#011 Machine Learning – Decision three

Highlights: Hello and welcome. In today’s post, we are going to talk about one of the learning algorithms that are very powerful and is used in many machine learning applications. It is called decision trees and tree ensembles. It is a very powerful tool that is well worth having in your toolbox. In this post, we’ll learn about decision trees and we’ll see how you can apply them in your own machine learning projects. So, let’s begin with our post.
Tutorial overview:
- What is a decision tree?
- Decision tree learning process
- Measuring purity
- Choosing a split: Information Gain
1. What is a decision tree?
To explain how decision trees work, we are going to use the following cat classification example. Let’s imagine that you are running a cat adoption center and given a few features, you want to train a classifier to quickly tell you if an animal is a cat or not. In the following image, you can see that we have 10 training examples.
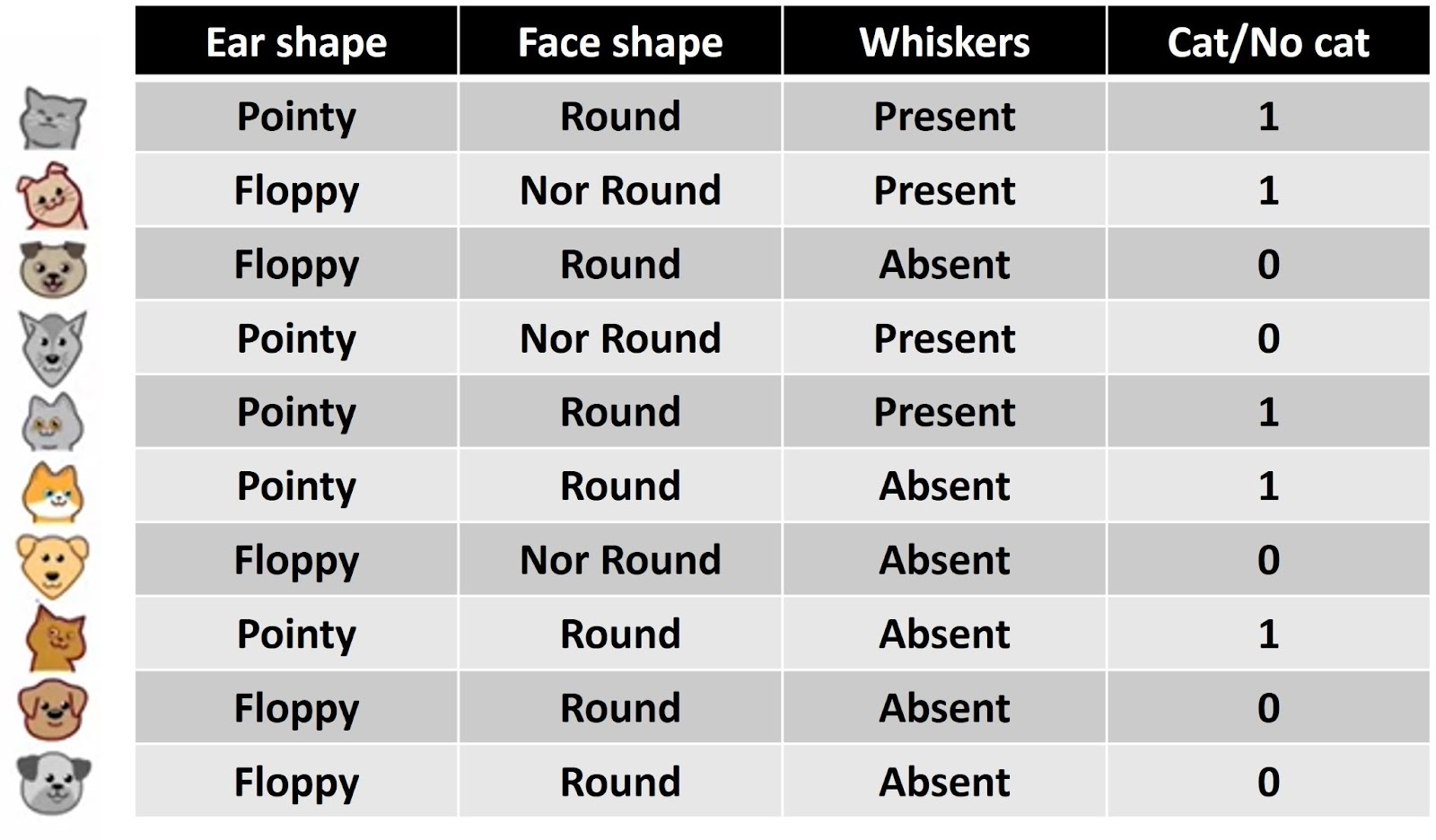
Associated with each of these 10 examples, we’re going to have features regarding the animal’s ear shape, face shape, and whether it has whiskers or not. We are also going to have a ground truth label that will tell us whether the animal is a cat or not. If we take a look at the first row in the table above we can see that this example has pointy ears, round faces, and whiskers present, and it is a cat. The second example has floppy ears, the face shape is not round, whiskers are present, and yes, that is a cat, and so on for the rest of the examples. This dataset has five cats and five dogs in it. The input features \(x \) are the first three columns, and the target output \(y \) is the final column. In this example, the features \(x \) take on categorical values. In other words, the features take on just a few discrete values. Your shapes are either pointy or floppy. The face shape is either round or not round and whiskers are either present or absent. This is a binary classification task because the labels are either one or zero. For now, each of the features \(x_{1} \), \(x_{2} \), and \(x_{3} \) take on only two possible values. Now, let’s see what exactly a decision tree is.

In the image above we can see an example of a model that you might get after training a decision tree learning algorithm on the data set that you just saw. The model that is output by the learning algorithm looks like a tree, and a picture like this is what computer scientists call a tree. Let’s examine this example in more detail.
Every one of the ovals or rectangle shapes is called a node in the tree. The way this model works is as follows. Let’s say that you have a new test example of a pointy ear-shaped cat that has round, face, and whiskers. This model will look at this example and make a classification decision starting with this example at the topmost node of the tree. This node is also called the root node of the tree, and we will look at the feature written inside, which is ear shape. Based on the value of the ear shape of this example we’ll either go left or go right. The value of the ear shape with this example is pointy, so we’ll go down the left branch of the tree and end up at the “face shape” node. Then we look at the face shape of this example, which turns out to be round. Therefore, the algorithm will make a prediction that this is a cat.
What we have shown in this image is one specific decision tree model. To introduce a bit more terminology, this top-most node in the tree is called the root node. All of these oval shape nodes, but are called decision nodes. They’re decision nodes because they look at a particular feature and then based on the value of the feature, decide whether to go left or right down the tree. Finally, these rectangular boxes are called leaf nodes. They make a prediction.
So, the job of the decision tree learning algorithm is as follows. Out of all possible decision trees, the algorithm tries to pick one that hopefully does well on the training set and it also ideally generalizes well to new data such as your cross-validation and test sets as well.
So, it seems like there are lots of different decision trees one could build for a given application. How do you get an algorithm to learn a specific decision tree based on a training set? Let’s take a look at that problem.
2. Decision tree learning process
The process of building a decision tree given a training set has a few steps. Let’s take a look at the overall process of what we need to do to build a decision tree.
- Select the best feature
- Make that feature a decision node and break the dataset into smaller subsets.
- Starts tree building by repeating this process recursively for each child until one of the conditions will match:
- All the tuples belong to the same attribute value.
- There are no more remaining attributes.
- There are no more instances.
To better understand this, let’s take a look at the specific example.

Suppose that we have a training set of 10 examples of cats and dogs like we earlier in the post. The first step of decision tree learning is to decide what feature to use at the root node. Let’s say that we decided to pick the ear shape feature. That means that we will look at all of our training examples, and split them according to the value of the ear shape feature. In particular, let’s pick out the examples with pointy ears and move them over down to the left side of the tree. Also, we will pick the five examples with floppy ears and move them down to the right. The second step is focusing just on the left part or sometimes called the left branch of the decision tree to decide what nodes to put over there. In particular, which feature we want to use next. Let’s say you decide to use the face shape feature. What we’ll do now is take these five examples and split these five examples into two subsets based on their value of the face shape. Finally, we notice that four examples with the round face are cats and one with a face that is not round is a dog. Rather than splitting further, we create two leaf nodes that make a prediction of cat and not a cat. Having done this on the left branch of this decision tree, we now repeat a similar process on the right branch of the decision tree. Focus attention on just these five examples, which contain one cat and four dogs. We would have to pick some features to split these five examples further. We chose the whiskers feature and split these five examples based on where the whiskers are present or absent. You notice that one out of one example on the left fare cats and zero out of four are cats on the right. Each of these nodes is completely pure. This means that all examples now are cats or not cats and there’s no longer a mix of cats and dogs.
So, this is the process of building a decision tree. Through this process, there were a couple of key decisions that we had to make at various steps during the algorithm. Let’s talk through what those key decisions were and we’ll keep on session of the details of how to make these decisions in the next few videos.
How to choose what features to use?
The first key decision was, how do you choose what features to use to split on at each node? At the root node, as well as on the left branch and the right branch of the decision tree, we had to decide if there were a few examples at that node comprising a mix of cats and dogs. Do you want to split on the ear-shaped feature or the facial feature or the whiskers feature? Decision trees will choose what feature to split on in order to try to maximize purity. Purity means that we want to find subsets, which are as close as possible to all cats or all dogs. Because if you can get to a highly pure subset of examples, then you can either predict cat or predict not a cat and get it mostly right.
When do we stop splitting?
The second key decision we need to make when building a decision tree is to decide when to stop splitting. The criteria that we have used in the previous example was to build the leaf node when we know that there are either 100 percent, all cats, or 100 percent of dogs. Because at that point it seems natural to build a leaf node that just makes a classification prediction.
Alternatively, we might also decide to stop splitting when no further results in the tree exceeding the maximum depth. The depth of a node is defined as the number of hops that it takes to get from the root node that is denoted at the very top to that particular node. So the root node takes zero hops, it gets herself and is at depth 0. The nodes below are of depth 1 and so on.

If you had decided that the maximum depth of the decision tree is say two, then you would decide not to split any nodes below this level so that the tree never gets to depth 3. One reason you might want to limit the depth of the decision tree is to make sure that the tree doesn’t get too big and unwieldy. The second reason is by keeping the tree small, makes it less prone to overfitting.
Another criterion you might use to decide to stop splitting might be the improvements in the purity score below a certain threshold. If splitting a node results in minimum improvements to purity we should stop splitting the decision tree.
Finally, if the number of examples in a node is below a certain threshold, then you might also decide to stop splitting.
Now, the next key decision we will dive more deeply into is how to decide how to split a node. Let’s take a look at the definition of entropy, which would be a way for us to measure purity, or more precisely, impurity in a node.
3. Measuring purity
Let’s take a look at the definition of entropy, which is a measure of the impurity of a set of data.

Given a set of six examples that we can see in the image above, we have three cats and three dogs. Let’s define \(p_{1} \) to be the fraction of examples that are cats, that is, the fraction of examples with label one. So, p_1 in this example \(p_{1} =3/6 \). We’re going to measure the impurity of a set of examples using a function called entropy which is illustrated in the following image.

The entropy function is conventionally denoted as \(H \) of this number \(p_{1} \) and the function looks like this curve where the horizontal axis is \(p_{1} \), the fraction of cats in the sample, and the vertical axis is the value of the entropy. In this example where \(p_{1} =3/6 \) or 0.5, the value of the entropy of \(p_{1} \) would be equal to 1. You notice that this curve is highest when your set of examples is 50-50. So it’s most impure as an impurity of 1 or with an entropy of 1 when your set of examples is 50-50. In contrast, if your set of examples was either all cats or not cats then the entropy is equal to 0.
Recall that \(p_{1} \) is the fraction of examples that are equal to cats so if you have a sample that is \(⅔ \) cats then that sample must have \(⅓ \), not cats. Therefore we can define \(p_{0} \) as follows:
$$ p_{0} = 1-p_{1} $$
The entropy function is then defined as follows:
$$ H\left(p_{1}\right)=-p_{1} \log _{2}\left(p_{1}\right)-p_{0} \log _{2}\left(p_{0}\right) $$
By convention when computing entropy we take logs to base 2 rather than to base \(e \). If you were to plot this function in a computer you will find that it will be exactly this function that we showed in the previous image.
To summarize, the entropy function is a measure of the impurity of a set of data. It starts from zero, goes up to one, and then comes back down to zero as a function of the fraction of positive examples in your sample.
Now that we have this definition of entropy, let’s take a look at how you can actually use it to make decisions about what feature to split on in the nodes of a decision tree.
4. Choosing a split: Information Gain
When building a decision tree, the way we’ll decide what feature to split on at a node will be based on what choice of feature reduces entropy or reduces impurity the most. In decision tree learning, the reduction of entropy is called information gain. Let’s take a look at how to compute information gain and therefore choose what features to use to split on at each node in a decision tree.
Let’s use the example of recognizing cats versus not cats. If we had split using their ear shape feature at the root node, this is what we would have gotten, five examples on the left and five on the right as you can see in the following image.

If you apply the entropy formula to this left subset of data and this right subset of data, we find that the degree of impurity on the left is the entropy of 0.8, which is about 0.72, and on the right, the entropy of 0.2 turns out also to be 0.72. This would be the entropy at the left and right subbranches if we were to split on the ear shape feature. One other option would be to split on the face shape feature.

Here, the entropy of 4/7 and the entropy of 1/3 are 0.99 and 0.92. So the degree of impurity in the left and right nodes seems much higher compared to the previous example. Finally, the third possible choice of feature to use at the root node would be the whiskers feature in which case you split based on whether whiskers are present or absent.

In this case, the entropy values are as follows 0.81 and 0.92.
The key question we need to answer is, given these three options of a feature to use at the root node, which one do we think works best?
Associated with each of these splits are two numbers, the entropy on the left sub-branch and the entropy on the right sub-branch. In order to pick from these, we like to actually combine these two numbers into a single number. The way we’re going to combine these two numbers is by taking a weighted average. Because how important it is to have low entropy in the left or right sub-branch also depends on how many examples went into the left or right sub-branch. If there are lots of examples in the left sub-branch then it seems more important to make sure that that left sub-branch entropy value is low.
In this example we have, five of the 10 examples that went to the left sub-branch, so we can compute the weighted average as 5/10 times the entropy of 0.8, and then add to that 5/10 examples also went to the right sub-branch, plus 5/10 times the entropy of 0.2. We can do the same calculation for the other two examples. The way we will choose a split is by computing these three numbers and picking whichever one is the lowest because that gives us the left and right sub-branches with the lowest average weighted entropy. In the way that decision trees are built, we’re actually going to make one more change to these formulas to stick to the convention in decision tree building. Rather than computing this weighted average entropy, we’re going to compute the reduction in entropy compared to if we hadn’t split at all. So, remember that we have started off with all 10 examples in the root node with five cats and dogs. Therefore at the root node, we had the entropy of 0.5 which was actually equal to 1. This was maximum in purity because there were five cats and five dogs. So we are going to use the following formulas:
$$ H(0.5)-\left(\frac{5}{10} H(0.8)+\frac{5}{10} H(0.2)\right)=0.28 $$
$$ H(0.5)-\left(\frac{7}{10} H(0.57)+\frac{3}{10} H(0.33)\right)=0.03 $$
$$ H(0.5)-\left(\frac{4}{10} H(0.75)+\frac{6}{10} H(0.33)\right)= 0.12 $$
These numbers that we just calculated, 0.28, 0.03, and 0.12, are called the information gain. They measure the reduction in entropy that you get in your tree resulting from making a split. Because the entropy was originally 1 at the root node and by making the split, you end up with a lower value of entropy. The difference between those two values is a reduction in entropy, and that’s equal to 0.28 in the case of splitting on the ear shape ( 0.28 is bigger than 0.03 and 0.12 and so we would choose to split onto the ear shape feature at the root node).
So, why do we bother to compute reduction in entropy rather than just entropy at the left and right sub-branches? It turns out that one of the stopping criteria for deciding when to not bother to split any further is if the reduction in entropy is too small.
Let’s now write down the general formula for how to compute information gain. Using the example of splitting on the ear shape feature, let me define \(p_{1}^{\text {left } \) to be equal to the fraction of examples in the left subtree that have a positive label.
$$ p_{1}^{\text {left }}=4 / 5 $$
$$ w^{\text {left }}=5 / 10 $$
Also, we define \(w^{\text {left }} \) to be the fraction of examples of all of the examples of the root node that went to the left sub-branch. Similarly, let’s define $latex p_{1}^{\text {right }} $ and \(w^{\text {right }} \).
$$ p_{1}^{\text {right }}=1 / 5 $$
$$ w^{\text {right }}=5 / 10 $$
Let’s also define \(p_{1}^{\text {root }} \) to be the fraction of examples that are positive in the root node.
$$ p_{1}^{\text {root }}=5 / 10=0.5 $$
Information gain is then defined as:
$$I =\mathrm{H}\left(\mathrm{p}_{1}^{\text {root }}\right)-\left(w^{\text {left }} H\left(p_{1}^{\text {left }}\right)+w^{\text {right }} H\left(p_{1}^{\text {right }}\right)\right) $$
With this definition of entropy, you can calculate the information gain associated with choosing any particular feature to split on in the node. Then out of all the possible futures, you could choose one that gives you the highest information gain. That will result in increasing the purity of your subsets of data that you get on the left and right sub-branches of your decision tree.
Now that you know how to calculate information gain or reduction in entropy, you know how to pick a feature to split on another node.
Summary
In this post, we learned about a very important algorithm in Machine learning called a decision tree. Decision trees are extremely intuitive ways to classify or label objects. We learned how to choose what features to use, when we need to stop splitting and how to measure the purity of the tree.
However, we’ve talked about how to train a single decision tree. It turns out that if you train a lot of decision trees to get a much better result. In the next post, we are going to dive deeper into the training of multiple decision trees.


