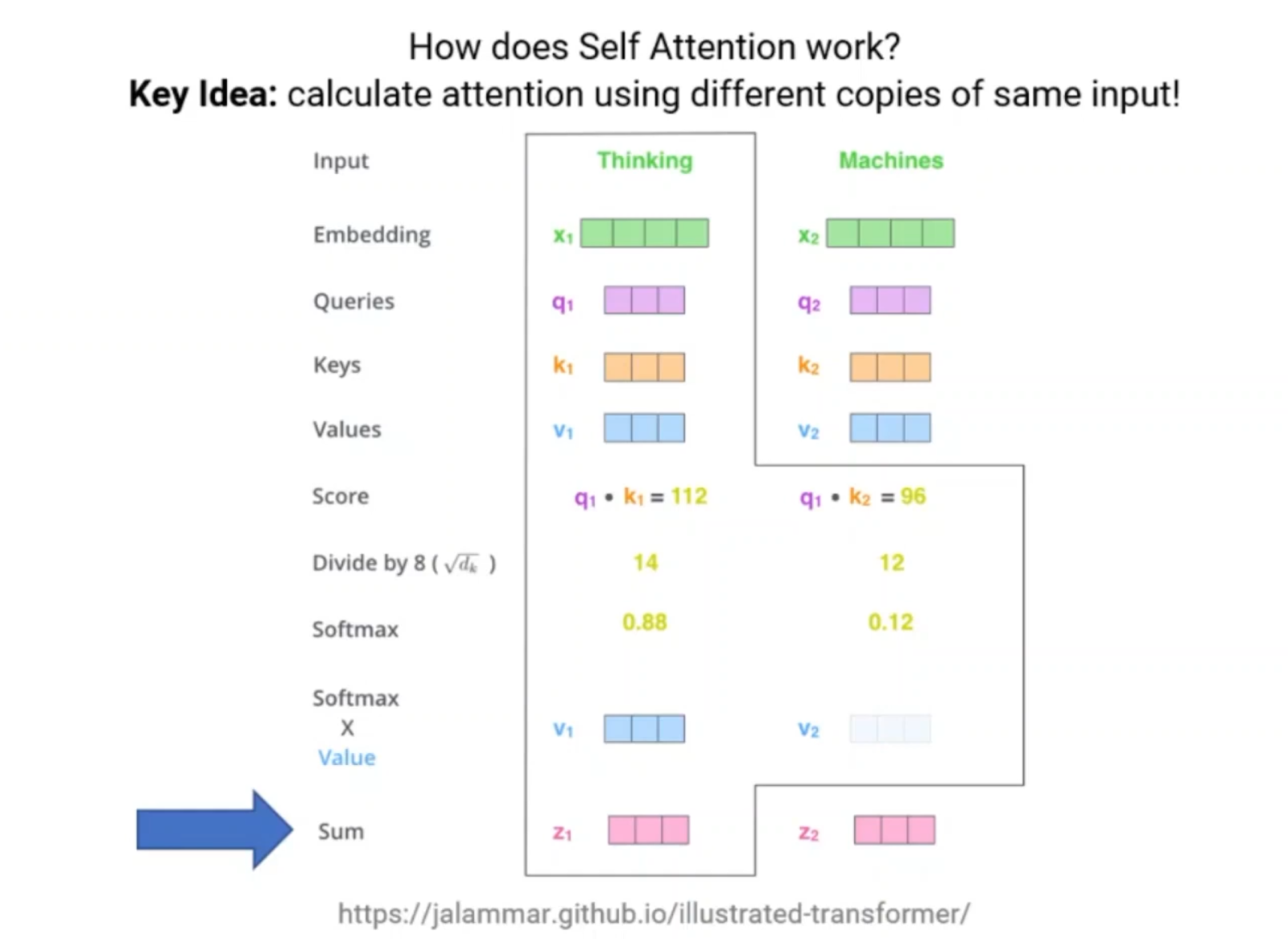
4. Single Head Attention: Self-Attention
Moving on, we will now explore the concept of self-attention. Understanding this important concept is necessary for further study of the multi-head attention concept. Have a look at Figure 11 below which shows the block diagram of the subsequent processing step of this process.
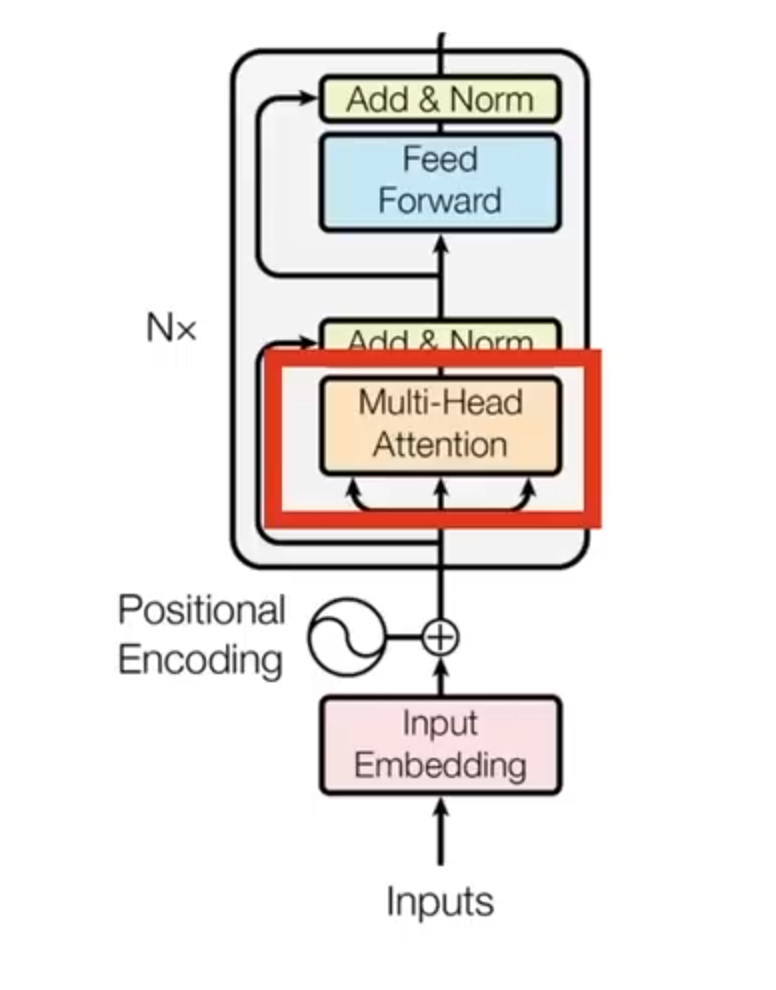
What is self-attention?
Self-attention is a mechanism that existed even before 2017. It was a model that enabled words to relate to each other. The formula that is currently used for self-attention is
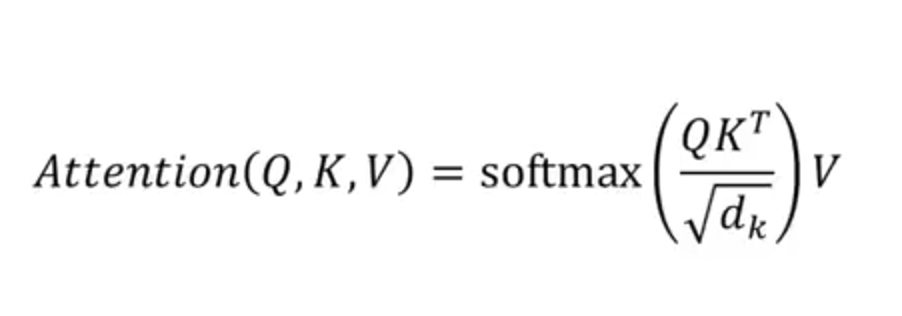
To illustrate self-attention with a simple example, we will assume that we have 6 words as our model’s input. Next, we will use the input embedding step and, thereby obtain the matrix of size 6×512.
This means that our matrix Q (query) will be of size 6×512.
Next, KT will remain the same as this equation:
(equation needed! Transpose KT)
However, the matrix needs to be transposed, so that we can multiply them. This multiplication step is shown using the following illustrated equation.
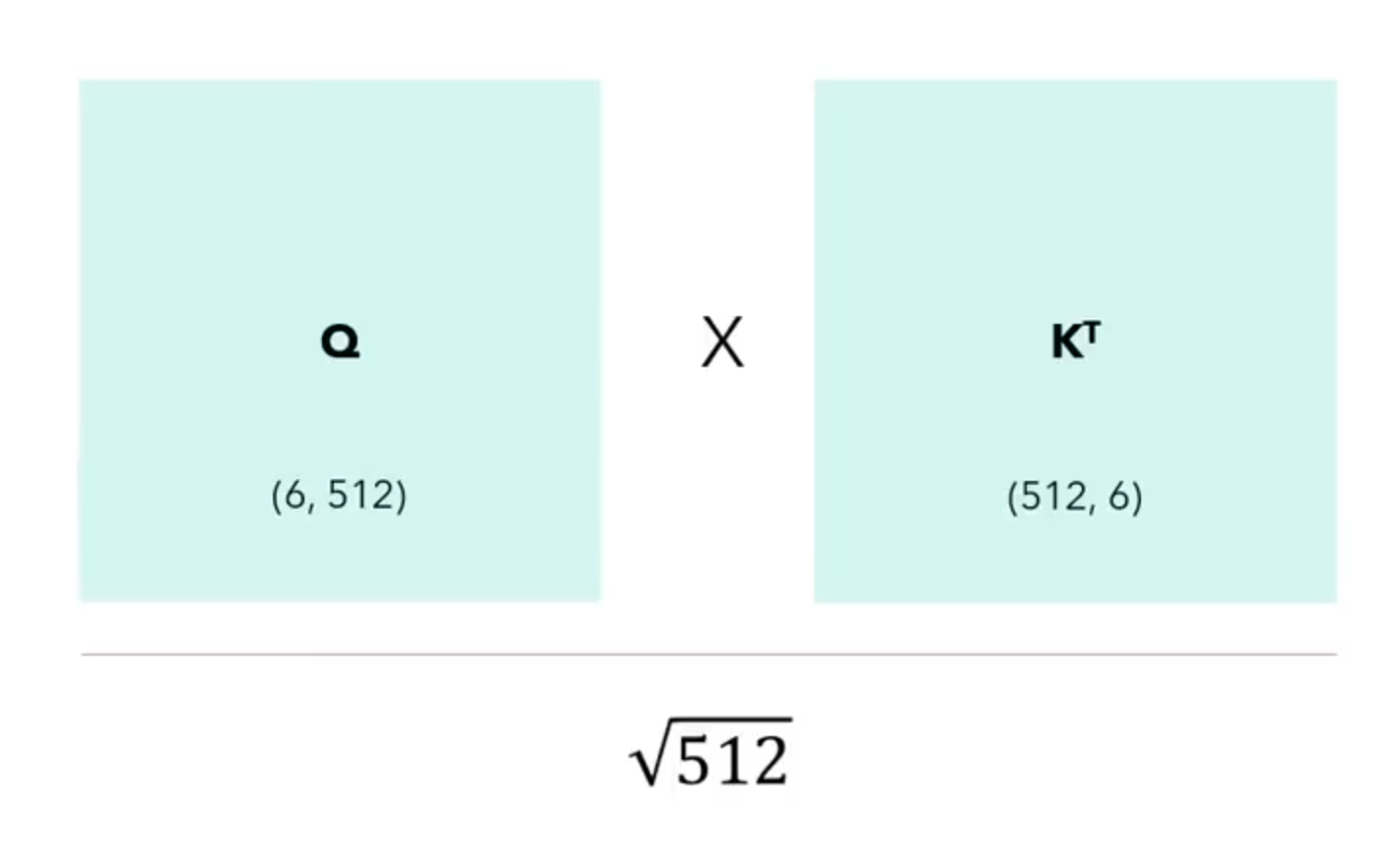
In our case, the model size dmodel is the same as dk for simplicity such that there is only one head. Hence, to normalise it, we divide the matrix multiplication result. This will result in a matrix of 6×6, and this matrix will tell us how each of the 6 words relate to each other.
In addition, we will apply a softmax() function to the final result to add the values along each row.. This will give us the sum that equals one.
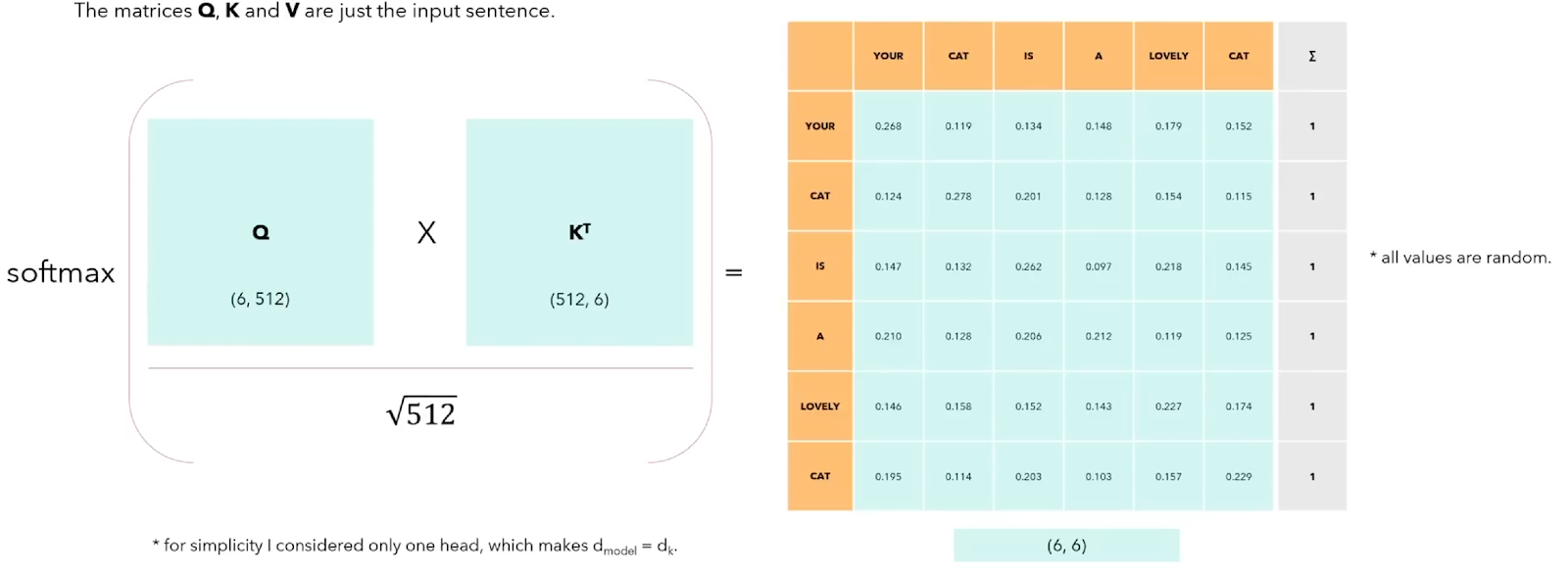
Finally, one additional step is to multiply this 6×6 matrix with the matrix V (Value).
This matrix is of size 6×512. This will result in the 6×512 matrix as well. This will be our resulting self-attention representation value.
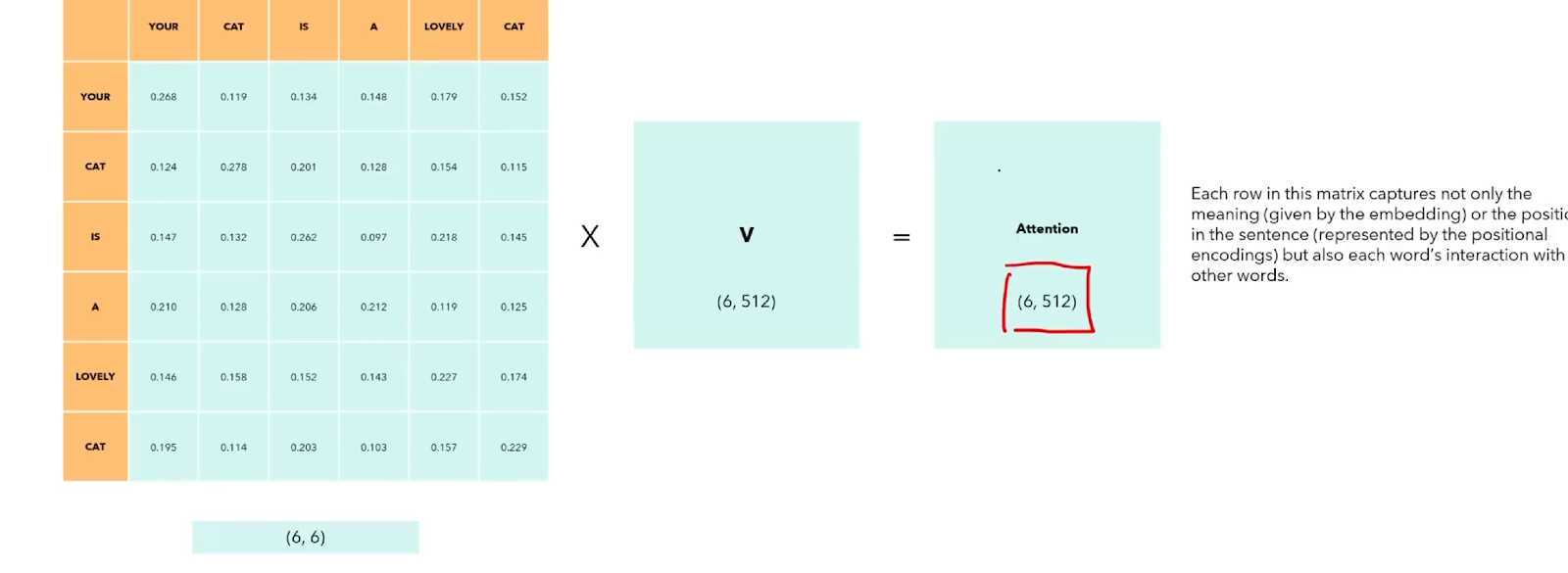
This representation is constructed from a row-vector for each word from the input embedding vector. Both the position and relation with other words in this sentence is captured using the self-attention matrix. For instance, it tells us the interaction between the words.
Properties of Self-Attention
So far, we have managed to derive a self-attention matrix. We can see that it actually does not rely on any single parameter. All the steps have been performed by the input embedding and positional encoding.
The attention matrix, intuitively, will have the largest values along the main diagonal. The larger the values of the off-diagonal elements, the stronger connection between two particular words will be.
In addition, it is a good time that we mention and introduce that sometimes we want to prevent the interaction between some words! To accomplish this, we will input a value of “– infinity“ in the matrix. This will further become a 0 value, after a softmax() function is applied. We will use this later within a decoder when we want to prevent “future” words from being seen by the model.
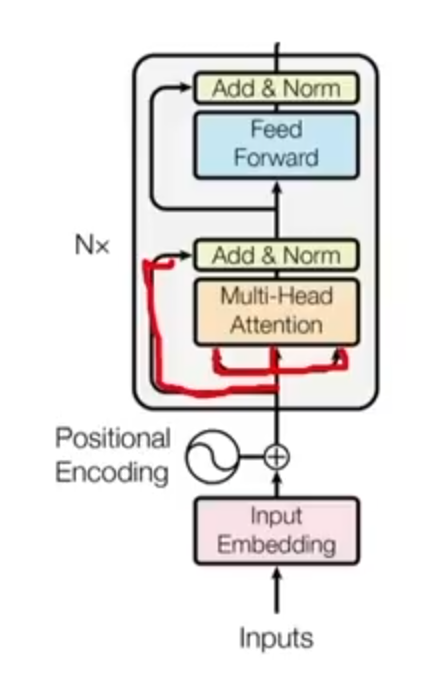
Multi-Hhead Attention
Till now, we learnt about Single-Head Self-Attention. It’s timeSo far, we have been exploring a single head self-attention.
Now, we will expand this concept and introduce Mmulti-Hhead Aattention.
It is defined usinggiven with the following formulas:
Let’s start slowly to decompose this and systematically explain all the variables her
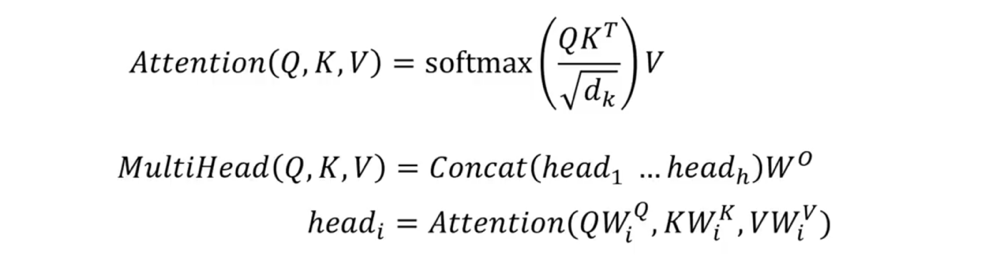 | |
 |  |
e.
Let’s start slowly to deconstruct these equations and systematically explain all the variables here.
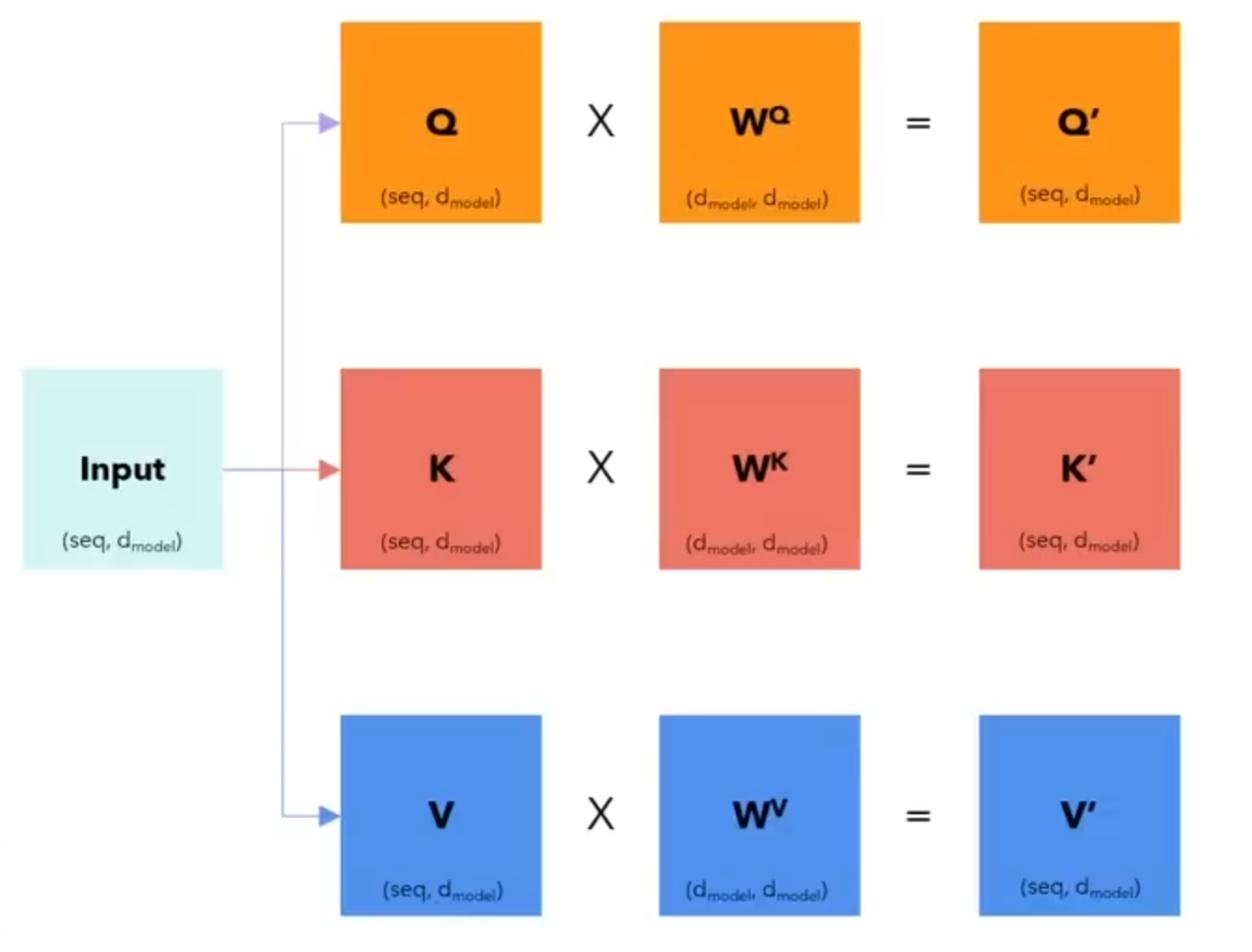
In the above equations, we haveWe will again assumed, that we ourhave an input sentence that consists of 6 words. After Iinput Embedding, we will get a matrix of size 6×512.
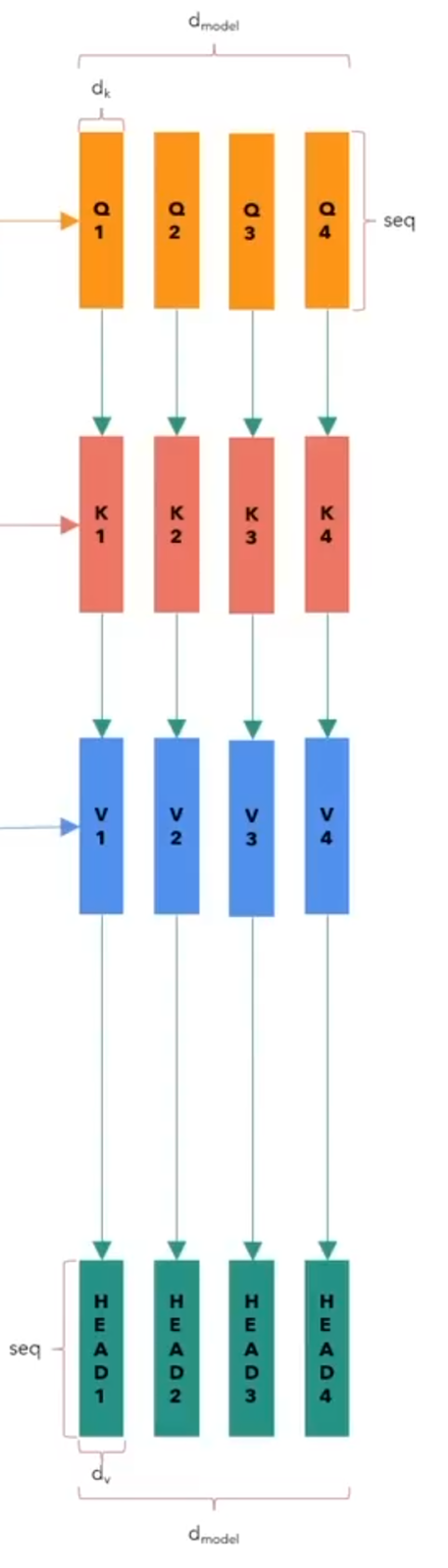
Next, four copies of this matrix will be sent throughout four different paths, as shown in the graph in Figure 12 below. These paths areand depicted as “red paths”.
TNext, these matrix embeddings are further multiplied with the corresponding W matrices, as depicted below:
Next, depending on the number of heads (h) ,and we calculatevalue dx = dmodel / h
Each head will see the same word from the input, but it will be processing only a single fraction from the final matrix.
Now, the formulas become more intuitive and the final head will become athe concatenation of the following head_i:
This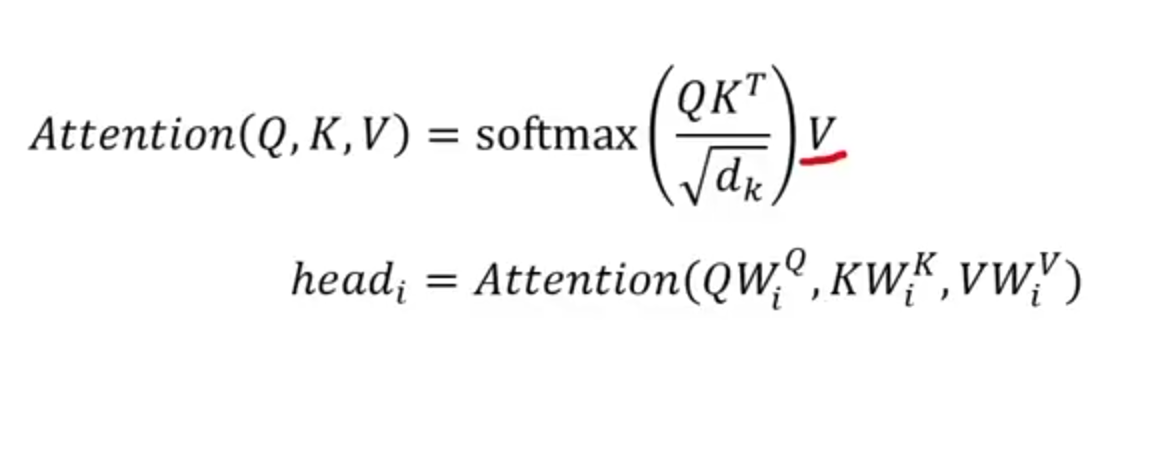
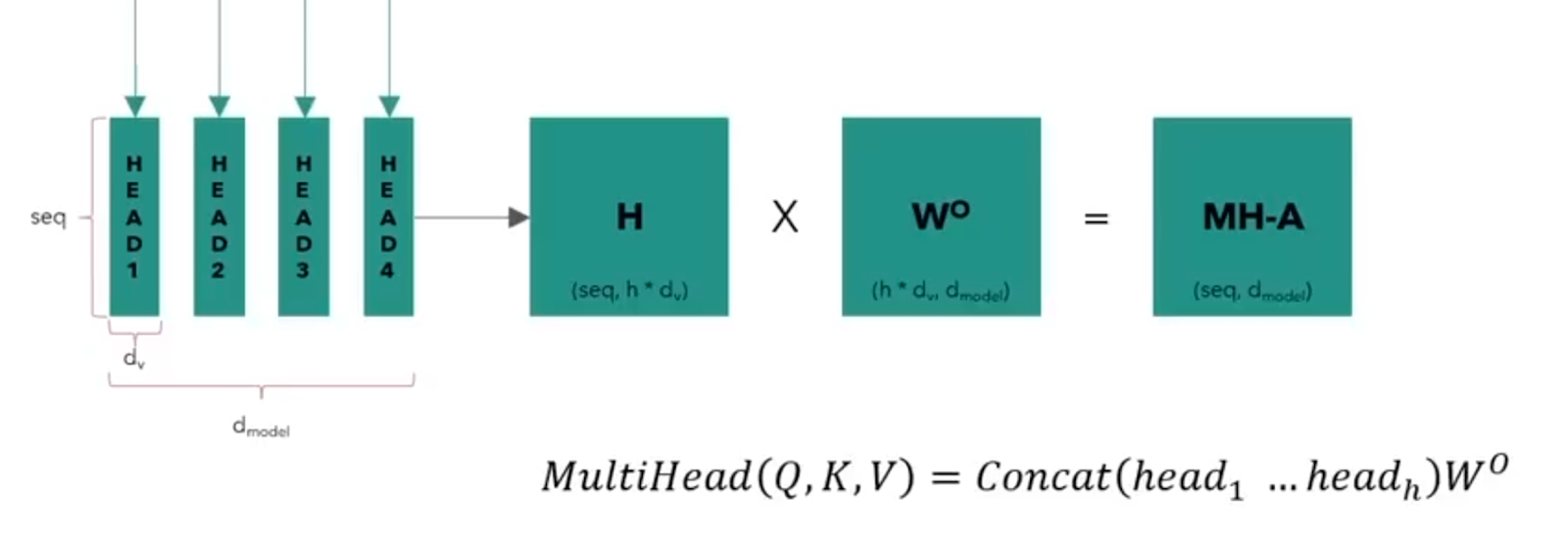
TNow, the matrix H is the result of concatenation of (seq x dv) matrices. Hence, instead of calculatingon attention between Q’, K’ and V’ matrices, the multi-head attention model splits them and then calculates “attention” ??? Between Q1, Q2, Q3, and Q4 and so on.
To summarise, the whole idea behind multi-head attention is so that some of the heads can lean to relate to nouns, verbs, or adjectives as well.For instance, some of the heads can learn to relate to nouns, verbs, or adjectives. This is the idea behind multi-head attention.
We can even visualise this ‘attention’Moreover, attention can also be visualised. For instance, we can apply the softmax function, when calculating the product between Q and KT.
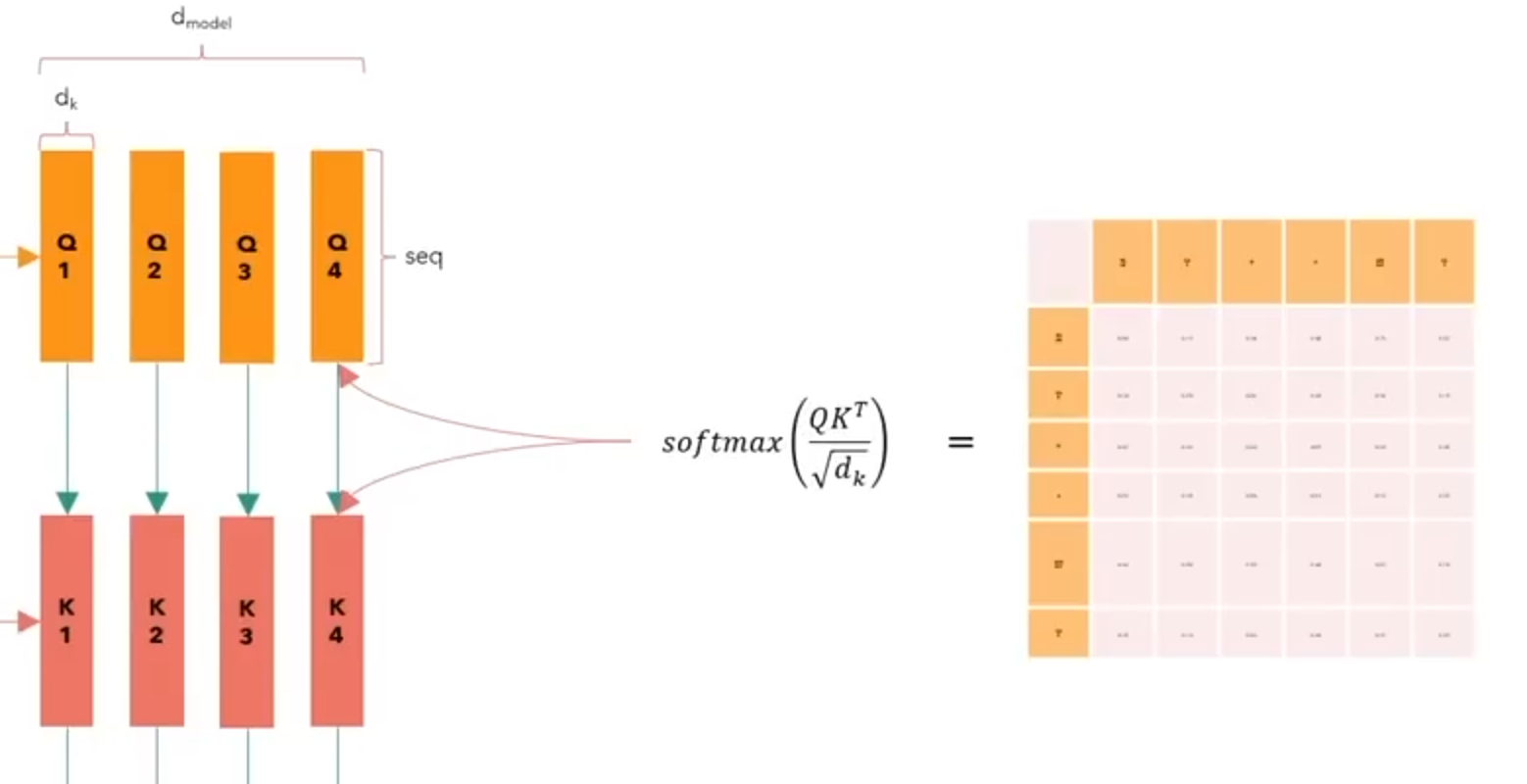
The final matrix in this case is (seq x seq) or (6 x 6), whichand it will tell us about the intensity of the relation between each word.
In Figure 13, Next, we present an illustrative example from the paper for you to better grasp the multi-head attention process. Notice howFor instance, some of the words are more related than each other.
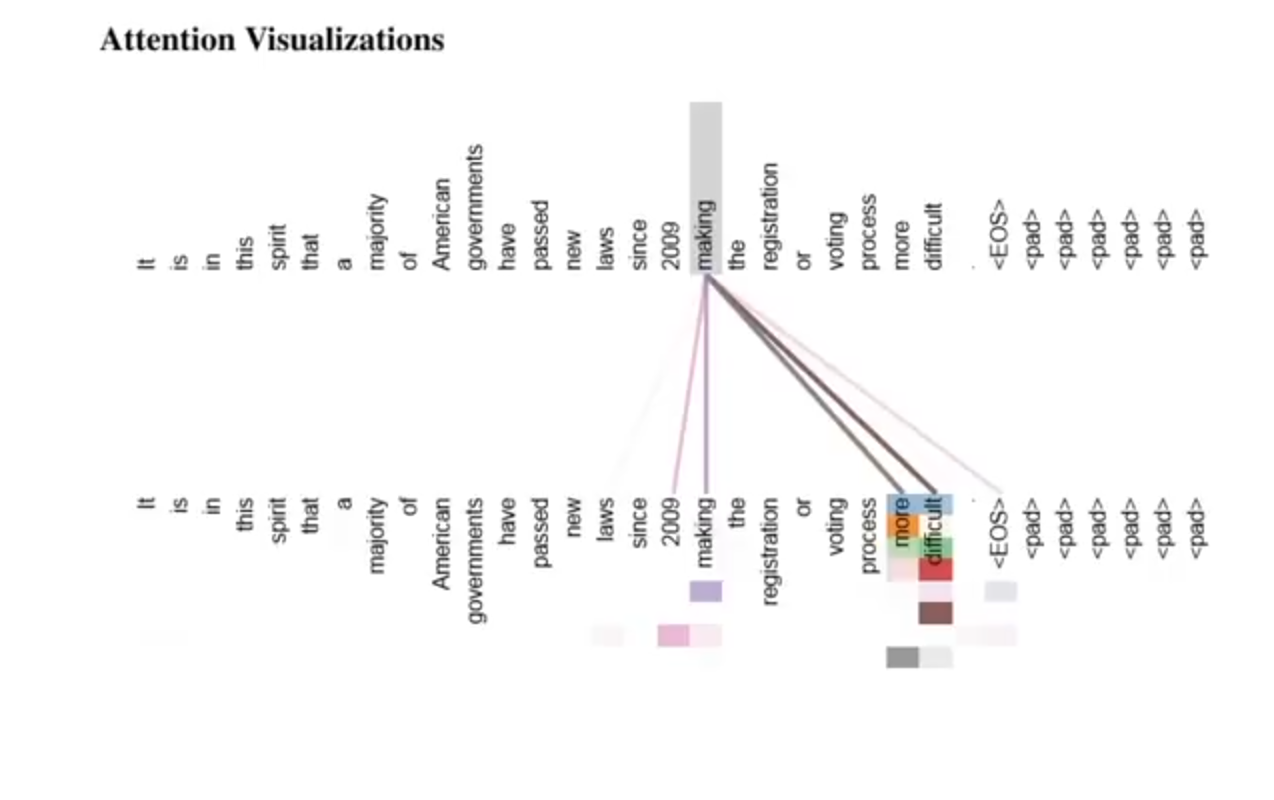
In this case, we can see how the verb “making” is related to all other words in the sentence.
Different colours are related to different heads from the model. (??? check).
It seems that the pink head can see the interaction between the values that other heads cannot see.
Query, Kkeys and Vvalues.
From a well-known Python data structure dictionary point of view, the terms ‘Query’, ‘Keys’, and ‘Values’ are quite familiar. Even still, if you want to know about them, you can checkout the very interesting reasonsing that’s provided on the Stack Overflow website.At the first glance, these terms should be already familiar from a well-known Python data structure – dictionary. In addition, a very interesting reasoning is provided at “Stack-overflow” website.

The authors relate these words with the retrieval system (e.g. Youtube video search). AThe ‘Qquery’ can be seen as an input search word. Video titles and descriptions can be seen as sets of ‘Keys’. And, a set of best matched videos can be seen as a final result or ‘Value’. This ‘Value’ is an Then, there is a set of keys such as video title and description. Finally, a set of best matched videos can be seen as a final result (value). The value is an output result that the YouTube search engine will presents to us.
The following example, can help us even more to get familiar with Qquery, Kkey and Vvalue interpretation.
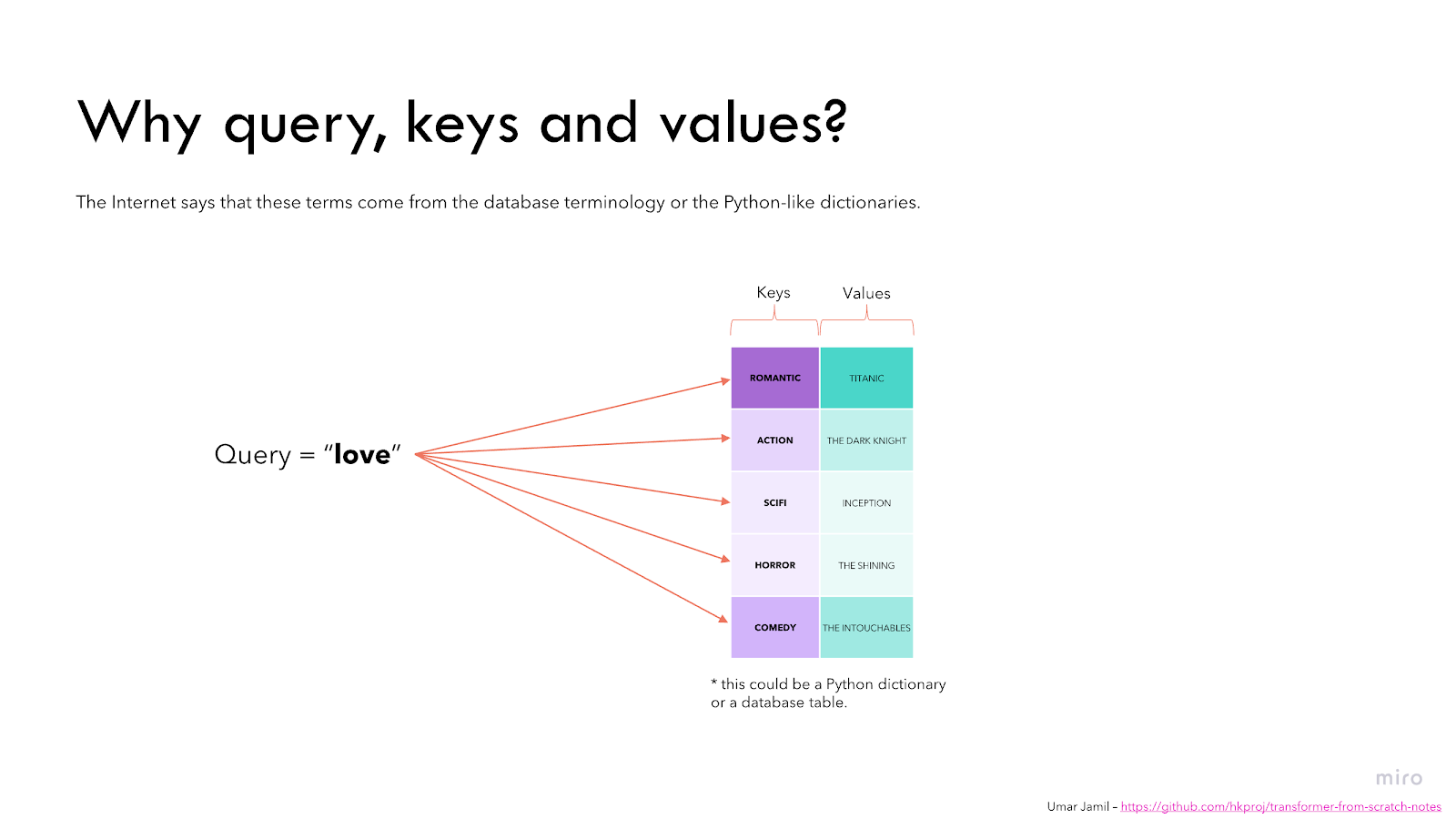
Let us consider can have a Python dictionary-like data structure. Keys can be movie genres and Vvalues will be the names of the movies.
Now, our Qquery can be “love”.
As a result, we want to have a model that will give high score values for movies where love is the main theme, and low score values for movies where love is not the will not be a main topic. This analogy further demystifies the idea behind the attention mechanism.
Normalization.
This process will be the final step. As it is not of high importance to follow the main transformer idea, we have included it in the Appendix. However, please note that for a full understanding of the transformer, there are still certain important technical details that are very important to be grasped.!
Feed-Forward
This block represents a simple Neural Network. That is a Feed-forward network with one hidden layer.
Nx layers.
Finally, do note that the attention layer is repeated Nx time throughout the encoder. Then, the final attention signal is sent to the decoder.
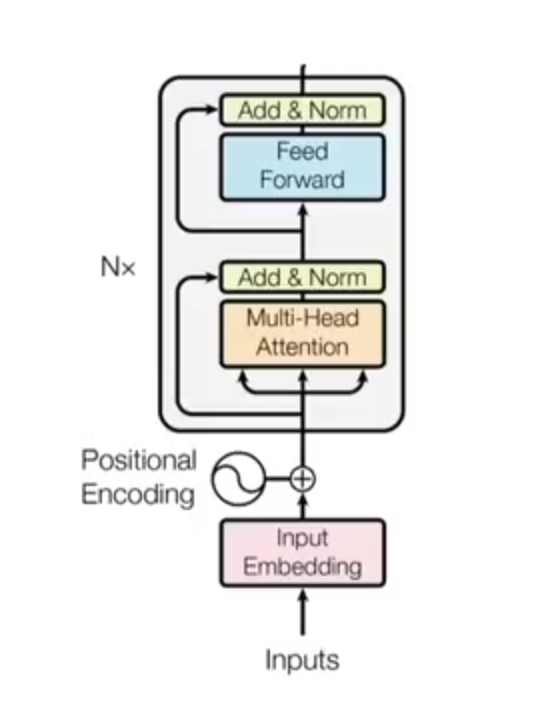
Decoder
Now, we can continue with the second transformer’s block – the Ddecoder which. It is depicted in Figure 14 below.
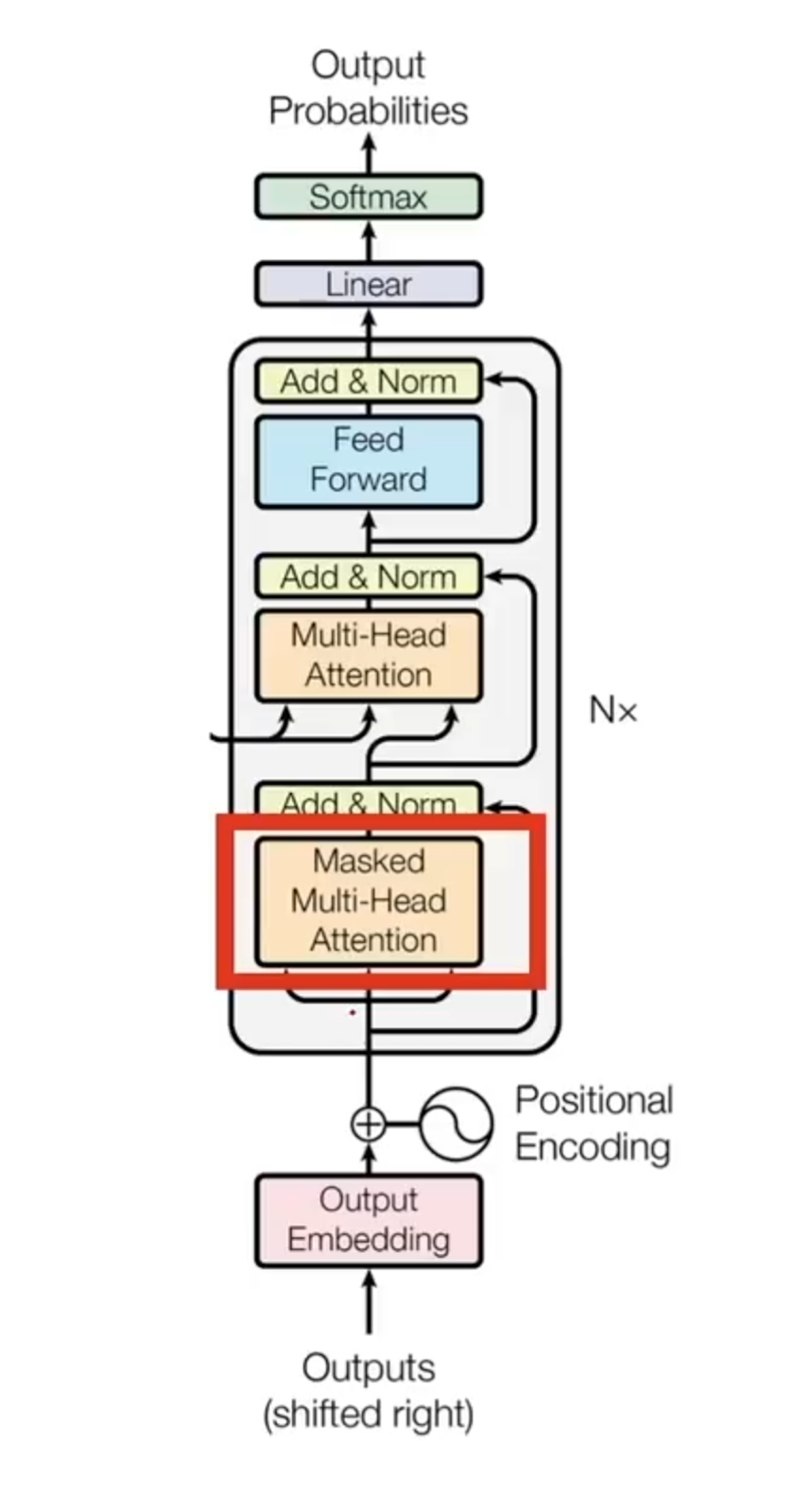
Similar to the EncoderIn the same way, as with the encoder, we have an Embedding step here as well which is known as Output Embedding. We also have (here Output Embedding), and the Positional Encoding.
Novelty is seen in the Multi-Head Attention block. Note that here, we have two Multi-Head Attention blocks. The first one is the same, as the one used in the Eencoder and the other one is new which is. In addition, there is also a “Masked” Multi-Head Attention block.
In the first one, we will have inputs from the Eencoder in the form of Keys and Values. The Queries, on the other hand, will come (keys, and values), whereas from (queries) are come from the Ddecoder part, i.e., – the Masked Multi-Head Attention block. In this way, we do not have self-attention, but cross-attention since we are now having two sentences.
The remaining layers are the same as in the Encoder.
Masked Multi-Head Attention.
“Masked” is used here to describe how we want to prevent interaction between certain words. We have already discussed this above and introduced it in the previous paragraphs. What this means is that Namely, we want to develop a causal model which, therefore will inhibit interaction between future words that are not visible to the model at the time of inference. , at the time of inference are not visible to the model (future words).
Therefore, to implement this within the Multi-Head Attention mechanism, we will simply set all the off-diagonal elements above the main diagonal to minus infinity.

In this way, after a softmax() function is applied, these elements will be simply set to 0 values.
Inference and training of a Transformer model.
Literature:
[1] Stanford CS25 V2 | Introduction to Transformers w Andrej Karpathy
[2] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … Polosukhin, I. (2017). Attention is All You Need. In Advances in Neural Information Processing Systems (pp. 5998-6008).