#030 CNN One-Shot Learning
One – Shot Learning
Solving the one-shot problem represents a challenge of face recognition task. This means that for most face recognition applications we need to recognize a person having only a single image or given just one example of that person’s face. Typically, deep learning algorithms don’t work well if there is only one training example. However, we will show how this problem can be tackled.
Let’s say that we have a database of \(4 \) pictures of employees in one organization. Let’s say someone shows up at the office and we need to detect who has arrived.

Examples of images of people in our database (left) and persons that we need to recognise (right)
So, this system with only one image, has to determine whether this person is in a database. That is, it will check all images in the database and it has to match it with the “same” person. On the other hand, if that image is matched with any other person, the system has to produce output “different” person. This is depicted in the Figure above for our mini database of \(4\) persons.
The one-shot learning problem is a problem where a system has to learn from just one example and has to recognize that person again.
Learning from example to recognize the person again

The input image (left) goes through a CNN and produces the one – shot output (right)
One approach we could try is to input the image of the person, feed it to a \(convnet \), and have it output a label \(y\) using a \(softmax \) unit. This really doesn’t work well, because if we have such a small training set, it is really not enough data to train a robust neural network for this task. Also, what if a new person joins our team? Then, we have one more person to recognize, so there should be one more output in the \(softmax \) output unit.
Do we have to retrain the \(convnet\) every time? That just doesn’t seem like a good approach.
Instead, we are going to use a “similarity” function and use it as our cost training function. In particular, we want a neural network to learn a function (d). That function inputs two images and it outputs the degree of difference between the two images.
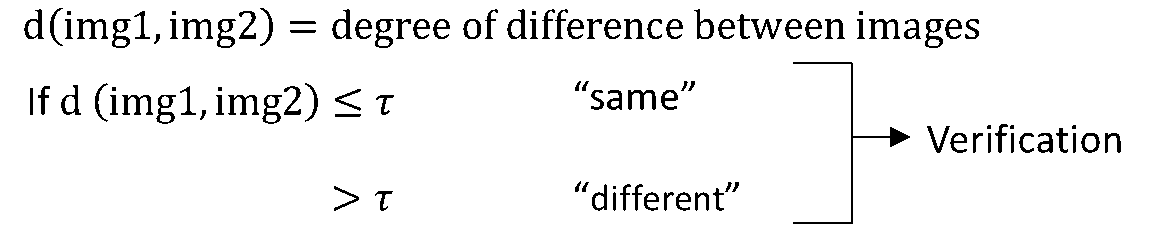
Learning a “similarity” function
If we have two images of the same person, we want a value of \(d \) to be a small number. In contrast, if the images are of two different people we want the function to be a large number. During recognition time, if the degree of difference between them is less than some threshold called \(\tau \), which is a hyper-parameter, then we would predict that these two pictures are of the same person. On the other hand, if it is greater than \(\tau \), we would predict that these are different persons. This is how we address the face verification problem.
To use this idea for a recognition task, for a new picture we would use a function \(d \) to compare two images. It is possible that the output is a very large number. Let’s say \(10 \) for this example. Next, we then compare this picture with the second image in our database. Because these two are the same person, our output will be a very small number. Then, we do this for other images in our database, and based on this we will figure out that this is actually that person.
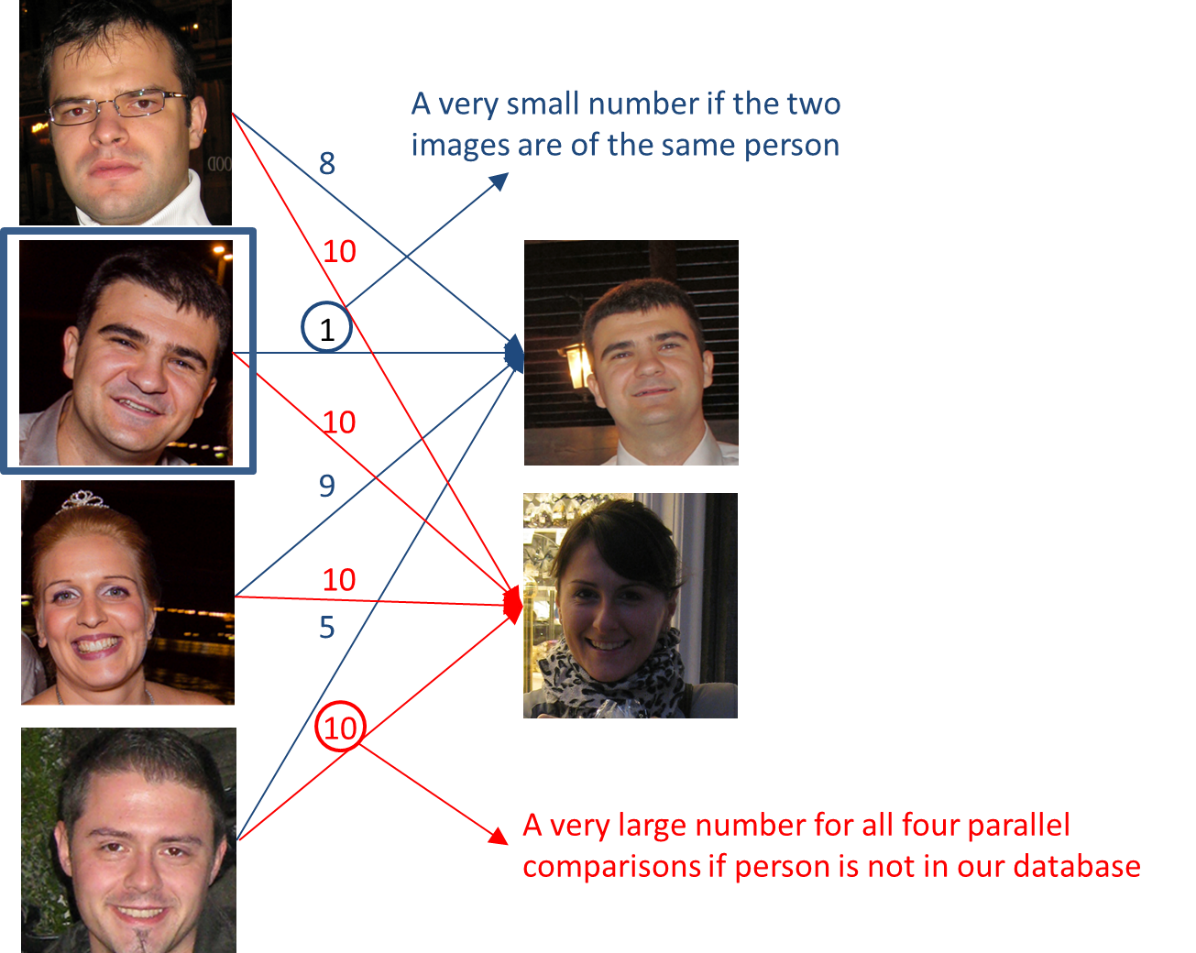
An example of how we get function \(d \)
In contrast, if someone who is not in our database shows up as well, we will use the function \(d \) to make all of these parallel comparisons. Hopefully, a function \(d \) will output a very large number for all four parallel comparisons, and then, we say that this is not a person from the database. A great advantage of a \(d\) function is that a new person may join the database easily, without the need to retrain the neural network.
In the next post, let’s take a look at how we can actually train our network and learn this function \(d \).