#021 CNN Object Localization
Object Localization
Object detection is one of the areas of computer vision that’s exploding and it’s working so much better than just a couple years ago. In order to build up object detection we first learn about object localization. Let’s start by defining what that means.
We have already said that the image classification task is to look at a picture and say is there a car or not. Classification with localization means not only do we have to label an object as a car, but also to put a bounding box or draw a rectangle around the position of the car in the image. In the term classification with localization problem, localization refers to figuring out where in the picture is the car we’ve detected.
We’ll learn about the detection problem where there might be multiple objects in the picture and we have to detect them all and localize them all. If we’re doing this for an autonomous driving application then we might need to detect not just other cars but maybe other pedestrians and motorcycles or even other objects. The classification and the classification with localization problems usually have one big object in the middle of the image that we’re trying to recognize or recognize and localize. In contrast in the detection problem there can be multiple objects, and in fact maybe even multiple objects of different categories within a single image. The ideas we learn about image classification will be useful for classification with localization and then the ideas we learn for localization will turn out to be useful for detection.
What are localization and detection ?

Image Classification (left); Classification with localization (center); Detection of multiple objects (right)
Let’s start by talking about Classification with localization. We’re already familiar with the image classification problem in which we might input a picture into a \(convnet \) with multiple layers, and this results in a vector of features that is fed to maybe a \(softmax \) unit that outputs the predicted class.

A \(convnet \) with a \(softmax \) output
If we’re building a self-driving car, maybe our object categories are a pedestrian, a car, a motorcycle and a background (this means none of the above). So, if there’s no pedestrian, no car, no motorcycle then we may have an output background. These are our four classes, so we need a \(softmax \) with \(4 \) possible outputs.
How about if we want to localize the car in the image as well ? To do that we can change our neural network to have a few more output units that output a bounding box. In particular, we can have the neural network output \(4 \) more numbers, and those numbers will be \(b_x \), \(b_y \), \(b_h\), \(b_w \). These \(4 \) numbers parameterize the bounding box of the detected object.

Convolutional neural network which outputs position of a bounding box
Classification with localization
Here is used the notation that the upper left point of the image is \((0,0) \), lower right is \((1,1) \).
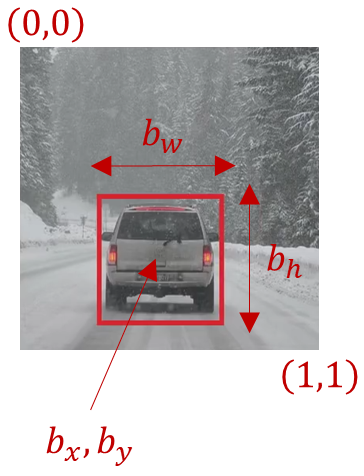
Bounding box and it’s coordinates
Specifying the bounding box the red rectangle requires specifying the midpoint, so that’s the point \(b_x \), \(b_y \) as well as the height that would be \(b_h\), as well as the width \(b_w \) of this bounding box. Now if our training set contains not just the object class label, which our neural network is trying to predict up here, but it also contains \(4 \) additional numbers giving the bounding box, then we can use supervised learning to make our algorithm outputs not just a class label, but also the \(4 \) parameters to tell us where is the bounding box of the object we detected. In this example the \(b_x \) might be about \(0.5 \) because this is about half way to the right to the image, \(b_y \) might be about \(0.7 \) since that’s about \(70 \) % of the way down to the image, \(b_h\) might be about \(0.3 \) because the height of this red square is about \(30 \) % of the overall height of the image, and \(b_w \) might be about \(0.4 \) because the width of the red box is about \(0.4 \) of the overall width of the entire image.
Defining the target label \(y \)
Let’s formalize this a bit more in terms of how we define the target label \(Y \) for this as a supervised learning task. Let’s define the target label \(Y \). It’s going to be a vector where the first component \(p_c \) is going to show is there an object. If the object is a pedestrian, a car or a motorcycle, \(p_c \) will be equal to 1, and if it is the background class (if it’s none of the objects we’re detected ), then \(p_c \) will be \(0 \). We can think \(p_c \) stands for the probability that there’s a object, probability that one of the classes we’re trying to detect is there, something other than the background class.
Our vector \(y \) would be as follows:
$$ y=\begin{bmatrix} p_{c}\\ b_{x}\\b_{y}\\b_{h}\\b_{w}\\c_{1}\\c_{2}\\c_{3}\end{bmatrix} $$
Next, if there is an object then we want to output \(b_x \),\(b_y \),\(b_h\) and \(b_w \), the bounding box for the object we detected. And finally, if there is an object, so if \(p_c =1 \), we want to also output \(C1 \), \(C2 \) and \(C3 \) which tells is it the \(class1 \), \(class 2 \) or \(class 3 \), in other words is it a pedestrian, a car or a motorcycle. We assume that our image has only one object and the most one of these objects appears in the picture in this classification with localization problem. Let’s go through a couple of examples.
If \(x \) is a training set image, then \(y \) will have the first component \(p_c =1\) because there is an object, then \(b_x \),\(b_y \), \(b_h\) and \(b_w \) will specify the bounding box. So, our label training set we’ll need bounding boxes in the labels.
And then finally this is a car, so it’s \(class 2 \). \(C_1=0 \) because it’s not a pedestrian, \(C_2=1 \) because it is a car, \(C_3=0 \) since it’s not a motorcycle. Among \(C_1,C_2,C_3 \) at most one of them should be equal to \(1 \).
$$ y= \begin{bmatrix}1\\b_{x}\\b_{y}\\b_{h}\\b_{w}\\0\\1\\0 \end{bmatrix} $$
What if there’s no object in the image? In this case \(p_c=0 \) and the rest of the elements of this vector can be any number, because if there is no object in this image then we don’t care what bounding box of the neural network outputs as well as which of the three objects \(C_1,C_2,C_3 \) it thinks of this.
$$ y=\begin{bmatrix}0\\?\\?\\?\\?\\?\\?\\? \end{bmatrix} $$

Examples of images in a training set
Given a set of labeled training examples this is how we construct it: \(x \) the input image as well as \(y \) the class label both images where there is an object and for images where there is no object, and the set of these will then define our training set.
Loss function
Finally let’s describe the loss function we use to train the neural network. The ground truth label was \(y \), and neural network outputs some \(\hat{y} \) what should the loss bee.
$$ L\left ( \hat{y},y \right )=\left ( \hat{y}_{1}-y_{1} \right )^{2}+\left ( \hat{y}_{2}-y_{2} \right )^{2}+…+\left ( \hat{y}_{8}-y_{8} \right )^{2}, y_{1}=1 $$
$$ L\left ( \hat{y},y \right )= \left ( \hat{y}_{1}-y_{1} \right )^{2}, y_{1}=0 $$
Notice that \(y \) here has \(8 \) components (the first row of loss function), so that goes from sum of the squares of the difference of the elements, and that’s the loss if \(y_1 =1 \). That’s the case where there is an object so \(y_1 \)=\(p_c \). So, if there is an object in the image, then the loss can be the sum of squares over all the different elements.
The other case is if \(y_1 =0.\) That’s if this \(p_c=0 \), in that case the loss can be just \(\hat{y_1} \) minus \(y_1 \) squared because in that second case all the rest of the components are not important. All we care about is how accurately is the neural network outputting \(p_c \) in that case.
Just a recap…
If \(y_1=1 \), then we can use the squared error to penalise squared deviation from the predictor than the actual outputs for all eight components, whereas if \(y_1 =0\) then we don’t care for remaining seven values. All we care about is how accurately is our neural network estimating \(y_1 \) which is equal to \(p_c \). Just as a side comment for those of you that want to know all the details. We’ve used the squared error just to simplify the description here, in practice we could probably use a likelihood loss for the \(C1 \enspace ,C2 \enspace ,C3\enspace \) to the \(softmax \) output but, when calculating the loos, the squared error will work fine.
In the next post, we will talk about Landmark Detection.