#OD1 YOLO Object Detection

YOU ONLY LOOK ONCE
Highlights: In this post we will learn about the YOLO Object Detection system, and how to implement such a system with Keras.

About Yolo:
Our unified architecture is extremely fast. Our base YOLO model processes images
in real-time at 45 frames per second. A smaller version of the network, Fast YOLO,
processes an astounding 155 frames per second …
— You Only Look Once: Unified, Real-Time Object Detection, 2015
Tutorial Overview:
This post covers the following topics:
1. What is Yolo?
Yolo is a state-of-the-art, object detection system (network). It was developed by Joseph Redmon. The biggest advantage over other popular architectures is speed. The Yolo model family models are really fast, much faster than R-CNN and others. This means that we can achieve real-time object detection.
Yolo involves a single neural network trained end-to-end that takes an image as input and predicts class labels and bounding boxes for each bounding box directly. This technique offers lower accuracy but operates at 45 frames per second and up to 155 frames per second.

The Yolo model works by splitting the input image into grid cells, where each cell is associated with a bounding box that falls within it.
Each cell will predict the bounding box and confidence. A class prediction is also based on each cell. You can find more about Yolo here.
Architecture:
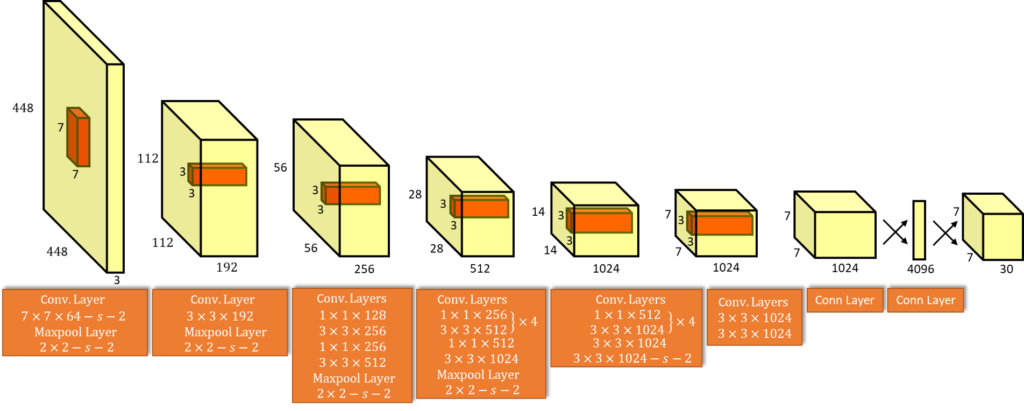
2. Implementation in Keras
The first step is to import all required libraries:
There will be a lot of convolutional blocks(layers), so the easiest way is to make a function for this, where we will pass important parameters that will change from layer to layer.
Next step is to create a layer, using the previously defined conv_block function:
If we are using pre-trained Neural Network, we need to read the weights of that network, so the next important thing is to define a class with functions for this, as follow:
Download the weights from the next link, and place them in a specific folder for this project. OS library provides us with a function to change the path of our program, so this is one of a few to do this.
Then read the weights file. Also, we can save our model to disk, so there is no need to load the weights later again because this can take some time.
One of the ways to read an image is to use OpenCV or Keras. Keras.preprocesing provides us with the same functions to read pictures or work with them.
There is often a need to perform the same task again, especially when we are working with pictures. So we will define a function that reads the image, normalize, and return the normalized image, with a width and height information.
3. Testing
Now we can test our model and make some predictions.
Model predictions are, in fact, encoded candidate bounding boxes from three different grid sizes, and the boxes are defined as anchor boxes, based on an analysis of the size of objects in the MSCOCO dataset. Any bounding box with a class probability below a threshold, can not be described as an object, and will be ignored. Here we use a probability of 0.6, which is 60%. Function decode_netout is provided by experiencor, and the whole file can be found at this link. This function returns a list of BoundBox instances that define the corners of each bounding box and class probabilities.
The bounding boxes predicted by our model does not match the size of the original image. So the next important step is to stretch them, and this can be done by using the correct_yolo_boxes function. This functions is also provided by experiencor and can be found at this link. It performs translation of bounding box coordinates, and the coordinates of the bounding box are updated directly.
The list of bounding boxes can be filtered and the boxes that overlap and refer to the same object can be merged. The amount of overlap is in this case 0.6, which refers to 60%. This process is called non-maximal suppression, and it is an important and required step in post-processing. If we delete the overlapping boxes, we lose the opportunity to use it to detect another object type, so we just need to clear their probability for the overlapping class.
One of the most important parts of this procedure is called Intersection over Union.
After non-maximal suppression, we will have the same number of boxes, but only a few of interest. We can retrieve just those boxes that strongly predict the presence of an object by just going through every box and check class prediction value.
We also need a list of strings containing the class labels from the MSCOCO dataset known to the model in the correct order used during training.
In the end, we can plot the original photo, with bounding boxes around detected objects. Matplotlib.patches has a function called Rectangle, which can help us to draw rectangles around objects. It can also be done by using the OpenCV library.
And the final result.
Another example:
Summary
In the end, this is one of the most ways for object detection, also one of the best. This network can be trained on other datasets, which are well labeled. As well it is possible to filter categories to detect just certain objects, like people, faces, or even cars, signs in autonomous vehicle systems.
More resources on the topic:
- YOLO: Real-Time Object Detection
- Experiencor GitHub
- CNN Object Localization
- CNN Intersection over Union
- Face Detection with OpenCV
References:
Deep Learning for Computer Vision, Jason Brownlee
keras-yolo3, Huynh Ngoc Anh, MIT License