#002 Advanced Computer Vision – Motion Estimation With Optical Flow

Highlights: Techniques like Object Detection have enabled computers of today to detect object instances easily. However, tracking the motion of objects such as vehicles across all frames of a video, estimating their velocity, and predicting their motion requires an efficient method such as Optical Flow. In our previous posts, we provided a detailed explanation about two of the most common Optical Flow methods – the Lucas Kanade method and the Horn & Schunck method.
In this tutorial post, we will go through the fundamentals of Optical Flow and study some of the advanced algorithms used in calculating Optical Flow. So let us begin!
Tutorial Overview:
- Fundamentals Of Optical Flow
- Optical Flow Using Python: Code
- Advanced Optical Flow Algorithms-Flow Net
1. Fundamentals Of Optical Flow
An important piece of information that common object detection techniques miss out, is the relationship between objects in two consecutive frames. Optical Flow tackles this problem by calculating the relative movement between the camera and the object.
What Is Optical Flow?
Optical Flow can be defined as a pattern of motion of pixels between two consecutive frames. The motion can be caused either by the movement of a scene or by the movement of the camera.
The main idea behind Optical Flow is to estimate the object’s displacement vector caused by its motion or camera movements method components. Basically, our goal is to find the displacement of a sparse feature set or all image pixels to calculate their motion vectors[1].
If we were to represent the problem of Optical Flow pictorially, it would be something like this:
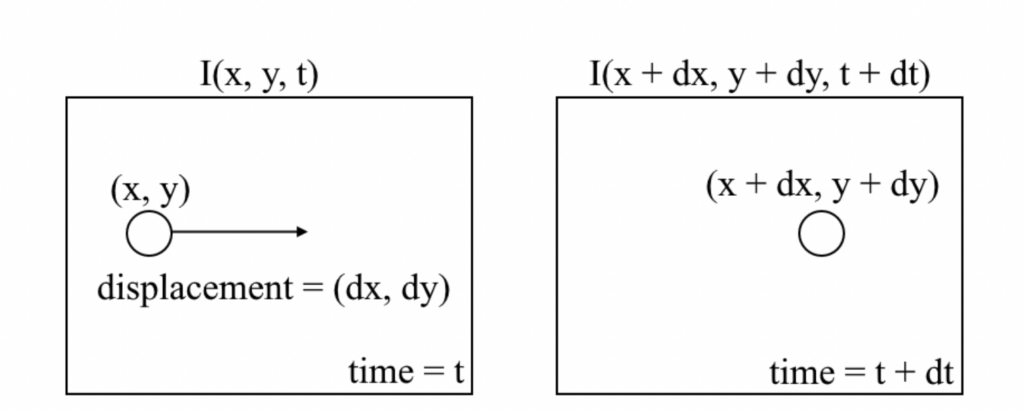
In the image above, \(I\) is the image intensity represented using 3 dimensions.
A vital ingredient in several computer vision and machine learning fields such as object tracking, object recognition, movement detection, and robot navigation, Optical Flow works by describing a dense vector field. In this field, each pixel is assigned a separate displacement vector that helps in estimating the direction and speed of each pixel of the moving object, in each frame of the input video sequence.
Let us quickly revise the types of Optical Flow.
Types Of Optical Flow
There are essentially two types of Optical Flow:
- Sparse Optical Flow
- Dense Optical Flow
While Sparse Optical Flow processes the flow vectors of only the most interesting pixels from the entire image of a frame, the Dense Optical Flow processes the flow vectors of all pixels in the entire frame. Naturally, Dense Optical Flow is more accurate than Sparse Optical Flow, however, it is quite slow and also, computationally expensive.
While the problem of Optical Flow has historically been an optimization problem, Deep Learning-based approaches have shown promising results. Moving ahead, we shall see how we can use Deep Learning approaches to estimate Optical Flow accurately and efficiently, starting with a Python code implementation.
2. Optical Flow Using Python: Code
Now, let’s take a look at one easy way to calculate optical flow using Python
The first step is to import the necessary libraries.
import cv2
import numpy as np
import matplotlib.pyplot as plt
from google.colab.patches import cv2_imshowNext, let’s create two images. We will call the first image a base image and the second will be called a template image. Our goal is to create a video where the template image will change its position for each video frame.
To accomplish this goal first we are going to use a function np.arange() to create two variables – delta_x and delta_y. These variables will determine by how many pixels our image will move in the \(x \) and \(y \) direction.
delta_x = np.arange(50)
print(delta_x)[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49]
delta_y = np.arange(0,100,2)
print(delta_y)[ 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 52 54 56 58 60 62 64 66 68 70 72 74 76 78 80 82 84 86 88 90 92 94 96 98]
Now, let’s create our images. We will create the base image using the function np.zeros.(). So it will be a black image with dimensions \(256\times256 \) pixels. For the template image, we can use any random picture. Do note that it needs to be smaller than the base image. So, we will resize it to the dimensions of \(60\times60 \) pixels.
img = np.zeros((256,256,3),np.uint8)
template = cv2.imread("1.jpg")
resized = cv2.resize(template, (60, 60))
Now, with the following code, we will place the template image at the top left corner of the base image. We will define the height and width of the template image and coordinates of the top left corner x0 and y0. Then, we will simply add these coordinates to the height and width. Finally, using indexing we can place the template image in the top left corner of the base image.
h = resized.shape[0]
w = resized.shape[1]
x0 = 10
y0 = 10
x1 = x0 + w
y1 = y0 +h
img[y0:y1, x0:x1,:] = resizedSo, we basically created the first frame of our video. Now we are ready to create other frames and apply optical flow. Let’s see how we can do that.
First, let’s define the FourCC codec and write our output. After that, we will create an empty list where we will store the frames of the video. Then, we will create a for loop and at each iteration, we will add delta_x and delta_y vectors. Finally, we will store our frames in the list.
fourcc = cv2.VideoWriter_fourcc('M', 'P', '4', 'V')
out = cv2.VideoWriter('output.mp4', fourcc, 10, (256,256))
list_img=[]
for i in range(len(delta_x)):
img = np.zeros((256,256,3),np.uint8)
img[y0 + delta_y[i]: y1 + delta_y[i], x0 + delta_x[i]:x1 + delta_x[i],:] = resized
#img[y0+delta_y[i]:y0+h + delta_y[i], x0+delta_x[i]:x0+w +delta_x[i],:] = resized
list_img.append(img)Next, we will iterate through all frames. It is important to subtract one from the length of the list because the optical flow is calculated between two consecutive frames. Therefore, at the end of the process, we will end up with 49 frames instead of 50. The next step is to create two consecutive frames. To visualize our results we are going to use the HSV color model.
N = len(list_img) - 1
for i in range (N):
prev = list_img[i]
curr = list_img[i+1]
hsv = np.zeros_like(prev)
hsv[..., 1] = 255HSV stands for Hue, Saturation, Value and it is an alternative representation of the RGB color model. Here the hue and the value are dependent on apparent motion. Hue is determined by the angle of the optical flow vector and value is determined by the magnitude of the optical flow vector. For example, an object with a high upward velocity will be bright green, and an object with a high downward velocity will be bright blue.
After we convert our images into grayscale, we are ready to calculate Optical flow. For that, we will use the function cv2.calcOpticalFlowFarneback().
prevgray = cv2.cvtColor(prev, cv2.COLOR_BGR2GRAY)
gray = cv2.cvtColor(curr, cv2.COLOR_BGR2GRAY)
flow = cv2.calcOpticalFlowFarneback(prevgray,gray,None,0.5, 1, 25, 5, 11, 1.1, cv2.OPTFLOW_FARNEBACK_GAUSSIAN)To better understand how optical flow works let’s plot our image movement along the \(x \) and \(y \) axis. To do that, we need to create the center of the template image. Also, we will crop the flow array in order to create a rectangular shape of the Optical flow.

h1 = 60
w1 = 60
curent_center = (y0 + h1//2, x0 + w1//2)
rectangle = flow[curent_center[0]-15 : curent_center[0]+15, curent_center[1]-15 : curent_center[1]+15]Next, we are going to create variables x and y from a 2D channel array of flow vectors. Here, channel 0 is the movement along the \(x \) axis, and channel 1 is the movement along the \(y \) axis. Then we will reshape x and y matrices in order to get the one-dimensional vector. After that, we will calculate the mean of the x and y vector. Then, we will encode the result into HSV format for visualization purposes, and write an image where the color model is changed from BGR to HSV using the following code.
x = rectangle[:,:,0]
y = rectangle[:,:,1]
x_vec = x.reshape(-1,1)
y_vec = y.reshape(-1,1)
mean_x = np.mean(x_ves)
mean_y = np.mean(y_vec)
mag, ang = cv2.cartToPolar(flow[..., 0], flow[..., 1])
# Use Hue and Value to encode the Optical Flow
hsv[..., 0] = ang * 180 / np.pi / 2
hsv[..., 2] = cv2.normalize(mag, None, 0, 255, cv2.NORM_MINMAX)
bgr = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR)
out.write(bgr)Finally, we are going to update the position of the next frame in the video by adding the mean_x and mean_y to the x0 and y0.
x0 += int(np.round(mean_x))
y0 += int(np.round(mean_y))
out.release()To better understand the movement along the \(x \) and \(y \) axis, let’s plot x_vec and y_vec vectors.
plt.ticklabel_format(useOffset=False)
plt.hist(x_vec, bins = 100);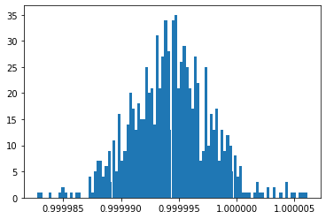
plt.ticklabel_format(useOffset=False)
plt.hist(y_vec, bins = 100);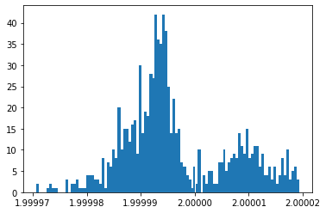
As you can see the movement along the \(x \) axis is close to 1, and the movement along the \(y \) axis is close to 2 for each frame in the video.
3. Advanced Optical Flow Algorithms
Deep Learning-based methods for computing Optical Flow utilize large amounts of training data. Imagine labeling the video footage to accurately figure out the exact motion of each and every point on the image, and that too with sub-pixel accuracy. In order to solve this gigantic training data issue, computer graphics have been proposed to simulate realistic worlds wherein the motion of every point on an image in a video sequence is known beforehand. Methods such as MPI-Sintel and Flying Chairs are popular Optical Flow methods in this category.
As you must have realized by now, deep neural networks are quite popular these days for solving Optical Flow problems. Many variants have been used by researchers such as FlowNet, SPyNet, PWC-Net, among others.
Now, let’s go into the details of the FlowNet method for Optical Flow Estimation.
FlowNet
The first CNN approach to predict Optical Flow, introduced in 2015, was the FlowNet Architecture. Have a look at the pictorial representation of FlowNet below.

Backed by promising results in classification, depth estimation, and semantic segmentation, two types of FlowNet architectures were introduced:
- FlowNetS or FlowNetSimple: Takes two consecutive frames as input
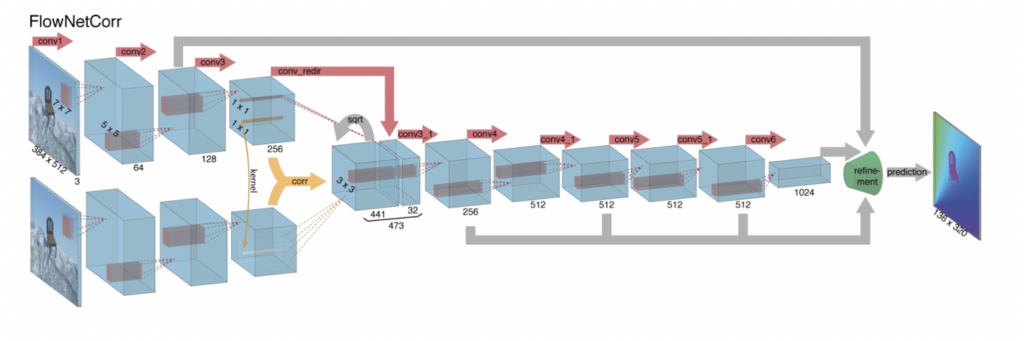
- FlowNetCorr: Takes only one frame as input
Both these architectures consist of an encoder and a decoder, wherein the encoder extracts features from two consecutive images and the decoder upscales the encoder feature maps to get the final Optical Flow prediction.
The main difference between FlowNetS and FlowNetCorr is the Correlation Layer present in FlowNetCorr which is computed in the same way as the convolutional layer. However, there are no trainable kernels in FlowNetCorr due to which the correlation layer performs multiplicative patch comparisons between two feature maps without any weights.
Have a look at the architectures of FlowNetSimple and FlowNetCorr respectively.
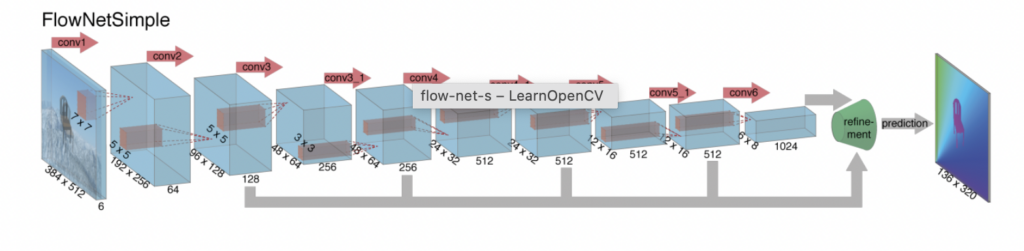
In the FlowNet architecture, the final prediction is nothing but an upscaled small-sized Optical Flow. This means that even a prediction of a small size can contribute more to the total loss than a prediction of a large size. Here is the mathematical expression to represent the loss function:
$$ L=\left|V_{g t}-V_{\text {calc }}\right|_{1}=\sqrt{\left(\Delta x_{g t}-\Delta x_{c a l c}\right)^{2}+\left(\Delta y_{g t}-\Delta y_{c a l c}\right)^{2}} $$
Here, prediction is represented as \(V_{\text {pred }}=\left(\Delta x_{\text {pred }}, \Delta y_{\text {pred }}\right) \) and the ground truth data is written as \(V_{g t}=\left(\Delta x_{g t}, \Delta y_{g t}\right) \).
FlowNet is one of the many advanced Optical Flow algorithms commonly used by researchers to solve the Optical Flow problem. There are many applications of Optical Flow such as compression, slow-motion, stabilization, tracking, and action recognition, among others. Deep Learning-based approaches give quite a boost to the quality of models designed for estimating Optical Flow.
Motion Estimation With Optical Flow
- Object detection methods miss out on the relationship between objects in two consecutive frames
- Optical Flow is the motion of pixels between two frames caused by scene or camera
- Sparse Optical Flow and Dense Optical Flow are two types of Optical Flow
- Deep Learning-based approaches are getting popular these days for solving the Optical Flow problem, but they require large amount of training data
- FlowNet is a popular advanced algorithm that is an efficient solution for the Optical Flow problem
- There are two types of FlowNet architectures: FlowNetSimple and FlowNetCorr
Summary
Well, folks, that’s it for this post! We hope you are enjoying our content, especially the ongoing Optical Flow posts. Finding solutions and devising models for such problems is quite popular these days among top researchers. Through our tutorials, we want to empower you to build your own models and advance the field of AI, Machine Learning, and Computer Vision. For more content, follow us on YouTube, we have some exciting content coming up. We’ll see you soon with our next post. Cheers 🙂
References:
[1] LearnOpenCVRAFT: Optical Flow estimation using Deep Learning