#013 Machine Learning – K-means clustering
Highlights: Hello and welcome. In the previous posts, we talked in great detail about supervised learning. In this post, we’ll talk about unsupervised learning. In particular, you’ll learn about clustering algorithms, which is a way of grouping data into clusters. In particular, we will talk about one of the most popular clustering algorithms called k-means clustering.
Tutorial overview:
1. What is clustering?
A clustering algorithm looks at a number of data points and automatically finds data points that are related or similar to each other. Let’s take a look at what that means.
Let’s take a look at the following image.

On the left side, we can see a graph of supervised learning for binary classification. Given a dataset with features \(x_{1} \) and \(x_{2} \) with supervised learning, we had a training set with both the input features \(x \) as well as the labels \(y \). We could plot a dataset and fit a logistic regression algorithm or a neural network to learn a decision boundary. In contrast, in unsupervised learning, you are given a dataset illustrated in the graph on the right with just \(x \), the target labels \(y \). That’s why when we plot a dataset, it looks like this, with just dots. Because we don’t have target labels we’re not able to tell the algorithm what is the “right answer” that we wanted to predict. Instead, we’re going to ask the algorithm to find some interesting structure in this data.
The first unsupervised learning algorithm that we are going to talk about is called a clustering algorithm. This algorithm looks at the dataset and tries to see if it can be grouped into clusters, meaning groups of points that are similar to each other. A clustering algorithm, in this case, might find that this dataset comprises data from two clusters shown here.
Here are some applications of clustering:
- DNA analysis
- Grouping similar news
- Market segmentation
- Astronomical data analysis
Clustering today is used for all of these applications and many more. Now, let’s take a look at the most commonly used clustering algorithm called the k-means algorithm, and let’s take a look at how it works.
2. K-means algorithm
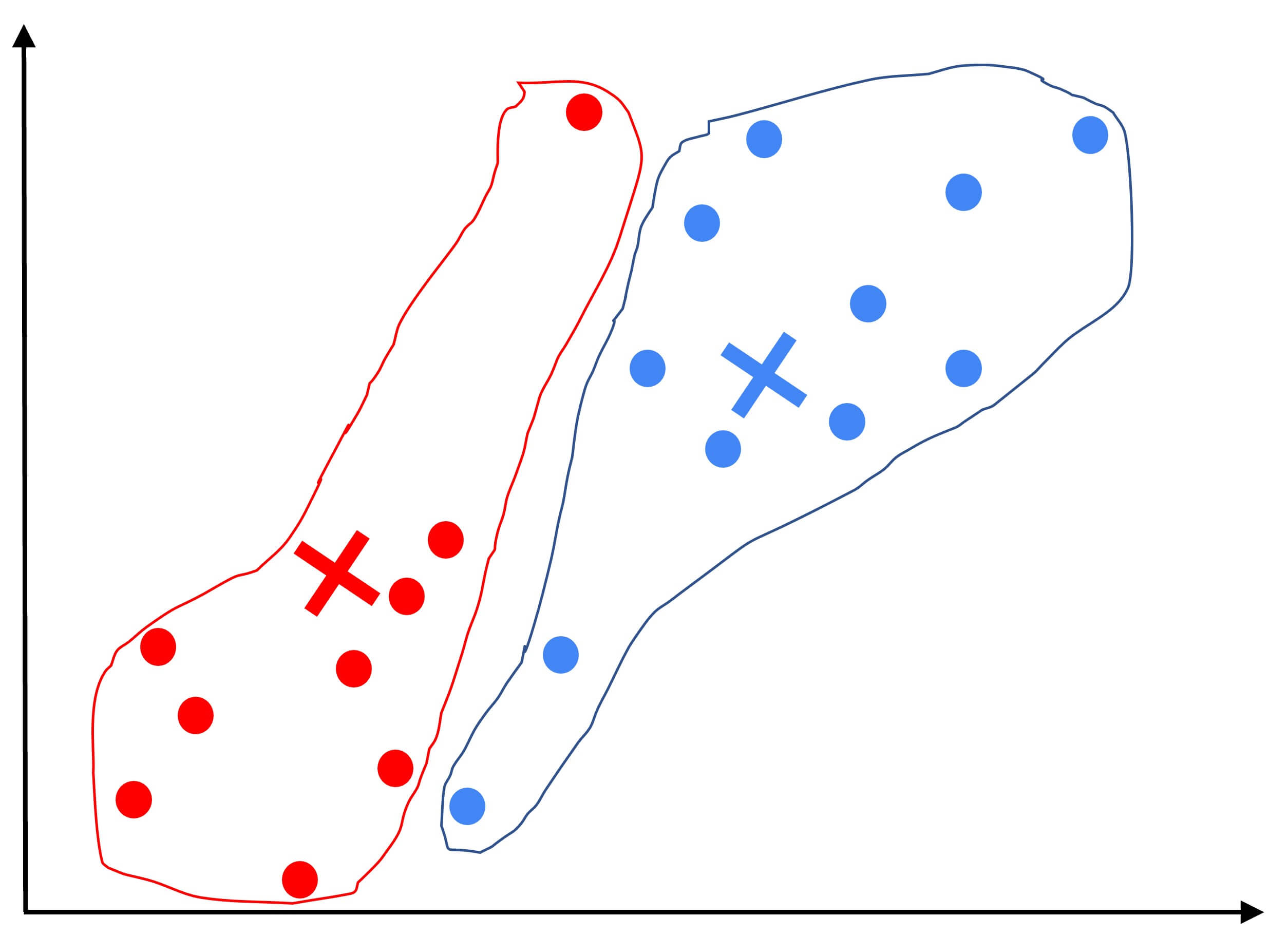
Let’s start with an example. Here we’ve plotted a data set with 20 unlabeled training examples. So, in the following image, we can see 20 points. What we like to do is run K-means on this data set. The first thing that the K-means algorithm does is it takes a random guess at where might be the centers of the two clusters.

In the example above these randomly picked cluster centers are shown as red and blue crosses. This is just a random initial guess and they’re not particularly good guesses. One important thing to remember is that K-means will repeatedly do two different things. The first is to assign points to cluster centroids, and the second is to move cluster centroids. Let’s take a look at what this means. The first step is to go through each of these 30 points and look at whether it is closer to the red cross or to the blue cross. Then, it will assign each of these points to whichever of the cluster centroids it is closer to.

So, that was the first of the two things that K-means does -assign points to clusters of centroids. The second of the two steps that K-means does is, to look at all of the red points and take an average of them. And it will move the red cross to whatever is the average location of the red dots. Then it will do the same thing for all the blue dots.

So now we have a new location for the blue cluster centroid and red cluster centroid. Now, the algorithm will repeat the process. It will go through all of the 30 training examples again and check for every one of them, whether it’s closer to the red or the blue cluster centroid for the new locations.

If you do that, you see that some points have changed color. That is because the given point is now closer to the other cluster centroid. Then we just repeat the second part of K-means again. And it turns out that if you were to keep on repeating these two steps, that is look at each point and assign it to the nearest cluster centroid and then also move each cluster centroid to the mean of all the points with the same color. If you keep on doing those two steps, you find that there are no more changes to the colors of the points or to the locations of the clusters of centroids. This means that at this point the K-means clustering algorithm has converged.

Because applying those two steps over and over, results in no further changes to either the assignment to point to the centroids or the location of the cluster centroids. In this example, it looks like K-means has done a pretty good job.
So now you’ve seen an illustration of how K-means works. It searches for a predetermined number of clusters within an unlabeled multidimensional dataset. It accomplishes this using a simple conception of what the optimal clustering looks like:
- The “cluster center” is the arithmetic mean of all the points belonging to the cluster.
- Each point is closer to its own cluster center than to other cluster centers.
These two assumptions are the basis of the k-means model. Now let’s take a look at how we can implement k means in Python. We will use a simple dataset and see the k-means result.
3. K-means algorithm in Python
First, let’s import the necessary libraries.
import matplotlib.pyplot as plt
import seaborn as sns; sns.set() # for plot styling
import numpy as npLet’s generate a two-dimensional dataset containing four distinct blobs.
from sklearn.datasets import make_blobs
X, y_true = make_blobs(n_samples=300, centers=4,
cluster_std=0.60, random_state=0)
plt.scatter(X[:, 0], X[:, 1], s=50);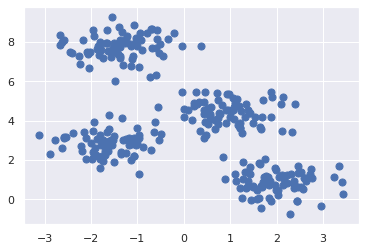
In the image above, it is relatively easy to spot the four clusters. The k-means algorithm will do this automatically. First, we will import the k-means algorithm from the sklearn library. Then we need to choose the number of clusters
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=4)
kmeans.fit(X)
y_kmeans = kmeans.predict(X)Next, let’s visualize the results by plotting the data that are now colored by 4 labels. We will also plot the cluster centers as determined by the k-means estimator.
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap='viridis')
centers = kmeans.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='black', s=200, alpha=0.5);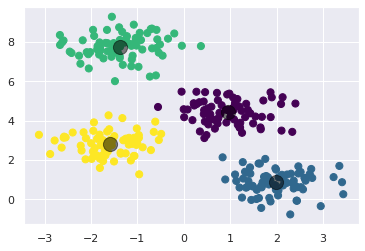
As you can see, the k-means algorithm in this simple case, assigns the points to clusters very similarly to how we might assign them by eye.
Summary
In this post, we talked about K-means clustering. It is one of the simplest and popular unsupervised machine learning algorithms. We learned how K-means algorithm starts with a first group of randomly selected centroids, which are used as the beginning points for every cluster, and how it select and optimizes the positions of the cluster centroids. Finnaly, we also learned how to perform K-means clustering i Python.