#004 RNN – Language Modelling and Sampling Novel Sequences
Highlights: Recurrent Neural Networks (RNN) are sequence models that are a modern, more advanced alternative to traditional Neural Networks. Right from Speech Recognition to Natural Language Processing to Music Generation, RNNs have continued to play a transformative role in handling sequential datasets.
In this blog post, we will learn how RNNs are used to build and train Language Models, and thereby, sample novel sequences from our trained models. By the end of the post, you will understand how RNNs can be applied to generate texts from famous authors or any text pieces you like. So, let us begin.
Tutorial Overview:
- What is Language Modelling?
- Building a Language Model using RNN
- Tokenization of Input Sequence
- Forward Propagation
- Back Propagation
- Sampling a Sequence From a Trained RNN
- Character-Level Language Model
1. What is Language Modelling?
One of the most fundamental aspects of Natural Language Processing is building Language Models. Recurrent Neural Networks are well-equipped to handle such tasks and can help you build and train successful and accurate Language Models, easily.
To understand Language Modelling, let us take a basic example of a sentence and see how speech can be perceived in different ways by a neural network.

Suppose while building a speech recognition system, you hear the sentence “Whenever he was free, Ross read books”. While you may guess that the phrase is “read books”, it is quite possible for you to confuse it with “red books”. The same confusion occurs at the network’s end as well. However, the neural network has its own smart ways of guessing the right output even though both phrases sound exactly the same.
A good speech recognition system uses a Language Model which calculates the probability of both these phrases/sentences. In this instance, the language model may suggest that the probability of the phrase being “red books” is \(3,2\times 10^{-13} \) and the probability of the phrase being “read books” is \(5,7\times 10^{-10} \). Clearly, “read books” wins over “red books” by a factor of over \(10^{3} \), and thus, the speech recognition system makes the appropriate choice.
Therefore, the main job of a Language Model is to compute the probability of a given sequence of words that form the input sentence, which means, the chance of you finding that particular sentence in a daily newspaper, a random email or a random webpage or encountering it in your life. The same fundamentals not only apply to Speech Recognition systems but also Machine Translation systems.
So, how do we really build such Language Models? More importantly, how do we build Language Models using Recurrent Neural Networks? Let us move to the next section to understand this in detail.
2. Building a Language Model Using RNN
Well, to start building our own Language Models using Recurrent Neural Networks (RNNs), we would need a training set that comprises of a large database of words or text from English or your preferred language for modeling. This data set or word corpus is an NLP terminology that translates to a large collection of the English text of English sentences.
Let us consider an example sentence.

Tokenization of Input Sequence
Our training set has a new sentence: “Dogs have an average lifespan of 12 years.” The foremost thing we need to do is to tokenize the sentence. What do we mean by tokenizing? To tokenize a sentence is to create a vocabulary or dictionary of words for the sentence, as we discussed in our previous posts. After creating the dictionary, we map each of these words to one-hot vectors of the indices in the dictionary. An important thing to be careful while tokenizing the input sentence is that we need to be mindful of the end of the sentence. We can tackle this by adding an extra token called EOS (End Of Sentence) that signals when the sentence ends. If we want to capture the exact moment when our sentences end in our training set, we can add the EOS token to add the end of each sentence.
In our example, there are nine inputs including the EOS token, namely, \(y^{\left \langle 1 \right \rangle}\), \(y^{\left \langle 2 \right \rangle}\), \(y^{\left \langle 3 \right \rangle}\), \(y^{\left \langle 4 \right \rangle}\), \(y^{\left \langle 5 \right \rangle}\), \(y^{\left \langle 6 \right \rangle}\), \(y^{\left \langle 7 \right \rangle}\), \(y^{\left \langle 8 \right \rangle}\) and \(y^{\left \langle 9 \right \rangle}\). It is up to you whether you want to include punctuation such as period / full-stop as an explicit token as well. In that case, you can add the period / full-stop to the dictionary as well. For our ease of understanding, we are not considering any punctuation as tokens in our examples.
Now, what happens when some of the words from our training set are not present in the vocabulary or dictionary that we created? Observe this Output Sentence: “The Irish Setter is a breed of dog”. Even after creating a dictionary of 10,000 most common English words, there are few words like “Setter”, the Irish breed name of a dog, that might still be missing. Not to worry! We can simply replace such words with a unique token called UNK, which literally stands for “Unknown Word”. Then, we can suitably compute the probability of this unknown word in our model.
Once we have tokenized the input sentence by pairing it to the individual tokens or the individual words of the dictionary, we can move ahead in building the Recurrent Neural Network to model the chance/probability of these different sequences. One of the things that we’ll see in this post ahead is that we end up setting the following equation:
$$ x^{\left \langle t \right \rangle}= y^{\left \langle t-1 \right \rangle}$$
Let us now move ahead and build our Recurrent Neural Network model for our example.
Building RNN Architecture
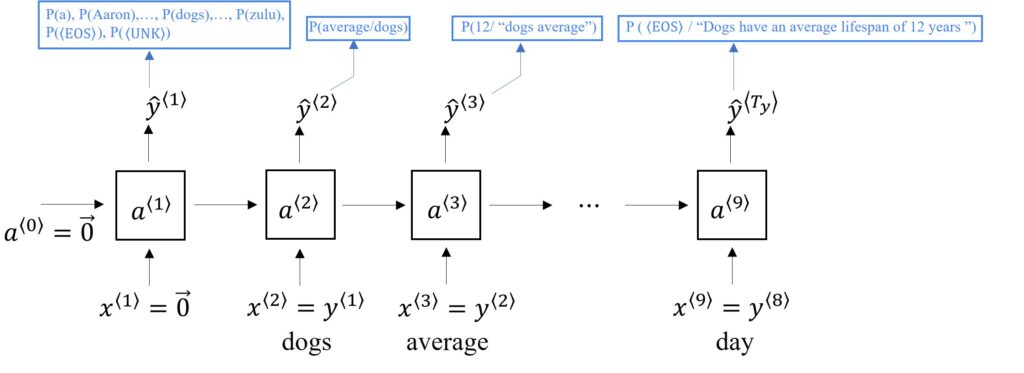
After understanding how tokenization of input sequence is done, we can now get on with building the RNN architecture for our training example sentence: “Dogs have an average lifespan of 12 years.” This is what the RNN architecture looks like:

Forward Propagation
The forward propagation of our RNN model begins at time 0, wherein some activation \(a^{\left \langle 1 \right \rangle} \) is computed as a function of some input \(x^{\left \langle 1 \right \rangle}\), which in turn is set to all zeros, or a 0-vector. The initial activation \(a^{\left \langle 0 \right \rangle}\) by convention is also an event of zeros. Now, the main role that \(a^{\left \langle 1 \right \rangle}\) plays is that it makes a Softmax prediction to try to predict the probability of the first word of our training example – “Dogs”. This is denoted by \(\hat{y}^{\left \langle 1 \right \rangle}\).
What do we mean by Softmax prediction here? A Softmax prediction picks each word from the dictionary we have created and tries to predict the probability of that word occurring in a particular sentence. For example, computing the chance that the first word was “Zulu” or the chance that the first word is an Unknown Word and so on. In short, Softmax helps us get to the output at each stage, that is, \(\hat{y}^{\left \langle 1 \right \rangle}\). In our training set, Softmax will have to predict probabilities for 10,002 tokens in total, including EOS and UNK.
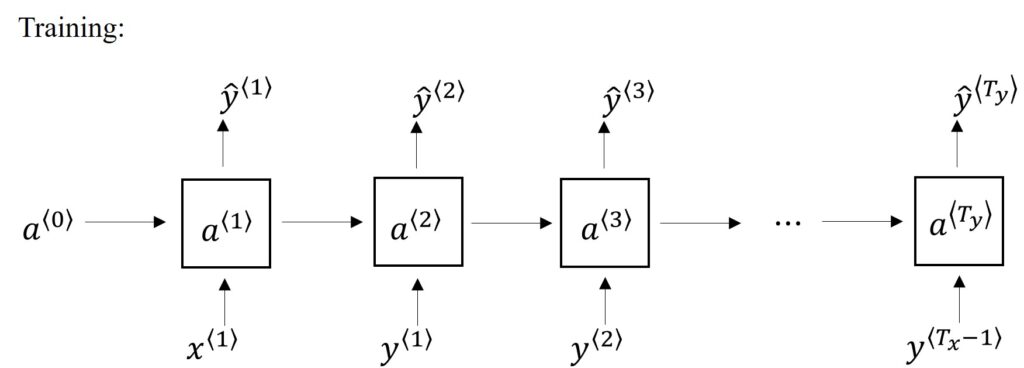
Continuing with the forward propagation, the RNN model uses the activation \(a^{\left \langle 1 \right \rangle}\) to predict the next word. At this time step, the network will also be given the correct value of the first word. In our case, we will tell the RNN that the first word was “Dogs”. This way the output of the previous time step also becomes the input for the next time step, that is, \(y^{\left \langle 1 \right \rangle}= x^{\left \langle 2 \right \rangle}\). We move to the next time step and the whole process with Softmax is repeated as it predicts the second word. In the third time step, we tell the network the correct second word which is “have” and the next activation value \(a^{\left \langle 3 \right \rangle}\) is computed. In this step, the input is the first two words “Dogs have” and hence, the output of the previous step is again equal to the input of the next step, that is, \(x^{\left \langle 3 \right \rangle}= y^{\left \langle 2 \right \rangle}\).
The process moves from left to right till it reaches the EOS token. In each step of the RNN, previous words act as input for the next word, and this way, the RNN learns to predict one word at a time propagating in the forward direction.
Back Propagation
Now that we have performed forward propagation for our Language model using RNN, we shall look at how we are going to define the cost function and compute the loss using backpropagation. As we learned in our previous post, we are going to train our network by calculating loss at a certain time \(t \). So, if at this time the correct word was .. and the neural network Softmax predicted the output .., we can easily compute the loss at this particular time. The total loss, as we understood previously, is nothing but the sum of losses computed for each time step and individual predictions.
If we train this neural network for a larger training set, given an initial set of words such as “Dogs have an average” or “Dogs have an average lifespan”, our neural network will be able to predict the probabilities of the subsequent words using Softmax, such as \(P \)of \(y^{\left \langle 2 \right \rangle}\) given \(y^{\left \langle 1 \right \rangle}\) and so on. Hence, for a three-word sentence or a four-word sentence, the total probability will be the product of all the previous probabilities of those three or four words.
So, this is how we train a language model using a Recurrent Neural Network. In the upcoming section, we will put these theories to practical use and learn more about how to sample novel sequences from our already trained model.
3. Sampling a Sequence From a Trained RNN
We have successfully learned how to build and train a Language Model using a Recurrent Neural Network. Let us see how we can put this trained model to use.
An important aspect to be explored, once a Language Model has been trained, is how well it can generate new or novel sequences. Let us understand this in detail.
Using Softmax, our trained model predicts the chance or probability of a particular sequence of words and this can be represented as follows.
$$ P\left ( y^{\left \langle 1 \right \rangle},…,y^{\left \langle T_{x} \right \rangle} \right ) $$
The network has been trained using a training example sequence, however, we need to explore the possibilities of it generating different sequences as well. The sampling of novel sequences can be represented in a neat graphical form as shown below.
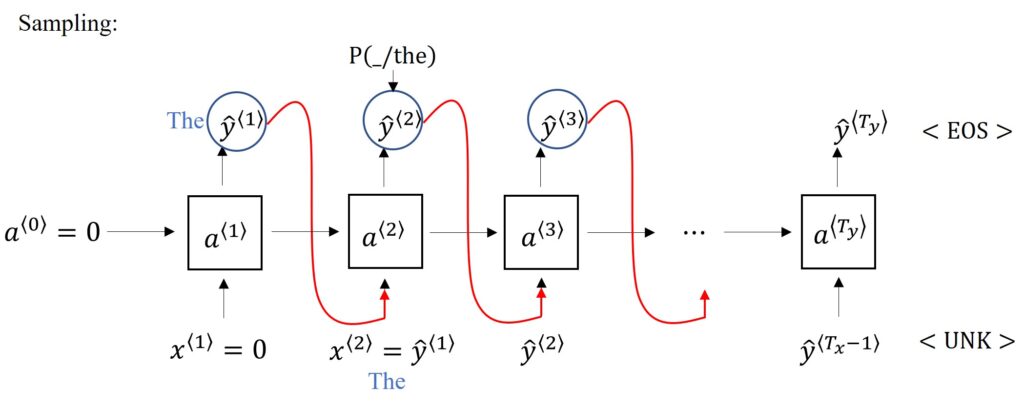
The sampling begins after we have initiated the first input \(x^{\left \langle 1 \right \rangle}= 0 \) and set the initial activation value \(a^{\left \langle o \right \rangle}= 0 \). Softmax distribution calculates the probabilities of random samples. The vector formed by all these probability values of each time step is then inputted to a NumPy command, np.random.choice, which samples the first words according to these calculated probabilities.
After the first word has been sampled, we move on the second time step which is expecting \(y^{\left \langle 1 \right \rangle}= 0 \) as input. However, we pass on the output we sampled above, \(\hat{y}^{\left \langle 1 \right \rangle}\), and pass as input to the second time step. Softmax distribution will, then, make a prediction for the second output \(\hat{y}^{\left \langle 2 \right \rangle}\) based on this input, which is nothing but the sampled output of the previous time step.
Let’s say the first word we sample, \(\hat{y}^{\left \langle 1 \right \rangle}\), happens to be “The”, which is a fairly common choice for the first word in the English language. We pass this “The” as the input to the second time step, represented by \(x^{\left \langle 2 \right \rangle} \). Softmax distribution will now determine what is the most probable second word, given that the first word is “The”.
In the second time step as well, we shall use the sampling function method to sample the next word. This process keeps continuing until we reach the last time step.
But how would you know when the sequence ends? One solution, as we learned earlier, is to add an EOS (End Of Sentence) token as part of our dictionary. The second solution is that we don’t include EOS in our dictionary but set a pre-decided number of time steps. When the system reaches that number of time steps, the process ends. Another hurdle is that of unknown words. If we want to ensure that our algorithm never generates a UNK token, we could simply reject any sample that turns out to be “unknown” and keep sampling until we sample an output which is not “unknown”. Alternatively, we could just leave it as is, that is, if you don’t mind an unknown word output.
Following the above procedure, you can easily generate a randomly chosen sentence based on your created dictionary, using a Recurrent Neural Network’s Language Model.
So far, what we have learned, is a words-level Language Model, where all the words sampled are taken from an English vocabulary or dictionary. This type of model has certain issues, especially, the problem of unknown words being generated. This can be solved if we change our Language Model slightly. Let us see how we can do that.
4. Character-Level Language Model
An alternative to a Words-level Language Model uses characters instead of words to form a dictionary. This means that the vocabulary only contains alphabets from “a” to “z” along with space, punctuation, and digits from “0” to “9”. We could also distinguish our alphabets by segregating them according to Uppercase and Lowercase within our dictionary. We can decide what to include in this character-level dictionary based on the kind of characters that appear in our training set.
Let’s look at the basic architecture of a Character-level Language Model.
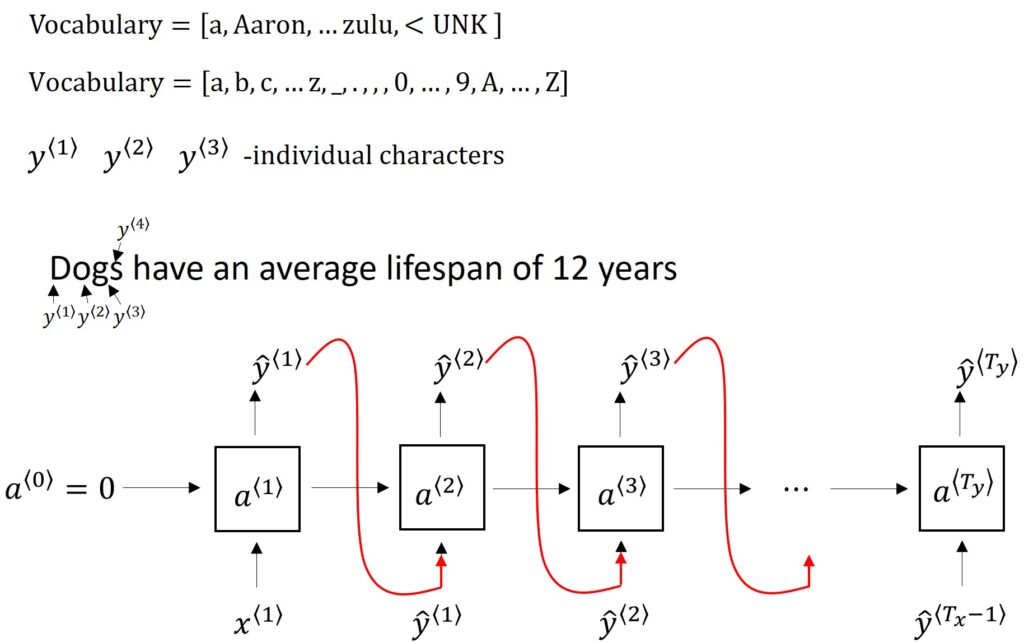
Unlike the case of word-level language model, each time step will predict each character rather than each word, as represented by \(y^{\left \langle 1 \right \rangle} \), \(y^{\left \langle 2 \right \rangle} \), \(y^{\left \langle 1 \right \rangle} \).
Consider the previous example again: “Dogs have an average lifespan of 12 years”. For a character-level language model, the character “D” would be \(y^{\left \langle 1 \right \rangle} \), “o” would be \(y^{\left \langle 2 \right \rangle} \), “g” would be \(y^{\left \langle 3 \right \rangle} \), “s” would be \(y^{\left \langle 4 \right \rangle} \) and the space between the “Dogs” and “have” would be \(y^{\left \langle 5 \right \rangle} \), and so on.
No doubt the character-level language model is a more detailed system than a word-level language model. However, it has its own advantages and disadvantages.
Advantage: No need to worry about unknown word tokens, since “Setter” as a word might not have been available in a word-level dictionary and will have a zero probability, but at a character-level “Setter” will have a non-zero probability.
Disadvantage: The length of sequences become much longer in character-level language models as compared to the word-level language models. An English sentence with, say, 20 words, will have dozens of characters and therefore, long-range dependencies between the early parts of the sentence and the latter part of the sentence. In addition, such character-level language models turn out to be more computationally expensive when it comes to training them.
Until now, the preferred choice for Natural Language Processing used to be Word-level Language Models. It is mostly preferred even today. However, with the advancement of modern and faster computers, the use cases for Character-level Language Models are steadily rising. Specialized applications such as cases where unknown words need to be dealt with are making use of Character-level Language Models but they are still very hard and computationally expensive to train, as we learned earlier.
So, these are the methods that are used to build and train a Recurrent Neural Network that looks at the corpus of training text in English, decides between a character-level or a word-level Language Model, and then samples novel sequences from this trained model.
You can build Language Models and train them on news articles to generate sample text that you might find often appearing in the news. You can also train your model using the works of Shakespeare and generate text which seems like it could have been written by Shakespeare himself.
“The mortal moon hath her eclipse in love”.
“And subject of this thou art another this fold”.
“When blessed be my love to me see sabl’s”.
“For whom are ruse of mine eyes havens”.
Of course, these are not grammatically perfect but hey, we can keep training our model to improve its grammar too. At least, it’s a good start!
This brings us to the end of this blog post. I’m sure you have had fun learning all about the basic Recurrent Neural Networks (RNN) and how we can build Language Models using it. You can even sample novel sequences from your trained models, now. There are many challenges to training RNNs that we haven’t discussed in this post. However, in our upcoming posts, we shall discuss about those challenges in detail, specifically, about vanishing gradients that are used to build even more powerful RNN models. So, hang in there and we’ll be back shortly with more tutorials!
Language Models Using RNN: Building, Training, and Sampling
- Language Models are used extensively for building Speech Recognition systems
- Two types of Language Models: Word-Level and Character-Level
- Word-Level Language Models predict words but harder to train with unknown words
- Character-Level Language Models predict characters, no issue of unknown words but are computationally expensive to train
- Once Language Models are trained, one can easily sample novel sequences from them
- Real-life applications include generating sample news headlines, writings similar to famous authors, among others
Summary
How cool would it be if you could build a Language Model that can write like William Wordsworth or one of your favourite authors? You are closer than ever to fulfil that dream since now you have learnt everything in theory about building Language Models using Recurrent Neural Networks. You have real magical powers now. Test them out while we prepare another awesome post for you, ok? See you soon ?