#015 PyTorch – Building A Smile Detector with PyTorch

Highlights: People spend a lifetime in the pursuit of happiness. Fortunately, intelligent machines can, today, detect happiness or smiles within seconds using Smile Detection Models.
In this tutorial post, we will learn how to build a Deep Learning-based Smile Detection model in PyTorch. We will utilize the LeNet-5 architecture and work on the CelebA dataset which is a large dataset of images containing faces of people smiling and not smiling, respectively. So let’s begin!
Tutorial Overview:
1. CelebFaces Attributes Dataset (CelebA)
The CelebA dataset is a large-scale face attributes dataset that contains over 200,000 images of celebrities. Each of these images has 40 attribute annotations and cover large pose variations as well as background clutter. This dataset is quite diverse with various combinations of hair color, gender, nationality, and age, and consists of large quantities and rich annotations. Have a look at the key attributes of this dataset.
- Number of identities = 10,177
- Number of face images = 202,599
- Number of landmark locations = 5
- Binary Attributes annotations per image = 40
- Image Size = \(178 \times 218 \)
Have a look at some of the sample images from the CelebA dataset below.

We can deploy the CelebA dataset as a training set as well as a test set for various Computer Vision tasks such as:
- Face attribute recognition
- Face recognition
- Face detection
- Landmark / Facial-part localization
- Face editing and synthesis, among others
Now that we are introduced to the CelebA dataset, let us get on with the process of building our Smile Detection model. For that, we will need to refresh ourselves with the basics of LeNet-5 architecture.
2. LeNet-5 CNN Architecture
LeNet-5 is a Convolutional Neural Network that was introduced by Yann LeCun [Gradient-Based Learning Applied to Document Recognition] in 1989. It is one of the earliest pre-trained models in Deep Learning to be used for recognizing handwritten characters and digits.
The model became popular due to its simplistic architecture that consists of 7 layers in total.
- 3 Convolutional Layers
- 2 Sub-Sampling Layers (including the Average Pooling Layers)
- 2 Fully-Connected Layers
A \(32 \times 32 \) grayscale image is inputted into the architecture (which means that the number of channels is \(1 \)) and the output is a SoftMax layer.
As we go deeper into the layers of the network, the number of channels increases from \(1 \) to \(6 \) to \(16 \). The LeNet-5 has a small number of parameters – \(60.000 \). However, today, we use neural networks that have parameters ranging from \(10 \) million to as large as \(100 \) million.
Have a look at the basic architecture of LeNet-5 CNN in the figure below.

In the first step, we use \(6\enspace5 \times 5 \) filters with a stride \(s=1 \) and no padding. Therefore, we end up with a \(28 \times 28 \times 6 \) volume. Notice that, because we are using \(s=1 \) and no padding, the image dimensions reduce from \(32 \times 32 \) to \(28 \times 28 \).
Next, \(LeNet-5 \) applies Pooling . In the days when the LeNet-5 research was done, Average pooling was much more in use. However, nowadays, we would probably use Max pooling instead.
For our understanding, we will study the implementation of the initially researched case using Average pool with filter \(f=2 \) and stride \(s=2 \). Using this, we get a \(14 \times 14 \times 6 \) volume. This means that we have reduced the dimensions of our image by a factor of \(2 \) due to the use of a stride of \(2 \).
Next, we apply another convolutional layer. We will use \(16 \) filters of dimension \(5\times5 \). And, we end up with \(16 \) channels in the next volume. The dimensions of volume are \(10\times10\times16 \). Once again, the height and the width are reduced and that is because when this paper was written same convolutions were not much in use.
Moving ahead, we will apply another pooling layer with filter size \(f=2 \) and stride \(s=2 \). Here again, we have reduced the size of the image by \(2 \), similar to the first pooling layer.
Finally, we have \(5\times5\times16 \) volume and if we multiply these numbers \(5\times5\times16 \), we get \(400 \). This means we have reduced the dimensions of the image and we can, now, apply a Fully connected layer with \(120 \) nodes.
In the next step, we apply another Fully connected layer with \(84 \) nodes. The final step is to use these \(84 \) features to get the final output. Notice that the output can have \(10 \) possible values since our goal is to recognize \(10 \) different digits (\(0 \) to \(9 \)).Towards the end, we are left with a softmax layer with a \(10 \)-way classification output. Interestingly, back in the day, \(LeNet-5 \) actually used a different classifier at the output layer, which is unfortunately, not of any use today.
Now that we have understood the basic architecture of LeNet-5, let us see how we can implement this knowledge into building an actual Smile Detection model using PyTorch code.
3. Smile Detection Model: PyTorch Code
First, let’s import the necessary libraries.
import os
from os import path
import shutil
import numpy as np
import pandas as pd
import dlib
import torch
import cv2
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset
from torch.utils.data.sampler import SubsetRandomSampler
from torchvision import datasets, transforms, models
from sklearn.preprocessing import StandardScaler
import random
import matplotlib
import matplotlib.pyplot as plt
from PIL import Image
import seaborn as sns
import zipfile
import shutil
Now let’s build our network. For our smiles detector, we are going to use LeNet5 architecture. We will use 2 fully convolutional layers, the Relu activation function, and MaxPooling. This will also be coupled along with 2 linear layers.
For the purpose of this project, we are going to adjust the layer and kernel dimensions. The following table demonstrates the architecture of our LeNet5 model.
- LeNet5( (convolutional_layer): Sequential(
- (0): Conv2d(3, 20, kernel_size=(5, 5), stride=(1, 1))
- (1): ReLU()
- (2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
- (3): Conv2d(20, 50, kernel_size=(5, 5), stride=(1, 1))
- (4): ReLU()
- (5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
- (linear_layer): Sequential(
- (0): Linear(in_features=1250, out_features=500, bias=True)
- (1): ReLU()
- (2): Linear(in_features=500, out_features=2, bias=True)
- (1): ReLU()
- (2): Linear(in_features=500, out_features=2, bias=True)
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
self.convolutional_layer = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=20, kernel_size=5, stride=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride =2),
nn.Conv2d(in_channels=20, out_channels=50, kernel_size=5, stride=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride =2),
)
self.linear_layer = nn.Sequential(
nn.Linear(in_features=1250, out_features=500),
nn.ReLU(),
nn.Linear(in_features=500, out_features=2),
)
def forward(self, x):
x = self.convolutional_layer(x)
x = torch.flatten(x, 1)
x = self.linear_layer(x)
x = F.softmax(x, dim=1)
return xNext, we will define a variable device that will store CPU or GPU depending on what we are training on. Then we are going to call the model we just created and set it to work on the device.
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = LeNet5()
model = model.to(device)
print(model)The next step is to download the CelebA dataset. With the following command, you can download this dataset directly into your Colab script.
!mkdir data_faces && wget https://s3-us-west-1.amazonaws.com/udacity-dlnfd/datasets/celeba.zip After running this command the zip file will appear in your script. First, we will call a module that will unzip this file, and then with the function zip_ref.extracall() we are going to extract files into the folder called data_faces that we created.
with zipfile.ZipFile("celeba.zip","r") as zip_ref:
zip_ref.extractall("data_faces/")Then, we need to download a CSV file which will help us to classify images with smiles and images with no smiles. You can download this folder here and then upload it into the Colab script.
The next step is to read this CSV file and create another one which will contain 1000 images with a smile and 1000 images with no smile. We can do that in the following way.
df = pd.read_csv("list_attr_celeba.csv")
df = df[['image_id', 'Smiling']]
smiling = df[df['Smiling'] == 1][:1000]
non_smiling = df[df['Smiling'] == -1][:1000]
df_all = pd.concat([smiling, non_smiling])
a = np.array(df_all)
df = pd.DataFrame(a)
print(df)0 000001.jpg 1
1 000002.jpg 1
2 000009.jpg 1
3 000011.jpg 1
4 000012.jpg 1
... ... ..
1995 001924.jpg -1
1996 001925.jpg -1
1997 001926.jpg -1
1998 001928.jpg -1
1999 001930.jpg -1
[2000 rows x 2 columns]Now, notice that the labels for non-smile images have the value of -1. We are going to change the values of these labels to 0 using the following code.
train=[]
for i in range(len(a)):
temp=[]
temp.append(a[i][0])
if a[i][1]==-1 :
temp.append(0)
else :
temp.append(a[i][1])
train.append(temp)
df=pd.DataFrame(train)
print(df)
smiling_size = int(len(smiling))
non_smiling_size = int(len(non_smiling))
df_size = int(len(df))
Our next goal is to crop the lip area from the images. In that way, we are going to achieve much better accuracy for our model.
To detect the lips we will use 68 facial landmarks from the dlib library. First, we are going to download dlib shape predictor using the following code:
!wget http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2
!bunzip2 "shape_predictor_68_face_landmarks.dat.bz2"Then we are going to create detector and predictor objects. We will use these objects to detect faces and facial landmarks.
detector = dlib.get_frontal_face_detector()
p = "shape_predictor_68_face_landmarks.dat"
# Initialize dlib's shape predictor
predictor = dlib.shape_predictor(p)Next, we will iterate through all images in our dataset and detect faces and facial landmarks. We will use indexes for landmarks in order to extract the specific area around the lips. Then, we will crop the area around the lips. Finally, we will create two folders. Using the function cv2.imwrite() we will specify the path to these folders and move cropped images with smiles to the folder called smile and images with no smiles to the folder called non_smile.
i_temp = 0
for i in range(smiling_size):
tmp_smile = smiling.iloc[i]['image_id']
image = cv2.imread(f"/content/data_faces/img_align_celeba/{tmp_smile}")
if image is None:
print(f"No such video: {tmp_smile}")
#gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
faces = detector(image)
for face in faces:
if (face.tl_corner().x) > 0:
i_temp = i_temp +1
landmarks = predictor(image, face)
left_x = landmarks.part(48).x
left_y = landmarks.part(50).y
right_x = landmarks.part(54).x
right_y = landmarks.part(56).y
w = np.abs(right_x - left_x)
h = np.abs(right_y - left_y)
padding_w = np.round(w * 0.4)
padding_h = np.round(h * 0.9)
left_x -= padding_w
right_x += padding_w
left_y -= padding_h
right_y += padding_h
cropped_lip = image[int(left_y):int(right_y), int(left_x):int(right_x)]
if len(cropped_lip)>0:
cv2.imwrite(f"/content/data/smile/{tmp_smile}", cropped_lip)
cv2.imwrite(f"/content/data/all_images/{tmp_smile}", cropped_lip)i_temp = 0
for i in range(non_smiling_size):
tmp_smile = non_smiling.iloc[i]['image_id']
image = cv2.imread(f"/content/data_faces/img_align_celeba/{tmp_smile}")
if image is None:
print(f"No such video: {tmp_smile}")
#gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
faces = detector(image)
for face in faces:
if (face.tl_corner().x) > 0:
i_temp = i_temp +1
landmarks = predictor(image, face)
left_x = landmarks.part(48).x
left_y = landmarks.part(50).y
right_x = landmarks.part(54).x
right_y = landmarks.part(56).y
w = np.abs(right_x - left_x)
h = np.abs(right_y - left_y)
padding_w = np.round(w * 0.4)
padding_h = np.round(h * 0.7)
left_x -= padding_w
right_x += padding_w
left_y -= padding_h
right_y += padding_h
cropped_lip = image[int(left_y):int(right_y), int(left_x):int(right_x)]
if len(cropped_lip)>0:
cv2.imwrite(f"/content/data/non_smile/{tmp_smile}", cropped_lip)
cv2.imwrite(f"/content/data/all_images/{tmp_smile}", cropped_lip)Next, we need to create a data frame for the images with cropped lips. To do that we will create two lists of images (smile and non_smile) using the function os.listdir(). Then, we will create two dictionaries where we will store the image names and labels. Images with smiles will be labeled with number 1 and images with no smiles will be labeled with 0. After that we are going to construct a DataFrame from these dictionaries.
img_list1 = os.listdir("/content/data/smile/")
data = {'img_id': [], 'smiles': []}
for j in range(len(img_list1)):
data['img_id'].append(img_list1[j])
data['smiles'].append(1)
df_smile = pd.DataFrame(data)
#a = pd.DataFrame(df_smile)
img_list2 = os.listdir("/content/data/non_smile/")
data = {'img_id': [], 'smiles': []}
for j in range(len(img_list2)):
data['img_id'].append(img_list2[j])
data['smiles'].append(0)
df_non_smile = pd.DataFrame(data)
#b = pd.DataFrame(df_non_smile)
a = pd.concat([df_smile, df_non_smile])
df_np = np.array(a)
df = pd.DataFrame(df_np)
print(df)0 000663.jpg 1
1 001502.jpg 1
2 000785.jpg 1
3 000854.jpg 1
4 001760.jpg 1
... ... ..
1952 000468.jpg 0
1953 001489.jpg 0
1954 001484.jpg 0
1955 001581.jpg 0
1956 000682.jpg 0
[1957 rows x 2 columns]Now, we need to arrange our data and define a size for the training, validation, and testing set. First, we are going to use the function np.min() which compares two arrays and returns a new array containing the element-wise minima. In that way, we will be able to determine which area of images is smaller – smile or non_smile. Then, we will select the same number of images from both data frames.
Next, we will create training, validation and test datasets. The length of the test dataset will be 80% of the total length where the length of the validation and the test datasets will be 10%.
min_ = np.min([len(df[df[1] == 0]), len(df[df[1] == 1])])
smiling = df[df[1] == 1].iloc[:min_]
non_smiling = df[df[1] == 0].iloc[:min_]
train = pd.concat([smiling,non_smiling])
train.reset_index(drop=True, inplace=True)
indices = np.arange(0, len (train))
np.random.seed(42)
np.random.shuffle(indices)
train_size = int(0.8*len(indices))
test_size = int(0.1*len(indices))
val_size = int(0.1*len(indices))
train_indices = indices[:train_size]
indices = indices[train_size:]
test_indices = indices[:test_size]
indices = indices[test_size:]
val_indices = indices[:val_size]
indices = indices[val_size:]
train_database = train.iloc[train_indices]
test_database = train.iloc[test_indices]
val_database = train.iloc[val_indices]The next step is to load our images and labels. First, we need to resize our images to dimensions \(32\times32 \) and transform them to tensors. For that, we will use the function transforms.compose().
train_transform = transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
])
test_transform = transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
])
val_transform = transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
])
Next, we are going to define a class that will help us to create a train, validation, and test dataset. Parameters for this class are a data frame, root to images, and transformation which is set to None as default. The class will return two values: image and label.
class Dataset(Dataset):
def __init__(self, df, root, transform=None):
self.data = df
self.root = root
self.transform = transform
def __len__(self):
return len(self.data)
def __getitem__(self, index):
item = self.data.iloc[index]
path = self.root + "/" + item[0]
#image = Image.open(path).convert('L')
image = Image.open(path)
label = item[1]
if self.transform is not None:
image = self.transform(image)
return image, label
Now, we are going to define the image path and create datasets using the Dataset class.
IMG_PATH ="/content/all_images/"
train_data = Dataset(train_database, IMG_PATH, train_transform)
test_data = Dataset(test_database, IMG_PATH, test_transform)
val_data = Dataset(val_database, IMG_PATH, val_transform)
train_data_size = len(train_data)
test_data_size = len(test_data)
val_data_size = len(test_data)
print(train_data_size)
print(test_data_size)
print(val_data_size)1540, 192, 192
Next, we are going to create trainLoader, valLoader and testLoader objects using the function torch.utils.data.DataLoader(). As parameters, we will specify the dataset that we created, batch size which is set to be equal to 64, and shuffle which will be set to True.
batch_size = 64
trainLoader = torch.utils.data.DataLoader(train_data,batch_size=batch_size, shuffle=True)
testLoader = torch.utils.data.DataLoader(test_data, batch_size=batch_size, shuffle=True)
valLoader = torch.utils.data.DataLoader(val_data, batch_size=batch_size, shuffle=True)Next, we need to define an optimizer and criterion. For an optimizer, we will use the optim.Adam() function which will calculate gradients. As parameters to this function, we will pass the model.parameters(), and we will set the learning rate to be equal to 0.0001. Then, we will calculate the loss by using nn.CrossEntropyLoss() function.
optimizer = optim.Adam(model.parameters(), lr=0.0001)
criterion = nn.CrossEntropyLoss()Now it is time to train our model. We will train it for 50 epochs. First, we will iterate through all training images and set them to work with the device we specified in the beginning. Then, we will zero the gradients, apply the forward propagation, calculate the loss, and apply the backpropagation step. After the training step, we also validate our model. We will iterate through all the validation images and use our model for predictions. We will add one to the variable total every time our model predicts correctly. To calculate the accuracy we will just divide the number of correctly predicted images by the size of the validation set.
epochs = 50
train_loss = []
val_loss = []
t_accuracy_gain = []
accuracy_gain = []
for epoch in range(epochs):
total_train_loss = 0
total_val_loss = 0
model.train()
total_t = 0
# training our model
for idx, (image, label) in enumerate(trainLoader):
image, label = image.to(device), label.to(device)
optimizer.zero_grad()
pred_t = model(image)
loss = criterion(pred_t, label)
total_train_loss += loss.item()
loss.backward()
optimizer.step()
pred_t = torch.nn.functional.softmax(pred_t, dim=1)
for i, p in enumerate(pred_t):
if label[i] == torch.max(p.data, 0)[1]:
total_t = total_t + 1
accuracy_t = total_t / train_data_size
t_accuracy_gain.append(accuracy_t)
total_train_loss = total_train_loss / (idx + 1)
train_loss.append(total_train_loss)
# validating our model
model.eval()
total = 0
for idx, (image, label) in enumerate(valLoader):
image, label = image.to(device), label.to(device)
pred = model(image)
loss = criterion(pred, label)
total_val_loss += loss.item()
pred = torch.nn.functional.softmax(pred, dim=1)
for i, p in enumerate(pred):
if label[i] == torch.max(p.data, 0)[1]:
total = total + 1
accuracy = total / test_data_size
accuracy_gain.append(accuracy)
total_val_loss = total_val_loss / (idx + 1)
val_loss.append(total_val_loss)
if epoch % 5 == 0:
print('\nEpoch: {}/{}, Train Loss: {:.4f}, Val Loss: {:.4f}, Val Acc: {:.4f}'.format(epoch, epochs, total_train_loss, total_val_loss, accuracy))
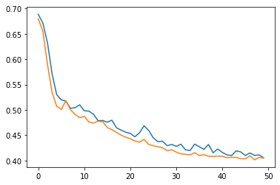
Epoch: 0/50, Train Loss: 0.6886, Val Loss: 0.6799, Val Acc: 0.5469
Epoch: 5/50, Train Loss: 0.5199, Val Loss: 0.5009, Val Acc: 0.8073
Epoch: 10/50, Train Loss: 0.4983, Val Loss: 0.4872, Val Acc: 0.8385
Epoch: 15/50, Train Loss: 0.4758, Val Loss: 0.4651, Val Acc: 0.8594
Epoch: 20/50, Train Loss: 0.4535, Val Loss: 0.4429, Val Acc: 0.8750
Epoch: 25/50, Train Loss: 0.4447, Val Loss: 0.4293, Val Acc: 0.8906
Epoch: 30/50, Train Loss: 0.4280, Val Loss: 0.4166, Val Acc: 0.9115
Epoch: 35/50, Train Loss: 0.4271, Val Loss: 0.4099, Val Acc: 0.9115
Epoch: 40/50, Train Loss: 0.4160, Val Loss: 0.4083, Val Acc: 0.9167
Epoch: 45/50, Train Loss: 0.4099, Val Loss: 0.4032, Val Acc: 0.9115
After we have trained our model, let’s print the training loss, validation loss, training accuracy, and validation accuracy.
Training and validation loss:
Accuracy:
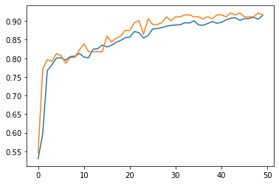
As you can see, using just 1000 images we have achieved an accuracy of almost 90%.
Now, let’s test our model. First, we are going to iterate through the test loader using the following code.
testiter = iter(testLoader)
images, labels = testiter.next()Then, for testing, we need to turn off the gradient calculation using the function torch.no_grad(). Next, we will send our images and labels to the device. After that, we will create a prediction variable that will be equal to our trained model and images in the testLoader.
Next, we will extract all the images into a list using this one line for loop. Also, we will convert the data to numpy. Finally, we will create a list of two classes – no_smile and smile.
with torch.no_grad():
images, labels = images.to(device), labels.to(device)
pred = model(images)
images_np = [i.cpu() for i in images]
class_names = ['no_smile', 'smile']Now, we can visualize the performance of our model using the following code. We will iterate through 50 images and plot them with their corresponding label. We will color the label in blue in case that our model predicted correctly, and in red if it failed to predict that class.
fig = plt.figure(figsize=(15, 7))
fig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.05, wspace=0.05)
for i in range(50):
ax = fig.add_subplot(5, 10, i + 1, xticks=[], yticks=[])
ax.imshow(images_np[i].permute(1, 2, 0), cmap=plt.cm.gray_r, interpolation='nearest')
if labels[i] == torch.max(pred[i], 0)[1]:
ax.text(0, 3, class_names[torch.max(pred[i], 0)[1]], color='blue')
else:
ax.text(0, 3, class_names[torch.max(pred[i], 0)[1]], color='red')
As you can see only 6 out of the 50 images were classified incorrectly. So we can say that our model achieved very good accuracy.
Building A Smile Detection Model With PyTorch
- CNNs can detect happiness or smiles easily using Smile Detection Models
- CelebA is a dataset that contains 200K diverse celeb images with over 10K identities
- LeNet-5 Convolutional Neural Network is used to build a Deep Learning-based Smile Detection model
- LeNet-5 architecure is quite popular due to its simplicity
- LeNet-5 architecture contains 7 layers – 3 Convolutional, 2 Average Pooling and 2 Fully-Connected Layers
Summary
Well, that’s it for today’s tutorial! Hope our Smile Detection model could bring a smile to your face too. Just out of curiosity, which celebrity’s smile do you find the most attractive? Let us know in the comments. If you are facing any issues with our content, write to us and if you are enjoying our posts, drop us a message of appreciation as well. Time to build your own Smile Detection model, now that you have learned how to build one. We’ll return with another awesome topic next time. Till then, keep smiling! 🙂