#001 Uvod u Data Science

Uvod u Data Science
Ideja o nastanku bloga o Data Science-u na srpskom jeziku motivisana je sledećim razlozima:
-
- Na svetskom tržištu postoji velika potreba za Data Science veštinama. U Srbiji svega nekoliko kompanija ima svoja Data Science odeljenja koja se susreću sa velikim problemom pronalaženja adekvatanog kadra.
- Ideja o blogu motivisana je nedavnom inicijativom da se uvedu studijski programi osnovnih i master studija koji su posvećeni Data Science-u. Više o tome možete saznati na sledećem linku.
- Razvojem softverskih alata Data Science više nije oblast koja isključivo zahteva doktorat (PhD) već se mnogi strukovni profili mogu priključiti ovoj oblasti. Sa druge strane, treba istaći, da ekspertiza u Data Science oblasti zahteva detaljno iščitavanje velikog broja udžbenika, solidnog programiranja i rešavanja algoritamskih problema.
- Blog će se inicijalno baviti osnovama Data Science-a i mašinskog učenja u cilju njihove demistifikacije.
- Konferencije u Srbiji: Sinteza 2017, Data Science Conference.
- Ideja je da blog postepeno preraste u platformu za Data Science takmičenja, kako juniora tako i seniora. Sama takmičenja biće inspirisana problemima iz akademije ili industrije.
Šta je Data Science?
Ukratko, Data Science i mašinsko učenje glavni su pokretači vodećih svetskih IT kompanija:
Google, Facebook, LinkedIn, Instagram, …
Google ima mogućnost da pretraži veliki broj internet stranica i pronađe odgovore na tražene upite. Facebook automatski sortira naš News Feed, preporučuje prijatelje, dok Instagram procesira slike i vrši preporuke sličnih slika. Na taj način uči koje slike će privući našu pažnju. Amazon je svoju ekspertizu razvio na algoritmu za preporuku knjiga koje potencijalni kupac želi da kupi (engl. Recommendation systems).
Dobro je podsetiti se da je Harvard business review još 2012. predvideo Data Science kao novo i revolucionarno zanimanje.
Kada govorimo o Data Science-u njene glavne podgrane podrazumevaju znanja iz sledećih oblasti:
- Mašinsko učenje – Machine Learning
- Matematika, statistika i verovatnoća, linearna algebra, metode optimizacije
- Programiranje – trenutno najpopularniji su script jezici: Python i R.
- Vizuelizacija podataka
- Komunikacione veštine
- Ekonomija i biznis
Važno je istaći da se ne očekuje da neko bude ekspert u svim oblastima.
Detaljan pregled o tome šta je zapravo Data Science i kakva je njena razlika od mašinskog učenja data je u prvom poglavlju knjige, Doing Data Science, Rachel Schutt i Cathy O’Neil.
Takođe, važano je napomenuti da rezultat Data Science-a treba da bude proizvod koji je kreiran uz pomoć podataka i algoritama.
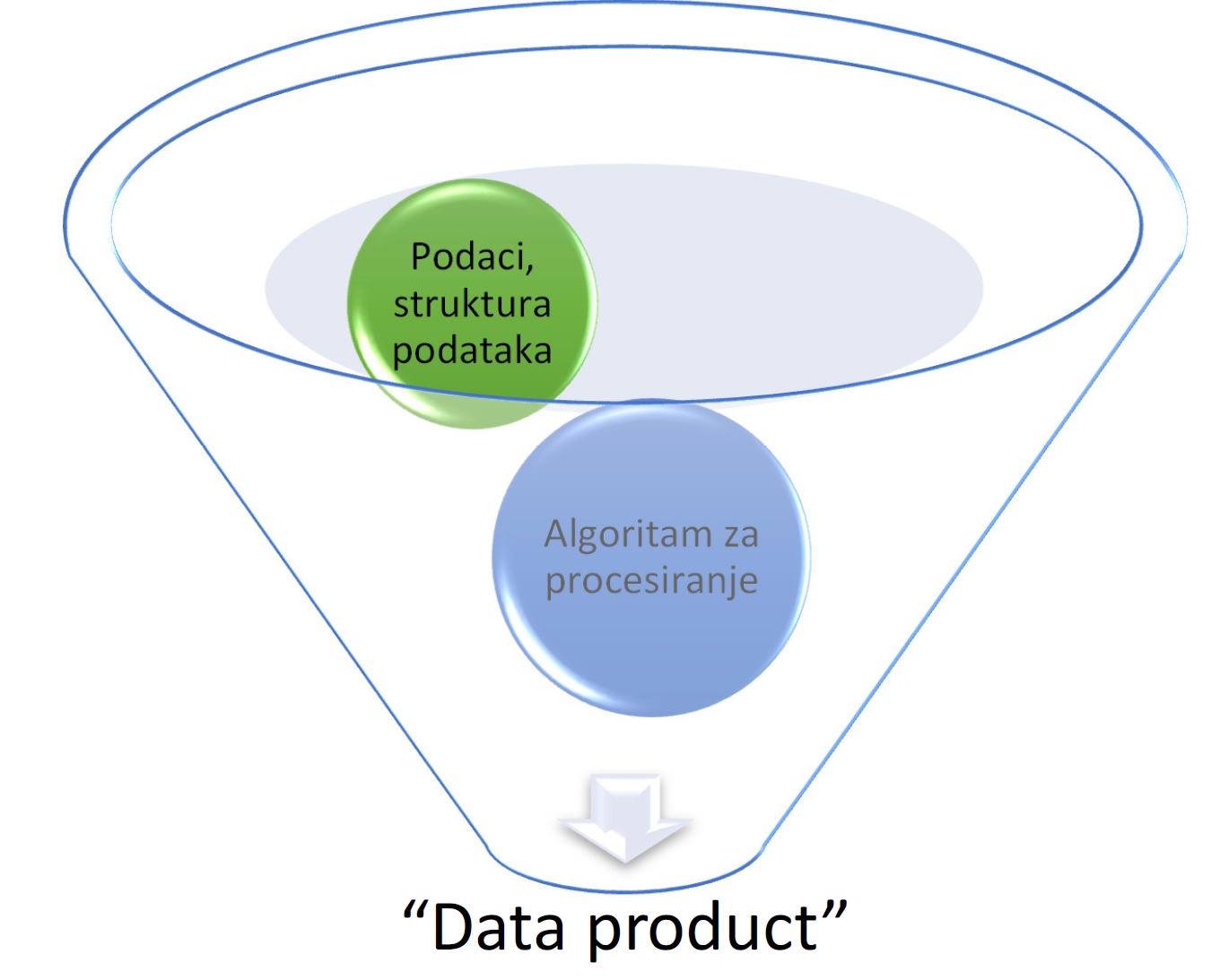
Proces obrade podataka
Mašinsko učenje
Dve glavne komponente mašinskog učenja su podaci i algoritmi. Algoritmi procesiraju podatke, obučavaju (treniraju) parametre i na taj način stiču sposobnost da u novim scenarijima donose pametne odluke.
Pogledajmo prvo šta su to podaci i u kojim primenama se najčešće sreću:
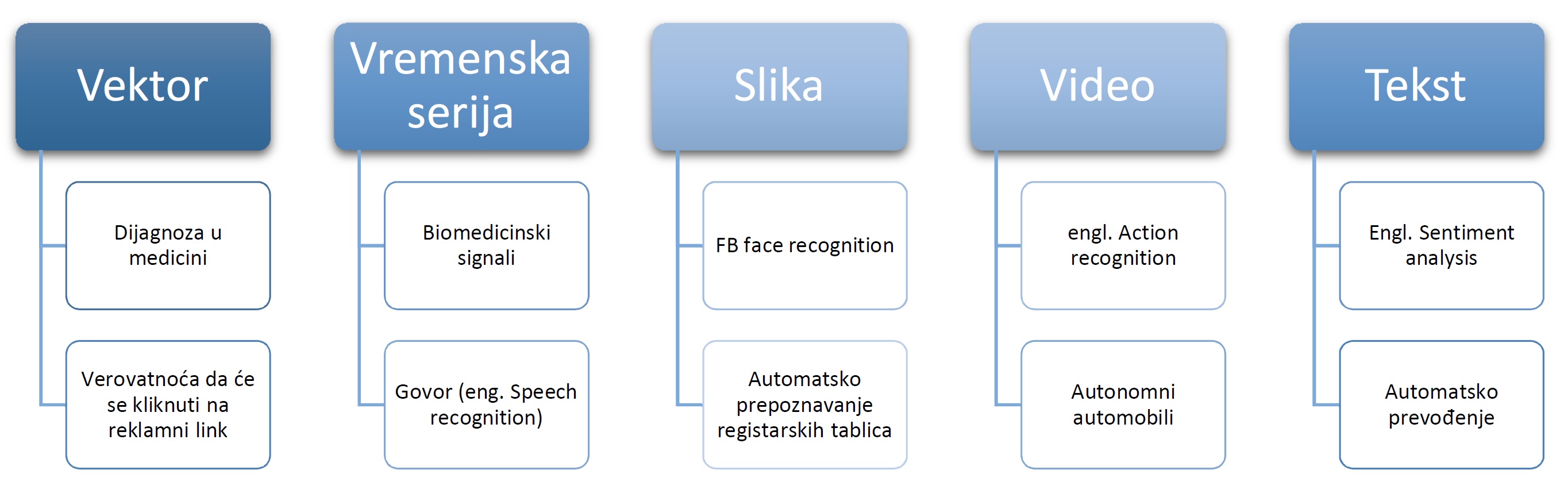
Vrste podataka i primena mašinskog učenja
- Podaci prisutni u formi vektora mogu da budu rezultati krvne slike. Prilikom analize rezultata krvne slike, možemo da obučimo algoritam koji će pacijente klasifikovati da li imaju određeno oboljenje.
- Vremenske serije kao što su biomedicinski signali (EKG – elektrokardiogram, EEG – elektroencefalogram itd.) koristi se u monitoringu bolesti i dijagnostici (da li pacijent ima određeno oboljenje ili ne).
- Na naplatnim rampama u Srbiji postoji algoritam koji tačno prepoznaje broj na osonovu slike registarskim tablicama.
- Kod razvoja autonomnih automobila trenutno se javlja veliki napredak, a kao glavni podatak za procesiranje koristi se video snimak.
- Važna grana Data Science-a je i procesiranje tekstualnih podataka. Primer može biti automatsko prepoznavanje zadovoljstva korisnika u velikom broju komentara.
- Mnoge kompanije prikupljanjem parametara o potrošačima segmentiraju svoje korisnike, koji prikazuju personalizovane reklame.
Navedeni podaci obrađuju se aloritmima mašinskog učenja koji se koriste pri:
- Klasifikaciji – da li je pacijent zdrav ili ne, da li je e-mail spam ili ne;
- Klasterovanju – segmentacija korisnika internet portala po kategorijama;
- Regresiji – određivanje novih vrednosti neke funkcije. Na primer kolika se potrošnja električne energije može očekivati u narednom periodu;
- Sistemi za preporuke (engl. Recommender system) – koji će video Youtube preporučiti odgovarajućem korisniku.
Mašinsko učenje bazira se na ideji da algoritmu dostavimo podatke, na kojima će se on obučiti, a potom donositi odluke u situacijama koje mu do tada nisu bile poznate. Na primer, iako nikada ranije nije video e-mail koji nam pristiže, spam filter ima mogućnost da prepozna spam poruke. Da bi to bilo moguće, spam filter je pre toga morao da “vidi” veliku količinu spam i običnih mejlova. Kako mašina može da rešava ove komplikovane zadatke? Veoma jednostavan spam filter mogao bi na primer da proverava da li se u mejlu nalazi reč “kazino”. Ukoliko da, verovatnoća da se radi o spam poruci bi se povećala. Naravno, algoritam mora da bude dovoljno efikasan da mejl od našeg prijatelja koji nam možda piše o svom iskustvu iz kazina ne protumači pogrešno.
Izazovi i problemi koje rešava mašinsko učenje mogu biti teški. Međutim, razvojem gotovih softverskih rešenja, sve je lakše rešavati probleme iz mašinskog učenja. Pre 15 godina razvoj sistema za automatsko prepoznavanje tablica ili automatsko prepoznavanje ručno pisanih cifara (engl. OCR – Optical Character Recognition) predstavljali su zahtevne inženjerske probleme. Danas se ovi sistemi projektuju izuzetno brzo i koriste se uglavnom kao demonstrativni Data Science primeri.