# 005 RNN – Tackling Vanishing Gradients with GRU and LSTM

Highlights: Recurrent Neural Networks (RNN) are sequence models that are a modern, more advanced alternative to traditional Neural Networks. Right from Speech Recognition to Natural Language Processing to Music Generation, RNNs have continued to play a transformative role in handling sequential datasets.
In this blog post, we will carry forward our knowledge from building Language Models to addressing issues that arise from those language models, such as Long-term Dependencies. These can also be termed as Vanishing Gradient problems and we will see how we can solve them by modifying our basic RNN architecture to GRUs (Gated Recurrent Units) and LSTM (Long Short-Term Memory) Units.
Tutorial Overview:
- Understanding Long-term Dependencies
- Vanishing Gradients
- Exploding Gradients
- Gated Recurrent Unit (GRU)
- GRU Architecture
- Forward Propagation in GRU
- Solving the Vanishing Gradient Problem Using GRU
- Simplified Notation For GRU
- Other Notations For GRU
- Long Short-Term Memory (LSTM) Unit
- Notation And Architecture of LSTM Units
- Variations of LSTM
1. Understanding Long-term Dependencies
In our previous posts, we learned how Recurrent Neural Networks can be applied in problems like Name Entity Recognition and Natural Language Processing. We also learned how to build and train Language Models using basic RNNs. We went further ahead to understand how to sample novel sequences from our trained Language Models and generate Shakespeare-like text or any kind of text that we desire. If you recall, our RNN architecture looked something like this:
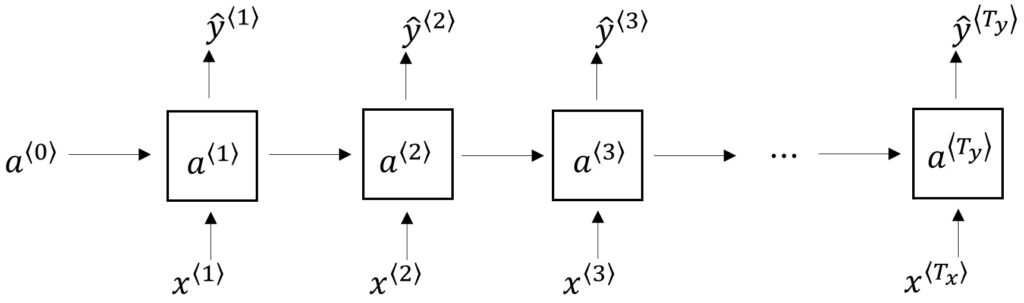
However, with due course of time, we also realized that there are many dependencies, especially long-term dependencies, when it comes to tackling the English Language in those Language Models made using the basic RNN algorithm.
Let’s take another Language Modelling example to fully understand what we mean by long-term dependencies.

If you carefully observe the two sentences above, you will notice how the word “Dog” at the very beginning of the sentence influences the word “has” which is at the very end. If we change the singular word to a plural word “Dogs”, there is a direct effect on the word “have” which is very far from the influencer word “Dogs”.
Now, the sentence in between can get longer than our liking and is not really under our control. Something like, say, “The dog, which ran out of the door and sat on the neighbor’s porch for three hours and roamed the street for a couple of hours more, has come back.” So, for a word that’s almost at the end of a very long sentence to be influenced by a word which is almost at the beginning of that sentence, is what we call a “long-term dependency”.
The basic Recurrent Neural Networks that we have seen so far are not very good at handling such long-term dependencies, mainly due to the Vanishing Gradient Problem.
Vanishing Gradients
Let’s understand vanishing gradients in detail. Have a look at this very deep neural network algorithm.

To carry out forward propagation in this 100+ layer deep neural network and then backpropagate the output \(\hat{y}\) to affect the computations in earlier layers, is extremely difficult. The gradient from this output and the errors associated will almost vanish by the time they reach the earlier layers during backpropagation.
Essentially, what we are demanding from our neural network is to memorize that the noun used at the beginning of the sentence, i.e., “Dog” or “Dogs” is singular or plural. Only then can it generate either “has” or “have” later in the sequence. Depending on the length of the middle portion of the sequence, which as we saw can be arbitrarily long, the neural network would have to memorize the singular/plural noun for a very long time.
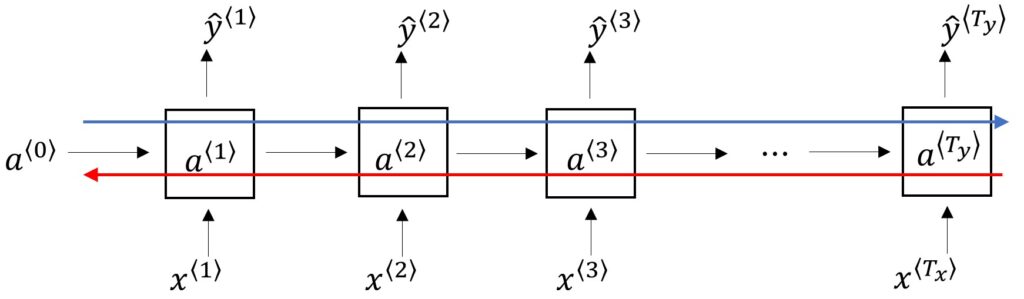
This brings us to an important observation of basic RNN models. In such basic models, the output \(\hat{y}^{\left \langle 1 \right \rangle} \) is mainly influenced by inputs closer to it. Similarly, it is hard for the output \(\hat{y}\) to be influenced by an input at the start of the sequence, say, \(\hat{y}^{\left \langle 1 \right \rangle} \). Such long backpropagation is quite tedious to perform for the neural network. And this is the main weakness of the basic Recurrent Neural Network (RNN) algorithm.
To model an algorithm that is good at capturing long-term dependencies, we need to focus on handling the vanishing gradient problem, as we will do in the upcoming sections of this blog post. Along with vanishing gradients, there are other issues with basic RNN models such as “exploding gradients” but those are easier to handle than vanishing gradients. Let’s see how.
Exploding Gradients
When we are backpropagating through time in our RNN model, the gradient can not only decrease exponentially (as we saw above) but also increase exponentially. These exploding gradients can be disastrous for our networks as they can cause our parameters to become so large that our network just goes bonkers!
The silver lining with exploding gradients is that they are easier to spot than vanishing gradients. The network might display NaN (Not a Number), which means there is a numerical overflow in our neural network computations.
We can solve the problem of exploding gradients by applying gradient clipping. This is nothing but scaling or re-scaling our gradient vectors once they reach a threshold or a maximum value. It is as robust a solution for exploding gradients as you can get.
Exploding gradients might look dangerous but they are easily solvable. However, vanishing gradients are quite tricky. There are some solutions that we will explore in the next section which require modifying the hidden layers of our RNN model. We call these new models as GRUs or Gated Recurrent Units and these will help us in capturing long-term dependencies with more ease than our current models.
2. Gated Recurrent Unit (GRU)
As we learned in our previous section, vanishing gradients of derivatives can make it hard for RNN models, especially very deep networks, to capture long-term dependencies. This problem can be solved with a modified hidden layer of our Recurrent Neural Network, called a GRU (Gated Recurrent Unit).
First, let’s recall what the hidden layer of our basic RNN looks like:

The formula for computing the activation values at time \(t \) of RNN is written as:
$$ a^{<t>}=g\left(W_{a}\left[a^{<t-1>}, x^{<t>}\right]+b_{a}\right) $$
The RNN unit takes two inputs – the activation value from the previous step, \(a^{\left \langle t-1 \right \rangle} \), and the current input, \(x^{\left \langle t \right \rangle} \). These two are fed to the RNN unit along with some weights and biases, and then, to the function \(g \) which is a tanh activation function. This tanh function computes the output activation, \(a^{\left \langle t \right \rangle} \). This output activation value, \(a^{\left \langle t \right \rangle} \), is also passed to a Softmax unit which then predicts the output \(\hat{y}^{\left \langle t \right \rangle} \).
An understanding of the above visualization of RNN’s hidden layer unit is important since we will use a similar representation for our Gated Recurrent Unit (GRU) too.
Note: I would like to point out that the bulk of the information and the concept of GRU we have is due to the two papers are written by Yu Young Chang, Kagawa, Gaza Hera, Chang Hung Chu, and Jose Banjo.
GRU Architecture
Let’s recall the example sentence we previously used: “The dog, which ran out …, has come back.”
How a GRU reads this sentence is pretty much the same as any RNN unit except that there are some modifications. One is the introduction of a memory variable called \(c \). The job of this memory variable is to remember whether the “dog” was singular or plural so that it can be utilized in the latter part of the sentence. At a time $latex t $, this memory cell will have some value \(c^{\left \langle t \right \rangle} \). The GRU unit will give an output of an activation value \(a^{\left \langle t \right \rangle} \), which is actually equal to the same memory variable \(c^{\left \langle t \right \rangle} \). Even though they both have the same value, we will for now, use two different variables for memory cell value and output activation value. However, they won’t have the same value when we move on to Long Short-Term Memory (LSTM) Units later on in this post.
At every time step, we will consider overwriting the memory variable with a value Slatex \tilde{c}^{\left \langle t \right \rangle} $ and this will in turn replace the value \(c^{\left \langle t \right \rangle} \) using the activation function tanh of \(w_{c} \). This parameter will, in turn, be passed on to the current memory variable along with the previous memory cell value, the activation value and the current input value \(x^{\left \langle t \right \rangle} \), together with the bias. This is what the equation will look like:
$$ \tilde{c}^{\left \langle t \right \rangle}= tanh\left ( w_{c}\begin{bmatrix} c^{\left \langle t-1 \right \rangle}, &x^{\left \langle t \right \rangle}\end{bmatrix} +b_{c}\right ) $$
So now what the Gated Recurrent Unit (GRU) does is that it literally creates a Gate that makes a decision about the input word being singular or plural. This gate is represented by \(\Gamma _{u}\) where \(u \) stands for update gate, and the value of this gate will either be 0 or 1. Say, 1 when the word is plural and 0 when the word is singular. Our candidate \(\tilde{c}^{\left \langle t \right \rangle} \) for replacing \(c^{\left \langle t \right \rangle} \) is passed through this gate and the gate decides at what time this value is to be used. In our example, the gate is assigned a value \(\Gamma _{u}\), at the word “dog” and it makes a decision at the word “has”.
We calculate the gate value using a sigmoid function as represented below:
$$ \Gamma _{u}= \sigma \left ( w_{u}\begin{bmatrix} c^{\left \langle t-1 \right \rangle}, &x^{\left \langle t \right \rangle}\end{bmatrix} +b_{u}\right ) $$
In reality, this sigmoid function ranges from values which are infinitesimally close to 0 to values infinitesimally close to 1. However, for intuition purposes, we consider this as absolute 0 and absolute 1.
Now, coming back to the key GRU equation:
$$ \tilde{c}^{\left \langle t \right \rangle}= tanh\left ( w_{c}\begin{bmatrix} c^{\left \langle t-1 \right \rangle}, &x^{\left \langle t \right \rangle}\end{bmatrix} +b_{c}\right ) $$
At the word “dog”, the memory cell value \(c \) will be set to 1 (assuming 1 means singular) or 0 (if the word is “dogs” and not “dog”, i.e., plural). The GRU unit will memorize this value of this \(c^{\left \langle t \right \rangle} \) all the way till it the word “has” or “have”. The job of our gate \(\Gamma _{u}\) is to continue reading through the words and if any change occurs in singularity or plurality, it makes a decision to update the memory cell value. Once the memory cell value has been used, the gate updates it to signal that there is no further need to memorize any value as the job is done.
Change text: The dog, which ran out …, has come back.

Forward Propagation in GRU
Let us see how our Gated Recurrent Unit (GRU) works in forward propagation. The equation that will be following is this:
$$ c^{\left \langle t \right \rangle}= \Gamma _{u}\times \tilde{c}^{\left \langle t \right \rangle}+\left ( 1-\Gamma _{u} \right )\times c^{\left \langle t-1 \right \rangle} $$
Here, \(c^{\left \langle t \right \rangle} \) is the actual value, \(\tilde{c}^{\left \langle t \right \rangle} \) is the candidate value and \(\Gamma _{u}\) is the gate value.
Notice that if the gate value is equal to 1, it means the GRU is setting the new value \(c^{\left \langle t \right \rangle} \) of equal to the candidate value, \(\tilde{c}^{\left \langle t \right \rangle} \). This is when the GRU is processing the word “dog”.
When the GRU propagates further through the sentence, it keeps updating the gate value to zero. This essentially means that for the words between “dog” and “has”, the gate value will be zero and thus, the memory cell will keep holding on to its previous value. Because if \(\Gamma _{u}= 0 \), then, \(1- \Gamma _{u}= 1 \). Thus, \(c^{\left \langle t \right \rangle} \) will just be equal to the previous value \(c^{\left \langle t-1 \right \rangle} \). This way, throughout the sentence, GRU remembers that “The dog” is singular in nature.
You must be thinking that you have learned GRU mathematically, but how does it look like graphically. The representation below is a nice way to depict a functional Gated Recurrent Unity (GRU).
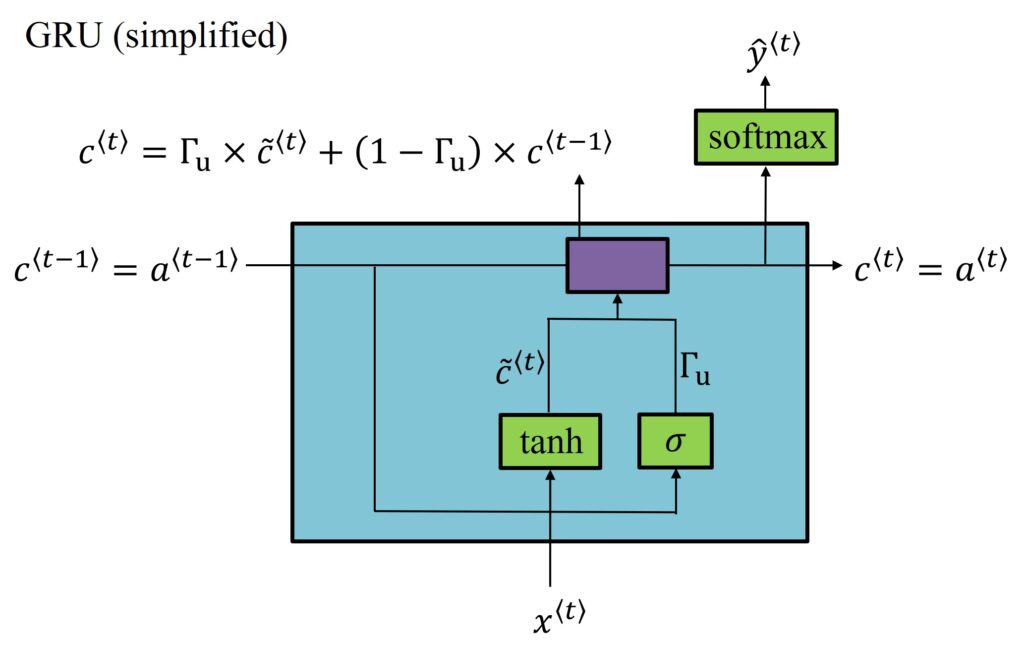
Observe how the input for the GRU is \(c^{\left \langle t-1 \right \rangle} \) which is equal to \(a^{\left \langle t-1 \right \rangle} \). As we mentioned, it is in GRU only that these two values are equal. When we move on to understanding LSTM, these two values will be different.
Now, this input, which is taken from the previous time step, \(c^{\left \langle t-1 \right \rangle} \), is then combined with the current time step’s input \(x^{\left \langle t \right \rangle} \). These is put together along with appropriate weights and activation function tanh to get our candidate value, \(\tilde{c}^{\left \langle t \right \rangle}. This candidate value is then combined with the output of the sigmoid activation function which is the update gate, \)latex \Gamma _{u} $.
Then, the candidate value, the previous time step value and the update gate are passed into another operative function (the purple box), resulting in our GRU equation, $$ c^{\left \langle t \right \rangle}= \Gamma _{u}\times \tilde{c}^{\left \langle t \right \rangle}+\left ( 1-\Gamma _{u} \right )\times c^{\left \langle t-1 \right \rangle} $$. This finally generates a new value for our memory cell. This new memory value can further be used by Softmax distribution to predict for an output \(\hat{y}^{\left \langle t \right \rangle} \).
Solving the Vanishing Gradient Problem Using GRU
GRU’s capability of using gates and memory cells makes it an efficient solution for our vanishing gradient problem. This is because the gate of GRU can easily be set to 0. Due to the sigmoid function being used, this absolute value of 0, which we have assumed for the sake of simplicity here, is very close to 0 in reality as well. And, it is excellent at maintaining this closeness to 0, something like 0.000001 or even smaller than that. This is the reason GRUs don’t suffer from vanishing gradients that much. This small value of the gate/gamma close which can be rounded off to 0 allows the GRU to set the actual memory value equal to the previous memory value and maintain that throughout the time steps of our deep neural network sentence, i.e., \(c^{\left \langle t \right \rangle}= c^{\left \langle t-1 \right \rangle}\). Thus, GRUs makes for an excellent choice for tackling long-term dependencies, which were a problem while we were dealing with basic RNN algorithms.
If you observe carefully, the multiplication of values in the GRU equation is in fact element-wise product of vectors of the same dimension. So, if \(c^{\left \langle t \right \rangle}\) is a 100-dimensional vector, then \(c^{\left \langle t \right \rangle}\), \(\tilde{c}^{\left \langle t \right \rangle}\) and \(\Gamma _{u} \) are also of the same dimensions. The element-wise multiplication of these vectors tells your GRU of the dimensions of your memory cell vector that need to be updated at each time step. You can choose which bits of these vectors to update and which of them to keep as constant. Say, if you are using one bit to define if the word “dog” is “singular or plural”, you can use another bit to tell the GRU that the sentence is “talking about going out of the house or entering the house” and make subsequent predictions accordingly.
Simplified Notation For GRU
Let us now compile all the concepts we have learned so far about GRU and present a simplified Gated Recurrent Unit with three key equations:
$$ \tilde{c}^{\left \langle t \right \rangle}= tanh\left ( w_{c}\begin{bmatrix} c^{\left \langle t-1 \right \rangle}, &x^{\left \langle t \right \rangle}\end{bmatrix} +b_{c}\right ) $$
$$ \Gamma _{u}= \sigma \left ( w_{u}\begin{bmatrix} c^{\left \langle t-1 \right \rangle}, &x^{\left \langle t \right \rangle}\end{bmatrix} +b_{u}\right ) $$
$$ c^{\left \langle t \right \rangle}= \Gamma _{u}\times \tilde{c}^{\left \langle t \right \rangle}+\left ( 1-\Gamma _{u} \right )\times c^{\left \langle t-1 \right \rangle} $$
We will just make a minor change in the first equation to represent the full GRU algorithm. By adding another gate \(\Gamma _{r} in the calculation of new candidate value of the memory cell, we can know how relevant is \)latex c^{\left \langle t-1 \right \rangle}$ in calculating the next candidate for \(c^{\left \langle t \right \rangle}\). We will also add another parameter matrix to help with computing the relevance gate, \(\Gamma _{r}, and this parameter will be represented as \)latex w_{r}$. So, our revised first equation is now this:
$$ \tilde{c}^{\left \langle t \right \rangle}= tanh\left ( w_{c}\begin{bmatrix} \Gamma _{r}\times c^{\left \langle t-x \right \rangle}, &x^{\left \langle t \right \rangle} \end{bmatrix} +b_{c}\right ) $$
And in the equation above, the relevance gate $latex \Gamma _{r} is computed as follows:
$$ \Gamma _{r}= \sigma \left ( w_{r}\begin{bmatrix} c^{\left \langle t-1 \right \rangle}, &x^{\left \langle t \right \rangle} \end{bmatrix} +b_{r}\right ) $$
Other Notations for GRU
In our blog post, we have tried to maintain consistency in terms of the notation, so that it is easy for you, our readers, to understand the concepts of GRU. However, there are many academic literature where you might encounter alternative notation such as \(\tilde{h}\), \(u \), $latex r $ and \(h \). The same goes for the notation for the gates, \(\Gamma \). So, don’t be baffled if you come across other notations, you can continue to use the notations we discussed in this blog post as they are written with the intent of simplifying the learning process and also to keep notations consistent for the upcoming section on LSTM.
There are many ways to design neural networks that solve the problem of vanishing gradients. You may think why we have ended with the use of an extra gate, $latex \Gamma _{r} and if we could have kept it simpler than that, say, with the use of only a single gate. You are right in thinking that. This is why we suggest you also try to invent newer ways of handling long-term dependencies, longer-range connections, and vanishing gradients.
Of course, Gated Recurring Units (GRUs) are just one robust way of solving the problem that researchers around the globe have converged to, after trying out many other algorithms. The range of applications for GRU is quite extensive, as has been proved over time. Among the most common algorithms, GRU is the most popular and the other is LSTM (Long Short-Term Memory) which will talk about in the next section. So, let’s get on to it.
3. Long Short-Term Memory (LSTM) Unit
As we learned in the earlier section, there is no one way to solve the problem of long-term dependencies or long-range connections. Gated Recurrent Unit (GRU) is the most commonly used. However, there is an even more powerful method than GRU which we will look into now. These are Long Short-Term Memory Units (LSTM).
Before we lay down the equations and notations for LSTM, let’s quickly recap the equations for GRU:
$$ \tilde{c}^{\left \langle t \right \rangle}= tanh\left ( w_{c}\begin{bmatrix} \Gamma _{r}\times c^{\left \langle t-1 \right \rangle}, &x^{\left \langle t \right \rangle} \end{bmatrix} +b_{c}\right ) $$
$$ \Gamma _{r}= \sigma \left ( w_{r}\begin{bmatrix} c^{\left \langle t-1 \right \rangle}, &x^{\left \langle t \right \rangle} \end{bmatrix} +b_{r}\right ) $$
$$ \Gamma _{u}= \sigma \left ( w_{u}\begin{bmatrix} c^{\left \langle t-1 \right \rangle}, &x^{\left \langle t \right \rangle}\end{bmatrix} +b_{u}\right ) $$
$$ c^{\left \langle t \right \rangle}= \Gamma _{u}\times \tilde{c}^{\left \langle t \right \rangle}+\left ( 1-\Gamma _{u} \right )\times c^{\left \langle t-1 \right \rangle} $$
$$ a^{\left \langle t \right \rangle}= c^{\left \langle t \right \rangle} $$
In the case of GRU, we had \(a^{\left \langle t \right \rangle}= c^{\left \langle t \right \rangle}\). We also had two gates, the update gate and the relevance gate. The update gate \(\Gamma _{u}\) would decide whether or not to update the memory cell value, \(c^{\left \langle t \right \rangle}\) using the candidate value, \(\tilde{c}^{\left \langle t \right \rangle}\).
Notation And Architecture of LSTM Units
The case for Long Short-Term Memory Unit has been laid out impactfully by a seminal paper that has had a huge impact on sequence modeling. This paper was written by Sepp Hochreiter and Jürgen Schmidhuber and is quite deep in its research into the theory of vanishing gradients.
Let us look at the equations that govern LSTM Units, as learned from the research paper by Hochreiter and Schmidhuber.
$$ \tilde{c}^{\left \langle t \right \rangle}= tanh\left ( w_{c}\begin{bmatrix} c^{\left \langle t-1 \right \rangle}, &x^{\left \langle t \right \rangle}\end{bmatrix} +b_{c}\right ) $$
$$ \Gamma _{f}= \sigma \left ( w_{f}\begin{bmatrix} c^{\left \langle t-1 \right \rangle}, &x^{\left \langle t \right \rangle} \end{bmatrix} +b_{f}\right ) $$
$$ \Gamma _{u}= \sigma \left ( w_{u}\begin{bmatrix} a^{\left \langle t-1 \right \rangle}, &x^{\left \langle t \right \rangle} \end{bmatrix} +b_{u}\right ) $$
$$ \Gamma _{o}= \sigma \left ( w_{o}\begin{bmatrix} c^{\left \langle t-1 \right \rangle}, &x^{\left \langle t \right \rangle} \end{bmatrix} +b_{o}\right ) $$
$$ c^{\left \langle t \right \rangle}= \Gamma _{u}\ast \tilde{c}^{\left \langle t \right \rangle}+\Gamma _{f}\times c^{\left \langle t-1 \right \rangle} $$
$$ a^{\left \langle t \right \rangle}=\Gamma _{o} \times c^{\left \langle t \right \rangle} $$
In the case of LSTM, the first difference from GRU is that the case where \(a^{\left \langle t \right \rangle}= c^{\left \langle t \right \rangle} \) will no longer be true. We will be especially using \(a^{\left \langle t-1 \right \rangle} \) more than \(c^{\left \langle t-1 \right \rangle}\). In addition, we also won’t be using the relevance gate, \(\Gamma _{r}\). We could definitely create a variation of LSTM where we use this relevance gate, but the common version of LSTM doesn’t require using this relevance gate. The update gate \(\Gamma _{u} \) will be there like in the case of GRU but with more extensive use of \(a^{\left \langle t-1 \right \rangle}\).
One new inclusion in LSTM unit is another gate that utilizes the sigmoid function, which we call a Forget Gate. This forget gate \(\Gamma _{f} \) will be used instead of the term \(1-\Gamma _{u} \). Then, we also have a new output gate which is the sigma of \(\Gamma _{o} \). The update value to the memory cell will be \(c^{\left \langle t \right \rangle}= \Gamma _{u}\ast \tilde{c}^{\left \langle t \right \rangle}+\Gamma _{f}\times c^{\left \langle t-1 \right \rangle}\).
Similar to what we learned in GRUs, in the case of LSTMs too, the multiplication in the above equation is a cross-product between vectors or an element-wise multiplication.
LSTM, in total, uses three gates – Update Gate, Forget Gate, and Output Gate. Let’s see how the LSTM architecture looks like.
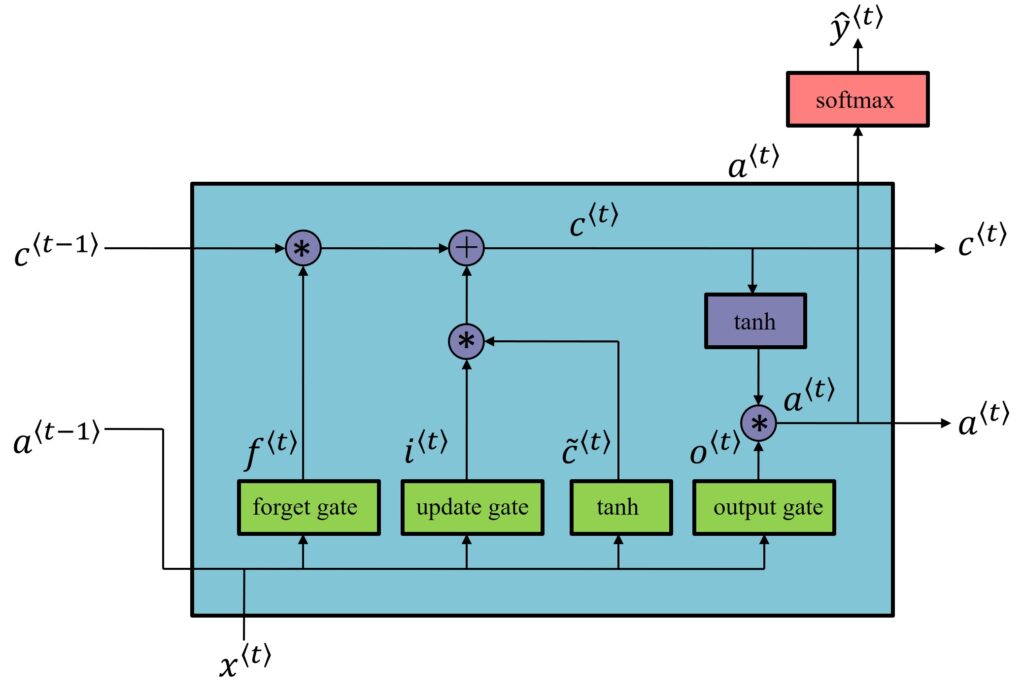
Note: The diagrams we have used in this blogpost for LSTM are inspired by a blog post by Chris Ola, titled ‘Understanding LSTM Network’. So, big thanks to Chris!
Now, as we can see in the above diagram, all the gate values (forget gate, update gates and output gate) are computed using \(a^{\left \langle t-1 \right \rangle}\) and \(x^{\left \langle t \right \rangle}\). These two values also go through a tanh function to calculate the candidate value \(\tilde{c}^{\left \langle t \right \rangle}\). All these values are, then, combined using element-multiplication to get \(c^{\left \langle t \right \rangle}\) from the previous \(c^{\left \langle t-1 \right \rangle}\).
Let’s try connecting this one LSTM unit in parallel with the subsequent units to see how propagation works in LSTM.
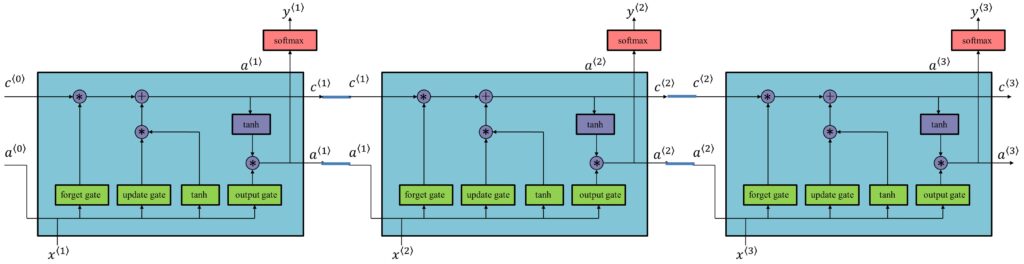
Just like any forward propagation, each LSTM unit receives the respective inputs \(x^{\left \langle 1 \right \rangle}\), \(x^{\left \langle 2 \right \rangle}\) and \(x^{\left \langle 3\right \rangle}\) and outputs an activation value, say, \(a^{\left \langle 1 \right \rangle}\), which then becomes the input \(a^{\left \langle t \right \rangle}\) for the next timestep. We can even simplify the above diagram further and notice how easy it is for LSTM units to have some value \(c^{\left \langle 0 \right \rangle}\) and have it memorized till all the way to the end of the sequence to give, \(c^{\left \langle 3 \right \rangle}= 0 \).

This is the real advantage of using LSTM units, and in fact, GRU as well, because they are so good at memorizing certain values and that too for a very long time.
Variations of LSTM Units
The most commonly used LSTM is the one you saw above. However, there are a few variations of LSTM units that are also used. One of them is the “Peephole Connection”. Interesting name, we agree!
In a peephole connection, the gate values are not just dependant on \(a^{\left \langle t-1 \right \rangle}\) and \(x^{\left \langle t\right \rangle}\), but also \(c^{\left \langle t-1 \right \rangle}\), which is the previous memory cell value. So, if you have a 100-dimensional hidden memory cell unit, the fifth element of latex c^{\left \langle t-1 \right \rangle}$ will affect only the fifth element of the corresponding gate. Therefore, in a peephole connection, there is a one-to-one relationship between elements.
The question now arises when to use GRU and when to use LSTM. To be honest, the research world hasn’t reached any consensus on this yet. Even though we learn GRU first in our blog post, LSTMs arrived much earlier in the deep learning chronology. GRUs are more recently invented, partly due to the efforts of Pavia’s simplification of the more complicated LSTM model.
Both these algorithms have been used by researchers for a variety of problems and there has been no clear winner, yet! We should be able to make a decision based on the pros and cons of both these algorithms based on the problem we have at hand. On one side, GRUs are much simpler than LSTM and it is easier to build bigger networks with GRU. They also have only two gates, so they are faster computationally as well, and thereby, they can be easily scaled to build bigger models. On the other side, LSTM, though complex, are more powerful as well as effective with their use of three gates instead of two.
If you go by historical evidence, LSTM models have been used more often. However, since the past few years, GRUs have been gaining a lot of traction due to their simplicity. All in all, both GRUs and LSTMs are excellent in handling long-term dependencies or long-range connections and solve the dire problem of vanishing gradients easily.
This brings us to the end of this blog post. Vanishing gradients were seeming like a big problem before this tutorial and I’m sure learning about GRUs and LSTMs has given you the appropriate solution that you were looking for. Please remember that whichever models we discussed today can be modified, re-thought, re-invented, and built upon to create simpler, more effective, and more powerful models. That’s what we hope you’ll do after you have mastered the concepts of Recurrent Neural Networks, sequence generation, language modeling, vanishing gradients, GRUs, and LSTMs. If you have any doubts or suggestions, please do leave a comment and we promise to respond as quickly as we can.
RNN: Vanishing Gradients, GRU and LSTM
- Basic RNNs are not good at capturing long-term dependencies or long-range connections
- The problem of Vanishing Gradients and Exploding Gradients are common with basic RNNs
- Gated Recurrent Units (GRU) are simple, fast and solve vanishing gradient problem easily
- Long Short-Term Memory (LSTM) units are slightly more complex, more powerful, more effective in solving the vanishing gradient problem
- No clear winner between GRU and LSTM
- Many other variations of GRU and LSTM are possible upon research and development
Summary
Congratulations! You have mastered the entire concept of Recurrent Neural Networks (RNN). From basic models to advanced and more complex algorithms, you have come a long way in this journey. You are now ready to build your own models, be it Speech Recognition, Machine Translation, Music Generation, Natural Language Processing, or Name Entity Recognition. Do share with you your exciting new models and we’ll be happy to test them out with you, ok? Take care and we’ll see you in our next tutorial. ?