#007 kNN (k Nearest Neighbors) – k najbliži sused

U našem narodu dobro je poznaka izreka “S kim si onakav si”. Dobro je poznata i misao da mi, kao pojedinci, predstavljamo “sredinu, od petoro ljudi sa kojima provodimo najviše vremena”. Slagali se sa ovim ili ne, osnovna ideja ovih poruka predstavlja ideju za algoritam kNN. k Nearest Neighbors za svaki element iz skupa podataka prvo definiše razdaljinu od susednih elemenata. Ta razdaljina može da predstavlja rastojanje između dve tačke. Parametar k biramo mi i on utiče na broj suseda za jednu tačku koju ispitujemo u njegovoj okolini.
Definišimo dve klase elemenata tako što ćemo ručno napraviti elemente klase. Neka elementi klase 1 budu tačke koordinatnog sistema sa pozitivnim koeficijentima, a elementi klase 2 sa negativnim.
Na ovom primeru prikazaćemo novi algoritam za klasifikaciju. Njegovo ime je kNN – k Nearest Neighbours. Na sledećoj slici prikazan je osnovni način rada kNN algoritma.
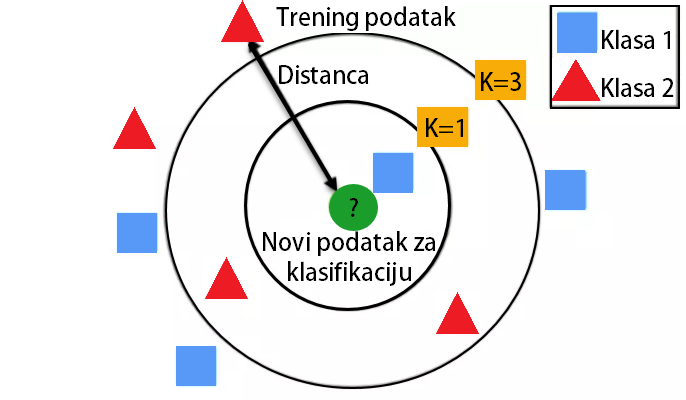
Način rada kNN-a
Zamislimo da dobijemo novu tačku (2,1) koja predstavlja test skup. Naš zadatak je da odredimo da li ona pripada klasi 1 ili klasi 2. Parametar k kNN algoritma je podešen na vrednost 3. Uglavnom se biraju neparni brojevi, a videćemo ubrzo i zašto. Pronađimo 3 najbliže tačke našoj test tački. Najlakše je da ovo ilustrujemo i da vizuelno pronađemo 3 najbliže tačke.
Naša test tačka je “okružena” elementima klase 1, tj. tri njoj najbliže tačke imaju klasu 1. kNN algoritam će ovo izbrojati i primenit tzv. majority vote: 3-0 u korsit klase 1. Stoga će naša nova tačka biti dodeljena klasi 1. Proverimo sam tok kada primenimo kNN algoritam koji se nalazi u biblioteci sklearn.
Da bismo na slučajan način birali cvetove iz sva tri skupa možemo da se poslužimo naredbom .random.shuffle(). Umesto da direktno indeksiramo koje elemente ćemo koristiti u trening a koje u test skupu, možemo našu uređenu listu indeksa da izmešamo. Ovo upravo činimo pomenutom naredbom .random.shuffle(niz) koja vrši proizvoljnu permutaciju nad nizom niz.
Ovo je upravo ono što smo tražili. Indeksi su raspoređeni na potpuno proizvoljan način. Prvih 80% podataka iskoristićemo za pravljenje našeg trening dataset-a. Preostalih 20% koristićemo za pravljenje test skupa.
Jedini parametar koji algoritam kNN prihvata kao ulazni podatak jeste n_neighours, odnosno k. Uobičajne vrednosti koje se uzimaju za ispitivanje različitih vrednosti k su {3, 5, 7, 9, 11, 15 …}. Radi vežbe promenite sami parametre n_neighbours i pratite kolika se tačnost postiže na test skupu. Pre nego što završimo, pogledajmo još kako možemo izvršiti vizuelizaciju iris dataset-a. Pored biblioteke matplotlib, često se koristi i biblioteka seaborn. Seaborn omogućava praveljenje veoma lepih i korisnih grafika za Exploratory Data Analysis – EDA.
Grafici koje smo dobili izvan glavne dijagonale, predstavljaju dobro poznati scatter plot. Za sva četiri obeležja, napravljeni su scatter plotovi koji iscrtavaju 3 klase cveta iris. Ovo nam može biti od velikog značaja da shvatimo koliko je “težak” naš klasifikacioni problem. Vidimo da je plava klasa uvek jasno razdvojena od ostale dve vrste cveta. Takođe, vidimo da klase 1 i 2, možemo efektno razdvojiti obeležjima 2 i 3. U poslednjoj koloni, i poslednjem redu, prikazano je kako odgovarajuće obeležje pojedinačno može da razdvoji 3 date klase. Ovde se vidi da je možda najveća diskriminativna moć među klasama 3 i 4, a nešto manja u klasama 1 i 2. Ipak, da bismo neko obeležje proglasili lošim, neophodno je izvršiti detaljnije provere.