#011 3D Face Modeling – Capture, Learning, and Synthesis of 3D Speaking Styles – VOCA

Highlights: Hello and welcome back! We will continue our post series on talking faces. In this post, we will explore, the so-called, face animation. That is, we will not be focussed on face photo-realism, but on a digital avatar. So, let’s begin.
Let’s have a look at the image below.

Here we can see the difference between the animated character and a realistic 3D digital human. In this post, we will explore a model called VOCA as well as VOCASET.
Introduction
Face modeling and processing are an important part of computer vision and computer graphics. So far, a lot of work has been done in the areas of Facial Expression Recognition, shape modeling, and estimation of facial motion.
Interestingly, only a few researchers explored the connection between speech and facial shapes. On the other hand, most facial expressions are generated while we speak. In this way, there is a strong interdependence between audio and visual facial content. This relation has been used to separate audio-visual speech, as well as to develop audio-driven facial animation.
In this work [1], the researchers developed a model, that can relate to any person, speaking in any language and enabling control of any face. The model is named VOCA – Voice Operated Character Animation. Hence, this model represents a speaker-independent model. So far, it has been rather challenging to solve this problem, and we will name a few reasons:
- There is a strong relationship between speech and facial motion. However, they lie in the two spaces which are completely unrelated, thereby making a regression function highly non-linear. This could be solved by Deep Learning regression, but this approach would require an immense quantity of data.
- There is a so-called, many-to-many problem that should relate any phoneme with any facial motion.
- To make the animation realistic, one has to produce results that are satisfying to a very sensitive human eye. This is known as the Uncanny Valley phenomenon.
- A generic method should be developed so that numerous speaking styles are captured by such a model.
Here, we will give an overview of the proposed method. Before that, we will mention that speaker-dependent solutions with impressive results have been developed. That is, speech is used to control facial animation. Therefore, such solutions are overly tuned for a particular person, and due to this reason, these models lack generalization ability.
Next, there is a strong relation between facial shape (identity) and facial motion. Here, in this work [1], the key goal is to factor in the identity and to correlate a speech only with a motion component. In this way, faces can be combined during the training process, and later, this will be important to develop a model that will generalize well.
Within the VOCA solution, the DeepSpeech model is used to extract the audio features. In this way, the model becomes robust to different speakers as well as to noise.
Furthermore, this model is developed using the FLAME head model. This is an expressive model that allows accurate modeling of:
- different faces, including a neck as well,
- animation of a wide range of human faces and
- editing of identity-dependent shapes and head pose during the animation
One important aspect of VOCA development is that it is trained across faces that share the same topology. Then, this makes it possible to generalize well from previously unseen points. In addition, the process of generalization here refers to the ability to generalize across different speakers in terms of audio (variations in accent, speed, and audio source) and generalization across different facial shapes and motions.
DeepSpeech
In order to develop a robust model, in VOCA, the DeepSpeech model is used. This model represents an end-to-end deep learning model for Automatic Speech Recognition (ASR). DeepSpeech uses five layers of hidden units, of which the first three layers are non-recurrent fully connected layers with ReLU activations. The fourth layer is a bi-directional RNN and the final layer is a fully connected layer with ReLU activation. The final layer is fed to the softmax function whose output represents the probability distribution for each character. This means, that it is possible to train it for any desired language if needed.
In some practical implementations, the DeepSpeech model can be altered in a way that the RNN module is replaced by an LSTM cell. Moreover, 26 MFCC audio features are used instead of direct inference on the spectrogram.
FLAME
Different people have different facial shapes. Next, their style of speaking is different as well as head pose motion. Therefore, it is appealing to have the same learning space for all different people.
A model FLAME is used within the VOCA solution. It uses a linear transformation to characterize the identity, expression, and facial motion. Given a template \(T \in \mathbb{R}^{3N}\), in “zero pose”, this shape measures the identity, expression, and motion offsets from \(T\).
VOCA
VOCA receives as input subject-specific template T (zero-pose), obtained from FLAME, as well as raw audio signals, from which speech features are calculated using DeepSpeech.
The desired output is a target 3D mesh. In this way, VOCA acts as an encoder-decoder network that transforms the audio features into a low-dimensional feature space. On the other hand, a decoder learns to upscale this feature vector, so that we obtain a displacement of the 3D vertices.
Speech feature extraction
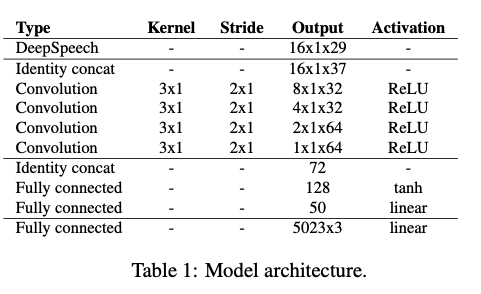
The outputs are unnormalized log probabilities of characters for frames of length 0.02s (50 frames per second). Thus, the output is an array of size \(50T x D\), where \(D\) is the number of characters in the alphabet plus one more for a blank/silence. In this experiment, the output is resampled at 60fps, so that it matches the sampling rate of a video signal. Here, a standard linear interpolation is used. Next, in order to incorporate temporal information, we convert audio frames into overlapping windows of size \(W x D\), where \(W\) is the window size. Hence, the final output is a three-dimensional array of size \(60T x W x D\).
Encoder
Our encoder is composed of four convolutional layers and two fully connected layers. The speech features and the final convolutional layer are conditioned on the subject label to learn subject-specific styles when trained over multiple subjects. As VOCASET has 8 subjects, a D-dimensional audio feature vector is extended by 8 elements that represent the one-hot encoding of the subjects. This results in \(W x (D+8)\) audio feature vector. In addition, this one-hot encoded vector is also concatenated to the output of the final convolutional layer, as can be seen in Figure 2. below.
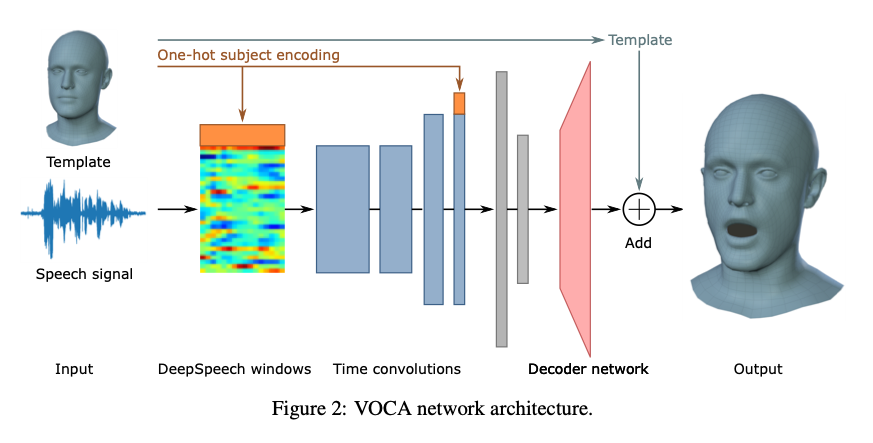
Next, the goal is to learn temporal features. For this reason, as the audio does not have a spatial component it is transformed into \(W x 1 x (D+8)\). Then, a 1D convolution is applied over the temporal dimension. The number of layers is kept low: 32 filters for the first two layers and 64 for the last two convolutional layers. This approach is designed to help reduce overfitting.
Finally, after convolutional layers, two more fully connected layers are added. Here, the hyperbolic tangent activation function is used. The first layer is designed with 128, and the last one with 50 units.
Decoder
The decoder part is designed as a very simple one. It actually consists of only one fully connected layer with a linear activation function. It outputs 5023×3 dimensional output. Hence, these elements represent a displacement from the “zero-pose” template \(T\).
Animation control
The interesting part here is that during inference we can alter the one-hot encoded vector. As a result, this will generate different speaking styles captured from the dataset. Hence, the output of the VOCA is a mesh having the same “zero-pose” but with expressions. Here, the output model structure follows the FLAME face model.
Training of our face model
A large 4D dataset is used denoted as \(\{ (x_i, y_i)\}^{F}_{i=1} \). Where \(x_i\) represents \(x_i \in \mathbb{R}^{WxD}\), the input audio window centered at the \(i_{th}\) frame, and \(y_i\), the training vertices. Also, \(f_i \in \mathbb{R}^{Nx3}\), which denotes the output of VOCA for \(x_i\).
Loss function
The training loss function consists of two terms: position and velocity term. They are expressed with the following equations. The position term measures the distance between the predicted and the training (ground truth) vertices.
$$ E_p = || y_i – f_i ||^2_F $$
In addition, the velocity term is computed between the consecutive frames. In particular, we have the differences between ground truth labels, as well as the differences between consecutive predictions. We can see that this term measures the speed of the vertices. Hence, as such, it assists us to improve the temporal stability of the generated videos.
$$ E_v = || (y_i – y_{i-1}) – (f_i – f_{i-1}) ||^2_F $$
Have we maybe missed clarifying some things? Well, probably many, but, here is the important one. What is a 4D scan and how it works?
Capture setup
In this experiment, the researchers have used a multi-camera active stereo system (3dMD, LLC, Atalanta) to capture high-quality head scans along with the audio signal. This system has both gray and color cameras as well as an additional setup that assists to generate videos at 60fps. This results in the 3D mesh that has 120k vertices. In addition, the audio is synchronized at 22kHz.
In Figure 3, below, we can see sample meshes of the such an acquisition system.

Results
In the figure below we can see the result of the VOCA model. Two persons are selected and for each, we have a reference template scan (left). Next, we have three randomly chosen frames that are driven by the same audio input.

References
[1] Cudeiro, Daniel, et al. “Capture, learning, and synthesis of 3D speaking styles.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.