#007 Machine Learning – Activation functions in Neural Networks

Highlights: In the previous post we learned to build a simple Neural Network. Recall that we’ve been using the sigmoid activation function in all the nodes in the hidden layers and in the output layer. The reason for that is we were building up neural networks using Logistic regression algorithms. However, if we apply other types of activation functions, our neural network can become much more powerful. In this post, we are going to explore different types of activation functions and we will learn how to choose the activation function for different neurons in our neural network. So, let’s begin with our post.
Tutorial overview:
- Alternatives to the sigmoid activation function
- Types of Neural Networks Activation Functions
- How to choose the activation function?
1. What is the activation function?
Before we dig deeper into different types of activation functions let’s see what exactly the activation function is.
An Activation Function decides whether a neuron should be activated or not. This means that it will decide whether the neuron’s input to the network is important or not in the process of prediction using simpler mathematical operations.
The primary role of the Activation Function is to transform the summed weighted input from the node into an output value to be fed to the next hidden layer or as output.
In the previous post, we used the sigmoid activation function for our logistic regression model. However, there are different activation functions that we can use as an alternative to the sigmoid activation function. That can make your neural networks work even much better.
1. Alternatives to the sigmoid activation function
To better understand this let’s take a look at the demand prediction example where the input to the network are features like price, shipping cost, marketing, and material and we want to predict if something is highly affordable.

In this example, we assume that awareness is a binary feature. Therefore, either people are aware or they are not. But it seems like the degree to which possible buyers are aware of the t-shirt you’re selling may not be binary. They can be a little bit aware, somewhat aware, extremely aware or they could have gone completely viral. So, rather than modeling awareness as a binary number 0, or 1, we can try to estimate the probability of awareness. For example, maybe awareness should be any non-negative number because there can be any non-negative value of awareness going from 0 up to very very large numbers.
Now, let’s take a look at the following example.

So previously we had used this function \(g(z) \)to calculate the activation of the hidden unit estimating awareness where \(g \) was the sigmoid function and just goes between 0 and 1. Now, what if we want to allow that estimated awareness potentially take much larger positive values? In that case, we can instead swap in a different activation function. It turns out that a very common choice of activation function in neural networks is this ReLU function that you can see in the graph on the right. We can see that here if \(z<0 \) then \(g(z) =0 \) to the left of 0. However, to the right of 0, we can see this straight line of 45°. So, when \(z\geq0 \), \(g(z) =z \). The mathematical equation for this is \(g(z)= max(0, z) \). It is easy to see that \(max(0, z) \) results in this curve that you can see in the graph on the right side.
Now, let’s take a look at different types of activation functions that we can use in the Nural Networks.
2. Types of Neural Networks Activation Functions
The Activation Functions can be divided into 2 types:
- Linear Activation Function
- Non-linear Activation Functions
First, let’s take a look at the linear activation functions.
Linear Activation Function
The linear activation function, also known as “no activation,” or “identity function”, is a function where the activation is proportional to the input. The function doesn’t do anything to the weighted sum of the input, it simply spits out the value it was given.
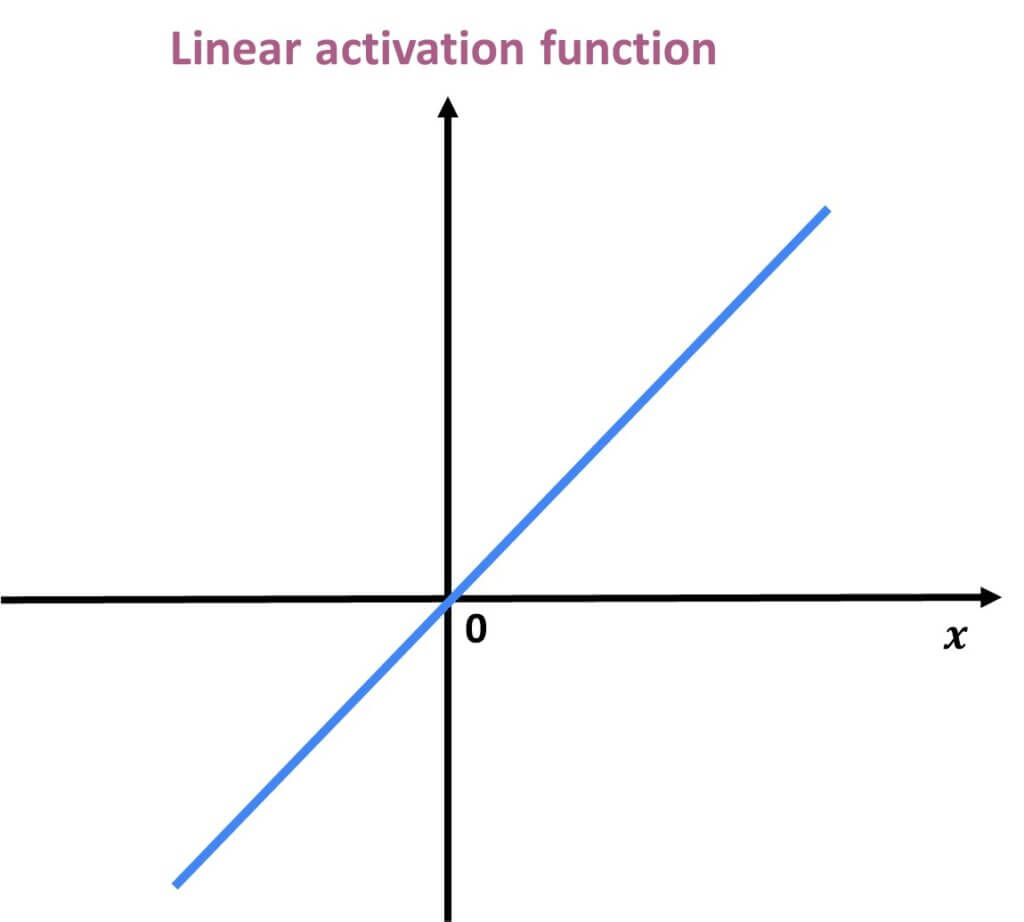
Mathematically, this linear function can be represented with the following equation:
$$ f(x) = x $$
The linear activation function shown above is simply a linear regression model.
Because of its limited power, this does not allow the model to create complex mappings between the network’s inputs and outputs.
In neural networks, this type of activation function is rarely used. The most common type of activation function is the non-linear function. So, let’s go over the most popular neural network non-linear activation functions and their characteristics.
Binary Step Function
The binary step function depends on a threshold value that decides whether a neuron should be activated or not. The input fed to this activation function is compared to a certain threshold. If the input is greater than the threshold, then the neuron is activated. On the other hand, if the input is smaller than the thresold, the neuron is deactivated, meaning that its output is not passed on to the next hidden layer.
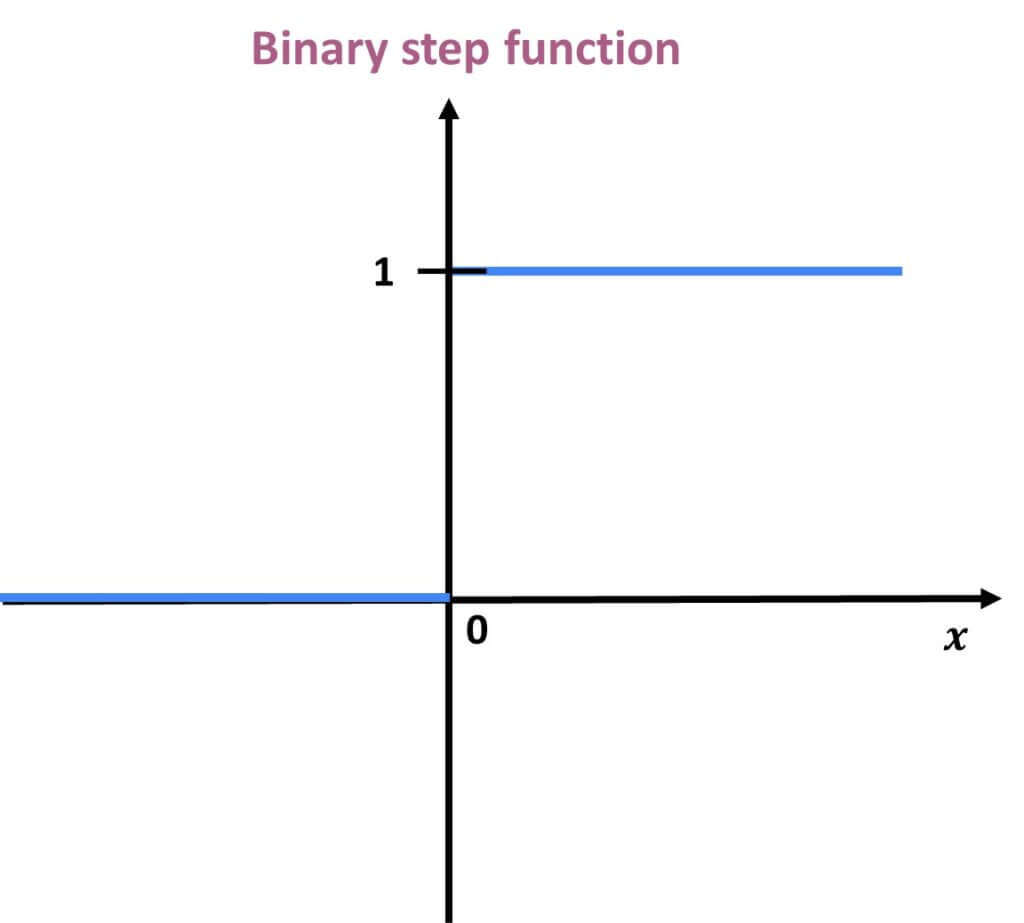
Mathematically it can be represented with the following formula:
$$ f(x)= \left\{\begin{matrix}0 for x<0 \\ 1 for x\geq 0\end{matrix}\right. $$
The limitations of the binary step function are:
- It cannot provide multi-value outputs (for example, it cannot be used for multi-class classification problems).
- The gradient of the step function is zero, which causes a hindrance in the backpropagation process
Sigmoid Activation Function
This function is already familiar to us because we used it in several examples. It takes any real value as input and outputs values in the range of 0 to 1.

This is the formula for the sigmoid function.
$$ f(x)= \frac{1}{1+e^{-x}} $$
The sigmoid activation function is one of the most widely used functions. Here are some of the reasons:
- It is commonly used for models where we have to predict the probability as an output. Since the probability of anything exists only between the range of 0 and 1, sigmoid is the right choice because of its range.
- The function is differentiable and provides a smooth gradient. It prevents jumps in output values.
Tanh Function – Hyperbolic Tangent
Tanh function is very similar to the sigmoid activation function and even has the same S-shape. The only difference is that the output here ranges from -1 to 1. In Tanh, the larger the input (more positive), the closer the output value will be to 1.0, whereas the smaller the input (more negative), the closer the output will be to -1.0.
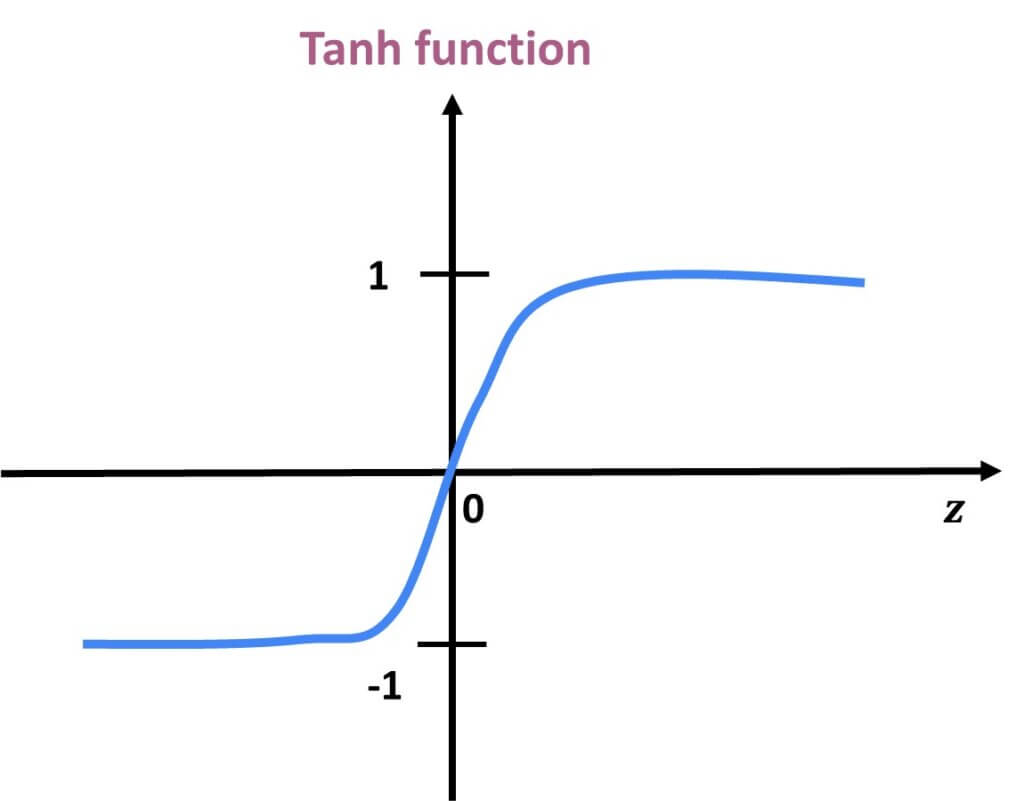
The function can be represented as:
$$ f(x)= \frac{(e^{x}-e^{-x})}{(e^{x}+ e^{-x})} $$
Advantages of using this activation function are:
- The output of the tanh activation function is Zero centered. That means that we can easily map the output values as strongly negative, neutral, or strongly positive.
- Usually used in hidden layers of a neural network as its values lie between -1 to 1. Therefore, the mean for the hidden layer comes out to be 0 or very close to it. It helps in centering the data and makes learning for the next layer much easier.
ReLU Function
ReLU stands for Rectified Linear Unit. Although it gives an impression of a linear function, ReLU has a derivative function and allows for backpropagation while simultaneously making it computationally efficient.
The main catch here is that the ReLU function does not activate all the neurons at the same time. The neurons will only be deactivated if the output of the linear transformation is less than 0.
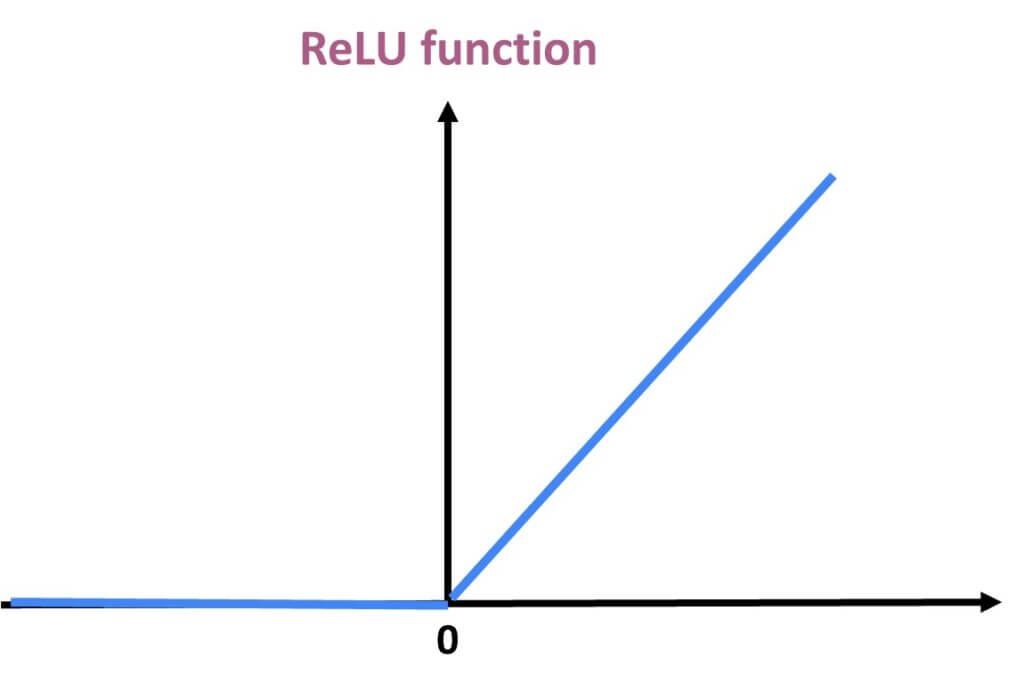
This is the formula for the ReLU function:
$$ f(x)= max(0,x) $$
The advantages of using ReLU as an activation function are as follows:
- Since only a certain number of neurons are activated, the ReLU function is far more computationally efficient when compared to the sigmoid and tanh functions.
- ReLU accelerates the convergence of gradient descent towards the global minimum of the loss function due to its linear, non-saturating property.
Leaky ReLU Function
Leaky ReLU is an improved version of the ReLU activation function which is used to solve the biggest ReLU problem which is the small positive slope in the negative area.
The advantages of Leaky ReLU are the same as that of ReLU, in addition to the fact that it does enable backpropagation, even for negative input values.
By making this minor modification for negative input values, the gradient of the left side of the graph comes out to be a non-zero value. Therefore, we would no longer encounter dead neurons in that region.
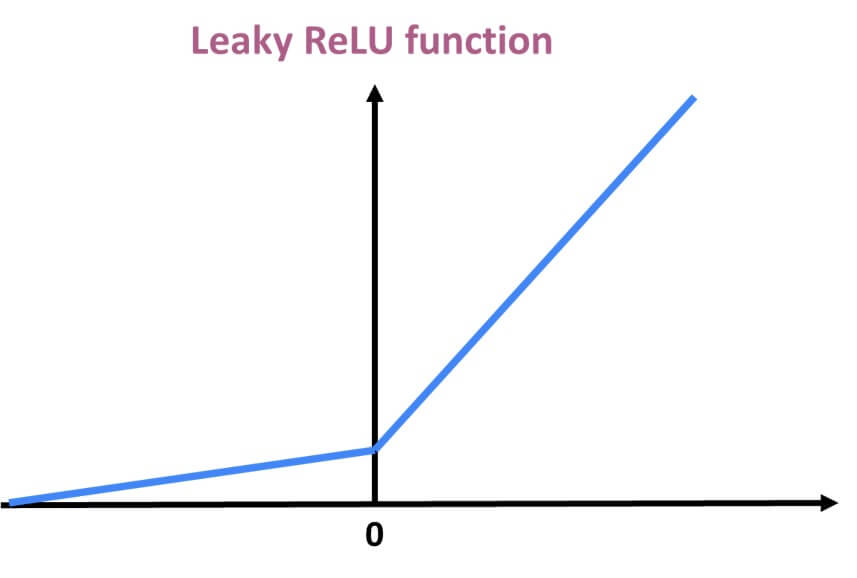
Mathematically it can be represented as:
$$ f(x)= max(0.1x,x) $$
With these activation functions, you’ll be able to build a rich variety of powerful neural networks. However, when building a neural network, do you want to use the sigmoid activation function for each neuron? Or maybe the ReLU activation function? Or a linear activation function? The question is how do you choose between these different activation functions? Let’s take a look at that problem.
3. How to choose the activation function?
Let’s take a look at how you can choose the activation function for different neurons in your neural network. We’ll start with some guidelines for how to choose it for the output layer. It turns out that depending on what the target label or the ground truth label \(y \) is, there will be one fairly natural choice for the activation function for the output layer. Specifically, if you are working on a classification problem where y is either zero or one, so a binary classification problem, then the sigmoid activation function will almost always be the most natural choice because then the neural network learns to predict the probability that \(y = 1 \), just like we had for logistic regression. Therefore, if you’re working on a binary classification problem, use sigmoid at the output layer. Alternatively, if you’re solving a regression problem, then you might choose a different activation function. For example, if you are trying to predict how tomorrow’s stock price will change compared to today’s stock price. Well, it can go up or down, and so in this case \(y \) would be a number that can be either positive or negative. In that case, you should use the linear activation function. Finally, if y can only take on non-negative values, such as if you’re predicting the price of a house, that can never be negative, then the most natural choice will be the ReLU activation function. The reason for that is that this activation function only takes non-negative values, either zero or positive values.
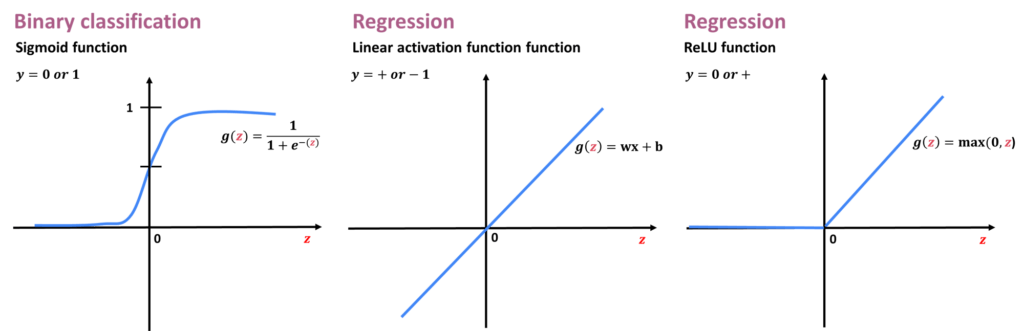
Now, what about the hidden layers of a neural network? It turns out that the ReLU activation function is by far the most common choice in how neural networks are trained by many practitioners today. Even though we had initially described neural networks using the sigmoid activation function, and in fact, in the early history of the development of neural networks, people use sigmoid activation functions in many places, the field has evolved to use ReLU much more often and sigmoids hardly ever. Well, the one exception is that you do use a sigmoid activation function in the output layer if you have a binary classification problem. So why is that? Well, there are a few reasons. First, if you compare the ReLU and the sigmoid activation functions, the ReLU is a bit faster to compute because it just requires computing \(max(0, z) \) whereas the sigmoid requires taking exponentiation and then an inverse. So, it’s a little bit less efficient. The second reason which turns out to be even more important is that the ReLU function goes flat only in one part of the graph whereas the sigmoid activation function, goes flat in two places. If you’re using gradient descent to train a neural network, then when you have a function that is fat in a lot of places, gradient descents would be really slow. Researchers have found that using the ReLU activation function can cause your neural network to learn a bit faster as well. That is why for most practitioners the ReLU activation function has become by far the most common choice for the hidden layer in the neural network.
There is one more question that we need to answer. Why do we even need activation functions at all? Why don’t we just use the linear activation function or use no activation function anywhere? It turns out this does not work at all. So, why do neural networks need activation functions? Well, imagine what would happen if we were to use a linear activation function for all of the nodes in one large neural network. It turns out that this big neural network will become no different than just linear regression. That is why activation functions are so important for getting your neural networks to work.
Summary
Today we learned that during the process of building a neural network, one of the choices you get to make is what activation function to use in the hidden layer as well as at the output layer of the network. We learned about the most common activation functions and which activation function we need to choose for different types of neural networks.
So, that is it for this post. See you, soon!