Top 10 GitHub Papers :: Object Detection

Object detection, a subset of computer vision, is an automated method for locating interesting objects in an image with respect to the background. This could be buildings, cars, or humans in digital images and videos. Some popular areas of interest include face detection.
Object detection has a various amount of areas it may be applied in computer vision including video surveillance, and image retrieval.
In this section, you can find state-of-the-art, greatest papers for object detection along with the authors’ names, link to the paper, Github link & stars, number of citations, dataset used and date published. Enjoy.
1. Searching for MobileNetV3

Abstract: We present the next generation of MobileNets based on a combination of complementary search techniques as well as a novel architecture design. MobileNetV3 is tuned to mobile phone CPUs through a combination of hardware-aware network architecture search (NAS) complemented by the NetAdapt algorithm and then subsequently improved through novel architecture advances. This paper starts the exploration of how automated search algorithms and network design can work together to harness complementary approaches improving the overall state of the art. Through this process we create two new MobileNet models for release: MobileNetV3-Large and MobileNetV3-Small which are targeted for high and low resource use cases. These models are then adapted and applied to the tasks of object detection and semantic segmentation. For the task of semantic segmentation (or any dense pixel prediction), we propose a new efficient segmentation decoder Lite Reduced Atrous Spatial Pyramid Pooling (LR-ASPP). We achieve new state of the art results for mobile classification, detection and segmentation. MobileNetV3-Large is 3.2\% more accurate on ImageNet classification while reducing latency by 15\% compared to MobileNetV2. MobileNetV3-Small is 4.6\% more accurate while reducing latency by 5\% compared to MobileNetV2. MobileNetV3-Large detection is 25\% faster at roughly the same accuracy as MobileNetV2 on COCO detection. MobileNetV3-Large LR-ASPP is 30\% faster than MobileNetV2 R-ASPP at similar accuracy for Cityscapes segmentation.
- Authors: Andrew Howard • Mark Sandler • Grace Chu • Liang-Chieh Chen • Bo Chen • Mingxing Tan • Weijun Wang • Yukun Zhu • Ruoming Pang • Vijay Vasudevan • Quoc V. Le • Hartwig Adam
- Paper: https://arxiv.org/pdf/1905.02244v5.pdf
- Github: https://github.com/tensorflow/models/tree/master/research/deeplab
- Dataset: COCO, Cityscape
- Github ⭐: 61,911 and the stars were counted on 27/02/2020
- Citations: Cited by 76
- Published: 6 May 2019
2. Looking Fast and Slow: Memory-Guided Mobile Video Object Detection

Abstract: With a single eye fixation lasting a fraction of a second, the human visual system is capable of forming a rich representation of a complex environment, reaching a holistic understanding which facilitates object recognition and detection. This phenomenon is known as recognizing the “gist” of the scene and is accomplished by relying on relevant prior knowledge. This paper addresses the analogous question of whether using memory in computer vision systems can not only improve the accuracy of object detection in video streams, but also reduce the computation time. By interleaving conventional feature extractors with extremely lightweight ones which only need to recognize the gist of the scene, we show that minimal computation is required to produce accurate detections when temporal memory is present. In addition, we show that the memory contains enough information for deploying reinforcement learning algorithms to learn an adaptive inference policy. Our model achieves state-of-the-art performance among mobile methods on the Imagenet VID 2015 dataset, while running at speeds of up to 70+ FPS on a Pixel 3 phone.
- Authors: Mason Liu • Menglong Zhu • Marie White • Yinxiao Li • Dmitry Kalenichenko
- Paper: https://arxiv.org/pdf/1903.10172v1.pdf
- Github: https://github.com/tensorflow/models/tree/master/research/lstm_object_detection
- Dataset: ImageNet VID 2015
- Github ⭐: 61,966 and the stars were counted on 01/03/2020
- Citations: Cited by 1
- Published: 25 March 2019
3. Pooling Pyramid Network for Object Detection

Abstract: We’d like to share a simple tweak of Single Shot Multibox Detector (SSD) family of detectors, which is effective in reducing model size while maintaining the same quality. We share box predictors across all scales, and replace convolution between scales with max pooling. This has two advantages over vanilla SSD: (1) it avoids score miscalibration across scales; (2) the shared predictor sees the training data over all scales. Since we reduce the number of predictors to one, and trim all convolutions between them, model size is significantly smaller. We empirically show that these changes do not hurt model quality compared to vanilla SSD.
- Authors: Pengchong Jin • Vivek Rathod • Xiangxin Zhu
- Paper: https://arxiv.org/pdf/1807.03284v1.pdf
- Github: https://github.com/tensorflow/models/tree/master/research/object_detection
- Dataset: COCO
- Github ⭐: 61,912 and the stars were counted on 27/02/2020
- Citations: Cited by 6
- Published: 9 July 2018
4. MobileNetV2: Inverted Residuals and Linear Bottlenecks

Abstract: In this paper we describe a new mobile architecture, MobileNetV2, that improves the state of the art performance of mobile models on multiple tasks and benchmarks as well as across a spectrum of different model sizes. We also describe efficient ways of applying these mobile models to object detection in a novel framework we call SSDLite. Additionally, we demonstrate how to build mobile semantic segmentation models through a reduced form of DeepLabv3 which we call Mobile DeepLabv3. The MobileNetV2 architecture is based on an inverted residual structure where the input and output of the residual block are thin bottleneck layers opposite to traditional residual models which use expanded representations in the input an MobileNetV2 uses lightweight depthwise convolutions to filter features in the intermediate expansion layer. Additionally, we find that it is important to remove non-linearities in the narrow layers in order to maintain representational power. We demonstrate that this improves performance and provide an intuition that led to this design. Finally, our approach allows decoupling of the input/output domains from the expressiveness of the transformation, which provides a convenient framework for further analysis. We measure our performance on Imagenet classification, COCO object detection, VOC image segmentation. We evaluate the trade-offs between accuracy, and number of operations measured by multiply-adds (MAdd), as well as the number of parameters
- Authors: Mark Sandler • Andrew Howard • Menglong Zhu • Andrey Zhmoginov • Liang-Chieh Chen
- Paper: https://arxiv.org/pdf/1801.04381v4.pdf
- Github: https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet
- Dataset: PASCAL VOC 2012, ImageNet, COCO
- Github ⭐: 61,912 and the stars were counted on 27/02/2020
- Citations: Cited by 1293
- Published: 13 January 2018
5. Focal Loss for Dense Object Detection
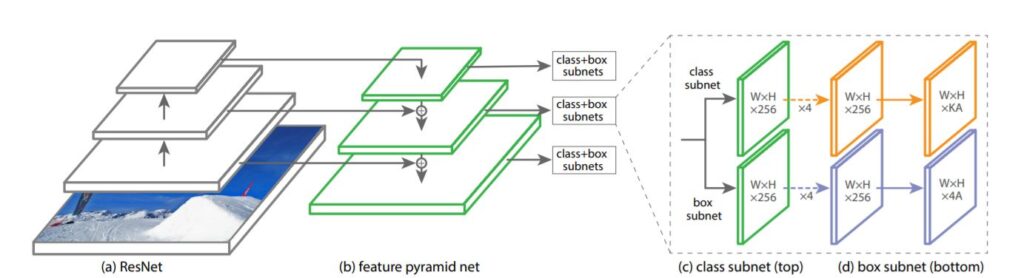
Abstract: The highest accuracy object detectors to date are based on a two-stage approach popularized by R-CNN, where a classifier is applied to a sparse set of candidate object locations. In contrast, one-stage detectors that are applied over a regular, dense sampling of possible object locations have the potential to be faster and simpler, but have trailed the accuracy of two-stage detectors thus far. In this paper, we investigate why this is the case. We discover that the extreme foreground-background class imbalance encountered during training of dense detectors is the central cause. We propose to address this class imbalance by reshaping the standard cross entropy loss such that it down-weights the loss assigned to well-classified examples. Our novel Focal Loss focuses training on a sparse set of hard examples and prevents the vast number of easy negatives from overwhelming the detector during training. To evaluate the effectiveness of our loss, we design and train a simple dense detector we call RetinaNet. Our results show that when trained with the focal loss, RetinaNet is able to match the speed of previous one-stage detectors while surpassing the accuracy of all existing state-of-the-art two-stage detectors. The highest accuracy object detectors to date are based on a two-stage approach popularized by R-CNN, where a classifier is applied to a sparse set of candidate object locations. In contrast, one-stage detectors that are applied over a regular, dense sampling of possible object locations have the potential to be faster and simpler, but have trailed the accuracy of two-stage detectors thus far. In this paper, we investigate why this is the case. We discover that the extreme foreground-background class imbalance encountered during training of dense detectors is the central cause. We propose to address this class imbalance by reshaping the standard cross entropy loss such that it down-weights the loss assigned to well-classified examples. Our novel Focal Loss focuses training on a sparse set of hard examples and prevents the vast number of easy negatives from overwhelming the detector during training. To evaluate the effectiveness of our loss, we design and train a simple dense detector we call RetinaNet. Our results show that when trained with the focal loss, RetinaNet is able to match the speed of previous one-stage detectors while surpassing the accuracy of all existing state-of-the-art two-stage detectors. Code is at: https://github.com/facebookresearch/Detectron.
- Authors: Tsung-Yi Lin • Priya Goyal • Ross Girshick • Kaiming He • Piotr Dollár
- Paper: https://arxiv.org/pdf/1708.02002v2.pdf
- Github: https://github.com/facebookresearch/Detectron
- Dataset: COCO
- Github ⭐: 22,874 and the stars were counted on 27/02/2020
- Citations: Cited by 2604
- Published: 7 August 2017
6. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
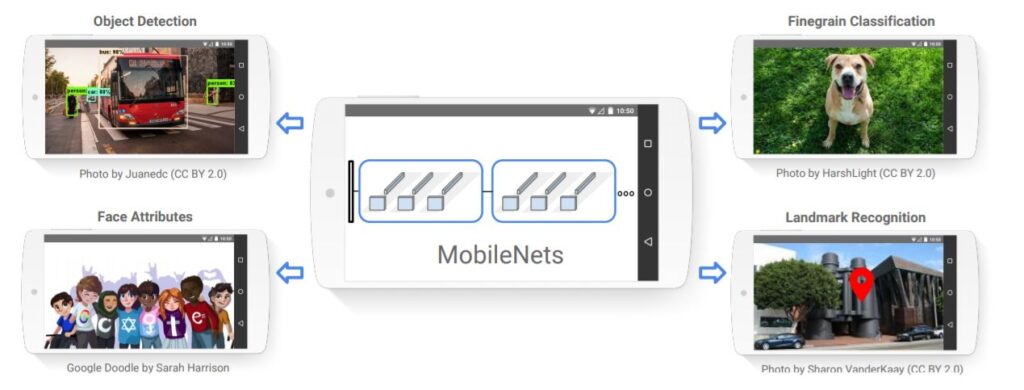
Abstract: We present a class of efficient models called MobileNets for mobile and embedded vision applications. MobileNets are based on a streamlined architecture that uses depth-wise separable convolutions to build light weight deep neural networks. We introduce two simple global hyper-parameters that efficiently trade off between latency and accuracy. These hyper-parameters allow the model builder to choose the right sized model for their application based on the constraints of the problem. We present extensive experiments on resource and accuracy tradeoffs and show strong performance compared to other popular models on ImageNet classification. We then demonstrate the effectiveness of MobileNets across a wide range of applications and use cases including object detection, finegrain classification, face attributes and large scale geo-localization.
- Authors: Andrew G. Howard • Menglong Zhu • Bo Chen • Dmitry Kalenichenko • Weijun Wang • Tobias Weyand • Marco Andreetto • Hartwig Adam
- Paper: https://arxiv.org/pdf/1704.04861v1.pdf
- Github: https://github.com/tensorflow/models/tree/master/research/slim
- Dataset: ImageNet
- Github ⭐: 61,911 and the stars were counted on 27/02/2020
- Citations: Cited by 3549
- Published: 17 April 2017
7. Mask R-CNN
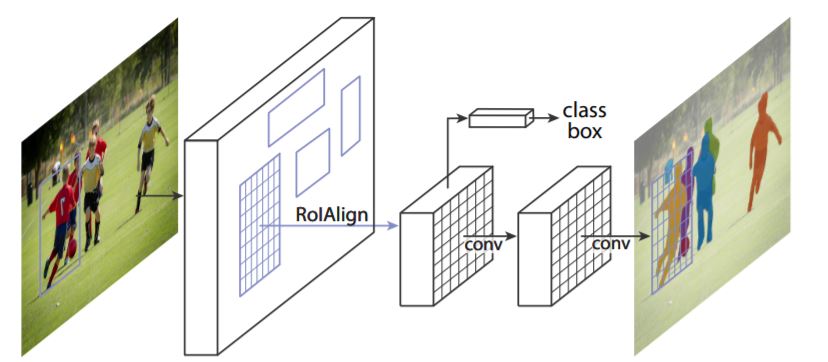
Abstract: We present a conceptually simple, flexible, and general framework for object instance segmentation. Our approach efficiently detects objects in an image while simultaneously generating a high-quality segmentation mask for each instance. The method, called Mask R-CNN, extends Faster R-CNN by adding a branch for predicting an object mask in parallel with the existing branch for bounding box recognition. Mask R-CNN is simple to train and adds only a small overhead to Faster R-CNN, running at 5 fps. Moreover, Mask R-CNN is easy to generalize to other tasks, e.g., allowing us to estimate human poses in the same framework. We show top results in all three tracks of the COCO suite of challenges, including instance segmentation, bounding-box object detection, and person keypoint detection. Without bells and whistles, Mask R-CNN outperforms all existing, single-model entries on every task, including the COCO 2016 challenge winners. We hope our simple and effective approach will serve as a solid baseline and help ease future research in instance-level recognition. Code has been made available at: https://github.com/facebookresearch/Detectron
- Authors: Kaiming He • Georgia Gkioxari • Piotr Dollár • Ross Girshick
- Paper: https://arxiv.org/pdf/1703.06870v3.pdf
- Github: https://github.com/facebookresearch/Detectron
- Dataset: COCO, Cityscapes
- Github ⭐: 22,874 and the stars were counted on 27/02/2020
- Citations: Cited by 5207
- Published: 20 March 2017
8. Speed/accuracy trade-offs for modern convolutional object detectors
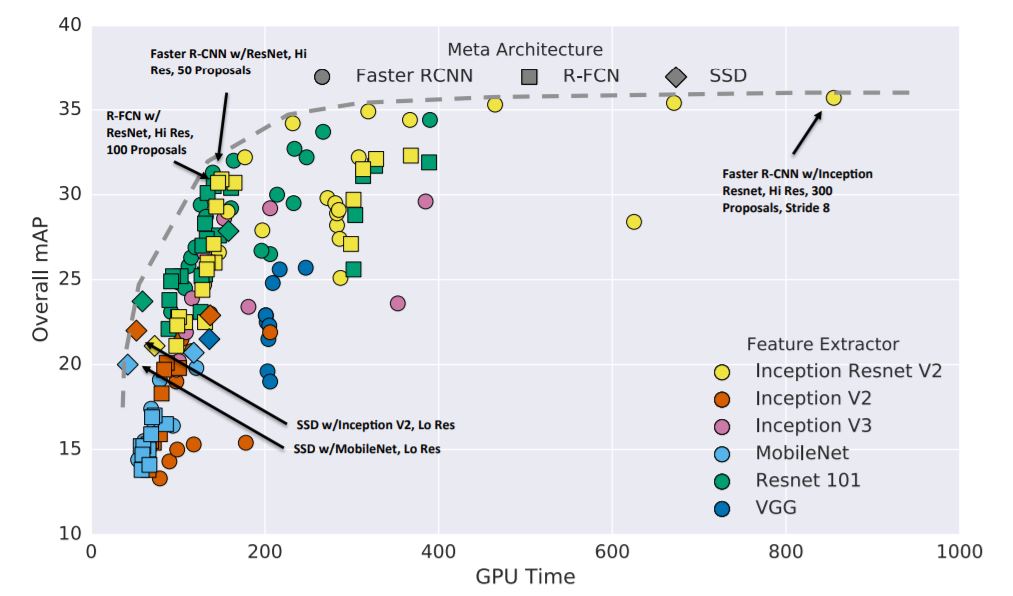
Abstract: The goal of this paper is to serve as a guide for selecting a detection architecture that achieves the right speed/memory/accuracy balance for a given application and platform. To this end, we investigate various ways to trade accuracy for speed and memory usage in modern convolutional object detection systems. A number of successful systems have been proposed in recent years, but apples-to-apples comparisons are difficult due to different base feature extractors (e.g., VGG, Residual Networks), different default image resolutions, as well as different hardware and software platforms. We present a unified implementation of the Faster R-CNN [Ren et al., 2015], R-FCN [Dai et al., 2016] and SSD [Liu et al., 2015] systems, which we view as “meta-architectures” and trace out the speed/accuracy trade-off curve created by using alternative feature extractors and varying other critical parameters such as image size within each of these meta-architectures. On one extreme end of this spectrum where speed and memory are critical, we present a detector that achieves real time speeds and can be deployed on a mobile device. On the opposite end in which accuracy is critical, we present a detector that achieves state-of-the-art performance measured on the COCO detection task.
- Authors: Jonathan Huang • Vivek Rathod • Chen Sun • Menglong Zhu • Anoop Korattikara • Alireza Fathi • Ian Fischer • Zbigniew Wojna • Yang Song • Sergio Guadarrama • Kevin Murphy
- Paper: https://arxiv.org/pdf/1611.10012v3.pdf
- Github: https://github.com/IBM/MAX-Object-Detector
- Dataset: COCO
- Github ⭐: 59 and the stars were counted on 27/02/2020
- Citations: Cited by 1174
- Published: 30 November 2016
9. Deep Residual Learning for Image Recognition
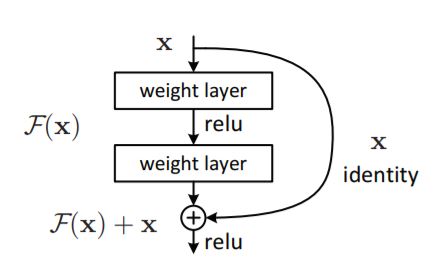
Abstract: Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers—8x deeper than VGG nets but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers. The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions, where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.
- Authors: Kaiming He • Xiangyu Zhang • Shaoqing Ren • Jian Sun
- Paper: https://arxiv.org/pdf/1512.03385v1.pdf
- Github: https://github.com/tensorflow/models/tree/master/research/slim
- Dataset: ImageNet, COCO
- Github ⭐: 61,965 and the stars were counted on 01/03/2020
- Citations: Cited by 40,397
- Published: 10 December 2015
10. Going Deeper with Convolutions
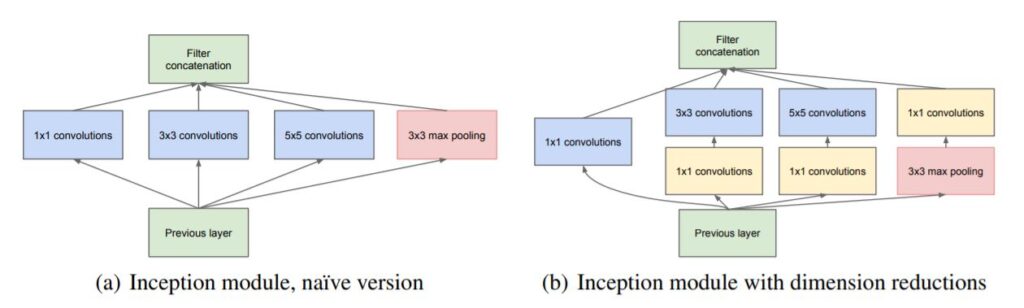
Abstract: We propose a deep convolutional neural network architecture codenamed “Inception”, which was responsible for setting the new state of the art for classification and detection in the ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC 2014). The main hallmark of this architecture is the improved utilization of the computing resources inside the network. This was achieved by a carefully crafted design that allows for increasing the depth and width of the network while keeping the computational budget constant. To optimize quality, the architectural decisions were based on the Hebbian principle and the intuition of multi-scale processing. One particular incarnation used in our submission for ILSVRC 2014 is called GoogLeNet, a 22 layers deep network, the quality of which is assessed in the context of classification and detection.
- Authors: Christian Szegedy • Wei Liu • Yangqing Jia • Pierre Sermanet • Scott Reed • Dragomir Anguelov • Dumitru Erhan • Vincent Vanhoucke • Andrew Rabinovich
- Paper: https://arxiv.org/pdf/1409.4842v1.pdf
- Github: https://github.com/tensorflow/models/blob/master/research/slim/nets/inception_v1.py
- Dataset: ImageNet Detection
- Github ⭐: 61,883 and the stars were counted on 26/02/2020
- Citations: Cited by 19,580
- Published: 17 September 2014