#009 Machine Learning – Evaluating a model
Highlights: Hello and welcome. By now we have learned about different learning algorithms, including linear regression and logistic regression. You already have a lot of powerful tools for machine learning, but how do you use these tools effectively? The efficiency of how quickly you can get a machine learning system to work well will depend to a large part on how well you can repeatedly make good decisions about what to do next. In this post, we will talk about a number of tips on how to make decisions about what to do next in a machine learning project that can save you a lot of time. Let’s take a look at some advice on how to build efficient machine learning systems.
Tutorial overview:
1. Making decisions
Let’s start with an example. Say you’ve implemented regularized linear regression to predict housing prices. So you have the usual cost function for your learning algorithm.
$$ J(\overrightarrow{\mathrm{w}}, b)=\frac{1}{2 m} \sum_{i=1}^{m}\left(f_{\overrightarrow{\mathrm{w}}, b}\left(\overrightarrow{\mathrm{x}}^{(i)}\right)-y^{(i)}\right)^{2}+\frac{\lambda}{2 m} \sum_{j=1}^{n} w_{j}^{2} $$
However, if you train the model, and find that it makes unacceptably large errors in its predictions, what do you try next? When you’re building a machine learning algorithm, there are usually a lot of different things you could try. For example, you could decide to get more training examples since it seems to have more data should help. Maybe you think that you have too many features, so you could try a smaller set of features. Or maybe you want to get additional features, such as finally additional properties of the houses to toss into your data. You might wonder if the value of Lambda is chosen well, and you might say, maybe it’s too big, and you want to decrease it. Or you may say, it’s too small, I want to try increasing it. On any given machine learning application, it will often turn out that some of these things could be fruitful, and some of these things not be fruitful. The key to being effective at how you build a machine learning algorithm will be if you can find a way to make good choices about where to invest your time.
So it is crucial for you to learn about how to carry out a set of diagnoses that you can run to gain insight into what is or isn’t working with a learning algorithm. In that way, you will gain guidance in improving its performance.
First, let’s take a look at how to evaluate the performance of your learning algorithm.
2. Evaluating a model
When training a model you don’t want your model to perform poorly after being deployed in production. You need to have a mechanism to assess how well your model is generalizing. Hence, you need to separate your input data into training, validation, and testing subsets to prevent your model from overfitting.
So in order to tell if your model is doing well, especially for applications where you have more than one or two features we need a more systematic way to evaluate how well your model is doing. Here’s a technique that you can use.
If you have a training set with just 10 examples rather than taking all your data to train the parameters of the model, you can instead split the training set into two subsets. Let’s put 60% of the data into the first part and the training set. The second part of the data, let’s say 20% of the data, we are going to put into a test set. The third part of the data, also 20% we are going to put into the validation set. Let’s now describe the role of each of these datasets.
Train Dataset
- Set of data used for learning(to fit the parameters to the machine learning model)
Validation Dataset
- Set of data used to provide an unbiased evaluation of a model during the training.
Test Dataset
- Set of data used to provide an unbiased evaluation of a final model fitted on the training dataset.
The typical workflow of developing a machine learning system is that you have an idea and you train the model, and you almost always find that it doesn’t work as well as you wish yet. The key to the process of building a machine learning system is how to decide what to do next in order to improve his performance. For example, looking at the bias and variance of a learning algorithm gives us very good guidance on what to try next.
3. Diagnosing bias and variance
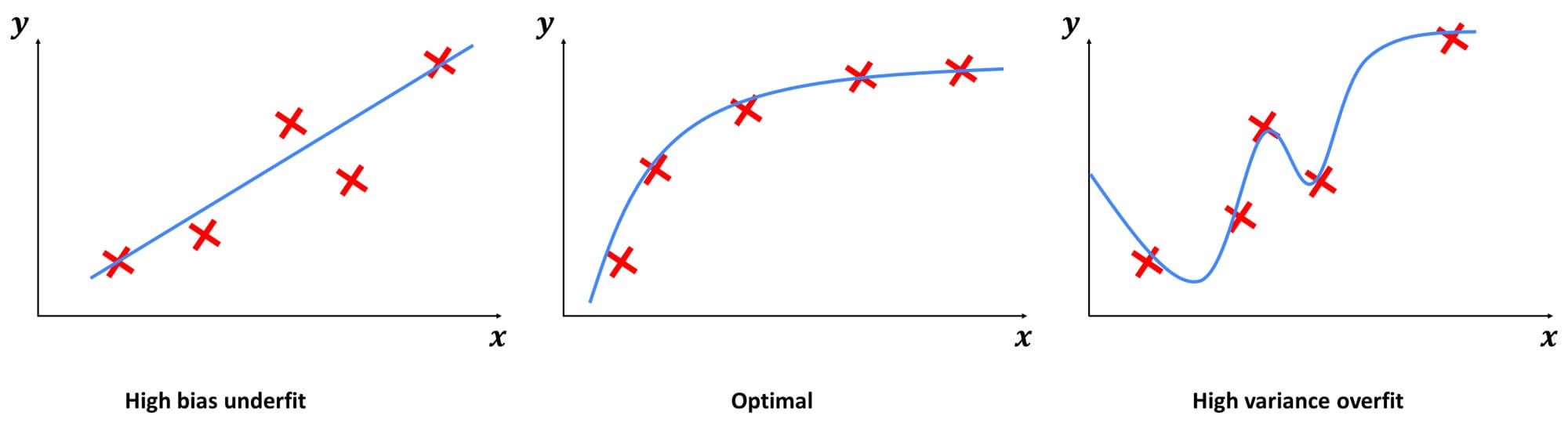
You might remember this example on linear regression. When given this dataset, if you were to fit a straight line to it, it doesn’t do that well. We said that this algorithm has a high bias or that it is under this dataset. If you were to fit a fourth-order polynomial, then it has high variance or overfits. In the middle, if you fit a quadratic polynomial, then it looks pretty good.
So, based on performance on both training and testing data we classify our model into three categories.
- Underfit Model. A model can’t learn the problem and performs poorly on both training and testing datasets.
- Overfit Model. A model learns the training dataset very well but does not perform well on a testing dataset.
- Optimal Model. A model learns the training dataset very well and also performs well on a testing dataset.
The following image illustrates all three scenarios: when the model is overfitted, under fitted, and optimal.

However, if you had more features, you can’t plot f and visualize whether your model is doing well as easily. Instead of trying to look at plots like this, a more systematic way to diagnose or to find out if your algorithm has a high bias or high variance will be to look at the performance of your algorithm on the training set and on the validation set. In particular, let’s look at the example on the left.
If you were to compute training cost you will get a measure of how well the algorithm does on the training set. As you can see, not that well. Training cost here would be high because there are actually pretty large errors between the examples and the actual predictions of the model. How about Validation costs? If we had a few new examples that the algorithm had not previously seen, it would also be high. One characteristic of an algorithm with high bias is that it’s not even doing that well on the training set. So when training cost is high, that is a strong indicator that this algorithm has a high bias.
Let’s now look at the example on the right. If you were to compute training cost, how well is this doing on the training set? Well, it’s actually doing great on the training set. Fits the training data really well and the training cost here will be low. But if you were to evaluate this model on other houses, not in the training set, then you find that validation cost will be quite high. A characteristic signature that your algorithm has high variance will be of validation cost is much higher than training cost. In other words, it does much better on data it has seen than on data it has not seen. This turns out to be a strong indicator that your algorithm has high variance.
Finally, the chase is in the middle. If you look at training cost, it’s pretty low, so this is doing quite well on the training set. If you were to look at a few new examples from your validation set, you find that the validation cost is also pretty low. So, training cost not being too high indicates the model doesn’t have a high bias problem and validation cost not being much worse than training cost indicates that it doesn’t have a high variance problem either. This is why the quadratic model seems to be a pretty good one for this application.
The next question is“how can we avoid this problem”? Well, to avoid overfitting in the neural network we can apply several techniques. Let’s look at some of them.
Simplifying The Model
The first method that we can apply to avoid overfitting is to decrease the complexity of the model. To do that we can simply remove layers and make the network smaller. Note that while removing layers it is important to adjust the input and output dimensions of the remaining layers in the neural network.
Early stopping
Another common approach to avoid overfitting is called early stopping. If you choose this method your goal is very simple. You just need to stop the training process before the model starts learning the irrelevant information(noise). However, we mentioned in the previous chapter that if you apply this method, you can end up with the opposite problem of underfitting. That is why the main challenge of this approach is to find the right point just before your model starts to overfit. This method is illustrated in the following image.
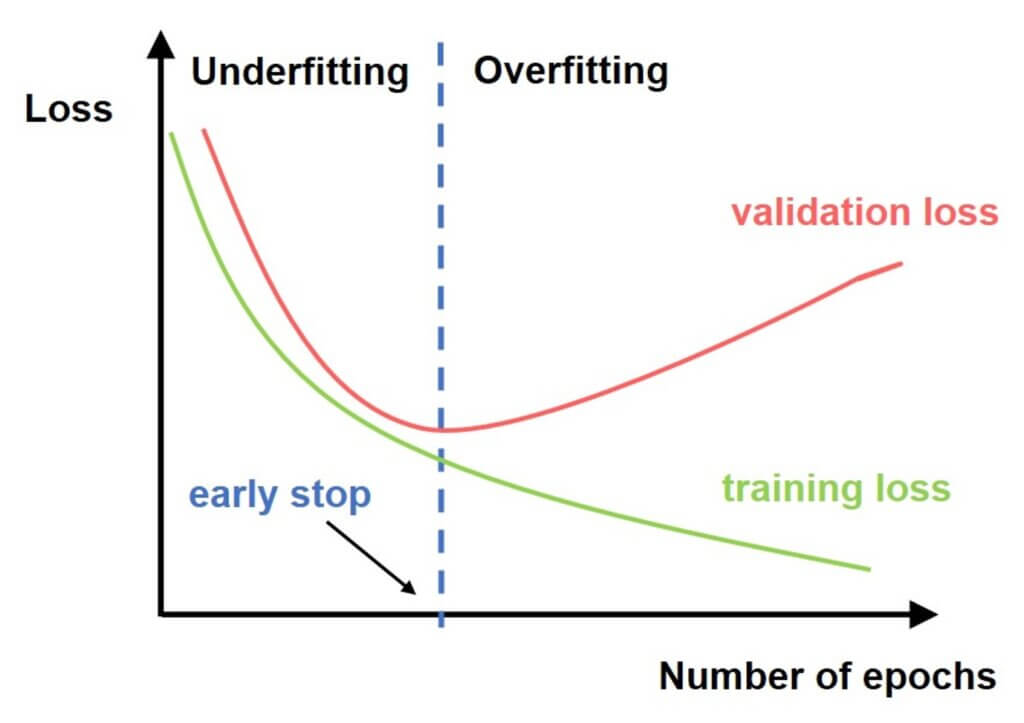
In the image above, the green curve represents the training loss and the red curve represents the validation loss. As we can see, after several epochs, validation loss has started to increase while the training loss is still decreasing. Therefore, we can be sure that the model is overfitting and we can stop the training exactly at the point where validation loss has started to increase.
Adding More Data To The Training Set
Probably the easiest way to eliminate overfitting is to add more data. The more data we have in the training set, our model will be able to learn more. Also, with more data, we’re hoping to be adding more diversity to the training set as well.
Data Augmentation
Data augmentation is the most popular technique that is used to increase the amount of data in the training set. To get more data, we just need to make minor alterations to our existing dataset. Even though the changes that we are making are quite subtle, our neural network will think these are distinct images. The benefit of data augmentation is that the model is unable to overfit all the samples, and is forced to generalize. The most common Data Augmentation techniques are flipping, translation, rotation, scaling, changing brightness, and adding noise. For a more detailed explanation of this topic check this link.
Regularization techniques
Another popular method that we can use to solve the overfitting problem is called Regularization. It is a technique that reduces the complexity of the model. The most common regularization method is to add a penalty to the loss function in proportion to the size of the weights in the model. In that way, the input parameters with larger coefficients are more penalized than the parameters with smaller coefficients. After applying this method we will eventually limit the amount of variance in the model.
There are a number of regularization methods but the most common techniques are called L1 and L2 regularization. The L1 penalty minimizes the absolute value of the weights, whereas the L2 penalty minimizes the squared value of the weights. This is mathematically shown in the following equation.

Here, the term we’re adding to the loss is the sum of the squared norms of the weight matrices which is multiplied by a small constant lambda. It is called the regularization parameter. Note that this is another hyperparameter that we’ll have to tune in order to choose the correct number for our specific model.
The L2 regularization is a technique often used in situations where data is too complex because it is able to learn inherent patterns present in the data. However, a disadvantage of this method is that it is not robust to outliers.
Dropouts
So, regularization methods like L1 and L2 reduce overfitting by modifying the cost function. On the other hand, Dropout is a technique that modifies the network itself. It is a method where randomly selected neurons are ignored during training in each iteration.
The idea behind this technique is that dropping different sets of neurons, it’s equivalent to training different neural networks.
For example, let’s assume that we train multiple models. Each of these models will learn the pattern from the data in different ways. If each component model learns a relationship from the data that contains the true signal with some addition of noise, a combination of models should maintain the relationship of the signal within the data while averaging out the noise.
This approach could solve the problem of overfitting. However training multiple models can take several days. This is why we need some more efficient method which will help us save a lot of time.
Using the dropout method we don’t need to train multiple models separately. We can build multiple representations of the relationship present in the data by randomly dropping neurons from the network during training. Then, in the end, the different networks will overfit in different ways, so the net effect of dropout will be to reduce overfitting.

This technique is shown in the diagram above. It has proven to reduce overfitting to a variety of problems involving image classification, image segmentation, word embeddings, and semantic matching.
Now, let’s see how we can select the best model in Python.
4. Learning curves in Python
Let’s look at an example of using cross-validation to compute the validation curve for a class of models. Here we will use a polynomial regression model: this is a generalized linear model in which the degree of the polynomial is a tunable parameter. For example, a degree-1 polynomial fits a straight line to the data.
First, let’s import the necessary libraries.
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import make_pipeline
import numpy as np
Next, we will define the function PolynomialRegression().
def PolynomialRegression(degree=2, **kwargs):
return make_pipeline(PolynomialFeatures(degree),
LinearRegression(**kwargs))Now let’s create some data to which we will fit our model.
def make_data(N, err=1.0, rseed=1):
# randomly sample the data
rng = np.random.RandomState(rseed)
X = rng.rand(N, 1) ** 2
y = 10 - 1. / (X.ravel() + 0.1)
if err > 0:
y += err * rng.randn(N)
return X, y
X, y = make_data(40)Now, we can visualize our data, along with polynomial fits of several degrees.
import matplotlib.pyplot as plt
import seaborn; seaborn.set() # plot formatting
X_test = np.linspace(-0.1, 1.1, 500)[:, None]
plt.scatter(X.ravel(), y, color='black')
axis = plt.axis()
for degree in [1, 3, 5]:
y_test = PolynomialRegression(degree).fit(X, y).predict(X_test)
plt.plot(X_test.ravel(), y_test, label='degree={0}'.format(degree))
plt.xlim(-0.1, 1.0)
plt.ylim(-2, 12)
plt.legend(loc='best');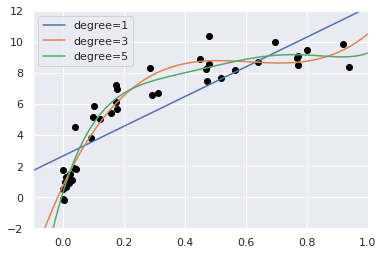
What controls model complexity, in this case, is the degree of the polynomial, which can be any non-negative integer. A useful question to answer is this: what degree of polynomial provides a suitable trade-off between bias (under-fitting) and variance (over-fitting)?
We can make progress in this by visualizing the validation curve for this particular data and model; this can be done straightforwardly using the validation_curve convenience routine provided by Scikit-Learn. Given a model, data, parameter name, and a range to explore, this function will automatically compute both the training score and validation score across the range.
from sklearn.model_selection import validation_curve
degree = np.arange(0, 21)
train_score, val_score = validation_curve(PolynomialRegression(), X, y,param_name='polynomialfeatures__degree',
param_range= degree, cv=7)
plt.plot(degree, np.median(train_score, 1), color='blue', label='training score')
plt.plot(degree, np.median(val_score, 1), color='red', label='validation score')
plt.legend(loc='best')
plt.ylim(0, 1)
plt.xlabel('degree')
plt.ylabel('score');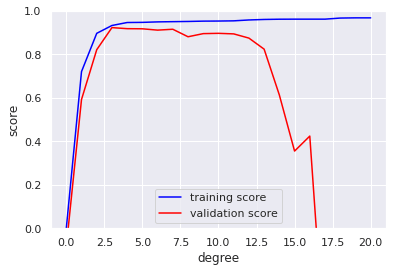
This shows precisely the qualitative behavior we expect: the training score is everywhere higher than the validation score. The training score is monotonically improving with increased model complexity, and the validation score reaches a maximum before dropping off as the model becomes over-fit.
From the validation curve, we can read that the optimal trade-off between bias and variance is found for a third-order polynomial; we can compute and display this fit over the original data as follows.
plt.scatter(X.ravel(), y)
lim = plt.axis()
y_test = PolynomialRegression(3).fit(X, y).predict(X_test)
plt.plot(X_test.ravel(), y_test);
plt.axis(lim);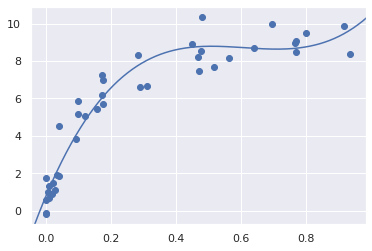
Summary
In this post, we have explored the concept of model evaluation, focusing on intuitive aspects of the bias-variance trade-off. We have talked about several useful tips that can help you to make decisions in order to improve the performance of your model.